
特征房价空间分析及连续型深度置信网络预测
2021-07-30 03:29吴莞姝胡龙超赵凯
华侨大学学报(自然科学版) 2021年4期
吴莞姝, 胡龙超, 赵凯
(1. 华侨大学 建筑学院, 福建 厦门 361021;2. 华侨大学 数量经济研究院, 福建 厦门 361021)
房地产行业在国民经济中有着举足轻重的地位,作为房地产价值体现的房价不仅关系到国民经济的健康、平稳发展,其涨跌变动还关系到居民的财富及生活水平[1-2].影响房价的因素众多,不仅受建筑特征的影响,还会因地区之间公共服务设施的资源配置不均衡而产生差异.人们根据对公共服务和设施的偏好选择居住区域,特别是在物质生活水平日渐丰富的经济社会环境下,居民往往愿意支付较高的价格以获得优质的公共服务,而这部分优质公共资源的价值就资本化于房价之中[3].
针对房价的研究多基于特征价格模型.Ridker等[4]采用特征价格法分析空气污染对房价的影响.Xiao等[5]利用特征向量空间滤波方法消除空间自相关性后,发现北京周围的设施对北京房价的影响参差不齐.张骥[6]以北京市二手市场上的商品住宅和非商品住宅为研究对象,利用基于特征价格的配对回归模型,研究北京学区房交易价格,发现北京市的学区房溢价已高出24.3%.文献[7-8]以北京为例,通过特征价格模型探寻房价影响因素,研究证实地铁、公交等交通基础设施及优质教育资源、高水平的医疗机构、公园等公共服务设施对房价上涨皆具有明显的正效应.Li等[9]则通过整合链家网站、Mobike网站及百度地图兴趣点的公开数据,分析上海公寓价格的空间模式及其与当地配套属性的关联,研究发现公园、学校、医院和银行等公共服务设施及娱乐、购物等私人服务设施推高了市中心地区的房价.
利用特征价格模型构建房价分析模型需要“先验”地设定函数形式,这往往容易损失房价与其特征变量之间的深层次关系.近年来,国内外学者尝试应用多种机器学习模型探讨房价的变化趋势和影响因素等问题.申瑞娜等[10]结合主成分分析和支持向量机,综合考察影响上海住房价格的8种因素,并对上海房价进行预测.文献[11-12]利用灰度GM(1,1)预测模型分别对福州市和周口市的房价走势进行预测,并得到精准度较高的预测结果.张智鹏等[13]利用梯度提升树(GBDT)算法对房价进行预测,实验结果表明,公共设施、生活服务、学校、购物服务等是对房价产生明显影响的因素.这些文献均采用结构较为简单的机器学习模型,并且分析数据的特征维度偏低.传统机器学习方法难以全面且精确地挖掘特征因素和房价之间的联系.
浅层BP神经网络模型(BPNN)在预测上优于传统机器学习模型,但仍存在学习速度慢、易陷入局部收敛等问题.而深度置信网络采用无监督训练方式,具有较好的降维性能.一方面,深度置信网络能有效克服传统人工神经网络需要大量有监督信号和易陷入局部极小等缺点;另一方面,深度置信网络可高效处理高维的数据并挖掘变量之间的深层关系.此外,深度置信网络解决了大规模数据计算耗时问题且精度较高,并成功应用于多种人工智能问题的研究,尤其在图像处理、声音辨识和智能网络分析等方面的应用中成效显著[14-15].由于深度置信网络在运算时使用数据离散化方法进行特征提取,隐藏层和可见层节点均为伯努利值(0或1),这使深度置信网络不适用于对连续型变量的高精度预测[16-17].为提高模型的预测精度,学者们将深度置信网络进行改进,使其能够有效处理连续型的输入变量[18-19].
尽管深度置信网络在人工智能领域特别是模式识别任务中取得了较好的成果,但将其应用于现实经济问题的研究仍较少见.基于此,本文尝试将连续型深度置信网络扩展至房价问题的研究中,依据特征房价理论并考虑到上海市二手房交易价格可能存在的空间相关性,构建空间计量模型以分析各特征变量对二手房交易价格的影响.在此基础上,利用连续型深度置信网络建立房价与多维影响因素之间的深度学习预测模型,深层挖掘其潜在规律.
1 研究介绍及数据探索
1.1 研究区域界定
由于上海是我国“超一线”城市,房地产市场发展较为成熟和完善,具有一定的代表性;同时,上海浦东和浦西在城市化建设和房屋价格上具有明显的差异,这为探讨建筑特征、区位特征和邻里特征对二手房交易价格的影响效果提供了较好的素材,因此,选择上海市作为研究区域.
1.2 数据来源
房屋交易数据源于“链家二手房交易平台”(https:∥m.lianjia.com),链家的楼盘数据库管理着160多个城市1.1亿套真实的房产数据,依托互联网对数据进行标准化管理,实现信息的无差别共享.
基于Python语言的爬虫技术,按照不同行政区对链家上海市二手房交易平台上的数据进行收集.利用Beautiful Soup对网页返回结果进行重构,得到超文本标记语言(HTML)的树状结构,再使用正则表达式对所需信息进行提取,进而获取变量数据.最终,所爬取的数据涉及房屋交易额、交易单价、百度地理坐标(BD08)、房屋户型、所在楼层、建筑面积、户型结构、建筑类型、建成年代、装修情况、梯户情况等变量信息,共计45 131条原始信息.同时,搜集整理上海市全部40家三甲医院(及其分院)、上海市34所重点中小学及上海市所有地铁站出口的地理坐标数据.上海市的主要三甲医院及重点中小学的地理位置信息,如表1所示.
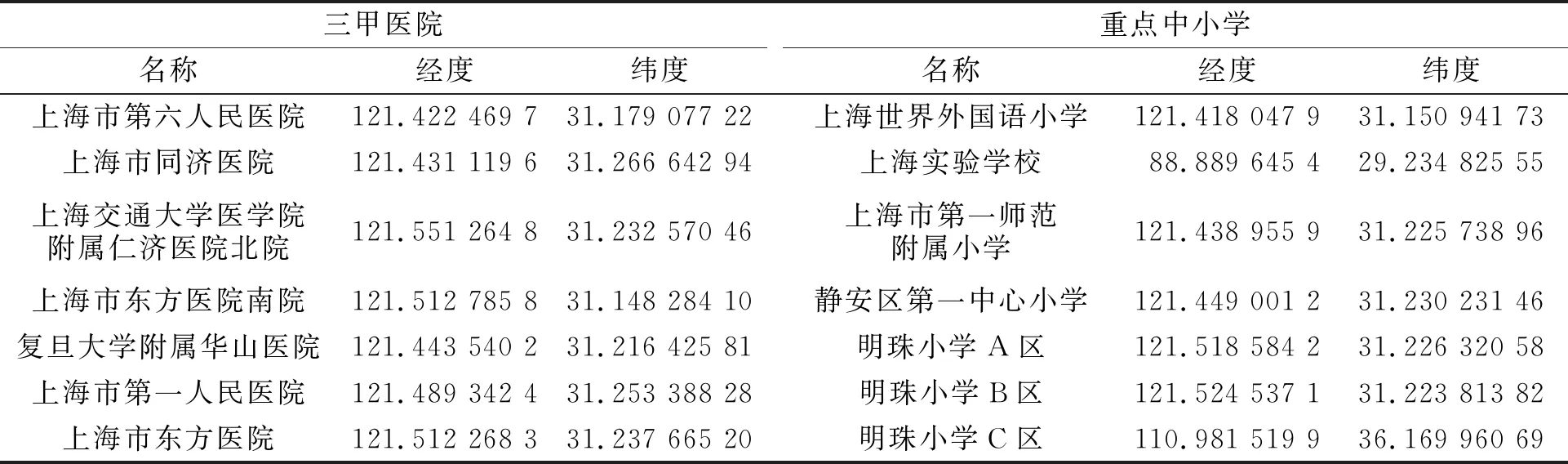
表1 上海市的主要三甲医院及重点中小学的地理位置信息
1.3 数据清洗
上海市各行政区的原始数据交易时间跨度不一,为剔除时间跨度的影响,对各行政区数据进行切割,保留共同交易时间跨度的数据为研究样本.另外,由于在房屋的交易权属中个税的收取不同,因而,删除交易权属中的售后公房.为避免极端价格对数据分析的影响,房屋用途中删除别墅、车库和商业办公类房屋,只保留普通住宅.剔除含有缺失值的数据条目,最终获得9 058个样本,涉及房屋户型、建筑面积、建成年代、所在楼层、装修情况、配备电梯等变量.
房屋户型变量的形式以字符数字组合为主,采用正则表达式将卧室、大厅、厨房和卫生间这几个数值提取出来,并分别作为建筑特征的变量.建筑面积的原始数据中带有面积单位m2,利用正则表达式剔除该单位,并把面积值变为浮点型数据.原始数据中建成年代为房屋建成年代,采用爬取数据的年份(2019年)减去建成年代的方式,计算房屋建成年数.所在楼层的原始数据为高楼层、中楼层和低楼层.对所在楼层进行数值化处理,把高楼层、中楼层和低楼层分别赋值为2,1和0.装修情况和配备电梯为二值数据,装修情况为已装修或未装修,配备电梯为有或无,利用1和0进行数值化处理.
链家官网的坐标数据来源于百度地图,利用ArcGIS软件将清洗后样本数据的地理坐标转化为WGS84坐标,其分布情况如图1所示.

图1 样本数据的空间分布
1.4 特征变量的选取
借鉴以往研究,将二手房的特征梳理为建筑特征、区位特征和邻里特征3类.二手房建筑特征为房屋本身的属性,涉及的变量包括房屋户型、所在楼层、建筑面积、建成年代、装修情况及配备电梯.区位特征量化了二手房区位对整个城市的可达性,如出行成本等.
将二手房到城市中心的距离作为二手房的区位特征变量;以陆家嘴金融贸易中心区域的质心为城市中心点.邻里特征通常指房屋周围的环境及配套,如交通站点、学校、医院等.选取到最近三甲医院的距离、到最近重点中小学的距离及到最近地铁站的距离体现邻里特征.距离计算方式取大圆距离,大圆距离是将地球看作一个球形,计算球面上两点的最短路径.特征变量的相关说明,如表2所示.

表2 特征变量说明
1.5 描述性统计
清洗后数据的描述性统计,如表3所示.由表3可知:二手房成交单价最大值为147 668元·m-2,最小值为7 059元·m-2,均值为49 577元·m-2,偏度为1.011 452,属于右偏数据,大多数交易价格集中在50 000元·m-2左右.

表3 数据的描述性统计
绘制QQPlot分布图,将数据分布与正态分布进行对比,结果如图2所示.图2中:S为标准正态值;Q代表数据的分位数.由图2可知:对数成交单价数据近似服从于正态分布.

图2 对数化后的二手房成交单价分布
化后的利用空间趋势分析将二手房成交单价投影到XZ和YZ平面上,绘制上海市二手房交易价格分布的空间趋势,如图3所示.图3中:X为经度;Y为纬度;Z为单价.由图3可知:不论在东西方向还是南北方向,上海市二手房交易单价都呈现由中心向两头递减的趋势.综上可知,上海市二手房市场具有中心高价的特点.

图3 二手房成交单价的空间趋势
2 特征房价空间分析
2.1 空间自相关

(1)

由于二手房交易价格数据在空间上是点要素的形式,没有多边形的拓扑关系,在空间上的分布也较不均衡,故整体的空间关联程度可以利用全局莫兰指数判断,莫兰指数(I)的表达式为
(2)

计算得到全局空间自相关的检验结果如下:莫兰指数I为0.236 862 3;统计量为-0.000 271;p近似为0.由检验结果可知:二手房交易价格的莫兰指数显著为正,说明上海市二手房交易价格具有空间集聚效应.
上海市二手房交易价格全局空间自相关散点图,如图4所示.通过莫兰散点图将空间自相关分为高-高集聚、高-低集聚、低-高集聚、低-低集聚这4种类型.图4中:L为lnP的空间一阶滞后;第1,3象限是高-高集聚、低-低集聚区域,即同质化明显的区域;而第2,4象限是高-低集聚、低-高集聚区域,即异质性较强的区域.
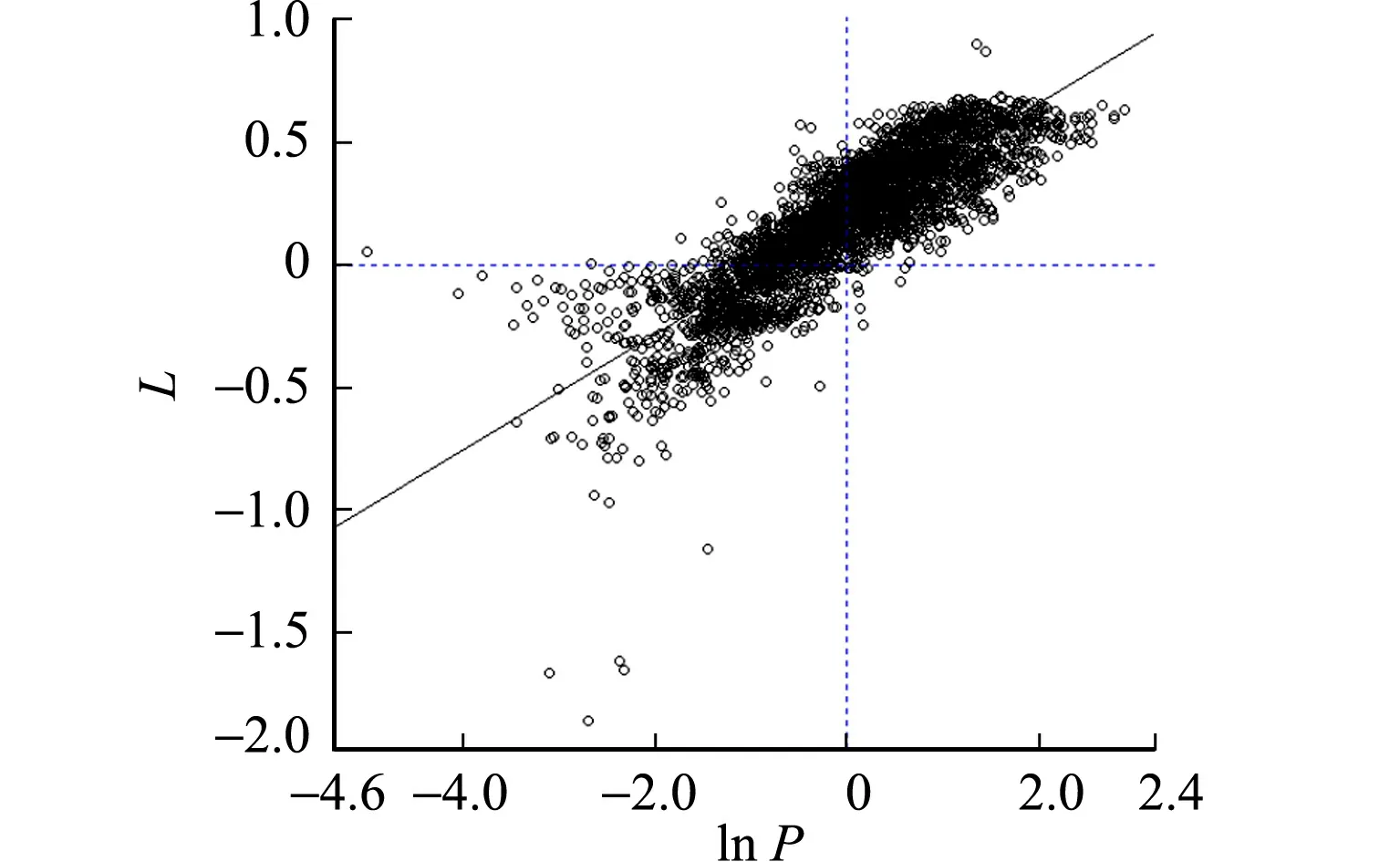
图4 上海市二手房交易价格全局空间自相关散点图
由图4可知:绝大多数样本落入第1,3象限,少部分样本落入第2象限,空间集聚特点较为明显.
2.2 空间异质性
借助ArcGIS软件绘制上海市二手房交易价格的LISA集聚状况,如图5所示.由图5可知:中心城区的房价呈现高-高集聚的空间效应,且越靠近城市中心点,高-高集聚的特征越显著;高-低集聚区域沿着高-高集聚区域的边缘分布;而低-低集聚效应区域大多分布在上海周边地区.

图5 LISA集聚状况 图6 冷热点分布
进一步,通过局部空间自相关检验探讨分析上海市二手房交易价格的空间异质性.局部空间自相关水平的冷热点分布,如图6所示.由图6可知:热点区域和冷点区域均在99%的置信水平上显著.上海市二手房交易价格呈现“中间高、四周低”的空间格局,相较于LISA集聚,冷热点分布更宽,涉及更多边缘样本.城市中部的浦西七区、宝山区及闵行区的二手房交易价格为高-高集聚,环绕四周的嘉定区、青浦区、松江区、奉贤区和浦东新区外环城区的二手房交易价格为低-低集聚.
2.3 空间计量模型估计
上海市二手房交易价格具有空间关联性,应选择空间计量模型进行分析.拉格朗日乘数检验项L-Mlag,LMerr及其稳健值R-LMlag,R-LMerr的检验结果,如表4所示.由于LMlag,LMerr均显著,需进一步比较R-LMlag和R-LMerr的显著性,又因为R-LMerr显著而R-LMlag不显著,故选择空间误差模型(SEM)进行分析.

表4 拉格朗日乘数的检验结果
基于特征价格法建立SEM,探讨影响上海市二手房交易价格的可能因素.SEM回归结果,如表5所示.表5中:ES为标准误差;λ为空间自相关系数;*,**,***分别表示在10%,5%,1%水平上影响有统计学意义.对数似然值为1 004.224;赤池信息准则AIC为-1 974.4.
由表5可知:除厨房数量外,其他特征变量对二手房交易价格的影响皆有统计学意义;已装修、带电梯、有客厅且洗手间数量较多的二手房交易价更高;临近重点中小学、医院和市中心的二手房交易价格较高;然而,卧室数量及建筑面积在一定程度上会对二手房交易价格产生一定的抑制作用,原因可能是上海市过高的单价抑制了人们对大面积住宅的需求;楼龄与楼层均在1%的显著性水平下对房价有反向影响,但系数较小.

表5 SEM回归结果
3 连续型深度置信网络房价预测
3.1 连续型深度置信网络简介
连续型深度置信网络(CDBNN)改造于深度置信网络(DBN).DBN是由多个受限玻尔兹曼机 (RBM)逐层堆叠而成,其核心思想是自底向上每一层RBM对输入数据进行提取、抽象,尽可能保留重要信息,训练过程一般采用贪婪无监督方式,即逐层对DBN中的每一个RBM进行训练.
RBM是一种基于能量的概率生成模型,生成模型是对特征和标签之间的联合分布进行建模.当可见层的状态ν和隐藏层的状态h确定后,RBM模型中的能量可以表示为
(3)
式(3)中:θ为参数向量;ai和bj分别为可见层第i个神经元上的偏置和隐藏层第j个神经元上的偏置;ωi,j为可见层神经元和隐藏层神经元之间的连接权重值.
基于能量函数,可得ν和h的联合概率分布为
上式中:z(θ)为归一化函数,使得概率之和为1.
依据联合概率分布,可以得到在可见层状态ν确定时,隐藏层每个神经元被激活的概率,以及在隐藏层状态h确定时,可见层每个神经元被激活的概率分别为
(4)
(5)

一般采用梯度下降方法求取最优参数值,过程中涉及难以求解的归一化函数z(θ),常用吉布斯(Gibbs)采样方法近似计算[20].CDBNN是在DBN的基础上改进,对式(4),(5)和激活函数σ(x)进行改进,使其适用于连续型数据,即
(6)
(7)
(8)
式(6)~(8)中:Ni(0,1),Nj(0,1)表示均值为0且方差为1的高斯随机变量;φ为常量;θH和θL为渐近线,一般取样本中的最大值和最小值.
由于连续型深度置信网络是在深度置信网络的基础上衍生而来,因此,该方法同样采用误差反向传播的算法进行网络调优.CDBNN算法主要有以下8个步骤.
步骤1准备训练数据D=(x1,x2,…,xn),共n个样本,假设所有神经元的状态使用状态集{Si}表示,随机初始化所有神经元的参数,设训练的最大次数为K次.


步骤4根据步骤3所得的Si,同步骤2,计算隐藏层的重构神经元状态Sj.
步骤5继续随机选择下一个训练样本,返回步骤2,如果样本集中的样本都选完毕,则依据式(8)计算参数变化量,更新方式为wi,j(k+1)=wi,j(k)+Δw,ai(k+1)=ai(k)+Δai.
步骤6进行第k+1次训练,当权重的变化量落入预定的范围内,即|Δwi,j|<ε,其中,ε是预先设定的误差范围,或者训练次数达到k次,则训练停止.
步骤7将训练好的RBM的输出作为下一层RBM的输入层输入数据,按照步骤1~6进行训练,直到训练完DBN的所有RBM层.
步骤8网络调优:完成DBN的训练后,需进一步优化深度神经网络权值.将训练好的DBN网络作为网络的初始状态,训练得出的参数作为DBN的初始参数;然后,使用反向传播的方法,运用梯度下降法对网络的整体权值进行有监督的学习.
3.2 连续型深度置信网络结构的确定
连续型深度置信网络结构的确定实质上就是选择深度置信网的超参数.待确定的神经网络结构的超参数包括神经网络的层数、神经网络隐藏层的节点数、学习率的确定、高斯随机变量中的方差值和样本迭代次数的选择及其他参数的选择.
超参数调优即选择超参数使网络结构达到最优的效果,是训练神经网络的核心任务.目前,常用的超参数调优方法有网格搜索与随机搜索.前者基于整个超参数空间进行搜索,速度较慢,但可获得最优的超参数组合.后者速度快,但可能会错过搜索空间中最优的超参数值.借鉴Snoek等[21]的思路,利用贝叶斯思想自动优化超参数,不仅能有效兼顾上述两种方法的优点,还能借助Python的hyperopt模块轻松实现优化超参数.主要超参数的估计值,如表6所示.

表6 主要超参数的估计值
3.3 预测模型性能的比较
在建立连续型深度置信网络的过程中,将所有样本按7∶3的比例随机分成训练集和测试集,先通过训练集对模型进行训练,再使用训练后的模型对测试集数据进行预测.将文中的预测结果与现有文献采用的支持向量机(SVM)、集成模型(采用Adaboost算法)和BP神经网络模型的预测结果进行对比.连续型深度置信网络、SVM、集成模型、BP神经网络的预测误差分别为0.006 67,0.007 61,0.008 42,0.029 03.BP神经网络的预测误差远高于其他3个模型,这是由于随机初始化使其难以达到全局最优值.而连续型深度置信网络可预先对BP神经网络进行预处理,有效缓解随机初始化对最优预测的阻碍.此外,CDBNN的预测结果也略优于SVM和集成模型,表明CDBNN有更高的复杂度,能够更加深入且全面地进行特征分析.
4种模型测试集样本点的预测残差绝对值,如图7所示.图7中:ε为残差绝对值.由图7可知:与其他模型相比,CDBNN的预测残差总体情况更优,CDBNN能够有效地解决BP神经网络在预测模型上存在的不足.

图7 测试集样本点的预测残差绝对值 图8 残差绝对值与二手房交易价格的关系
3.4 预测结果与讨论
通过绘制残差绝对值,可对CDBNN模型的预测结果进行评价.残差绝对值与二手房交易价格的关系,如图8所示.由图8可知:对于房价偏低或偏高的区域,影响上海市二手房交易价格的因素较为复杂,不仅局限于房屋建筑特征变量;房价偏低的区域大部分偏离市中心,距上海市重点中小学、三甲医院以及地铁站距离较远,利用特征价格法选取的变量对房价偏低区域的房价预测能力相对较差.这些区域的二手房交易价格可能会更多地受到其所在区域的亚中心及该区域所配套的基础设施的影响.对于二手房交易价格偏高的区域,预测的残差绝对值相对较大,可以认为当房价过高(P≥80 000元·m-2)时,二手房交易价格的影响因素更加复杂.这其中除特征变量之外,还可能与购房者的购房目的等因素有关.对上海市高房价区域的购买者来说,房价弹性相对较低,他们对高房价并不敏感;高房价的购买者对房屋的消费不仅在于其本身的价值,而可能是出于政策便利性和高房价周围的邻里交际环境.
各行政区预测结果的残差绝对值平方,如图9所示.由图9可知:崇明区、黄浦区和静安区的预测结果的残差绝对值较大;崇明区的二手房交易价格偏低,而交易价格偏高的区域大多集中在黄浦区和静安区这两个市中心区域;浦东新区预测结果的残差绝对值较小,基于特征房价探讨的变量对浦东新区这样的非市中心的二手房交易价格的预测效果较好;杨浦区和浦东新区的预测结果的残差绝对值很相近,而静安区和黄埔区的残差绝对值相对较大.这可能是因为杨浦区和浦东新区隔海相望,杨浦区的经济和浦东新区的经济相互影响较大,黄浦区和静安区作为上海一直以来的市中心,其二手房交易价格的影响因素较为复杂;而浦东新区是改革开放后繁荣的区域,受上个世纪90年代开放的房地产市场影响较大,所以,预测效果较好,特征价格法所选的建筑特征、邻里特征和区位特征对新区房价的解释力度更强;对于黄浦区和静安区这样的老中心区域,其房价的解释力度相对较小;黄浦区和静安区的二手房交易市场的影响因素已经超出特征价格变量的解释范围.

图9 各行政区预测结果的残差绝对值平方
4 结论
以上海市二手房交易市场为例,通过空间自相关分析,发现上海市二手房交易单价在空间上具有显著的自相关效应.二手房交易价格在上海市核心区域存在高-高集聚效应,在周边区域呈现低-低集聚效应,而在核心与周边交界地区存在高-低集聚和低-高集聚的负向空间效应.与此同时,基于连续型深度置信网络对特征二手房交易价格进行分析预测,发现特征变量对价格偏高区域的二手房交易价格解释力度较小,价格偏高区域的二手房交易价格影响因素较为复杂.从区域角度分析,除中心区域外,基于深度置信网络的特征变量对上海市二手房交易价格预测能力良好.连续型深度置信网络不仅能有效地解决BP神经网络在预测模型上存在的不足,而且与其他机器学习模型相比,连续型深度置信网络能更精准地对房价进行预测,从而为政府部门进行房价预测提供理论支持和政策导引.
文中采用一种能够处理大数据的深度学习模型,但由于获取数据的难度大,仅选取十余个解释变量.现实中,影响二手房交易价格的因素非常多,如加入更多的解释变量,基于连续型深度置信网络对特征二手房交易价格模型的预测将会更加精准.采用空间分析及深度学习技术对二手房交易价格进行研究,在各大城市均具有普遍适用性,可应用于其他城市的房价研究.
文中研究结果可为后续相关研究提供方法参考和模型借鉴.通过对上海市不同行政区及不同价格区间的房价预测模型效果进行差异性分析发现,在价格偏高的区域和上海市中心区域的预测效果较差.这为后续相关研究提供两方面借鉴:一方面,在预测房价时,需要考虑到空间异质性的影响,应针对不同区域构建不同的预测模型;另一方面,为进一步提高房价预测的精度,需要在建筑、区位、邻里等特征变量的基础上纳入更多相关的社会经济要素,从而提升模型的预测能力.对房价走势进行高精度预判,有助于政府制定调控政策.房地产市场调控一直是政府相关部门的工作重点,而稳定房价是调控的主要目标.对房价走势进行高精度预测具有一定的现实意义,可为政府相关部门完善房地产市场、优化城市规划设计提供一定的理论支持.
猜你喜欢
现代经济信息(2022年22期)2022-11-13
护理学报(2022年3期)2022-03-11
火力与指挥控制(2020年12期)2021-01-22
少年文艺·开心阅读作文(2020年3期)2020-04-07
中国外汇(2019年9期)2019-07-13
中国经贸(2018年7期)2018-05-10
会计之友(2017年20期)2017-10-25
三联生活周刊(2017年30期)2017-07-27
江苏农业科学(2016年7期)2016-10-20
财经(2016年19期)2016-08-11
