
面向在线评论的领域情感词典的自动构建
2021-08-06 08:26宗宇方朝阳吴波
现代计算机 2021年18期
宗宇,方朝阳,吴波
(1.江西师范大学地理与环境学院,南昌330000;2.鄱阳湖湿地与流域研究教育部重点实验室,南昌330000)
0 引言
近年来,随着乡村振兴战略的贯彻实施,乡村旅游发展总体呈现为“快、高、多、聚”的趋势。而互联网随着这些年来高速的发展,已经成为乡村旅游的重要信息载体。携程、马蜂窝、途牛等OTA网站已经可以充分满足游客出行一条龙服务所需的数据及完备的评价系统[1]。众多旅游爱好者利用智能终端进行预定旅游产品、编写游记点评及相互交流等活动。但由于信息渠道的不对称性,使得游客容易对旅游体验的好坏缺乏安全感,进而影响消费者的购买决策。因而,如何通过在线评论分析游客情感体验,改善自身服务水平以获取更多的旅游者信任,已经成为旅游景区管理者亟需考虑的重要问题之一[2]。
传统旅游目的地的相关评价主要是依靠定量模型,问卷调查和统计的方式来获取数据[3-4]。在当前大数据背景下,地理学者使用GIS和GPS技术将游客的时空行为信息可视化,从而获得群体性的空间规律和综合评价[5]。但是如何利用游客在互联网中产生的海量数据来精准捕捉游客的爱好、愉悦度和满意程度等情感信息,继而获得游客对旅游目的地的整体评价,仍然是现阶段专家学者亟需解决的问题。虽然目前旅游的不少领域已经有了相关的研究,如:大数据下旅游目的地评价[6]、酒店顾客在线评论[7]、山岳型景区情感词典的构建[2],等等。但是基于乡村旅游型情感词典的构建,从而进一步对乡村型旅游景区展开综合评价,这方面的工作国内相关研究较少且研究方法较不成熟。
本文通过已有的一些构建领域型情感词典的方法,构建了面向乡村景点的乡村型褒贬情感词典,通过与一般情感词典对比,取得了良好的效果。研究有利于更好地揭示乡村型旅游景区的情感空间规律,并可为旅游目的地综合评价工作提供更精准的情感词库,为乡村旅游情感分析研究提供更科学的参考方法。
1 研究区概况
婺源县,地处江西省东北部,隶属于江西上饶市,与安徽、浙江两省交界。全县多是丘陵地带,素有“八分半山一分田,半分水路和庄园”的地理特征。全县土地面积2967km2,截至2019年末婺源常驻人口34.6万人,其中乡村人口约17.3万人,占总人口的49.8%。婺源古时一直为的古徽州一府六县之一。民国23年划至江西,民国36年划归安徽,新中国建国后重新划归江西省。
婺源旅游产业萌芽于上世纪90年代,香港摄影家陈复礼举办了以“中国最美的农村——婺源”为主题的摄影展[8],这也吸引了无数人的惊叹,更为婺源乡村旅游产业走向世界打下了基石。婺源被誉为“中国最美乡村”,也是全国唯一一个以整个县命名的国家3A级景区。婺源的旅游资源以徽派建筑、田园风光及生态资源为主,经过近年来的大力发展,品牌效应日益凸显,且先后获得国家多项荣誉称号。2019年度婺源县全年全地区生产总值131.5亿元,其中第三产业增加值91.08亿元,约占生产总值的69.3%,全年共接待游客数达2463万人次[9]。因此选取婺源为研究区具有很好的代表性。
2 数据采集与预处理
2.1 微博评论数据采集
以微博漫游功能中提供的接口,设定爬取位置的经纬度并且限制获取范围为5公里。这是由于通过漫游接口返回的数据极有可能超出研究区域,同时为了采集范围尽可能覆盖整个研究区域,故设置采集半径为5公里。获取了2019年包含国庆节在内的9月24日至10月22日的婺源县的带有模糊地理位置的微博数据。
通过对微博接口进行解析,最后可以得到评论ID、用户姓名、发布内容、发布时间、城市编码、位置距离等信息,其数据结构见表1。评论ID用以识别重复的微博评论、去除数据冗余,发布内容用以进行后续的分词、领域型情感词典构建的工作,城市编码与空间距离可以过滤掉非婺源微博,保证数据的位置准确性。微博评论的样例数据如表2。
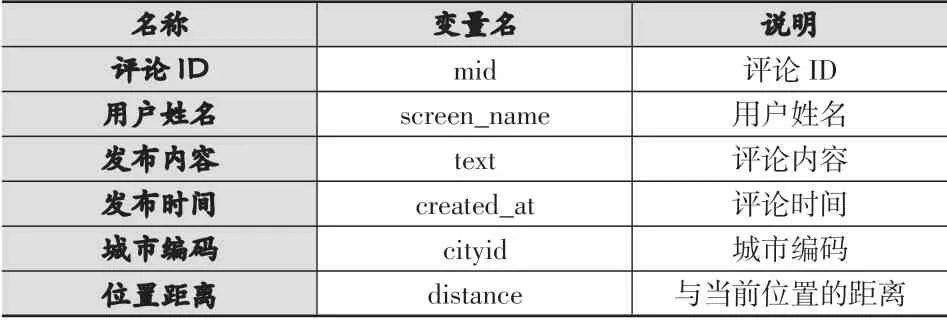
表1 数据结构说明

表2 微博评论样例数据
2.2 数据预处理
通过以上手段获取到的原始数据存在数据重复、未知字符过多、JS代码未去除干净、位置不准确等问题,直接使用会导致实验结果出现偏差。因此,需要将原始数据进行预处理以方便下一步使用[10]。由于使用漫游接口设置爬取半径可能覆盖到其他地市,故获取到的数据存在爬取到其他区域数据的情况,所以需要剔除非婺源数据。并且微博评论数据大量存在重复次数较多的词,如:分享图片、全文、地点、超话、话题等,也需要进行去除处理。具体预处理步骤如图1。

图1 数据预处理流程
(1)提取地点标签,并判断其位置是否在婺源县境内,对于非婺源数据统一剔除;
(2)去除“**的微博视频/**的秒拍视频”等标签;
(3)去除“**超话/#**#”等话题标签;
(4)去除“分享图片/分享视频/..全文等”无意义词语。
(5)最后通过人工识别,去除明显与旅游无关的微博评论。
之所以去除这些标签是由于其出现频率极高且重复次数多,而且这些标签对于下一步筛选词频较高的情感种子词和候选情感词具有较大的干扰作用。预处理后的结果如表3所示。
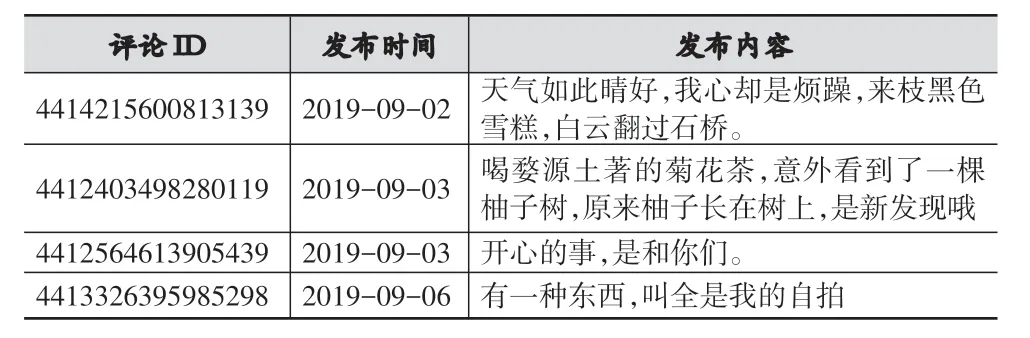
表3 语料预处理后
3 乡村型褒贬情感词典的构建
3.1 种子词集生成
种子词集的选取必须满足两个条件:①表达的情感强烈,②经常被使用[11]。由NTUSD中文情感极性词库、情感词汇本体库、HowNet情感词典库三种情感词库进行汇总,并人工判别选取若干感情强烈的情感词[12]。对语料库文本进行分词及去停用词,再利用词频统计工具,对词语出现的次数理解为是该单词的词语频率,即词频。根据词频进行排序,选取词频最高的前x个词语作为候选种子词,这里的x根据高频词语的数量而定,高频词语的数量越多x的数目也越多。再从x个候选种子词中通过人工识别选取表达情感最为强烈且常用的y个词语,此即为情感种子词集。一般y的数目约占x的15%为最佳[12]。
3.2 词义相似度计算
词义相似度是指两个词在语境文章中可以互相替换但不改变文章句法语义的程度[13]。目前,词语之间相似度的计算已经广泛运用于主题抽取、文本分类、信息检索等研究领域。而度量两个词之间的关系很重要的指标就是词语间的距离,其计算公式如下。
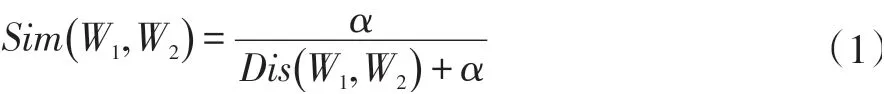
其中W1和W2分别代表两个词语,Sim(W1,W2)记为;词语W1和W2间的相似度,Dis(W1,W2)为W1和W2词语间的距离。α是一个可调节的参数,表示相似度为0.5时W1和W2两个词语在义原树中的长度, 值一般设为1.6[10]。
若W1和W2义原数目存在一对多、多对一乃至多对多的情况,则选取其中Sim(W1,W2)最大的一组义原作为W1和W2的义原相似度[14],其计算公式如下。
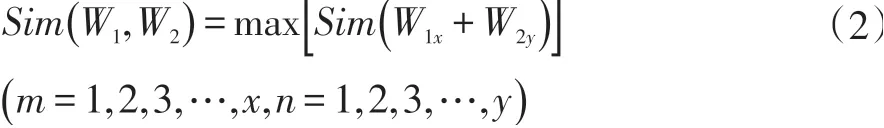
其中m代表W1的义原有m个,n代表W2的义原有n个。
3.3 N-Gram语言模型
N-Gram算法的核心思想是将文本内容按照字节流进行字节长度为N的滑窗操作,形成长度为N的字节片段列表,每个长度为N的片段称为gram,对全部的gram出现频率进行统计,设置阈值过滤频率较低的gram,形成包含一个或多个关键片段的列表[15]。N-Gram算法由于其无视语言差别、容错率强、无需词典规则等特性。而广受信赖。但是这种算法的缺点也尤为明显,对于长度大于或小于N的词语很容易因字节限制而导致语义上的偏差。姜如霞、黄水源等人[16]提出了一种基于N-Gram的改进算法,其基本思想是:在进行bigram切分字符串时,在统计gram出现频率的同时,也统计相邻gram并记录。最后全部处理完后,对其中经常出现的词合并为新的特征词。
本文中为了处理未登录词问题,采用了这种基于N-Gram的改进算法。从表4样例数据中可以看到,随着N的增大组成的词语个数也随之增多。根据文献中所述,常用的N参数一般为1、2、3、4。本文中设置N=3,并过滤其中词频较低的gram,从而得出常用的未登录词,为后面进行情感词典构建提供扎实的语料基础。
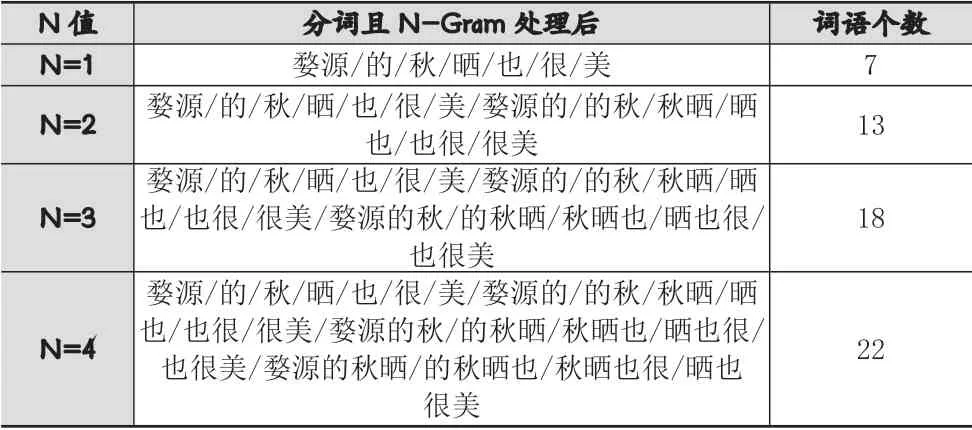
表4 进行N-Gram处理后样例数据
3.4 乡村型褒贬情感词典的构建
目前广为人知的比较成熟的五大情感词典分别是情感本体词库、李军中文褒贬词典、台湾大学NTUSD、知网HowNet等。但乡村旅游的在线评论显然不同于其他领域的评论,部分词语很少在其他领域使用,例如较有地域特色的淳朴、雕梁画栋、错落有致、生机勃勃、繁花似锦等词语就凸显了婺源徽派的建筑风格、乡土人情及油菜花开的秀丽风景。因此使用传统型情感词典或其他领域情感词典难以有效捕捉乡村旅游游客的情感倾向。在2019年严仲培提出的面向在线评论的构建山岳型旅游景区情感词典的方法[2],经实践证明其有效地解决了这个问题。本文在乡村型褒贬情感词典构建借鉴了严仲培构建山岳型领域情感词典的方法的同时,通过增加N-Gram语言模型提升未登录词识别的精准度,以此构建了如下乡村旅游情感词典。实验步骤详见图2。
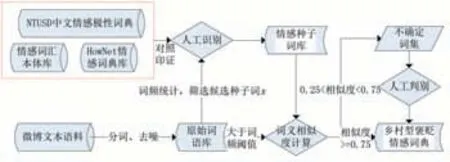
图2 乡村型褒贬情感词典构建流程
具体实验步骤如下:
(1)将微博文本语料进行分词和去噪处理,组成原始词语库。
(2)将得到的原始词语库进行词频统计后,取出词频最高的x个单词组成候选种子词库。同时将NTUSD中文情感极性词库、情感词汇本体库、HowNet情感词典库汇总,并与候选种子词库进行对比取交集,并通过人工识别得到最常用且感情最为强烈的y个词语,组成乡村旅游种子情感词集。
(3)对原始词语库统计词频,提取高频词并去除非情感词。从而与情感种子词库中种子词进行词义相似度计算,公式如上述公式(2)。其中相似度大于等于0.75即被认为可以进入乡村旅游情感词库。并将其中词语相似度大于等于0.25小于0.75的定义为不确定词集,需要进一步人工判别是否入库。至于词语相似度小于0.25则认为该词语不属于情感词,故舍弃[17]。
4 实验及结果分析
为了验证上述领域型情感词典构建方法的可用性及效果,本文研究进行如下实验。首先利用本文中第2节提供的数据采集及文本整理方法完成语料数据的收集与预处理工作,通过上述第3节中构建乡村型情感词典的方法,最终筛选到了11785条情感词。其中积极情感词6139条,负面情感词5646条。乡村型褒贬情感词典的部分情感词如表5所示。

表5 乡村型褒贬情感词典部分内容
本文随机选取500条测试集,通过人工判别标记测试集的情感倾向分别为:1代表积极倾向评论,0无情感倾向评论,-1消极倾向评论。针对不同两种不同的情感词典①乡村型褒贬情感词典,②具有一定知名度的知网HowNet情感词典,根据文献[18]中提供的情感倾向分类方法,分别计算测试集中每条测试集的情感倾向。以人工判别的测试集为基准,采用精确率(P)、召回率(R)、F值三个评估指标评估两种词典的性能。经计算得出如表6所示结果。
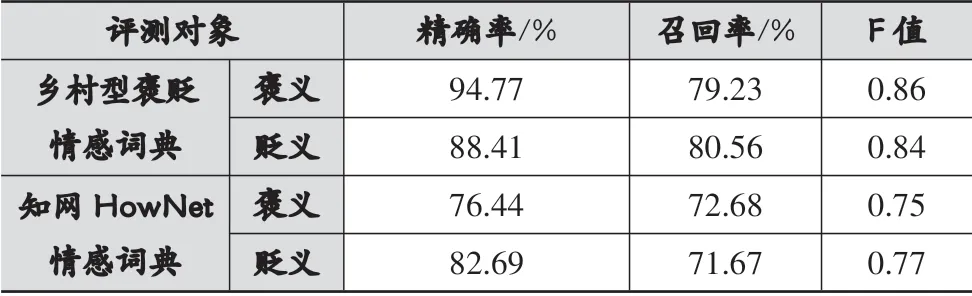
表6 两种类型情感词典的性能评估
表6结果表明,利用本文构建情感词典完成的情感倾向判别算法比利用知网HowNet情感词典评测结果的精确率略高。精确率略高的原因有二:一是由于语料使用的是微博评论,微博评论中经常会使用到不在知网HowNet词典中的同音字;二是由于网络发展日新月异,网民常用词也不断发生着变化,如:稀饭、high、钻石王老五,等等。本文中由于引进了N-Gram语言模型,对语料中常出现的网络用语进行捕捉,有效地减少了上述二者原因导致的误差。从精确率、召回率及F值中可以看出乡村型褒贬情感词典略优于知网HowNet情感词典,因此在婺源乡村旅游的情感分析上具有较高的准确性和可利用性。
5 结语
本文研究提出了一种基于在线评论的乡村型褒贬情感词典的构建方法,以N-Gram语言模型和义原相似度分析为基础,通过N-Gram语言模型筛选出语料中词频较高的未登录的潜在情感词,并与情感种子词的进行义原相似度计算,从而初步得出乡村型褒贬情感词典。整个情感词典的生成可由计算机自动进行,并结合必要的人工判别,使得新构建的词库具有较高的准确性。并且整个领域型情感词典的构建过程具有较高的可复制性,完全可以适用于其他领域的文本特征分类。
最后,研究尝试构建了基于乡村型褒贬情感词典的方法,但该方法仍存在一定的不足。未来可进一步对词库进行细粒,因此下一步将对乡村旅游领域型细粒度情感词典进行研究,并力求进一步提高文本特征分类的准确率。
猜你喜欢
动漫界·幼教365(大班)(2020年7期)2020-06-26
鸭绿江·下半月(2020年2期)2020-04-07
电脑爱好者(2017年5期)2017-05-04
读者·校园版(2015年7期)2015-05-14
山东青年(2014年10期)2014-11-24
心理学报(2014年4期)2014-02-02
网友世界(2009年12期)2009-03-05
