
低照度场景下的时空频域视频去噪算法
2021-08-07 10:26鲜连义康明
现代计算机 2021年17期
鲜连义,康明
(1.上海交通大学微纳电子学系,上海 200240;2.格科微电子(上海)有限公司,上海 201203)
0 引言
数字图像以及视频噪声的抑制起步较早,早期经典的去噪算法如:均值滤波、中值滤波、高斯滤波、维纳滤波[1]等在提出时都成为主流的优秀算法。伴随着图像去噪技术的不断发展,越来越多更加先进的算法被提出来,目前普遍的传统图像以及视频去噪方法包含空间域去噪[1]、变换域去噪[2-4]、时间域去噪[5-6]等等。
空间域去噪算法[1]的原理是利用二维图像空间直接采用相关操作如取平均等去除像素中的噪声,常见的操作方法基本是对具体像素点进行代数运算等,因而此类算法的复杂度较低,运算时间较快。变换域去噪[2-4]又叫频域去噪,不同于空间域去噪在二维图像空间内进行像素点的处理,它的主要思路是通过特定的变换规则如傅里叶变换等,将二维的图像矩阵数据转换到变换域内,以便于更容易的区分图像真值与噪声,将噪声过滤掉。图像从空间域转换到变换域的方法很多,其中最具代表性的有傅里叶变换、离散余弦变换[2]、多尺度几何分析方法[3]以及小波变换[4]等。但是这些方法[1-4]在处理过程中不可避免的会造成图像的平滑和细节的缺失。时间域去噪[5-6]主要的应用是多帧降噪算法,伴随BM3D[5]算法提出的同时针对视频降噪所提的VBM3D[6]算法,将时域的冗余信息加入视频去噪算法当中。在此之后不断有新的结合时间域去噪的算法例如VBM4D[7]算法等出现。但是这类的时间域去噪算法[5-7]往往需要进行多次块匹配,计算复杂度高,处理时间长。2018年Jana Ehmann等人提出了一种基于金字塔结构的视频去噪算法[8],可以实现高分辨率图像在Pixel2手机上30fps的去噪处理速度,基本满足了高分辨率图像实时性要求,但是去噪效果还有提升的空间。
为了克服上述一些方法[2-8]模糊图像细节[1-4]、计算复杂度高[5-7]、去噪效果受限[8]等的缺点和劣势,本文提出了TSF算法。TSF算法结合了时空域降噪的算法和频域降噪的原理,首先建立包含数字增益的低照度图像噪声模型,然后针对原始视频中的相邻前后两帧图像,基于光流法[9]完成图像配准得到位移图,在时空域对高频图像进行去噪和重构,进而结合后续噪声图像实现无限脉冲响应处理(Infinite Impulse Response,IIR),同时在空域进行降噪,输出后一帧去噪图像。所提TSF算法比实时视频去噪[8]算法具有更好的图像质量和纹理保持效果,与VBM4D去噪[7]算法相比,有效降低了运行时间。
1 低照度场景下的视频去噪算法
本文提出的低照度场景下的视频去噪算法处理流程如图1所示,从上到下的三个虚线框依次代表三个步骤:
(1)视频流前后帧的配准。
(2)视频流前后残差图像的融合和图像重构传播。
(3)对于融合和重构生成的低噪图像进行空间域去噪处理,得到输出结果。
配准步骤计算两个连续帧的位移图,融合步骤融合输入帧和前一帧图像的重构图像,最后空间域去噪处理得到当前帧的去噪结果。结合图1的详细流程,t和t+1时刻的图像分解为高斯和拉普拉斯金字塔。原始图像用于配准,拉普拉斯金字塔用于融合。融合金字塔经过重构生成与t+2时刻继续执行IIR处理的中间帧,该重构结果作为下一帧(t+2帧)融合步骤t+1时刻的输入,这样可以尽量保证空间域去噪造成的细节平滑不会传播到t+2帧的处理当中。同时低照度场景下的去噪当中仅仅采用时间域的去噪处理达不到最理想的处理效果,因此在本文的算法当中加入了空间域滤波的去噪处理模块。重构结果经过空间域去噪处理之后作为t+1时刻的最终去噪结果。
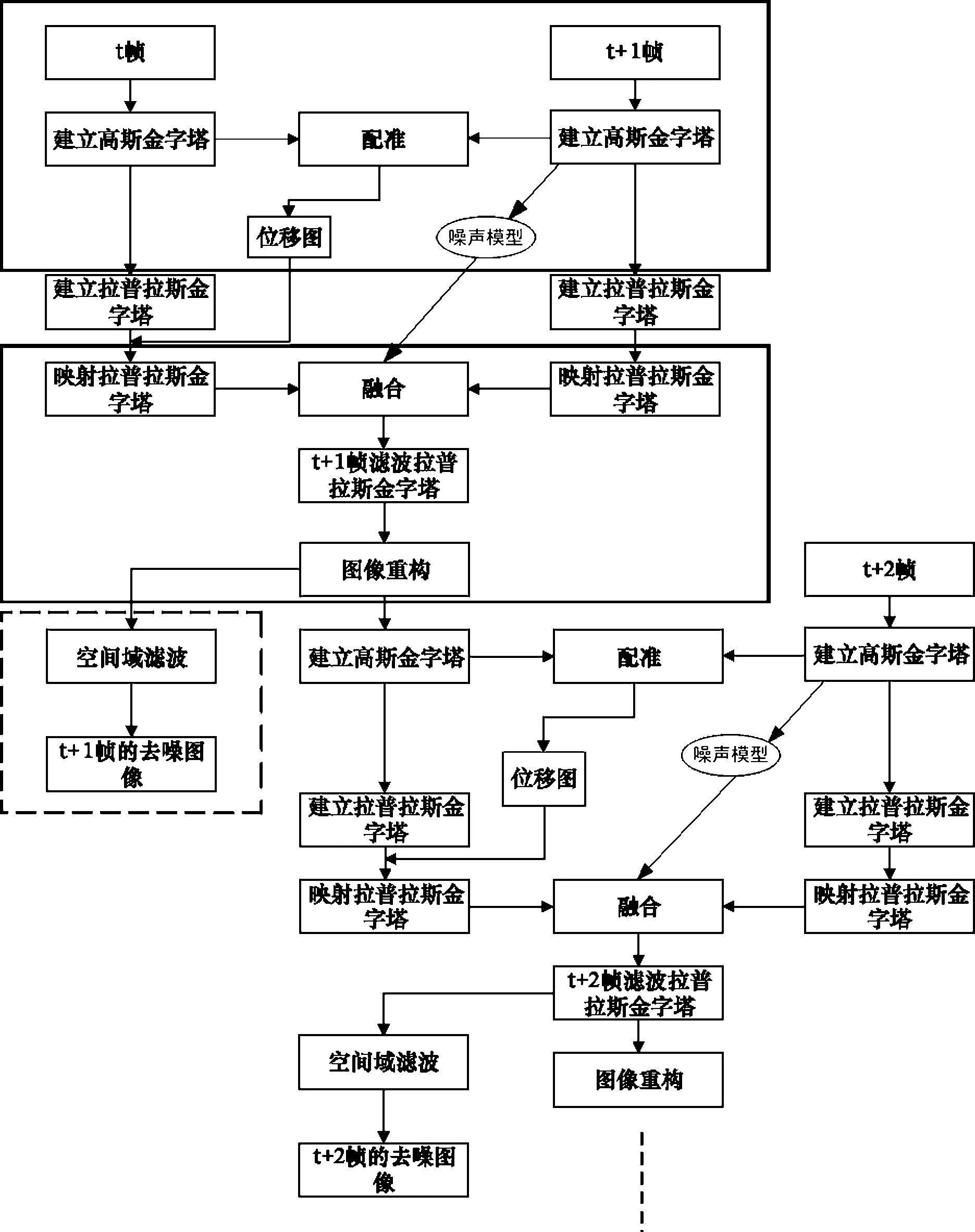
图1 本文算法流程
1.1 图像配准
图像配准是将多帧的图像对齐。如图1所示,建立t帧和t+1帧的高斯和拉普拉斯金字塔实现高频残差图像的提取,并且依据光流法进行图像配准得到位移图。在图像配准时使用快速的迭代逆光流法[9]加快处理速度。同时为了进一步减少处理时间,进行光流匹配时在除了原始图像这一金字塔层级以外的其他层级,采用整数级别的运动矢量来估计像素的运动。
1.2 图像融合
本算法的关键在于图像融合,融合效果相当程度上决定了最终的去噪质量。融合之后重构的图像用于IIR处理,即采用上一帧重构后的图像而不是未经处理的图像进行下一帧的处理。IIR处理对于去噪有很好的效果但是有潜在的伪影传播等缺点,本文设计的插值算法对配准错误有很好的健壮性,降低了伪影传播的影响。
首先利用位移图和前一帧的金字塔Lp建立重新映射的金字塔La,于是有:

(1)
其中上标l代表图像金字塔的级数,Al(p)代表位移图。
最终得到的图像金字塔是t+1帧拉普拉斯金字塔Lc与t帧拉普拉斯金字塔经过重新映射得到的图像Lp的融合,也即是:
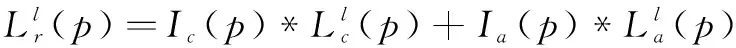
(2)
其中Ic(p)和Ip(p)是与像素位置、像素值以及噪声强度有关的插值函数。
为了更好地解释本文插值算法的设计原理,设Ldelta(p)=Lc(p)-La(p)作为像素值的差,通过与公式(2)比较得:
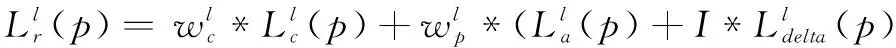
(3)
公式(3)当中的插值算子wc和wp分别是Ic的最小值和Ip的最大值,I是决定当前和之前像素的最终权重的插值因子。
1.2.1 建立低照度场景下的噪声模型
低照度场景下图像当中的信息很少,相应的噪声比例也就越大,因此需要针对低照度的场景建立相应的噪声模型用于辅助图像融合。本文的数据集是基于当前手机主流图像传感器在低照度场景下建立的数据集。噪声建模结合了文献[10-11]高斯-泊松噪声模型的方法,采用纯时域叠加的方式得到参考图像,比较噪声图像与参考图像的差异得到高斯-泊松噪声模型。需要注意的是低照度场景下数字增益也会影响图像和噪声数据,因此为了提升噪声模型的泛化性能,本文将数字增益也列入噪声模型当中,具体的噪声模型满足公式(4):
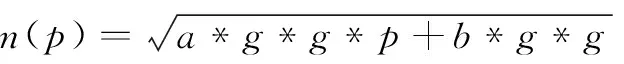
(4)
p为图像像素值,g代表数字增益,n(p)代表图像像素的标准差,a、b为曲线拟合参数。
依据公式(4)计算进而得到每一个像素的噪声水平nl(p)。由于算法的处理是在图像金字塔上实现的,因此针对于不同的图像金字塔层级l需要建立不同的噪声模型,应用到当前场景的算法流程当中进行算法下一步的处理。
1.2.2 自适应插值算子wc和wp
wc和wp分别代表当前图像和前一帧图像融合时的整体权重,对应地决定了去噪强度的下限和上限。wc越小,wp越大,去噪强度越大,相应的引入伪影也更多;wc越大,wp越小,引入的伪影会变少,但是去噪强度变小。算子在图像融合过程中起到平衡去噪强度和伪影的作用。同时图像金字塔的层级对应了不同的图像信号频率,在不同层级选择不同的算子,根据最终图像去噪质量的客观指标和主观评价得到最佳的算子搭配,这样就能得到图像质量更好,伪影更少的图像。
由于本文的去噪处理是针对视频而言的,某一帧图像插值算子的权重并不能适用于视频内的全部图像。如果在视频流当中采用恒定的插值算子wc和wp,当前帧所占整体权重维持不变,即相当于在视频处理的后续帧当中弱化了去噪性能,甚至引入了噪声。这样得到的去噪效果在视频流的前半部分提升了,后半部分却下降了,不能维持去噪效果的提升,因此需要在IIR处理过程当中不断的调整wc和wp。本文在视频流去噪处理当中设计动态的插值算子wc和wp,使得处理结果不仅能够实现图像去噪效果的提升,而且能够维持整个视频去噪效果提升的稳定性,具体的设计思想和方式如下文所述。
所提出的TSF算法基于IIR处理,处理的是重构后的前一帧图像和当前帧,重构后的图像是经过去噪处理的图像,噪声强度是减小的,因此在避免引入伪影的同时应当逐渐增大重构后图像的整体权重wp。本文采用有限脉冲响应(Finite Impulse Response,FIR)多帧降噪的算法思想来具体地改变wc和wp:即假设光流法得到的运动矢量结果是准确的,不包含块匹配错误,得到去噪图像也就是计算若干张噪声图像配准之后的融合结果。将FIR处理的思想应用到IIR处理当中得到动态的插值算子wc以及wp如公式(5)、(6)所示:
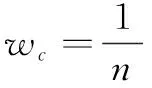
(5)
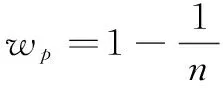
(6)
公式当中的n表示视频流处理的帧序。
随着视频流的输入,当前帧所占的比重在处理过程中不断降低,可以保证在视频流处理后期不会引入过多的噪声,稳定已有的去噪效果。
1.2.3 插值因子I的设计
插值因子I的选择是图像融合步骤的关键因素。wc和wp仅仅代表当前图像和前一帧图像融合时的的整体权重,而插值因子I则决定了融合步骤图像每一个像素的具体权重。在设计插值因子I时要考虑到不同的时空域处理对图像的影响,以在最少的伪影条件下得到更好的去噪效果。同时要考虑到在视频前期去噪处理过程中由于配准错误没有得到很好的配准效果时,算法处理需要更加保守以免在当前帧引入伪影。
对于I采用了文献[8]基于噪声改变和像素差异的插值算子的改进方法,以sigmod函数形式实现插值因子改进。
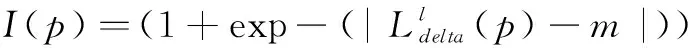
(7)
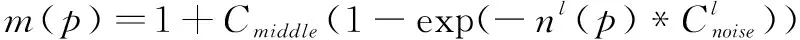
(8)
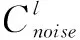
不同的噪声等级和像素值会令插值因子I有所差异,在不同的取值区间也会使I有不同的变化速度。在高噪声等级条件下尽管由于配准错误造成的像素值差异依然产生,此时的I依然可以灵敏的调节,通过令插值因子在接近0的过程有更大的波动范围,得到既能阻止来自之前帧的图像成分以减少伪影,又能取得更强去噪效果的处理结果。
为了防止伪影的过度传播,在对于I> 0.5的像素位置算法设置了一键关闭时域去噪效果的设计,此时使用空间域的双边滤波处理配准错误的区域,达到时空域联合去噪的处理效果。
1.3 空间域滤波处理
本文处理的图像是基于低照度场景下的噪声视频图像,因此单纯的时间域去噪处理并不能达到最理想的去噪效果。虽然在本算法融合步骤的处理之中包含了空间域去噪的处理,但是图像配准错误的区域并不占据很多的成分,导致空间域去噪占比也相当有限。因此在得到当前帧的重构图像之后,在该图像上进行空间域去噪的处理,例如双边滤波、引导滤波[12]、非局部均值算法[13-15]等可以继续提升图像质量。所提出的TSF算法采用了与BM3D[7]算法当中“两步估计”类似的思想,先得到相对噪声较小的图像,再在此图像之上实现接下来的空间域去噪处理,得到峰值信噪比和结构相似度更好的去噪图像。为了降低复杂度,本文采用双边滤波空间域去噪处理。同时为了防止视频流处理过程中空间域滤波平滑效果的传播,如图1所示,算法在进行空间域双边滤波之前就将t+1时刻的重构图像去与t+2时刻图像重复执行配准和融合等IIR处理,这样可以在达到更好的去噪效果的同时有效地防止细节平滑的传播。
2 实验结果与对比
2.1 数据集的选择与处理
当前的数据集采用当前手机主流4800万像素图像传感器在低照度场景下获取。数据集包含了36种场景,光照条件包含0.32lux、0.8lux和1.5lux;曝光时间包含1/15秒和1/30秒;场景包含静态、动态(大运动和小运动)、色卡、手持、窗户六个场景,每个场景拍摄60帧图片(色卡场景除外),共计1848张图片,数据集大小17.4G。由该图像原始数据经过去黑电平,合并的图像读出方式等预处理得到灰度图像数据,进行下一步去噪处理。
2.2 结果对比与分析
本文算法的处理是在Intel Core i7 10750H 64位操作系统,16G内存,Visual Studio 2015平台下进行的。所提出的TSF算法在0.8lux光照,曝光速度30f条件下的视频流处理效果折线图以及各个场景下与VBM4D[7]、实时视频去噪[8]等方法的结果数据对比如图5和表1到表6所示。
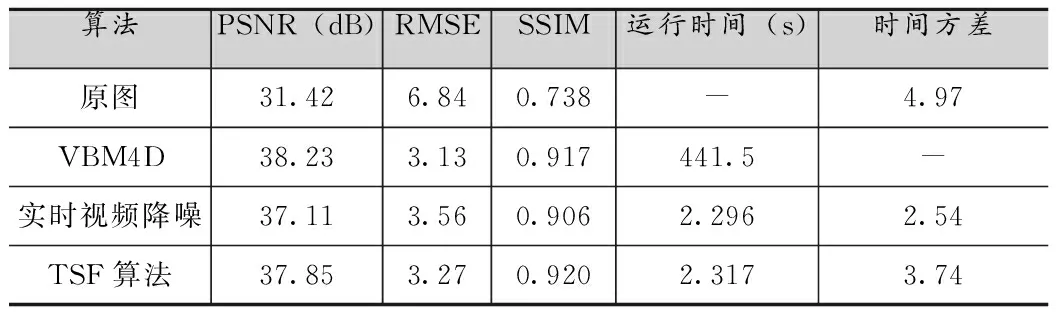
表1 0.32lux光照,曝光频率30f的静止场景处理结果对比
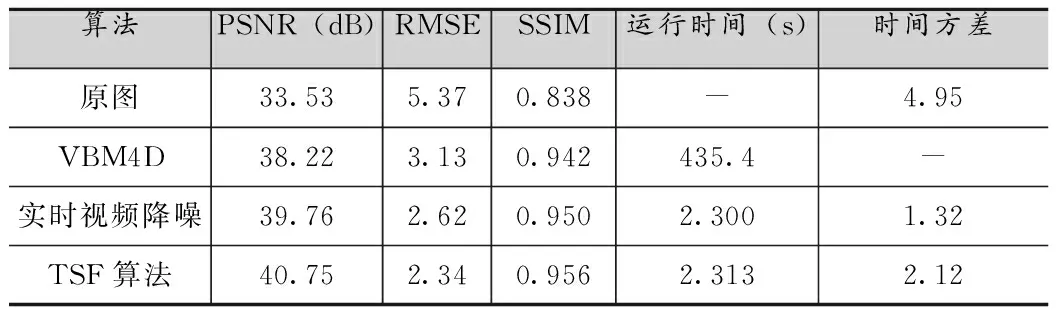
表2 0.32lux光照,曝光频率15f的静止场景处理结果对比
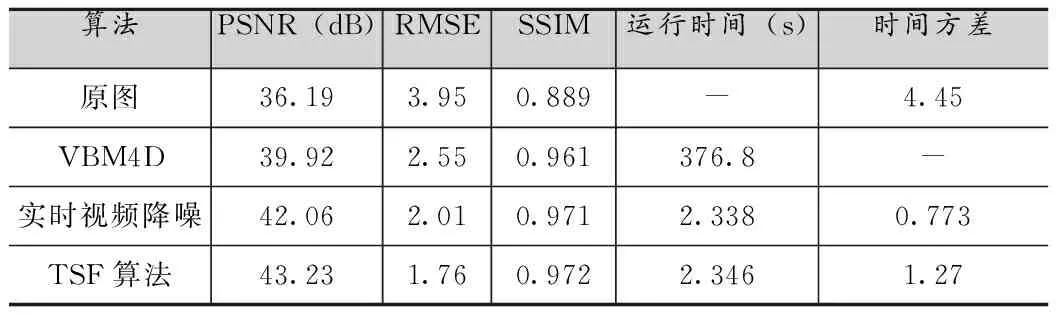
表3 0.8lux光照,曝光频率30f的静止场景处理结果对比
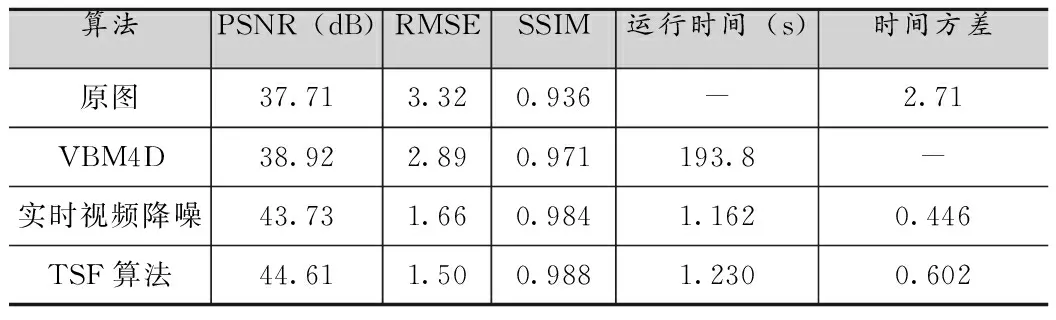
表4 0.8lux光照,曝光频率15f的静止场景处理结果对比

表5 1.5lux光照,曝光频率30f的静止场景处理结果对比
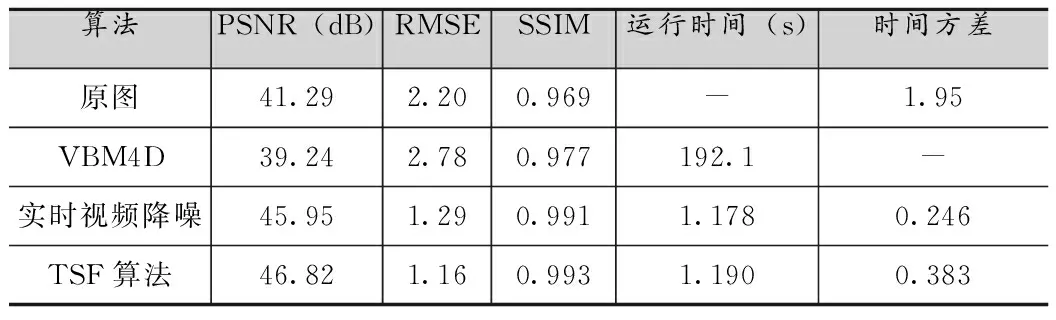
表6 1.5lux光照,曝光频率15f的静止场景处理结果对比
由图2和表1到表6可知,所提出的TSF算法在峰值信噪比(PSNR)、均方根误差(RMSE)、结构相似度(SSIM)和视频流处理稳定性方面(图2)得到了更好的客观指标,但是由于添加了空间域去噪的处理,相应的处理时间延长约0.01-0.02s,时间方差也依据具体环境有所上升。以表2为例,在光照为0.32lux,曝光速度15f条件下,TSF算法比实时视频降噪[8]算法PSNR提高了0.99dB,RMSE降低了0.28,SSIM也有所提升,相比而言处理时间仅仅延长了0.013s,时间方差也只提高了0.8左右。这是因为TSF算法采用了低照度场景下的噪声建模方式,同时针对该场景利用时空域相结合的去噪方式,对于采用的数据集产生了更好的去噪效果,显著提高了图像的质量,相比于实时视频去噪算法[8]提升效果明显,和一些其他如VBM4D[7]这种离线复杂度很高的算法也有很好的可比性。
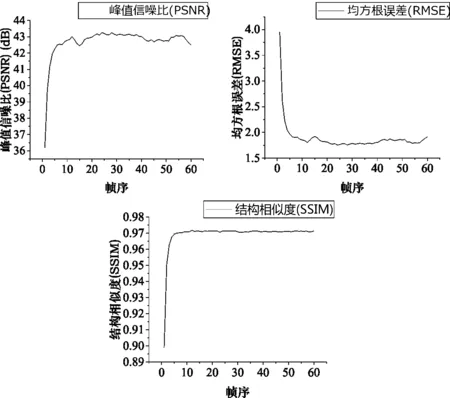
图2 (a)、(b)、(c)分别为0.8lux光照,曝光速度为30f的场景下视频流处理PSNR、RMSE、SSIM结果
2.3 主观评价对比与分析
2.3.1 静态场景比较
由图3可以看出VBM4D[7]算法由于包含多次的块匹配,因此对于图像的周期纹理去噪效果最好,但是考虑到处理时间可以知道它的复杂度很难实现实时化处理。本文的算法处理结果在主观去噪效果上与VBM4D[7]算法相近,并且明显优于实时视频去噪[8]算法。算法没有采用块匹配的策略,并且针对低照度场景做了相应的噪声建模和插值算子优化,添加了空间域滤波的算法处理,获得了相比于VBM4D[7]算法处理时间的优化和比实时视频降噪[8]算法更好的主观去噪效果。

(a)(b)
2.3.2 动态场景比较
与静态场景相比,动态场景的去噪效果更能反映算法的有效性和应用性。图4为0.8lux光照强度,曝光速度每秒30帧的动态场景下视频流部分连续帧去噪结果,比较可以看出先经过频域分隔处理的时空域去噪,然后通过空间域去噪处理之后,算法的去噪效果明显,并且在本文设计的动态插值算子调节下尽量避免了产生伪影、撕裂等缺陷,反映出本文动态插值算子设计的有效性。

(a)(b)
3 结语
对于传统视频去噪方法处理低照度场景视频的去噪效果有限,并且块匹配方法计算复杂度过高,处理时间过长等问题,本文提出了一种相对快速的视频去噪方法。所提出的TSF算法建立包含数字增益的低照度图像噪声模型,结合了时空域的降噪方法,同时利用高斯和拉普拉斯金字塔实现了频域的处理,相比于实时视频去噪算法[8]在客观的评价指标PSNR、RMSE、SSIM等方面得到了较高的提升,达到了优秀的去噪效果,同时并没有引起很大的额外时间处理开销。在主观评价方面也得到了很强的图像去噪增强的感受。算法的不足之处在于还没有实现实时处理,因此在接下来的工作当中要在保持去噪效果的同时优化处理时间,进一步优化算法和降低算法的复杂度。
猜你喜欢
科学与生活(2021年14期)2021-09-10
人民黄河(2021年4期)2021-04-27
环境与发展(2018年6期)2018-09-17
城市地理(2017年9期)2017-11-02
物流科技(2017年5期)2017-07-06
电子技术与软件工程(2017年6期)2017-04-14
软件(2016年4期)2017-01-20
计算技术与自动化(2014年1期)2014-12-12
