
基于数据挖掘的汽油精制过程辛烷值损失预测模型
2021-07-27 06:44李东超
科技创新导报 2021年5期
李东超


摘 要:汽油精制过程中造成的辛烷值损失会降低汽油的燃烧效率,如何降低汽油精制过程中辛烷值的损失量是目前相关企业面临的一个重要课题。本文利用我国某石化企业在催化裂化汽油精制过程中积累的数据,建立基于神经网络、测量误差模型以及DC-SIS数据降维方法的两阶段特征筛选模型,选择出对辛烷值影响比较大的因素。设计了一种基于XGBoost和神经网络的辛烷值预测模型,可以实现对不同原材料和不同操作下精制后辛烷值的预测,经验证,模型的均方误差为0.06876,所设计模型在处理辛烷值预测问题时可以达到比较好的预测效果。
关键词:辛烷值 高维降维 测量误差模型 神经网络 XGBoost
中图分类号:TP274 文献标识码:A 文章编号:1674-098X(2021)02(b)-0092-05
Prediction Model of Octane Number Loss in Gasoline Refining Process Based on Data Mining
LI Dongchao
(School of Mathematics and Statistics, Nanjing University of Information Science & Technology, Nanjing, Jiangsu Province, 210044 China)
Abstract: The loss of octane number in the process of gasoline refining will reduce the combustion efficiency of gasoline. How to reduce the loss of octane number in the process of gasoline refining is an important issue facing related enterprises. This paper uses the data accumulated by a petrochemical enterprise during the refining process of catalytic cracking gasoline to establish a two-stage feature screening model based on neural network, measurement error model and DC-SIS data dimensionality reduction method, and select the one that has a greater impact on the octane number factor. An octane number prediction model based on XGBoost and neural network is designed, which can predict the octane number after refining under different raw materials and different operations. After verification, the mean square error of the model is 0.06876. A better prediction effect can be achieved in the alkane number prediction problem.
Key Words: Octane number; High dimensionality reduction; Neural networks; XGBoost
汽油是小型車辆的主要燃料,汽油燃烧产生的尾气排放对大气环境有重要影响。降低汽油中的硫、烯烃含量,同时尽量保持其辛烷值是汽油清洁化重点。我国原油对外依存度超过70%,且大部分是中东地区的含硫和高硫原油。原油中的重油通常占比40%~60%,这部分重油(以硫为代表的杂质含量也高)难以直接利用。为了有效利用重油资源,我国大力发展了以催化裂化为核心的重油轻质化工艺技术,将重油转化为汽油、柴油和低碳烯烃,超过70% 的汽油是由催化裂化生产得到,因此成品汽油中95% 以上的硫和烯烃来自催化裂化汽油。故必须对催化裂化汽油进行精制处理,以满足对汽油质量要求。辛烷值(以RON 表示)是反映汽油燃烧性能的最重要指标。在进行精制处理时,应该尽可能减小辛烷值的损失,以保证汽油的燃烧性能[1-2]。
本文尝试从数据挖掘的角度出发,基于我国某石化企业在催化裂化汽油精制过程中积累的数据,对应影响辛烷值的因素进行了探索,并利用XGBoost模型建立了辛烷值的预测模型。
1 数据来源以及数据预处理
本文分析所用的数据来自于我国某石化企业催化裂化汽油精制脱硫装置在多年运行中积累的操作数据。获取的数据中包含325个样本,每个样本包括7个原料性质、2个待生吸附剂性质、2个再生吸附剂性质、2个产品性质等13个属性变量以及另外354个操作变量,共计367个变量。而响应变量则为精制过程中辛烷值的损失量。
原始数据中,大部分变量数据正常,但每套装置的数据均有部分变量存在问题:部分变量只含有部分时间段的数据,部分变量的数据全部为空值或部分数据为空值。这些数据缺失、不合理/异常的情况需要进行包括数据填补、删除变量、异常值提出等数据预处理。具体的处理方式如下:
(1)对于只含有部分时间点的变量,部分缺失,则填补缺失值,如果缺失较多可将此类变量删除;
(2)对于样本中数据全部为空值的变量,将此类变量删除;
(3)对于部分数据为空值的变量,空值处用其前后两个小时数据的平均值代替;
(4)对于部分不在范围内的样本,可根据操作要求及经验总结出原始数据变量的操作范围,采用最大最小的限幅方法将其剔除;
(5)对于异常值的处理,可根据拉依达准则(3准则)去除异常值。
2 变量筛选
由于炼油工艺过程的复杂性以及设备的多样性,需要操作的变量较多且各个变量之间具有高度非线性和相互强耦联的关系[3]。这就导致这些变量之间是存在冗余信息的,在进行预测时引入这些存在冗余的变量,不仅会增大训练的成本,也有可能导致模型过拟合,甚至导致一些模型无法正常构建(如多重共线性问题)。因此为了减少过拟合、减少特征数量(降维)、提高模型泛化能力,也为了使模型获得更好的解释性,在建模之前需要首先进行特征筛选处理。
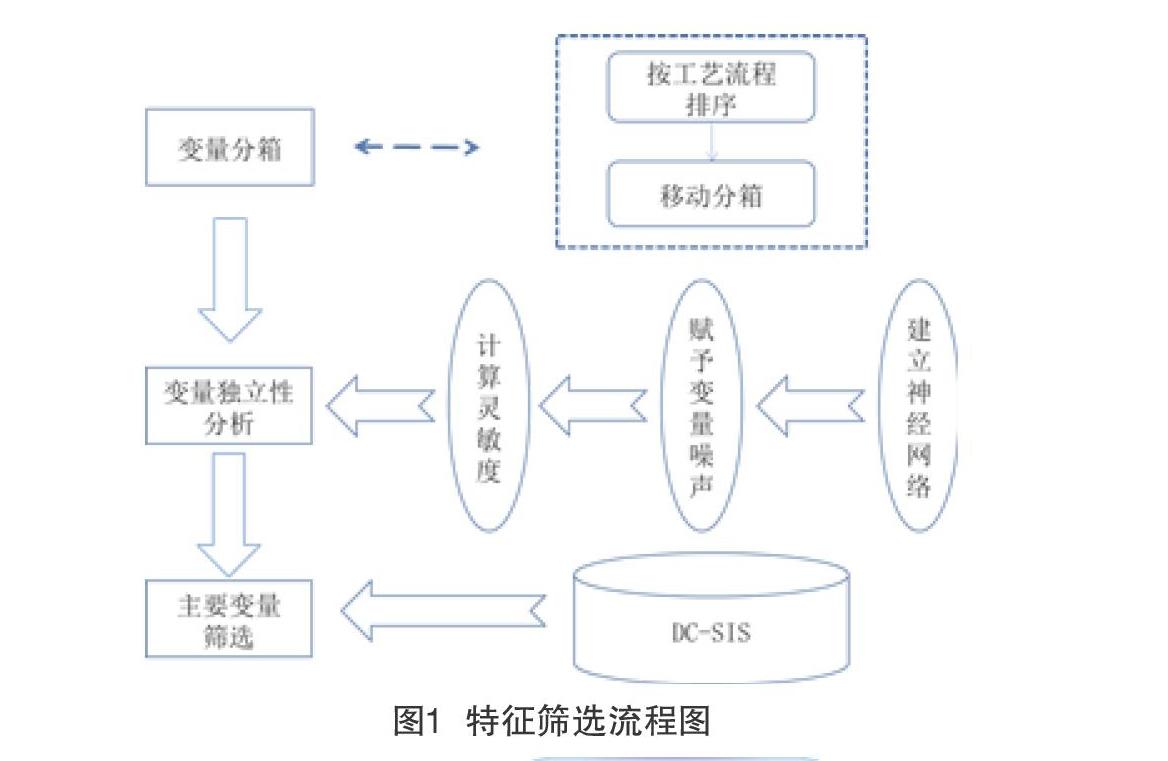
在进行特征筛选时,一个必须坚持的原则就是尽可能充分的挖掘出特征之间的相互关系,这种相互关系可能是线性关系,也可能是非线性的关系。一般的,线性关系是比较容易识别出来的,而非线性关系则相对比较难以识别。因此本文将神经网络模型和测量误差模型结合起来,并采用两阶段处理的思路,创建了一种新的特征筛选的方法。该算法的基本流程如图1所示。下面对该算法的细节进行介绍。
一般情况下,在进行工业操作时,比较接近的工业操作往往是存在一定的非线性和相互强耦联的关系的,因此本文在筛选变量的第一阶段先对相邻变量间的相互关系进行探索。具体地,首先对数据中的所有变量按照工业操作顺序进行排序处理,得到排序后的变量数据集为,其中P为数据集中变量的总个数。然后,再采用滑动分箱的手段将这P个变量分为 个“箱子”。滑动分箱的细节为:
对于第i个变量X1,我们选中其前后各K个变量作为第i个箱体bini中的变量。对每个变量执行上面的操作,可以得到分箱后的箱体集合为,其中值得注意的是,对于靠近边界处的变量,其某一侧变量的个数可能不足K个,则按不足 K个变量选择。
完成对变量的分箱之后,下面对每个箱体内部变量之间的相关性进行探索。考虑变量之间的关系可能不是简单的线性关系,本文利用神经网络模型在拟合非线性关系上的优异表现,设计了一种基于神经网络的测量误差变量筛选模型[4-5],模型的基本思路见图2。
对于第i个箱体bini,我们选择变量k作为中心变量,为协变量,拟合变量与xi之间的神经网络模型NNi,得到预测结果 。
接下来,根据测量误差模型的思路,如果协变量结合中的变量Xj与Xi之间存在强耦合关系,那么当我们给Xj加上一个比较小的误差时,在利用神经网络模型NMi对预测时,预测的结果应该会发生比较大的变化,相反的,如果两者的相互关系比较弱时,那么预测的结果应该不会发生比较大的变化。我们分别逐次给协变量集合中的每个变量加上一个比较小的误差,然后将加上误差的协变量集合带到模型NMi中,得到对Xi结果预测结果。得到预测结果后,为了衡量加上误差后预测结果的变动程度,我们设计了一个灵敏度指标这个指标的取值越大说明对应变量对中心变量 的影响程度越大,即可以认为两个变量的耦合关系越强。我们给定阈值Wesholol,选择灵敏度小于阈值对应的变量,便可以对箱体Bini内的变量进行降维处理。
对每个箱体进行相同的处理,然后将得到的所有变量合并去重组合在一起,便可以完成第一阶段的降维处理。
第二阶段的特征降维主要是利用DC-SIS算法[6-7]对第一阶段的结果再次进行降维处理。DC-SIS即基于距离系数的特征筛选方法,该方法通过定义特征与响应变量之间的距离相关系数来衡量变量的重要程度,具体地,对于随机变量u和v,他们之间的距离相关系数定义为
其中,和表示随机变量u和v的特征向量,表示它们的联合特征函数,du和dv表示随机向量u和v的维数,而,该式中,则表示的欧式范数。
按照上述方式定义距离相关系数的优势在于,两个随机向量的距离相关系数为0当且仅当它们相互独立.此外,两个一元正态随机变量的距离相关系数则随着它们之间的皮尔逊相关系数的绝对值严格递增。同时,该特征筛选方法能够直接用来处理分组变量以及多维因变量的筛选过程,也不需要预先假定变量与因变量之间的模型框架,所以可以称得上是完全无模型方法,适合用于处理本问题中非线性特征重要性的分析。
根据上面的定义,只需要通过对距离相关系数进行估计与排序,便可以计算出各个变量的重要性了。
对汽油精制过程按照前述三步两阶段的方法进行处理,可以得到汽油精制过程中重要的特征有19个,如表1所示。
根据表1可以发现,对辛烷值损失量影响比较大的特征中除了一些操作变量之外,还有一些原材料属性变量,如辛烷值、硫含量、饱和烃、烯烃。这与一般的认知是相符的,在进行精制时,辛烷值的损失量不仅取决于操作技术的水平,还取决于原材料的原始属性。
3 基于XGBoost和神经网络的辛烷值损失预测
XGBoost模型是Boosting 算法的一种。该算法思想就是不断地添加树,并通过特征分裂来生长一棵树,每添加一棵树就是学习一个新函数,去拟合上一步预测的残差。通过不断的迭代学习,最终实现对目标变量的预测。
尽管XGBoost模型作為一个机器学习模型有很好的表现,但是考虑到树模型在处理回归问题时仍存在一定的局限性,因此本文将XGBoost模型与神经网络模型进行了融合,首先利用XGBoost模型进行训练并计算残差,然后再利用神经网络模型对XGBoost模型的预测残差进行拟合,以便达到一个比较好的预测效果,即辛烷值损失量的预测值为,其中表示XGBoost模型的预测结果,表示神经网络对参加的进一步拟合结果。接下来将对具体解决问题的过程进行说明。
在本文要解决的问题中,由于炼油工艺过程的复杂性以及设备的多样性,操作变量众多,且变量间具有高度非线性和相互强耦联的关系,不利于分析并发现模型的主要变量和因素。这里选择经过数据预处理和建模变量筛选后的19个具有代表性的主要变量来作为训练辛烷值损失预测模型的解释变量,经过前面的特征选择方法,认为这19个变量可以比较充分的反应原始变量中的信息。而响应变量则为辛烷值的损失量。
在训练模型时,本文首先在原始的325个样本中随机选择70%的样本数据作为训练集,用以训练模型,确定XGBoost模型和BP神经网络模型的参数。而另外30%的样本数据则作为测试集,用来测试模型的预测效果如何。
经过测试,该模型对汽油精制过程中辛烷值损失量的预测效果是比较好的,模型的MSE(均方误差)为0.06876。具体的预测效果如下图所示:
由图3-1可以看出,经过精制处理后真实的辛烷值与预测的辛烷值是比较吻合的,这证明基于XGBoost和神经网络的辛烷值损失预测算法在预测辛烷值的损失情况时是有一定的可参考性,我们可以利用该模型来对不同的原材料和处理工艺进行分析,以便针对不同质量水平的原材料设计不同的精制工艺。
4 总结
本文为了预测汽油精制过程的辛烷损失情况,利用我国某石化企业在催化裂化汽油精制过程中积累的数据,对精制过程中影响辛烷值损失量的因素进行了探索,设计了一种基于神经网络、测量误差模型以及的DC-SIS数据降维方法的两阶段特征筛选模型,可以在较多的操作变量中选择出对辛烷值影响比较大的因素,进一步地,本文设计了一种基于XGBoost和神经网络的辛烷值预测模型,可以实现对不同原材料和不同操作下精制后辛烷值的预测,这有利于相关工作人员根据不同的原料选择不同的操作方法来减少辛烷值的损失量,经过验证,模型的均方误差为0.06876,相对较小,说明该模型是有一定的实用价值的。
参考文献
[1] 鲍树海.炼油化工企业催化汽油加氢工艺技术[J].化学工程与装备,2020(10):25-26.
[2] 赵鹏,焦峰,郭良,赵娟.降低催化裂化汽油烯烃含量的操作手段及优化方向[J].中外能源,2019,24(07):74-78.
[3] 张大齐.催化裂化汽油中轻汽油脱硫的研究[D].武汉工程大学,2016.
[4] Jae Kwon Kim, Sanggil Kang. Neural Network-Based Coronary Heart Disease Risk Prediction Using Feature Correlation Analysis[J]. Journal of Healthcare Engineering, 2017, Article ID 2780501, 13 pages.
[5] White, K. R., Stefanski, L. A., and Wu, Y. Variable Selection in Kernel Regression Using Measurement Error Selection Likelihoods[J]. Journal of the American Statistical Association, 2017, 112, 1587–1597.
[6] Li, R., Zhong, W. and Zhu, L.Feature Screening via Distance Correlation Learning. Journal of American Statistical Association,2012,107, 1129-1139.
[7] 連亦旻.超高维特征筛选方法SEVIS及其应用[D]. 中国科学技术大学, 2017.
猜你喜欢
山西化工(2020年3期)2020-02-20
石油炼制与化工(2020年9期)2020-01-05
电子制作(2019年19期)2019-11-23
石油学报(石油加工)(2017年1期)2017-02-08
汽车文摘(2016年8期)2016-12-07
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
电测与仪表(2014年20期)2014-04-04
电测与仪表(2014年2期)2014-04-04
