
计算广告中的点击率和转化率预测研究
2021-07-29 02:08颜金尧张海龙苏毓敏
中国传媒大学学报(自然科学版) 2021年2期
颜金尧 ,张海龙 ,苏毓敏
(1.中国传媒大学媒体融合与传播国家重点实验室,北京 100024;2.北京沃东天骏信息技术有限公司,北京 100176)
1 计算广告及点击率和转化率
计算广告又称为互联网广告,指的是在线媒体上投放的广告[1]。其伴随互联网的生长而在短短几十年内发展壮大,已经形成了以精准投放为目标,以竞价拍卖为手段,以计算模型为驱动的蓬勃发展的产业联盟。
1.1 计算广告的意义
计算广告脱胎于以免费模式提供服务的互联网。互联网概念的核心是连接每一个用户。从其诞生至今,每一款互联网产品的最初目标都是用免费使用的模式尽可能快速的获取大量用户,并在产品的成熟期寻求产品的变现渠道。这一过程中,传统媒体广告被引入并借助互联网能快速直达用户的特性迅速成长为互联网公司变现的核心渠道——计算广告。For‐rester 研究公司预测到2021年,美国的移动和社交广告规模将达到505亿美元[13]。
最初的计算广告是类似于传统媒体广告的展示广告。互联网产品公司通过直接售卖展示广告位的方式获取收益。很快,互联网广告运营者意识到互联网不同于传统媒体的特点:可以精准地向不同用户展示不同的信息。于是,为了提高广告位的报价,他们提出能向不同受众群展示不同类型广告的广告推送模式——定向广告。这一模式的改变标志着计算广告概念的出现。但是最初的定向广告并不能对广告流量进行非常细致的划分,也就无法使广告平台获取到最大的收益。而且在重要的一类计算广告——搜索广告中,广告从一开始就达到了非常精准的投送程度,因此直接采用了竞价的售卖方式。鉴于以上两点,竞价广告模式逐渐成为了计算广告的核心模式。
在竞价广告中,广告投送方按照自身人群需求在广告需求方平台(Demand Side Platform,DSP)上实时采买广告流量,称为实时竞价。由于实时竞价模式通常采用按展示/点击次数付费的方式,因此为了获取最高的收益,DSP 需要尽可能准确地估计每一次展示的期望价值。尤其是在竞价广告的排序阶段,其需要高效的计算广告的千次展示期望收入(Expected Cost per Mile,eCPM)并进行排序。eCPM 的计算主要依赖于点击率(Click Through Rate,CTR)或者转化率(Conversion Rate,CVR)估计,这就需要用到离线计算得到的CTR/CVR预测模型。
1.2 计算广告中的点击率与转化率预测
在计算广告中,点击率/转化率预测是最重要的技术之一,主要用在对检索出的候选广告计算eCPM并进行排序。点击率是指展示广告被点击的概率,而转化率是指广告投放者投放广告的目的最终发生的概率。准确的预测候选广告的点击率/转化率将为DSP带来巨大的收益。同时,由于DSP平台拥有丰富的用户上下文信息以及历史数据信息,这使得对点击率/转化率预测任务进行准确建模成为了可能。研究人员通常基于用户与广告的属性信息、上下文信息以及历史行为信息,采用机器学习的方法将点击率/转化率预测任务转化成分类或者回归任务建模。近年来,对CTR/CVR 预测问题的研究已经取得了非常大的进展,但其依然面临以下几个方面的问题[3‑4]。
(1)准确性问题。准确的估计候选广告的点击率/转化率非常重要。但用户点击或者转化的行为受到非常多因素的影响,比如展示广告的形式、推送的时间、用户的兴趣、社会关系影响等。
(2)数据稀疏问题。数据稀疏问题是指由于缺乏足够的有效样本数据而导致的预测精度低的问题。通常在训练数据集中,用户直接交互过的正样本广告数据非常少,大量的数据是用户没有交互过的负样本数据。这直接导致模型很难学习到用户和广告的隐兴趣特征。
(3)样本不均衡问题。通常广告的点击率只有千分之几,因而训练数据存在严重的正负样本不均衡,这将降低预测模型的准确性。
(4)冷启动问题。广告平台的新用户或者新广告通常没有任何历史交互信息,这会导致模型不能为他们提供准确的预测。
(5)转化时延问题。由于实际商业场景中,用户点击到下单的时间从几秒到几周不等,现存技术往往无法跟踪下单延迟,造成模型预估不准确。
1.3 预测模型性能评估指标
点击率/转化率预测模型预测的是交互概率,因此就可以采用机器学习领域的评价指标,比如准确率(Precision)、召回率(Recall)或者F1值进行评价[1]。同其它机器学习模型一样,为了更全面的衡量模型在所有场景下的综合泛化能力,研究人员更喜欢使用准确率/召回率曲线(Precision/Recall Curve,PR)和接收者操作特性曲线(Receiver Operating Characteristic Curve,ROC)来评价模型的综合性能。研究人员通过选取不同的正负标签划分阈值就可以绘制出PR 曲线和ROC曲线。ROC曲线相比PR曲线的优点是其曲线下的面积具有明确的物理意义,其能够在一定程度上表示模型对正负样本事件预测值排序的正确性。这个ROC 曲线下的面积被称为AUC(Area Under Curve),是评价点击率/转化率预测模型时常用的量化指标。
2 点击率与转化率预测模型研究
2.1 相关模型概述
早期的PC 端广告在形式上和实体广告相近,形式杂乱,占据空间与时间,很容易造成用户反感,所以计算广告中CTR/CVR 的预估效果不理想。而在移动互联网时代,特别是信息流广告引入后,广告效果更多的取决于广告内容与用户特征的匹配度,研究人员因而可以更准确的预测CTR/CVR。本节我们将概述CTR/CVR预测问题的研究进展。
2.1.1 点击率预测模型概述
经典的CTR 预估算法是逻辑回归(Logistic Re‐gression,LR)算法[3]。LR 算法模型简单,收敛速度快,能够较好的对二值问题进行分类,在早期广泛应用于CTR 预估领域。但是CTR 预估中的特征数据复杂,是一个典型的非线性预测任务。LR 模型无法提取两阶及以上的特征组合,所以将其用于CTR预估的效果不理想。为了提升模型效果,LR 模型通常使用人工提取的高阶特征。但是人工提取特征需要研究者具有丰富的特征组合经验,成本高昂,生成的模型还不具备泛化能力。
FM(Factorization Machines)模型[5]借鉴了协同过滤中的矩阵分解思想,将二阶组合特征的参数矩阵分解为特征隐向量的点积。经过矩阵分解与二次项化简后,FM 模型可以应用于特征高度稀疏且样本量巨大的场景。FFM(Field‑aware Factorization Machines)模型[6]通过引入场域的思想对FM 模型进行了有效改善。微软提出了结合GBDT(Gradient Boosting Deci‐sion Tree)与LR 算法的广告点击率预估融合模型[7]。模型将GBDT 提取的高阶组合特征结果输入LR 模型,在提升融合模型非线性表示能力的同时,还可以处理大规模稀疏数据。
虽然以上的融合模型取得了较好的效果,但都是基于浅层模型,非线性表达能力不强。研究人员开始将注意力转向近年来大放异彩的深度学习(Deep Neural Network,DNN)模型。DNN 模型在图像识别、计算机视觉、自然语言处理领域的成果证明其可以自动提取高维的非线性组合特征,这种特性使其也可以应用于点击率预估。Wide&Deep 模型[8]融合了DNN模型中Wide 结构与Deep 结构,从而结合了浅层模型与深层模型的优势。DeepFM模型[9]对Wide&Deep模型做了改进,将Wide 结构替换成了FM 模型,并与Deep结构的输出连接后输出到sigmoid层。文献[10]提出了Deep&Cross模型。模型分为并行连接的Deep模型和Cross 模型。其中Cross 模型可以自动进行相关特征的交叉组合。以上深度学习模型主要通过变换模型结构,来更好的提取低阶特征以及高阶组合特征,从而提高点击率预估的准确性。
注意力机制在神经网络机器翻译领域取得了显著的效果[11]。它通过控制权重矩阵,能够依据上下文内容对下一步的输出做出不同计算。阿里巴巴的DIN 模型[12]就通过引入注意力机制来提升模型预测性能。DIN 模型指出用户点击广告时的行为与用户近期的兴趣特征有非常强烈的关系。根据用户的兴趣进行广告展示能够提高广告被点击的概率。DIN模型使用注意力机制改进了DNN 的池化层结构,改进后的池化层能够根据用户对某类广告的兴趣产生不同的特征向量输出,从而增强了模型对用户兴趣特征的表示能力。但DIN 模型的局限性是没有认识到用户的兴趣是动态变化的,其会随着时间的流逝而改变。
2.1.2 转化率预测模型概述
在计算广告中,和CTR 预测类似,CVR 预测的地位也非常重要,是学术界和工业界的研究人员持续深入探索的重点课题。早期的CVR 预测方法主要是使用浅层模型。例如,基于逻辑回归或者决策树的模型,后期发展到FM 或者FFM 模型。然而,在获取高维非线性的用户行为数据方面,这些浅层模型的表达能力明显不足。深度学习框架的提出较好地解决了这个问题,如DCN、Wide&Deep以及DeepFM 等方法,通过加大网络的深度,扩展了早期的浅层模型方法,强化了模型的表达能力。
最近,阿里妈妈定向广告团队提出的ESMM 模型[2]采用深度学习框架直接从曝光中提取转化信号,试图解决CVR 预估中的样本不均衡问题和数据稀疏问题。ESMM 模型设计了“双塔”形式的模型结构。一塔是CTR预估模型,可以利用数据量巨大的曝光数据集进行参数训练;另一塔是CVR 预估模型,完成目标模型本身的参数训练。两个模型共享查询表层,使得CTR 训练更新的嵌入表示能够为CVR 训练所利用,极大地缓解了CVR 模型数据稀疏无法充分训练的问题。同时由于训练数据是在曝光样本集上进行,对于样本不均衡问题也有一定的缓解。但是在这些工作中,用户的历史行为转化为低纬度的嵌入特征,使得用户的历史行为特征没有被充分利用。
在工业界的真实CVR 预测的场景中,有一个非常大的特点和挑战:用户点击和转化(下单)行为之间的时间延迟很大,可能从几秒到几周不等。例如,当用户在电子商务网站点击广告时,她可能只是将产品添加到购物车中,在几天后才会下单。这种转化反馈的延迟会产生大量的“假负”样本,即正样本(最终会转化的样本)可能被视为负样本(没有转化的样本)。“假负”样本的存在加剧了转化样本的稀疏性和CVR预估的错误率。2014年KDD 会议上提出的延迟反馈模型(Delayed Feedback Model,DFM)[14]是对展示广告中延迟反馈问题的首次研究,具有里程碑式的重要意义。论文将用户点击与购买之间的时间延迟简单地假设为指数分布,通过建立一个指数概率模型来帮助计算未转化的样本。经过一系列的数学推导,论文将时延公式与CVR 预测公式合并为统一的损失函数,并通过EM 算法框架给出了可以分别优化各自参数集的可用损失函数形式。在这篇论文的基础上延伸出许多的改进论文,一类改进工作是提出其他复杂分布,另一类改进是通过优化非参数模型来学习延迟分布。这些论文都对CVR 预测任务中时延问题的解决做出了贡献。
2.2 我们最新的研究进展
2.2.1 点击率预测模型研究进展
受到深度学习中注意力机制以及DIN 模型的启发,我们提出了一种能动态感知用户兴趣变化的点击率预估模型——DIPN[15]。DIPN 利用用户历史展示广告记录计算出用户对候选广告的兴趣度,并将兴趣度融入特征向量注意力权重的计算中。为了更好的从历史点击记录这一时序数据中提取用户的隐特征,DIPN还引入了GRU层。
DIPN 模型架构图如图1 所示。在DIPN 中,输入的历史行为数据是历史展示广告记录。该历史记录是指该用户曾经浏览过的展示广告,包括点击以及未点击的广告。用户属性、展示历史、候选广告、上下文等特征一起输入模型。DIPN 首先根据历史展示广告与候选广告,使用兴趣度算法计算出用户对候选广告的兴趣度。兴趣度的模拟曲线如图2所示,其中,正值表示用户喜欢此类广告,负值表示用户排斥此类广告。然后DIPN 从历史展示广告中提取出历史点击记录并进行嵌入向量表示。嵌入表示之后,DIPN 先使用GRU 层提取历史点击广告序列的隐藏特征,然后GRU 层的隐状态输出向量和候选广告向量一起输入到后面的注意力网络层。其中,在计算注意力权重时,为了融合前面提出的用户兴趣度,我们提出了d‑Softmax函数进行权重的计算。d‑Softmax函数的公式如式1 所示,其中变量d 表示兴趣度算法计算出的用户兴趣度,xi是注意力层全连接网络输出的特征向量的第i 个元素。当d=1时,d‑Softmax 函数退化成Softmax 函数。注意力层输出的固定维度的特征表示向量最终输入后面的全连接网络以进一步提取用户的隐特征。DIPN 最后通过sigmoid 激活函数输出用户点击候选广告的概率。

图1 DIPN架构图
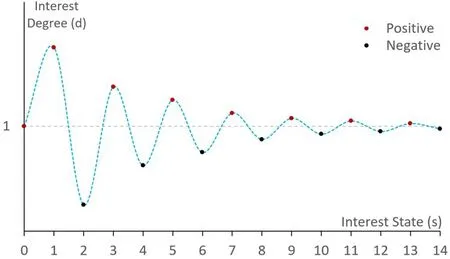
图2 兴趣度拟合曲线

2.2.2 转化率预测模型研究进展
TS‑DL模型[16]是我们在IJCAI2020上提出的CVR预测模型,主要目标是解决CVR 预测问题中的数据稀疏问题与时延问题。在CVR 预估模型中,为了解决时延问题,现有工作主要集中在捕获广告点击和转化之间的预期延迟分布上。例如,引入一个指数概率模型来帮助确定未转化的样本,或者在不假设参数分布的情况下估计时间延迟。这些工作都可以被归类为静态时延模型,即当点击事件发生时,时延分布就是确定不变的。
然而,随着更多的点击信息在广告点击后被观测和收集,广告转化的时间延迟分布应该是动态的。例如,用户在没有购买商品的情况下,点击了候选商品几天后,可能会浏览一系列相关商品,这实际上反映了用户最近强烈的购买意愿。这个简单但真实的示例反映了购买行为时延的动态转化概率。现有的静态时延模型无法从用户行为数据中获取丰富多样的信息。因此,为了解决时延问题,我们利用丰富的点击后行为数据,通过学习动态风险函数来校准时延模型,使时延分布更符合实际情况。具体来说,我们根据通过双层GRU 机制提取用户点击后行为所展现的兴趣信息,利用生存分析建模动态地学习生存模型中的风险率的向量表示,根据风险率实现灵活合理的时间延迟建模,最后产生可以用来校准转化率模型的延迟天数表示特征向量,用于辅助进行CVR 预测。另外,为了更好地提取用户行为中隐藏的个性化兴趣,我们提出一种新的基于内部自注意力机制(inner/self‑attention)的CVR 预测模型,分别利用self‑attention 来捕获所有用户与广告交互的全局/高级转化兴趣模式,与利用inner‑attention 选择与候选广告项相关的最重要的点击信息。从而在数据稀疏的情况下仍然能够较好地捕捉用户兴趣,提高CVR 预测的准确性。TS‑DL 模型的架构图如图3所示。

图3 TS⁃DL模型架构图
3 模型评估结果
3.1 点击率预测模型性能评估实验
DIPN 模型使用了丰富的用户历史行为数据。在本实验中,模型数据集选择“2019年华为DIGX算法大赛”提供的数据集。该数据集的统计信息如表1所示。
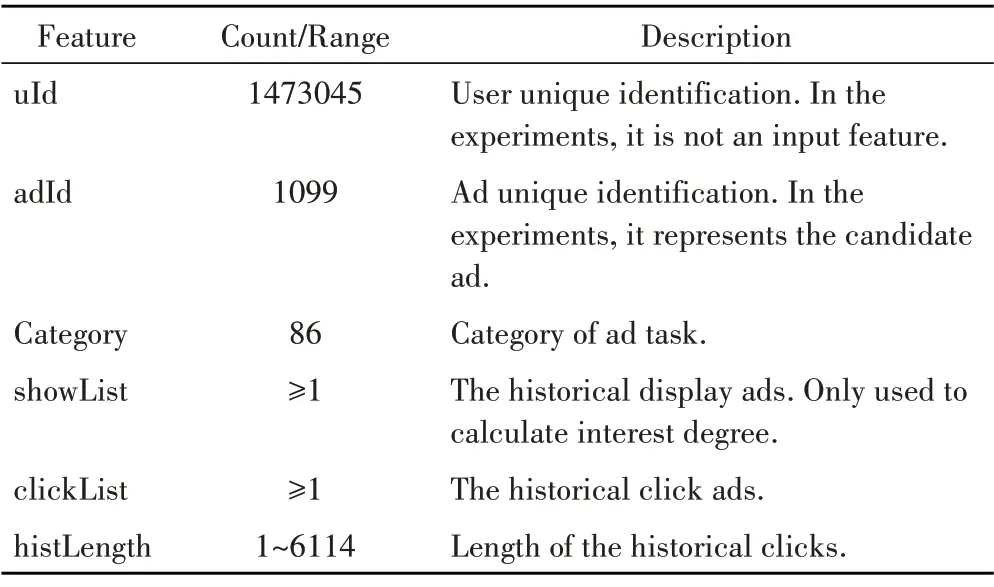
表1 数据集统计信息
实验平台为TensorFlow v1.14 及Python3.7,处理器 选 择Intel Core i7‑6800K,显 卡 为NVIDIA GTX 1080Ti。实验的对比模型包括LR 模型、DEEPFM 模型以及DIN 模型。另外,为了分析本文提出的DIPN模型各部分的性能,我们又设计了DIPN 的两个变体模型——DIN‑A 和DIN‑G。DIN‑A 模型是指将DIPN中的GRU 层去掉后形成的模型,而DIN‑G 是指将DIPN 中的兴趣度算法去掉后形成的模型。如图4 和表2展示了部分实验结果。更多其他实验结果已经发表到论文[15]中。图4 显示了在16次迭代过程中模型在测试集上的AUC 值变化曲线。表2 显示了训练过程中模型的最优AUC 值。从实验结果可以看出,LR 模型的AUC 值最低,但是收敛速度最快。这证明LR 模型易于训练,但是不能有效的提取高阶非线性特征。其中所有深度网络模型的结果都明显超越了LR 模型,这说明深度网络模型学习非线性特征的能力较强。DIN 模型展现了比深度模型更好的AUC 性能,这证明注意力机制可以提升特征向量的表达能力。同时,DIN‑A 和DIN‑G 模型的AUC 性能超过了DIN 模型,这证明兴趣度算法和GRU 层能够提升模型对用户兴趣特征的学习或者表达能力。

表2 各模型的最优AUC结果

图4 16次迭代中AUC值变化
实验结果表明,GRU层可以从历史点击广告序列中提取隐含的用户兴趣特征;注意力机制能够增强用户兴趣特征向量的表达能力;兴趣度特征通过d‑Soft‐max 函数可以缩放注意力权重,从而进一步提高兴趣特征向量的表达能力。通过结合以上三个部分,我们提出的DIPN模型取得了最好的AUC性能。
由于上面各模型架构不同,它们在训练时的复杂度和收敛时间也不同。我们将模型AUC 值达到最大值的90%定义为开始收敛并粗略统计了模型的训练收敛时间,相关统计结果如图5 所示。表中的统计结果只具有数量级精度。从图5 可以看到,对比LR 模型,深度网络模型具有更长的收敛时间。此外,加入GRU层会显著增加训练的收敛时间。但是,通过引入兴趣度算法和d‑Softmax 函数,DIPN 和DIN‑A 模型具有更短的收敛时间。
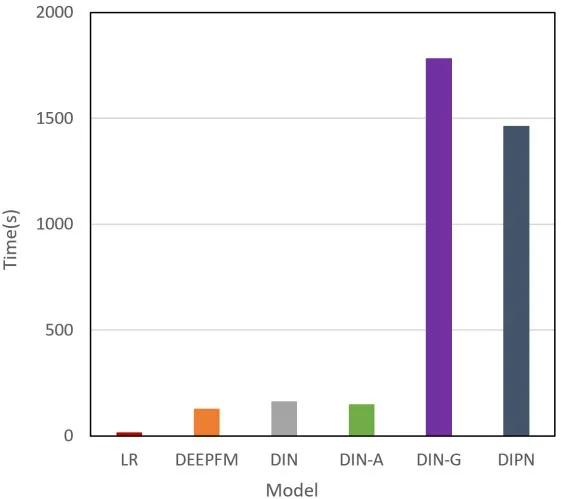
图5 模型的收敛时间统计
3.2 转化率预测模型性能评估结果
我们在IJCAI2020的论文[16]中对提出的用于CVR预测的TS‑DL模型进行了评估。评估结果表明TS‑DL 模型实现的时间延迟建模可以用来校准转化率预测,其中的内部自注意力机制(inner/self‑atten‐tion),在数据稀疏的情况下仍然能够较好地捕捉用户兴趣,提高CVR预测的准确性7.0%+,效果显著。
4 总结与展望
本文先介绍了计算广告中点击率与转化率的预测问题,然后梳理了现阶段的研究进展并指出存在的问题。文章最后介绍了我们在本领域的最新研究成果。在点击率预测模型上,我们从建模用户的动态兴趣出发,使用注意力机制与兴趣度算法搭建了DIPN模型。模型能够对用户的动态兴趣进行跟踪建模,从而提升预测的准确性。在转化率预测模型上,我们通过捕获广告点击和转化之间的预期延迟分布,解决CVR 预测问题中的数据稀疏问题与时延问题。可以发现,对点击率/转化率预测问题的建模正在朝着融合更多特征信息的深层网络方向前进。一方面,可以在特征信息中加入更多辅助信息,比如加入社交网络信息。另一方面,还需要提高模型预测结果的可解释性,增强用户的使用体验。
猜你喜欢
电脑知识与技术(2021年22期)2021-09-14
电脑知识与技术(2021年22期)2021-09-14
花火B(2019年3期)2019-04-27
电子制作(2019年23期)2019-02-23
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中学化学(2015年2期)2015-06-05
新课程·中学(2014年7期)2014-10-24
理科考试研究·高中(2014年8期)2014-10-17
中学化学(2014年1期)2014-04-23
海外英语(2013年3期)2013-08-27
