
多模态的情感分析技术综述
2021-07-22 17:02刘继明张培翔张伟东
计算机与生活 2021年7期
刘继明,张培翔,刘 颖,3,4,张伟东,4,房 杰,3,4
1.西安邮电大学 通信与信息工程学院,西安 710121
2.西安邮电大学 图像与信息处理研究所,西安 710121
3.陕西省无线通信与信息处理技术国际合作研究中心,西安 710121
4.西安邮电大学 电子信息现场勘验应用技术公安部重点实验室,西安 710121
情感是生物对外界价值关系产生的主观反应,也是生物智能的重要组成部分[1]。在日常生活中,人们一般都是通过面部表情来获取他人的情感状态,但是某一些情况下,人们也会根据语气、肢体动作等其他一些细微的变化来获取他人的情感状态。在服务型机器人、审讯、娱乐等方面需要通过计算机的帮助来获得人类准确的情感状态,因此情感分析体现了越来越重要的研究价值。
情感分析的理论和算法构建涉及人工智能(artificial intelligence,AI)、计算机视觉(computational vision,CV)和自然语言处理(natural language processing,NLP)等多个方面,是一个多学科交叉的研究领域。早在20 世纪,Ekman 等人[2]就将人类的情感分为愤怒、厌恶、恐惧、快乐、悲伤和惊讶六种基本情感,奠定了当今表情识别的基础。在后来的研究中,蔑视也被认为是人类的基本情感之一。
在现有的文献中,主要根据面部表情、文本以及语音中的一种模态来对情感进行分析。在面部表情识别(facial expression recognition,FER)中,传统的方法主要有基于几何和外观的方法。基于几何的方法虽然简单易行,但是容易忽略局部细节信息。基于外观的方法主要是根据面部的纹理变化来判断情绪的变化,具有良好的光照不变性。在面部的纹理特征提取中,局部二值模式(local binary pattern,LBP)和Gabor 小波因具有较好的性能而被广泛应用。情感极性是指积极、消极以及中性的情感状态。通过文本分析得到情感极性的方法又称为意见挖掘,传统的方法是基于情感词典,该方法通过人为构建情感词典并将其作为工具来判断情感极性。由于情感词典中情感词的不完整,该方法具有很大的局限性。语音情感分析主要是提取语音中的韵律、音质等特征来进行分析。近年来,随着深度学习的发展,面部表情、文本和语音三种模态都尝试用深度学习的方法来进行情感分析。在基于深度学习的方法中,面部表情信息主要用卷积神经网络(convolutional neural networks,CNN)、深度神经网络(deep neural networks,DNN)以及与传统方法相结合进行情感分析;文本信息主要用循环神经网络(recurrent neural network,RNN)、长短期记忆网络(long short-term memory,LSTM)来进行情感分析;语音情感分析主要用支持向量机(support vector machine,SVM)、隐马尔科夫模型(hidden Markov model,HMM)等来进行分析。基于深度学习的方法在这三种模态的情感分析中都取得了不错的效果,但是由于数据集等原因,在训练模型时仍然存在一些不可避免的误差。
在情感分析的发展过程中,许多研究者用一种模态来进行情感分析。由于用单模态来进行情感分析时只能在该模态获得情感信息,在某些情况下有很多局限性。如图1 所示,在对人物进行情感分析时,若仅仅考虑文本信息,会得到一样的结果,只有结合面部表情后才能得到正确的情感极性。随着研究的深入,为了解决单模态的局限性,研究者开始结合两种或两种以上的模态来实现跨模态的情感分析。多模态的情感分析有效解决了单模态的局限性,并且提高了结果的准确度。图2 显示了一个多模态情感分析的框架。该框架包含两个基本步骤:分别处理单模态的数据和将处理后的数据进行融合。这两个步骤都很重要,如果单一模态的数据处理不好,会对多种模态的情感分析结果产生负面影响,而融合方式的性能不好会破坏多模态系统的稳定性[3]。

Fig.1 Limitations of single mode图1 单一模态的局限性

Fig.2 Framework for multi-modal sentiment analysis图2 多模态情感分析的框架
在情感分析中,目前常用的信息有面部表情信息、文本信息和语音信息,也有一些研究者尝试用姿态、脑部信息来进行情感分析。多模态的情感分析是指由两种及两种以上的模态信息结合来进行情感分析。在特征提取阶段,多模态的情感分析与单模态的特征提取方法相同。利用多模态和单模态进行情感分析最大的区别就是在于多模态需要将单模态的信息进行融合,从而得到情感极性。结合现有文献,模态融合主要包括三种方法,分别是特征级融合、决策级融合以及混合融合。
在多模态情感分析发展过程中,学者从不同的角度对现有的技术进行了总结。文献[4]通过基于视觉信息、语音信息、文本信息以及脑部信息的情感分析分别对现有的技术进行了总结。文献[5]对情感识别、意见挖掘和情绪分析做了详细介绍和区分,并且对情感分析所用到的文本、语音和视觉三种模态的技术做了分类总结。文献[6]对现有的单模态情感分析技术进行讨论,然后对近几年的多模态情感分析文献进行概括总结的同时指出了其模态融合的方法。文献[7]从基于深度学习的角度对现有的模态融合算法进行了归纳总结。与上述综述相比,本文在介绍单模态情感分析技术的基础上着重对多模态情感分析进行归纳总结,并且对文中提到的算法进行对比分析,最后重点介绍了多模态融合技术并对现有问题进行总结。
1 多模态情感分析数据集
目前国内外多模态情感数据库大多来源于网络视频评论或人为制作,对于科研领域仍是半公开或者不公开的状态。由于模态选择的不同以及数据集的局限性,一些研究者会根据自己的需求来建立所需要的情感数据集。用于多模态情感分析的可用数据集大多是从不同在线视频共享平台上的产品评论收集的。表1 总结了常用的多模态情感分析数据集。
SEED 数据集[8]:该数据集收集了15 名(男性7名,女性8 名)受试者在观看15 个中国电影剪辑时的脑电信号。其标签为积极、中性和消极三种。
新浪微博数据集[9]:数据集收集了新浪微博中关于新闻以及娱乐八卦的评论,共包括6 171 条评论,其中有4 196 条肯定消息,1 354 条否定消息和621 条中性消息,5 859 条消息具有一个伴随图像。情感标注为三分类。
Yelp 数据集[10]:该数据集从Yelp.com 评论网站收集关于餐厅和食品的评论。一共有44 305 条评论和233 569 张图片,其中每条评论有13 个句子,23 个单词。情感标注为1~5 的5 个分数。
Multi-ZOL 数据集[11]:该数据集收集了关于5 288条多模态的关于手机的评论信息,其中每条数据至少包含一个文本内容和一个图像级。情感标注为1~10 的10 个分数。
DEAP 数据集[12]:该数据集收集了32 名(一半男一半女)受试者在观看音乐视频时的生理信号和受试者对视频的Valence、Arousal、Dominance、Liking 的心理量表,同时也包括前22 名参与者的面部表情视频。标签为消极到积极1~9 的9 个分数。
CH-SIMS 数据集[13]:该数据集中包含60 个原始视频,剪辑出2 281 个视频片段,每个片段长度不小于1 s 且不大于10 s。在每个视频片段中,除了说话者的面部以外不会出现其他面部,且只包含普通话。数据集的情感标注为-1(负)、0(中性)或1(正)三种。
YouTube 数据集[14]:该数据集包含从YouTube 上收集整理的47 个不同产品的评论视频。视频由不同年龄、不同种族背景的20名女性以及27名男性对产品的观点讲述组成,且所有视频长度都被规范为30 s。在进行标注时,3 名人员随机观看并用积极、消极、中性三种标签对视频进行标注。该数据集共包含13 个积极、22 个中性以及12 个消极标签的视频序列。
ICT-MMMO 数据集[15]:该数据集包含了来自YouTube 和ExpoTV 中的370 个关于电影评论的视频。视频中不同的人对着摄像机表达1~3 min 的电影评论。此数据集中包括228 个正面评论、23 个中立评论和119 个负面评论。
MOSI 数据集[16]:该数据集包含了YouTube 上的93 个关于电影评论的视频博客。视频中包括年龄为20~30 岁以及来自不同种族背景的41 位女性和48 位男性的2~5 min 的电影评论。数据集中拥有从-3 到+3 的视频标签,代表7 类情感倾向。
News Rover Sentiment数据集[17]:该数据集是新闻领域的数据集,由各种新闻节目和频道视频中的929个4~15 s的视频组成。该数据集的标注为三分类。
IEMOCAP 数据集[18]:该数据集包含了5 个男演员和5 个女演员在情感互动过程中的大约12 h 视听数据,该数据包括对话者的音频、视频、文本、面部和姿态信息等。情感标签为愤怒、快乐、悲伤、中立等10 个标签。
2 单模态的情感分析算法
情感分析主要是通过一些表达情感的方式(比如面部表情等)对人们的情感进行分析。目前,主流的单模态的情感分析主要有基于面部表情信息和基于文本信息的情感分析。
不同的人物在表达情感时的方式不同:当一个人趋向于用语言表达情感时,那么其音频特征可能包含较多的情感线索;如果一个人趋向于用面部表情来进行情感表达,那么其面部表情特征可能包含较多的情感线索。由于人们多用说话方式的改变、音调的高低或者面部表情的变化对自己的情感状态进行表达,本章将重点介绍基于面部表情信息、文本信息以及语音信息的情感分析技术。
2.1 基于面部表情的情感分析
在日常生活中,面部表情信息是人们相互获得情感状态的常用方式,因此面部表情信息在情感分析的过程中有很重要的意义。根据特征表示的不同,FER 系统可分为静态图像的FER 和动态序列的FER 两大类[9]。在动态序列的FER 中,面部表情呈现出两个特点:空时性和显著性。动态序列的FER 中常常忽略面部表情的显著性,为了解决这一问题,文献[19]提出一种基于空时注意力网络的面部表情识别方法,该方法在空域子网络和时域子网络中加入相应的注意力模块,来提高CNN 和RNN 提取特征时的性能。
面部表情识别过程包括三个阶段,分别是人脸检测、特征提取与选择以及分类。根据所采用的特征表示,可分为传统方法和基于深度学习的方法。
2.1.1 传统的FER 方法
目前,FER 中常用特征有几何特征、外观特征、统计特征和运动特征等。基于几何特征的方法是对人脸构建几何特征矢量,且每幅图像只保存一个特征矢量;基于外观特征的方法主要对面部的纹理特征进行提取,目前常用的纹理特征主要有:LBP、基于频率域的Gabor 小波特征等;基于整体统计特征的方法可以尽可能多地保留图像中的主要信息,目前主要有主成分分析(principal component analysis,PCA)和独立主元分析(independent component correlation algorithm,ICA);基于运动特征的方法对动态图像序列中的运动特征进行提取,常用的是光流法。表2 从概念和优缺点两方面对传统的FER 特征提取方法进行了总结。

Table 2 Traditional FER feature extraction methods表2 传统的FER 特征提取方法
2.1.2 基于深度学习的FER 方法
近年来,研究者尝试用深度学习的方法进行面部表情识别,令人惊喜的是,深度学习在面部表情识别中也取得了良好的效果,研究者对面部表情识别的研究也逐渐从传统的方法转向深度学习方法。
文献[20]提出一种基于CNN 集成的面部表情识别方法,该方法在一组CNN 网络中设计了3 个不同的结构化子网络,分别包含3、5、10 个卷积层,图3 为集成CNN 的框架。该模型包括两个阶段:第一阶段将面部图像作为输入,并将其提供给3 个CNN 子网络,这是该模型的核心部分;第二阶段则根据前一阶段的输出预测表情,将这些子网络输出结合起来,以获得最准确的最终决策。

Fig.3 Framework of integrated CNN图3 集成CNN 的框架
由于传统方法中的LBP 具有旋转不变性和对光照不敏感等优点,文献[21]提出基于VGG-NET 的特征融合FER 方法,该方法将LBP 特征和CNN 卷积层提取的特征送入改进的VGG-16 的网络连接层中进行加权融合,最后将融合后的特征送入Softmax 分类器获取各类特征的概率,完成基本的6 种表情分类。图4 为该方法的基本框架。

Fig.4 VGG-NET based feature fusion for FER图4 基于VGG-NET 的特征融合FER 方法
基于深度学习的方法弥补了传统方法在面部表情特征提取方面的缺点,提升了识别效果,同时也存在着一些问题。基于深度学习的方法需要大量的样本来进行模型的训练,以训练出稳定、可靠的面部表情识别模型。但是目前的面部表情数据集中的图像数量较少,在对模型训练时可能会存在过拟合的现象。为了减轻过拟合问题,研究者对扩充FER 数据库进行了研究。文献[22]提出一种基于cBEGAN(conditional boundary equilibrium generative adversarial networks)的数据扩充方法,这种方法收敛速度快,并且可以通过添加辅助条件标签信息来控制生成数据的类别。图5 为cBEGAN 模型,其中G、D、Enc、Dec、Rlr和Rlg分别代表生成器、鉴别器、编码器、解码器和两个重建损耗。
数据集中也存在着一些不可避免的问题:一个是在对图像标注时,依赖标注人员的主观判断,可能会出现标记错误的现象;另一个是数据中存在一些模糊的或者有遮挡的图像。用存在问题的数据集进行模型的训练时,可能会使模型在优化的初期就不合逻辑[23]。针对模糊的图像以及错误标签的问题,文献[23]提出一种自修复网络(selfcure network,SCN),该网络为了防止样本的过拟合问题将数据集中的样本进行排序正则化加权。在排名最低的组中通过重标记机制改变这些样本标签来对错误标签进行修改。
由于文化背景以及采集条件的不同,数据集中的数据可能会产生明显的偏差,文献[24]深入研究了这种偏差,首次探索了数据集差异的内在原因,提出了深层情感适应网络(emotion-conditional adaption network,ECAN),该方法可以同时匹配域间的边缘分布和条件分布,并且通过一个可学习的重加权参数来解决被广泛忽视的表达式类分布偏差。由于数据集中的数据较少,以及数据集中的问题,有些研究者提出用迁移学习的方法来弥补FER 数据集少的缺点,但是迁移学习也会产生一些冗余信息。文献[25]基于面部肌肉运动产生面部表情变化的原理,提出了一种新的端到端的深度网络框架以解决此问题。
2.2 基于文本的情感分析
文本情感分析是指从文本中提取可以表达观点、情感的信息。文本情感分析的应用有很多,包括获取用户满意度信息、根据用户情绪推荐产品、预测情绪等。涉及人工智能、机器学习、数据挖掘、自然语言处理等多个研究领域。文献[26]将文本情感分析分为两部分:第一部分是观点挖掘,处理意见的表达;第二部分是情感挖掘,关注情感的表达。观点挖掘更关注的是文本中表达的观点的概念,这些观点可以是积极的、消极的,也可以是中性的,而情感挖掘则是研究反映在文本中的情绪(如快乐、悲伤等)。
在文本情感分析中,情感信息抽取是最重要的部分。情感信息抽取的效果直接影响文本情感分析的效果。情感信息的抽取就是对文本中情感词的抽取,情感词汇可以分为三种类型:(1)只包含情感词的词汇(单词列表);(2)由情感词和极性取向构成的词汇(只有正负注释的单词列表);(3)具有方向和强度的情感词[27]。
随着对文本情感分析研究的深入以及大量带有情感色彩的文本信息的出现,研究者从刚开始对情感词进行分析逐渐转变到句子以及篇章级别的研究。目前,基于情感词典和深度学习的方法是文本情感分析的两种主要方法。
2.2.1 基于情感词典的方法

Fig.5 cBEGAN model图5 cBEGAN 模型
基于情感词典的方法首先对情感词进行抽取,然后根据情感词典中包含的单词及相关词汇的情感极性来进行情感估计[28]。常用词典包括WordNet、GI(general inquirer)词典等。基于情感词典的方法在识别中具有简单且识别速度快的特点,但同时也存在一些不可能避免的缺点。一个缺点就是这种方法比较依赖情感词的个数,另一个就是有一些词语一词多义,在识别时可能会造成误判。为了增加情感词典跨领域的适应性,文献[27]利用分布式语义的概念,提出了一种将语义相似度与嵌入表示相结合的情感分类模型,该方法通过计算输入词与词汇之间的语义相似度来提取文本的特征,有效地解决了情感词典中词汇覆盖率和领域适应方面的局限性。文献[29]提出了一种基于多源数据融合的方面级情感分析方法,该方法可以从不同类型的资源中积累情感知识,并且利用BERT(bidirectional encoder representation from transformers)来生成用于情感分析的方面特定的句子表示来使模型能够做出更准确的预测。
2.2.2 基于传统机器学习的方法
在文本情感分析领域中,传统的机器学习方法也广泛用于建立情感分析模型,这些方法首先建立一个训练集,并通过情感来标记训练数据,然后从训练数据中提取一组特征,并将其送到分类器模型中进行分析,常用的分类模型有逻辑回归、支持向量机、随机森林、最大熵分类等[30]。2002 年,文献[31]首次将朴素贝叶斯、最大熵分类和SVM 三种机器学习方法用在文本情感分析中,取得了不错的准确度。文献[32]基于多特征组合的方式用SVM 和条件随机场(conditional random field,CRF)分别进行文本情感分析,通过实验表明在选用的特征中情感词对结果的影响最大,程度副词对结果的影响最小,并且还可能降低结果的准确度,同时还表明在相同的特征条件下,CRF 的效果比SVM 好。为了提高机器学习算法在文本情感分析的准确度,文献[33]利用集成学习的方法结合多种分类器来进行情感分析。该文将常用的7 个不同的传统机器学习分类模型用Bagging 和AdaBoost-r 集成在两个不同的数据集上进行交叉验证。实验结果表明用集成学习方法比单一分类器的准确度高,并且在集成学习模型中,Bagging 的表现优于AdaBoost-r。
2.2.3 基于深度学习的方法
基于深度学习对文本进行情感分析的原理是将提取后的文本特征由计算机根据某种算法进行处理,然后对其分类。由于CNN 在文本挖掘和NLP 任务方面表现出了良好的适应性,研究人员用CNN 进行了一系列实验,证明CNN 在句子级的情感分析任务上表现出了良好的性能。受此启发,文献[34]提出了一种基于CNN 的文本分类模型,通过使用二维TFIDF(term frequency-inverse document frequency)特征代替预先训练的方法,得到了较好的识别准确度,图6 为该模型的基本结构。由于在文本情感分析中文本词向量作为特征对CNN 进行训练时无法充分利用其情感特征等问题,文献[35]提出了一种基于多通道卷积神经网络(multi-channels convolutional neural networks,MCCNN)的中文微博情感分析模型,该模型可以通过多方面信息学习不同输入特征之间的联系,挖掘出更多的隐藏特征信息。该模型在多个数据集上进行实验,都取得了良好的效果。

Fig.6 Text classification model based on convolutional neural network图6 卷积神经网络的文本分类模型
由于现有文本情感分析算法中网络输入单一,同时缺乏考虑相似文本实例对整体分类效果的影响,文献[36]提出一种融合CNN 和注意力的评论文本情感分析模型。在文本情感分析中,人们常常会忽略词语和上下文之间的关系,进而影响情感分析的准确度。文献[37]提出一种基于BGRU(bidirectional gated recurrent unit)深度神经的中文情感分析方法,该方法通过BGRU 对文本信息的上下文提取进行分析,通过实验表明,加入上下文信息后可以有效提高准确度。文献[38]提出了一个CNN 和RNN 的联合架构,该方法利用CNN 生成的粗粒度局部特征作为RNN 的输入来对短文本进行情感分析。神经网络模型在自然语言处理中非常强大,但该模型有两个主要缺点:训练数据集较小时,该模型可能会过拟合;当类别数较大时,它不能精确地限定类别信息。为了解决这两个缺点,文献[39]提出了一种文本生成新模型CS-GAN(category sentence generative adversarial network),它是RNN、生成对抗网络(generative adversarial networks,GAN)和强化学习(reinforcement learning,RL)的集合。该方法不仅可以通过CS-GAN扩展任何给定的数据集,还可以直接用GAN 学习句子结构,提高该模型在不同数据集上的泛化能力。
2.3 基于语音的情感分析
在日常生活中,以语音进行交流是必不可少的方式之一。语音中含有丰富的情感信息,不仅仅只是文本信息,还包括音调、韵律等可以显示情感的特征。近年来,利用多媒体计算机系统研究语音中的情感信息越来越受到研究者的重视,分析情感特征、判断和模拟说话人的喜怒哀乐成为一个意义重大的研究课题。在现有的文献中,基于语音的情感分析研究大部分集中在识别一些声学特征,如韵律特征、音质特征和谱特征。目前主要分为基于传统机器学习的方法和基于深度学习的方法。
2.3.1 基于传统机器学习的方法
在语音情感分析中,有一些研究集中在情感语音数据库的构建、语音特征提取、语音情感识别算法等方面。现有成果中,传统的情感识别的主要方法有SVM、K最近邻(K-nearest neighbor,KNN)、HMM[40]、高斯混合模型(Gaussian mixture model,GMM)等。如文献[41]通过基于机器学习的PPCA(probability PCA)工具包来提取韵律特征进行情感分析。文献[42]通过使用预先训练的SVM 和线性判断分析(linear discriminant analysis,LDA)分类器将语音情感特征分类输入来完成语音情感分析。
目前仍无法准确地确定各类情感的本质特征由哪些语音情感特征参数决定,理论上说,提取统计的特征参数越详细,情感类型越容易辨识,但实际上必须在大量情感信息中挑选出能准确反映情绪状况的特征参数,才能获得良好的语音情感识别性。通过对声学特征的对比分析,文献[43]结合韵律特征和质量特征导出MFCC(Mel frequency cepstrum coefficient)、LPCC(linear predictive cepstral coefficient)和MEDC(Mel-energy spectrum dynamic coefficient)三种特征来训练SVM 进行情感分析,取得了不错的效果,并且该方法具有较好的鲁棒性。
2.3.2 基于深度学习的方法
随着深度学习的日益发展,其被更多的研究者用于识别语音中的情感分析中。文献[44]利用CNN从音频中提取情感特征,然后将提取到的特征送入分类器进行情感分类识别。在大规模的网络语音数据中进行情感分析一直以来是一个挑战,为解决这个问题,文献[45]提出了一个深度稀疏神经网络(deep sparse neural network,DSNN)模型,该模型提取话语中三方面的特征:声学特征(音调、能量等)、内容信息(如描述性相关和时间相关性)和地理信息(如地理-社会相关性)。然后融合所有的特征来自动预测情感信息。
2.4 小结
本节主要介绍了现有的单模态的情感分析方法。如图7 所示,根据模态不同分别对文献进行叙述。在FER 中,现有算法多用传统方法与深度学习相结合的方法来进行情感分析,在数据集方面用GAN、迁移学习等进行扩充。
在文本情感分析中,由于传统方法中情感词典受情感词数量和个数的限制,大多数研究者使用深度学习中的RNN、LSTM 等模型来进行分析,同时加入注意力机制来提高分析效果;在语音情感分析中,多用深度学习的方法来进行分析,而难以采集到大量包含情感的语音数据是限制对其深入研究的主要因素之一。
由于从单模态中获得的信息量有限,想要进一步提高情感分析的准确度变得十分困难。因此有研究者尝试从多种模态中获取更多的信息进行情感分析来提高准确度。
3 多模态情感分析
用单模态进行情感分析有识别率低、稳定性差等局限性,在情感分析的发展过程中,研究者利用多种模态进行情感分析来提高其准确性以及稳定性。在多模态情感分析中,模态融合的效果会直接影响结果的准确性[46]。因此对单模态的信息处理完成时,还需要根据所用模态的不同以及模态中信息的不同选择适当的模态融合方法。
本章先对近几年的多模态情感分析文献根据模态融合方式的不同进行归纳总结,然后讨论了现有的模态融合算法,最后对文献中出现的算法进行对比分析。
3.1 基于多模态的情感分析

Fig.7 Current research status of monomodal sentiment analysis图7 单模态情感分析研究现状结构框图
在现有的文献中,基于多模态的情感分析除了单模态的特征提取外,还需要进行模态融合。融合不同模态的信息是任何多模态任务的核心问题,它将从不同的单模态中提取到的信息集成一个多模态特征[47]。多种模态信息的融合可以为决策提供更加全面的信息,从而提高决策总体结果的准确度[48]。目前模态融合的方式主要分为特征级融合、决策级融合和混合融合三种。
3.1.1 特征级融合
特征级融合也称早期融合,在进行特征提取后立即集成,通常只是简单连接它们的表示,广泛出现在多模态学习任务中[49]。
在基于特征级融合的文献中,文献[50]建立了首个在话语层面进行注释的MOUD 数据集并且提出了一种基于话语级的情感分析方法。该方法用OpenEAR、CERT 提取语音和面部的情感特征,将视频中出现频率低的单词删除,剩余单词与每个话语转录内频率的值相关联得到简单的加权图特征作为文本情感特征,然后使用特征级融合的方法将三种特征进行融合送入SVM 进行分析得到情感极性。
由于视频中的话语之间存在相互依赖和联系,一些文献在对视频中人物的情感分析过程中利用这种依赖和联系,取得了不错的情感分析效果。文献[51]提出了一种基于LSTM 的情感分析模型,该模型在进行特征提取时分为两部分:第一部分用CNN、3d-CNN 和openSMILE 对文本信息、面部表情信息以及音频进行特征提取;第二部分用bc-LSTM 提取语境话语层面的特征。文献[52]提出了一种多模态神经网络结构,此结构用LSTM 整合了随时间变化的视觉信息,并将其与音频和文本信息通过特征级融合的方式进行情感分析,图8 为该结构的基本框架。文献[53]提出了一种卷积递归多核学习(convolutional recurrent multiple kernel learning,CRMKL)模型。在特征提取时,用openSMILE 提取音频中音高和声音强度;在视频中,为了捕捉时间相关性,将时间t和t+1 的每对连续图像转换成单个图像,作为RNN 的输入,输出为“正”或“负”;在文本中,先将西班牙语转换为英语,用word2vec 字典进行预处理形成300 维的向量作为CNN 的输入来提取特征。在模型中,将提取的特征用基于循环相关的特征子集(correlationbased feature subset selection,CFS)和PCA 进行特征选择降低特征维度,然后用多核学习(multiple kernel learning,MKL)将特征进行特征级融合,最后进行分析得到情感极性。通过实验表明,加入上下文之间的联系进行分析时,可以有效提高情感分析的准确度。

Fig.8 Multi-modal neural network framework for emotion recognition图8 多模态神经网络情感识别框架
由于在用语音特征区分愤怒和开心时准确率过低,文献[54]结合文本和语音来区分愤怒和开心两种情绪。该方法用openSMILE 提取声学特征,用基于词典的方法提取文本特征,然后进行特征级融合,将融合后的结果分别送入SVM 和CNN 中进行对比分析。通过实验证明文本和语音中包含的情感信息进行互补,提高了愤怒和开心的区分准确率。
由于注意力机制和门控循环单元在一些领域取得了不错的效果,在多模态情感分析的研究中,研究者尝试将注意力机制和门控循环单元引入其中进行分析,如文献[55]结合音频和文本进行情感分析,提出了一种多特征融合和多模态融合的新策略(deep feature fusion-audio and text modality fusion,DFFTMF)。在特征提取时,用Librosa 工具包在音频中提取声学特征,用BERT 模型在文本中提取文本特征,然后将其分别输入到改进的Bi-LSTM 和CNN 串行神经网络中,结合注意力机制对情感特征进行改善,分别得到其情感向量,随后用多模态注意力机制和Bi-LSTM 编码器来选择性学习这些输入进行特征级融合,最后用softmax 进行情感分析。此方法在进行模态融合时用多模态注意力机制重点融合来自音频和文本互补的情感信息,减少了特征融合的数量。文献[56]用视频信息和文本信息提出了一种改进的多模态情感分析方法。该方法使用自注意力机制获得视频上下文的相关性,使用交叉注意力机制学习不同模态之间的相互作用,使用交叉相互的门控机制来克服单个模态中存在的噪声,选择性学习融合特征向量,随后使用Bi-GRU 来学习每个模态的深度特征向量,最后将每个模态的深度多模态特征向量连接用softmax 进行情感分析。
文献[57]利用图像的深度语义信息提出了一种深度语义以及多主体网络,从图像中提取包括对象和场景在内的深度语义特征作为情感分析的附加信息。在视觉信息中,分别选用VGG 模型和Scene-VGG 模型在ImageNet 以及dataset-Place365 数据集上进行预训练,然后采用迁移学习来克服数据集之间的类别差异,将学习到的参数转移到情感分析任务中,来获得视觉特征以及场景特征。在文本信息中,引入注意力机制和LSTM 模型提取文本特征。
由于大多数现有的任务方法在进行情感分析时主要依赖文本内容,而没有考虑其他重要的模态信息,基于此问题,文献[58]提出了一种用于实体级多模态情感分类的实体敏感注意和融合网络。在文本特征中,将文本分为左上下文、右上下文和目标实体三部分,用三个LSTM 获得其上下文信息以及情感特征;在视觉特征中,用残差网络(ResNet)来提取视觉特征并用注意力机制来获得其每部分的权重信息,然后加入门控循环单元(gate recurrent unit,GRU)来滤除图像噪声,最后通过特征级别融合的方式将两种模态的特征融合后送入softmax 中进行情感分析。虽然此方式在几个评论数据集上都取得了较好的效果,但是其网络结构较为复杂,运行时间较长。
3.1.2 决策级融合
决策级融合也称后期融合。在这个融合过程中,每个模态的特征被独立地分析,将分析结果融合为决策向量以获得最终的决策结果。决策级融合的优点是当任何一个模态缺失时,可以通过使用其他模态来做出决策,这时需要一个智能系统来检测缺失的模态。由于在分析任务中使用了不同的分类器,在决策级融合阶段,所有这些分类器的学习过程都变得繁琐而耗时[3]。
在基于决策级融合的方式中,部分文献仅用单模态提取的特征进行情感分析。文献[59]提出了一种基于深度CNN的微博视觉和文本的情感分析方法,在该方法中,用CNN 和DNN 分别对文本信息和视觉信息进行情感分析,最后用平均策略和权重对两种模态的分析结果进行融合。由于中文微博数据集较小,在构建DNN 模型时加入DropConnect 防止过拟合。文献[60]使用文本、视频和音频三种模态提出了一种擅长于异构数据的基于深层CNN 的特征提取方法。该方法在文本特征提取时,用CNN 对其情感特征进行提取;在面部特征提取时,将视频逐帧剪辑获取静态图像,然后从静态图像中提取面部特征点;在音频特征中,用openSMILE 软件来提取与音调、声音强度相关的音频特征,最后将所提取的特征送入单独的分类器中进行分析,将结果在决策级进行可并行化的融合。该文和文献[53]都用基于循环相关和主成分分析来减少特征分析时的数量。特征选择虽然加快了情感分析的速度,但同时可能丢失较为重要的细节情感特征信息,对结果产生负面影响。
由于多模态情感分析数据集较少,且注释的数据集中的示例较少,在情感分析模型训练时,得到的结果可能会与人物的身份特征相关联。为了解决此类问题,文献[61]提出了一个选择加性(select-additive learning,SAL)学习程序来改善神经网络在多模态情感分析中的泛化能力。SAL 程序一共分为选择阶段和添加阶段两部分。在选择阶段,SAL 从神经网络学习的潜在表征中识别混杂因素。在加法阶段,SAL通过在这些表示中添加高斯噪声,迫使原始模型丢弃混杂元素。将文献[44]中的情感分析方法用SAL增加其泛化能力和预测情绪后得到SAL-CNN,通过实验证明,SAL-CNN 在有限数据集上得到了不错的效果,并且该方法在不同的数据集上进行测试时,也获得了良好的预测精度。
文献[62]介绍了一种新的损失函数的回归模型,称为SDL(speaker-distribution loss),提出了一个时间选择性注意的模型(temporally selective attention model,TSAM),该模型由注意力模块、编码模块和说话人分布损失函数三部分组成。注意力机制通过明确分配注意权重来帮助模型选择显著的时间步长,在注意力模块用LSTM 对序列进行预处理,编码阶段用Bi-LSTM 对序列观测值进行编码并加权组合作为该模块的输出,最后送到SDL 中进行情感分析。在模态的特征提取中,用openFace 提取面部外观特征,用协同语音分析库技术(collaborative voice analysis repository technologies,COVAREP)提取声学特征,文本用Glove得到词向量。通过实验表明,加入注意力机制之后的模型能够关注以人为中心的视频序列的显著部分,并且取得了不错的效果。
3.1.3 混合融合
混合融合是特征级融合和决策级融合方法的结合。这种融合方法结合了特征级融合和决策级融合的优点,同时模型复杂度和实现难度也随之增加。
由于注意力机制和GRU 在情感分析中表现出较好的性能,文献[63]提出了一种带有时间注意门控的多模态嵌入LSTM 模型,该模型在单词级上进行融合,并且可以关注到最重要的时间帧,解决了“在每一时刻要寻找什么样的情况”和“在交流中什么时候说话最重要”这两个关键问题。在本文中,首次提出了一个注意层和一个强化学习训练的输入门控制器来解决模态中的噪声问题。文献[64]提出了一种端到端的RNN 模型用来对情感进行分析。此模型可以捕捉所有模态对话上下文、听者和说话者情绪状态之间的依赖性以及可用模态之间的相关性。在结构上,使用两种门控循环单元sGRU 和cGRU 来为对话者的状态和情感建模。除此之外,使用一个互连的上下文网络来学习上下文表示,并且使用成对的注意力机制来对每种模态的有用信息进行简单的表示。此文通过实验表明成对的注意力在多模态数据上具有最先进的性能。
文献[65]和文献[66]引入了几种不常用的模态进行情感分析。文献[65]基于面部表情、皮肤电反应和脑电图提出了一种基于混合融合的多模态情感分析系统,图9为其结构框图。该系统用8 898张图片训练得到CNNF模型,输出为7 个离散情感类别的概率向量。CNNV和CNNA由脑电图和皮肤电反应(galvanic skin response,GSR)模态的网络进行训练得到。加权单元分别计算CNNV和CNNA输出的化合价和唤醒的加权和,然后将其送到距离计算器计算情感距离,最后将情感距离送到决策树,与CNNF得到的结果进行融合得到情感状态。文献[66]结合视频中的面部表情和姿态提出一种基于视觉的多模态情感分析框架,从视频序列中自动识别面部表情和上身手势特征进行特征级融合,随后将分析结果用乘积和加权的方法进行决策级融合得出结果。由于多模态情感分析的数据集较少,该篇文章所用的数据集是自建的一个面部表情和姿态的视频数据库。
3.2 模态融合相关算法
由于多模态技术的发展,模态融合技术也受到了研究者的广泛关注。在模态融合技术发展的初期,大多数研究者都是使用基于机器学习的方法训练模态的分类器,如SVM、Logistic 回归、K-近邻分类器等,还有一些研究者使用基于规则的方法,如线性加权和多数表决等[67]。随着深度学习的发展,研究者将深度学习的方法引入到模态融合中。近年来提出了一些经典的模态融合方法如下:
一些研究者将注意力机制和GRU 引入模态融合中,通过注意力机制来获得模态的特征向量的权重。文献[68]提出了一种融合抽取模型(fusion-extraction network,FENet)。该模型用一种细粒度的注意力机制来交互学习视觉和文本信息的跨模态融合表示向量,可以融合两种单一模态中对情感最有用的信息。在该方法中引入门控机制调节多模态特征融合时的权重以进行情感分析。文献[69]提出了一种基于双向门控递归单元模型获取话语间的上下文关系的信息增强融合算法框架,通过CT-BiLSTM(contextual-based bi-directional long short-term memory)获取文本、音频和视频的上下文相关的单模态特征,然后用AT-BiGRU(attention-based bi-directional gated recurrent unit)模型来放大与目标话语高度相关的上下文信息。此算法可以优先选择对情感分析有较大影响的模态,能够增强对目标话语正确分类结果影响较大的情感信息。

Fig.9 Cross-subject multi-modal emotion recognition based on hybrid fusion图9 基于混合融合的跨主体多模态情感识别
也有一些研究者将张量引入模态融合中计算模态间的交互作用,如文献[70]提出了一种张量融合网络(tensor fusion network,TFN)新模型,可以端到端地学习模态内和模态间的动态特性,它明确地聚合了单模态、双模态和三种模态的相互作用。通过三种模态嵌入子网络分别对语言、视觉和声学模态进行模态内动力学建模。文献[71]将张量的方法和一些神经网络结合起来提出了一种深度高阶序列融合网络(deep higher order sequence fusion,Deep-HOSeq),通过从多模态时间序列中提取两种对比信息进行多模态融合。第一种是模态间信息和模态内信息的融合,第二种是多模态交互的时间粒度信息。该网络用LSTM 从每个单模态中获得模态内信息,然后将每个模态内信息合并为多模态张量,取其外积。另一方面利用前馈层从每个单模态中获得潜在特征,然后在每个时间步骤中获得模态内的作用,用卷积层和全连接层进行特征提取,最后通过池化操作统一来自所有时态步骤的信息。在获得这两种信息后与一个融合层相结合来进行情感分析。
在处理模态融合时,保持单模态神经网络的性能是至关重要的,基于此观点文献[72]提出了一种多层的多模态融合方法,该方法引入了一个特定的神经网络称为中央网络,该中央网络不仅可以将不同的特征联合起来,而且通过使用多任务学习来规范各个模态的网络。此融合方法可以通过将相应的单模态网络层和其前一层的加权和作为每个层的输入。中央网络的优点为中央网络的损失函数不仅允许学习如何组合不同的模态,而且还增加了对特定模态的网络的限制,从而增强了模态间的互补性。文献[73]用分层的方式对模态信息进行融合,在该方法中引入RNN 和GRU 分别用来获取周围话语信息以提高特征向量的质量和对上下文信息进行建模。
3.3 不同算法对比
为了得到影响情感分析准确率的因素,本节将前文中对视频信息进行情感分析所提到的算法进行对比研究,对比结果如表3~表6 所示。以下表中的评价指标都为Accuracy,并且表中的模态信息A、V、T分别代表Audio、Video、Text。

Table 3 Accuracy comparison of single-modal sentiment analysis表3 单模态的情感分析Accuracy 比较 %

Table 4 Accuracy comparison of different algorithms on MOSI dataset表4 MOSI数据集上不同算法Accuracy 比较 %

Table 5 Accuracy comparison of different algorithms on MOUD dataset表5 MOUD 数据集上不同算法Accuracy 比较 %
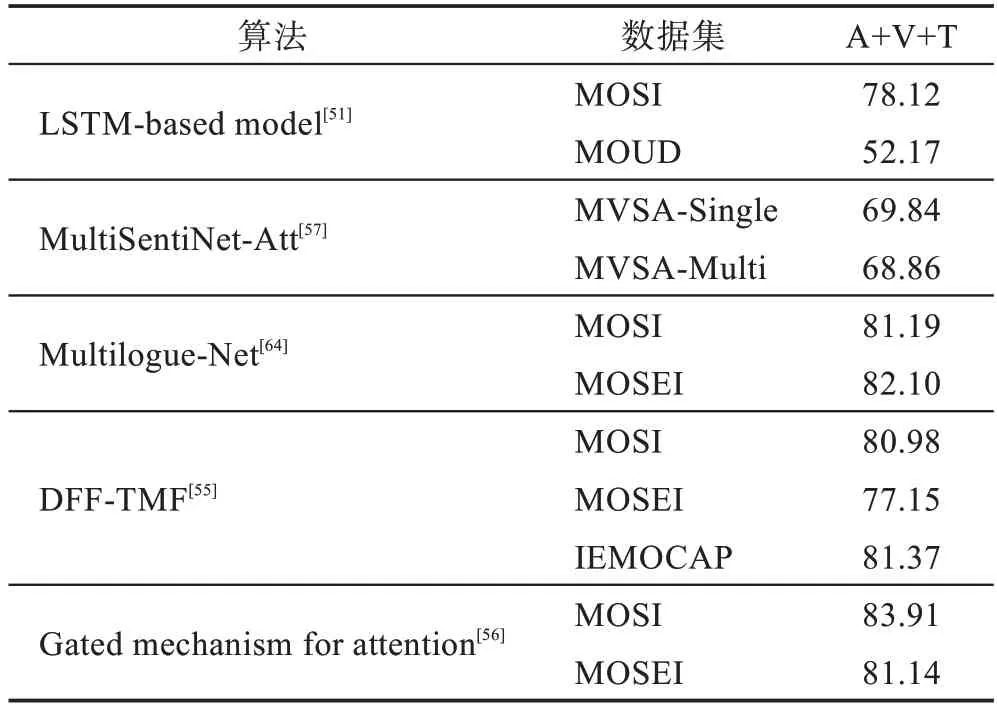
Table 6 Accuracy comparison of same algorithm on different datasets表6 相同算法在不同数据集上Accuracy 比较 %
通过表3 可以看出,大多数算法用T+V 和T+A进行情感分析时的准确率都要高于V+A,说明在基于多模态的情感分析中,文本信息仍然是重要的情感线索。
通过表4 可得,在MOSI 数据集上用三种模态进行情感分析时,Gated mechanism for attention 算法的准确率最高,说明门控单元在模态选择时的重要性。此外,对每种模态的特征进行除噪也可以提高准确率。其次,Multilogue-Net 和DFF-TMF 这两种算法的准确率也较高,可以看出注意力机制以及模态间的相关性在提高准确率方面也有重要的价值。
通过表5 可得,在MOUD 数据集上用三种模态进行情感分析时,CRMKL 算法的准确率最高,说明视频中上下文的信息、文本信息的预处理以及模态融合的选择对提高准确率很有帮助。
通过表6 可得,大多数算法在不同数据集上的鲁棒性较好。LSTM-based model 方法在不同数据集上的准确度相差较大,产生这种效果的原因是模型用MOSI 训练,MOSI 是英语,而MOUD 是西班牙语,语言不同,因而情感表达方式不同,分析方式也不同。
通过表3~表5 中相同的算法进行对比可以看出,用三种模态进行情感分析的准确率高于用两种和一种模态方法的准确率,说明结合多种模态信息进行情感分析的必要性。
3.4 小结
本节主要对现有的多模态情感分析技术以及模态融合技术进行了总结。在多模态情感分析技术中,部分文献仅在单模态的特征提取上进行改进提高准确度,而忽略了视频序列中的上下文信息,导致对不同模态的特征挖掘不充分。随着研究的深入,研究者引入RNN、LSTM、GRU 等网络提取上下文信息进而提高情感分析准确度,但处理长时间的序列容易出现信息丢失问题。现阶段可以考虑用多层级GRU编码上下文信息解决长时间依赖问题,从而获得更为全面的情感信息。
在模态融合技术方面,研究者利用多层融合的方法来进行模态融合,这种方法可以提高单模态特征向量的质量,在数据较大的情况下可以获得较好的效果,但在小样本中可能导致过拟合问题。由于注意力机制在模态融合中寻找最优权值时具有重要的作用,张量可以将所有模态的特征投影到同一空间获得一个联合表征空间,易于计算模态间的交互作用,近年来主流的模态融合方法是基于注意力机制的方法和基于张量的方法。
4 总结和展望
随着深度学习和一些融合算法的兴起,多模态情感分析技术得到了快速的发展,本文通过对多模态情感分析研究现状的认识,总结出其面临的挑战与发展趋势如下:
(1)多模态情感分析数据集。在多模态情感分析中,数据采集时的花费以及如何在人们自然表达问题的情况下进行数据的采集是目前存在的主要问题之一。数据集较少且多是由视觉、文本和语音三种模态组成,缺少姿态、脑电波等模态数据。因此需要高质量且规模较大的数据集来提高情感分析的准确度。
(2)单模态情感分析。在FER 中,一方面是不同的数据之间存在一定的差异性,由于不同的采集条件和注释的主观性,数据偏差和注释不一致在不同的数据集中非常常见。另一方面是对一些表情识别不准确,在对高兴、伤心等表情识别时很容易,但在捕获令人反感、愤怒和其他较不常见的表情信息时非常具有挑战性;在基于文本信息的情感分析中,由于不同领域的情感表达差别较大,导致情感词典的构建较难。在含有许多隐喻、反话等复杂的语言形式中进行情感分析得到的效果并不理想,因此如何提取对情感分析具有更大价值的特征依然是一个有待完善的课题;除此之外,情感分析技术在语音、姿态等一些模态中的不成熟制约了多模态情感分析技术的发展。
(3)模态间相关性。从不同模态中提取的特征之间存在一定的相关性,在现有的模态融合算法中,常常会忽略不同特征间的相关性,因此如何有效利用模态间的相关性来提高情感分析的准确度是未来的研究方向之一。
(4)算法复杂度。在进行多模态情感分析时,模态过多会提高融合算法的复杂度,模态过少会影响结果的准确性,因此如何选择最佳的模态进行融合也是一个急需解决的问题。
(5)模态融合时模态的权值问题。在模态融合时,不同环境中不同模态的最优权值分配是影响情感分析结果的重要因素之一。在完成不同分析任务时,不同的模态对分析结果的影响不同,因此如何将对分析结果影响最大的模态赋予较大的权值是接下来模态融合的重点方向之一。
5 结束语
本文对多模态的情感分析领域的现有研究成果进行了总结,介绍了常用的多模态情感分析数据集;然后将近几年中单模态的情感分析技术的文献根据面部表情信息、文本信息以及语音信息进行分类叙述;随后对多模态的情感分析技术的文献进行总结,并且对现有的模态融合技术进行了详细的描述;最后对情感分析中存在的问题进行了讨论。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车工程师(2021年12期)2022-01-17
速读·下旬(2021年11期)2021-10-12
大东方(2019年12期)2019-10-20
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
成长·读写月刊(2018年8期)2018-08-30
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
电影新作(2014年1期)2014-02-27
