
模糊云资源调度问题的RIOPSO 算法
2021-08-07 07:42李成严马金涛
计算机与生活 2021年8期
李成严,宋 月,马金涛
哈尔滨理工大学 计算机科学与技术学院,哈尔滨 150080
云资源调度是云计算中的核心内容,文献[1]为了使完工时间最短,建立了相应的云计算调度模型。文献[2]在调度过程中,保证服务质量的前提下,使云服务提供商获取最大的利益。文献[3]为了使能源消耗最小,建立了实时调度系统。以上这些研究中,使用的都是确定的执行时间。但是由于任务执行的不可预见性,在任务执行完成之前,执行时间只能是一个估计的值,这就导致任务的执行时间具有不确定性,因此本文在建立云资源调度模型时,对任务执行时间具有不确定性的情况进行了考虑。在解决实际问题时,数学模型可以分为三类,分别为确定性的数学模型、随机性的数学模型和模糊性的数学模型,对于不确定的需要估计的问题,就需要模糊数学模型进行解决。文献[4]使用模糊遗传系统对疾病的诊断时间进行了时间复杂度的分析,文献[5]研究了云环境下基于模糊神经网络算法的作业调度。在本文中,使用三角模糊数对不确定的任务执行时间进行表示[6],建立了模糊的云资源调度模型。
云资源调度问题是一个NP 完全问题[7],没有有效的多项式算法。为解决云资源调度问题,国内外学者常常采用智能优化算法来实现上述目标。智能优化算法包括遗传算法(genetic algorithm,GA)[8],粒子群算法(particle swarm optimization,PSO)[9]和蚁群算法(ant colony optimization,ACO)[10]等。相比于GA 算法,PSO 算法在处理和实现上不存在重叠和突变现象,因此PSO 算法在求解云资源调度问题时比GA 算法速度快。相比于ACO 算法,PSO 算法更容易获取初始解,可以更有效地对云资源调度问题进行优化。综合考虑,由于PSO 算法在分布式环境中计算速度较快,处理时间较短,本文使用了一种基于粒子群的优化算法对云资源调度问题进行求解。
在PSO 算法寻求最优解的过程中,存在收敛精度不高,容易陷入局部最优解,容易产生早熟收敛的问题,针对以上缺点和不足,本文提出了一种混合粒子群优化算法(re-randomization inertia weight orthogonal initialization particle swarm optimization,RIOPSO)。采用重新随机化[11]的方法使粒子群能够充分搜索解空间,避免粒子陷入早熟。采用实时更新惯性权重[12]的方法,控制粒子在搜索过程中的速度,防止陷入局部最优。本文还采用正交矩阵对粒子种群进行初始化[13],使粒子群获得有序的初始解,在粒子初始探索解空间时能够更有效率。本文同时使用以上三种优化方法,使PSO 算法在搜索过程中,得到的解的质量更高,同时增强粒子的搜索能力,从而得到最优解。
1 相关工作
1.1 多目标问题
多目标问题(multi-objective problem,MOP)往往由于多个目标之间相互冲突,而无法获得使每一个目标都达到最优状态的最优解[14]。针对这一问题,将求解算法分为以下三种方式:
(1)基于帕累托支配的多目标进化算法[15]。由于目标函数的增多,最优解解集有时过于庞大,导致以该方法求解多目标问题时,容易产生消息溢出的问题[16]。
(2)基于性能指标的多目标进化算法[17]。在使用性能指标作为算法的进化的参考信息时,对于性能指标的计算过于复杂,导致运行时间较长[18]。
(3)基于分解的多目标进化算法[19]。将对多目标问题求解转化为对多个单目标协同求解,引入分解的思想,将复杂的多目标问题简单化。该算法求解效率高,解集性能较优。Zhang 等[20]提出的多目标进化算法(multi-objective evolutionary algorithm based on decomposition,MOEA/D)效果尤为显著。
相比于其他两种算法,基于分解的多目标进化算法,对于处理组合优化问题,有着较强的搜索能力。云资源调度的优化目标包括使总完成时间最短,使资源的消耗最少,满足QoS 等,本文的主要研究目标是在有限资源下,使云资源调度能够在时间-成本约束下完成调度目标。因此本文利用MOEA/D算法的分解思想,使用妥协模型,对时间和成本约束下的目标评价函数进行权重分解,根据权重占比,同步优化时间和成本的目标函数。
1.2 算法与性能指标
为了验证本文提出的RIOPSO算法在求解多目标云资源调度的问题时,收敛性和多样性都能够得到保证,本文将使用NSGA-Ⅰ算法[21]、NSGA-Ⅱ算法[22]、NSGA-Ⅲ算法[23]和MOEA/D 算法[24]四种主流算法与本文提出的RIOPSO 算法进行对比实验。
随着多目标优化算法的提出,如何评价算法的优劣也成为一个重要的研究方向,在多目标优化算法解决多目标问题时,可以使用性能指标对算法性能进行量化比较。常用的性能指标可以分为:准确性度量指标、多样性度量指标和综合度量指标三类。
在上述算法求解多目标云资源调度问题时,使用两个综合度量指标,反向世代距离(inverted generational distance,IGD)[25]和超体积(hypervolume,HV)[26]指标,准确性度量指标覆盖率(coverage-metric,CMetric)[27]指标,对算法的性能进行量化,并且通过量化后的性能对上述算法进行对比评价。
本文使用模糊数学模型,对不确定执行时间的多目标云资源调度问题进行求解。并且对如何能够高效地找到最佳调度方案提出了优化算法。
2 模糊云资源调度问题
2.1 云资源调度模型
在云资源调度中,任务需要根据可行性算法在虚拟机上执行,并且每个任务只能在一个虚拟机上执行,但是虚拟机可以根据需要执行多个任务。现在有m个任务TASK={Task1,Task2,…,Taskm},有n个虚拟机VM={Vm1,Vm2,…,Vmn},虚拟机个数n远小于任务个数m。
由于云资源调度中虚拟机和任务之间存在一对多的关系,可以将它们之间的映射关系表现为图1 的形式。从图中可以看出,每个任务只能在一个虚拟机上执行,每个虚拟机可以执行多个任务。如图1 所示,代表一种调度方案Rk。
图1是在云资源调度模型中用到的一些基本定义。
定义1timeij表示任务i在虚拟机j上执行的时间,其计算公式如下:

其中,taskSizei表示第i个任务的大小,vmSpeedj表示第j个虚拟机的处理速度,均在给定的范围内随机生成。
定义2vmTimej表示在虚拟机j上的任务执行时间,其计算公式如下:

Fig.1 Task-VM mapping relationship图1 任务-虚拟机的映射关系

其中,Xij表示任务i是否在虚拟机j上执行,如果任务i在虚拟机j上执行,那么Xij=1,否则Xij=0。
定义3vmCostj表示在虚拟机j上的任务执行成本,其计算公式如下:

其中,costj表示单位时间内虚拟机j的执行成本,虚拟机执行成本由虚拟机的处理速度经过规则运算得到。
定义4Time(Rk)表示调度方案Rk的总的执行时间,由于任务的并发性,调度方案的总的执行时间就是执行时间最长的虚拟机的执行时间,其计算公式如下:

定义5Cost(Rk)表示调度方案Rk的总的执行成本,调度方案总的执行成本就是所有任务执行消耗的成本的和,其计算公式如下:

在求解最优调度方案时只考虑时间因素,那么时间约束函数为:

其中,Timemin、Timemax代表任务在虚拟机上执行的最短时间和最长时间。
如果只考虑成本因素时,成本约束函数为:

其中,Costmin、Costmax为任务执行所需的最低成本和最高成本。
由于只考虑时间因素或成本因素,考虑因素过于单一,并不能得到一个使得云资源提供者和云资源消费者都满意的方案。文献[28]提到,云资源提供者想要以较低的成本提供服务,而云资源消费者想要以较快的时间执行完任务。因此通过综合考虑,为了达到能够使云资源提供者和云资源消费者都能满意的目的,提出时间-成本约束条件,将时间因素(6)和成本因素(7)通过式(8)将多目标问题转化为单目标的问题。评价函数为:

其中,t代表时间因子,c代表成本因子,本文通过改变t和c的值,来决定调度方案中时间因素和成本因素所占的比例,进一步控制时间和成本对于评价函数的影响。
时间-成本条件约束下的云资源调度模型为:

根据调度模型P,对每一种调度方案进行评价,得到最小的评价函数值,对应的调度方案就是最优调度方案。
2.2 模糊云资源调度模型
根据式(1)得到的是任务在虚拟机上执行的确定的时间。但是由于在实际执行过程中,任务的执行具有不确定性,本文使用三角模糊数对任务执行时间进行不确定表示。
使用三角模糊数给出任务执行时间的模糊范围,通过式(10)和式(11)对任务在虚拟机上的执行时间的波动范围进行上下范围的判定。
任务执行时间的模糊下限:

任务执行时间的模糊上限:

其中,Rand()表示在(0,1)中的随机数,α1和α2分别表示上、下界的模糊系数。将任务的执行时间进行模糊之后,表示为,其中tL代表任务执行的乐观时间,tM代表任务执行的最可能时间,tR代表任务执行的悲观时间。
根据三角模糊数的线性特征和可分解性,使用模糊后的执行时间计算相应的评价函数值,将式(9)转换为式(12):

文献[29]提出了一种判别规则,通过计算三角模糊数的平均值和标准差,判定谁的模糊性能更好。如果一个模糊数具有较高的平均值和较低的标准差,则认为该模糊数排序更高。
根据上述方法,可将确定的云资源调度模型转化为不确定任务执行时间的模糊云资源调度模型。调度的目标转化为对评价函数的平均值和标准差的计算,然后根据三角模糊数的加法运算和数乘运算,利用三角模糊数的特性,得出不确定任务执行时间下的云资源调度的问题模型,如式(13)所示。

其中,Pη为模糊数的平均值,Pμ为标准差,∂是对不确定度的加权系数。
3 RIOPSO 算法
3.1 PSO 算法分析
PSO 算法是模拟鸟类觅食行为的一种进化算法,通过迭代的方式,以个体最优寻找全局最优,从而得到最终的结果。本文使用不确定执行时间下的粒子群优化算法,对云资源调度问题进行求解。最优调度方案的判断是通过评价函数的取值进行评价的。表1 是PSO 算法中需要用到的参数的定义。

Table 1 Parameter list表1 参数列表
在PSO 算法中,粒子可以模拟鸟类的觅食行为,在G维空间中进行寻优。在粒子群中有N个粒子,其中第i个粒子的位置为:

速度为:

粒子在迭代过程中通过对表1 中的速度的更新来进行位置的更新。
粒子群在寻优的过程中,通过比较评价函数的值找到个体最优和全局最优,之后对速度和位置进行迭代更新,其中在第k次迭代时,第i个粒子的个体最优值为pBesti,全局最优值为gBestk。粒子i的速度更新公式为:

粒子的位移更新公式为:

如何使用PSO 算法解决云资源调度的问题,首先将PSO 算法中的粒子与云资源调度中的任务和虚拟机进行对应。粒子解空间的维数取决于云资源调度中的任务数。每一维的取值范围就是云资源调度中被分配到的虚拟机数,即每一维的解对应的就是虚拟机的编号。粒子每一次的迭代更新的过程,粒子的位置就会发生相应的进化,就会产生一个新的进化粒子,产生一个如图1 所示的新的任务和虚拟机之间的对应关系,一个新的调度方案。
对一个任务数为8,虚拟机数为3 的云资源调度来说,使用的PSO 算法中,粒子群中相应的粒子有8维,每一维的取值可以是0、1、2。对于任务和虚拟机之间的对应关系,表2 为粒子的一种可能表示方式。

Table 2 Expression of a particle表2 某一粒子的表示
3.2 正交初始化
在PSO 算法中,粒子的寻优过程需要通过迭代来进行。粒子群的初始状态对之后的寻优过程有着直接的影响,在粒子搜索的初始阶段,初始解越有序越利于之后的粒子迭代搜索。在种群初始化时,要尽可能保证粒子均匀分布在解空间中,这就使得在初始化阶段要满足粒子具有各个方向的解。在PSO算法中,随机初始化种群,并不能保证粒子能够均匀分布在解空间中,有可能使粒子集中在一个区域,或者使粒子的相似程度过高,都不利于之后的寻优过程。在本文中使用正交矩阵初始化种群的方法,使整个种群均匀分布在可行解空间中。
当系统有Ele种元素,且每种元素都有Lev种水平,那么一共会有LevEle个组合数产生。如果在实验中将这LevEle个组合全部进行实验,当Lev和Ele很大时,会产生许多相似的组合,用这些组合做的实验达不到好的效果,拟合度过高。因此构建正交矩阵G=Lrow(LevEle),初始化种群,能够筛选出均匀分布在解空间中的粒子,使用较少的组合进行实验,从而使得粒子种群减小。这样使用了较少的粒子,却能够达到更好的效果。其中,row 代表一共有多少组水平组合数,row 远小于LevEle。
对任务数为4,虚拟机数为3 的云资源调度问题,使用正交初始化粒子种群的方式进行举例。如果将每一个任务在每一个虚拟机上都执行,那么需要进行34=81 次的实验。但是如果采用正交初始化的设计,只需要进行9 次实验,就能够找到代表性的解。而且随着虚拟机数量和任务数量的增多,正交初始化就更能显示出“均匀分散,齐整可比”的特点。
表3 就是使用正交矩阵,初始化虚拟机数为3,任务数为4 的云资源调度的分配方案。

Table 3 Orthogonal initial population表3 正交初始种群
从表3 可知,使用正交矩阵初始化种群,只需9个初始解就可以均匀分布在解空间中。每一行代表一种调度方案,列数代表任务数,每一个数字代表执行任务选择的虚拟机编号。
对于构建正交矩阵,首先需要确定基本列,然后根据基本列构建非基本列,基本列和非基本列的和就是需要构建的正交矩阵的列数,也就是一共需要被执行的任务数。基本列J满足式(18),下面是创建正交矩阵的伪代码。

算法1
步骤1构建基础列

步骤2构建非基础列

步骤3将ai,j进行加1

创建基本列和非基本列之后,已经将一个完整的正交矩阵构建完成,但是最终想要得到的是适合粒子群初始化的矩阵,就要对创建出来的矩阵进行列的取舍。算法2 得到最终的矩阵。
算法2

这样就构建了用来初始化种群的正交矩阵。
3.3 重新随机化
根据PSO 算法容易陷入局部最优的缺点,采用能够使粒子跳出局部最优的重新随机化的方法对粒子寻优能力进行优化,使粒子在解空间中能够探索的范围更大,寻优效率更高。通过计算方差的方式对粒子进行迭代更新,确保粒子能够获得更优的解。
根据式(19)得到适用于粒子种群的方差值,然后根据得到的方差对粒子群进行迭代更新。

在式(19)中,k代表当前迭代次数,A表示重新随机化的有效初始值,S代表坡度,它控制粒子的搜索范围。在搜索过程中,第一部分称为大范围搜索,即广泛搜索,此时方差曲线的坡度较大,使得粒子能够在远离全局最优粒子gBest的搜索空间进行随机搜索。第二部分称为小范围搜索,即精细搜索,此时方差曲线的坡度较小,粒子在靠近全局最优粒子gBest周围进行随机搜索。两部分结合起来能够使得最后粒子收敛到最优解,从而使得粒子能够在全局范围内进行搜索,跳出局部最优,搜索到最优解。M是对应方差曲线坡度中点的迭代次数,两部分通过中间点M进行分割,中间点M决定广泛搜索和精细搜索的搜索时间。
3.4 更新惯性权重
粒子在解空间中寻优时,粒子的收敛速度影响粒子在搜索过程中是否能收敛到当前最优状态。粒子的惯性权重值是PSO 算法中的重要参数,通过调整粒子在每一次迭代过程中的惯性权重,来控制粒子的收敛速率。当粒子的惯性权重较大时,粒子搜索范围增大,收敛速率过慢,不易得到精确的解;当惯性权重较小时,粒子的搜索范围减小,收敛速度过快,容易陷入局部极值。根据粒子收敛过程中的这一特性,本文使用实时更新惯性权重的方式,和重新随机化相结合,使粒子能够探索到整个解空间的同时,控制粒子的收敛速率。
根据粒子在每一次迭代过程中评价函数的变化,对惯性权重值进行更新。当迭代之后的粒子的评价函数值变小,那么该粒子的惯性权重值将增加或者保持不变;如果该粒子的评价函数值变大,那么将对该粒子的惯性权重值进行减小。对应公式为式(20),对第i个粒子的惯性权重值进行实时更新。

其中,ωi(k)表示当前第i个粒子的惯性权重值,取值范围为(0,1),S代表期望的评价函数值的范围,ΔJi(k)代表该粒子当前评价值与前一个状态评价值的差值。
在重新随机化和更新惯性权重之后速度的更新由式(16)变为式(21)。

粒子的位置更新公式为:

其中,variance(k)就是重新随机化中的方差,取值由式(19)决定。ωi(k)就是每一个粒子在每一次更新中的惯性权重值,取值由式(20)决定。
RIOPSO 算法的流程图如图2 所示。

Fig.2 Algorithm flowchart图2 算法流程图
4 仿真实验
4.1 数据的生成与参数的选择
为了分析和比较本文提出的模型和算法的性能,在云计算仿真平台Cloudsim 上进行仿真实验。时间和成本对实验的结果都有影响,本文将式(8)中的时间因子t和成本因子c都设置为0.5。本文采用文献[30]的数据生成方法产生数据集,使生成的任务大小和虚拟机处理速度分别在范围[3 000,130 000]和[300,1 300]之内。根据得到的任务的大小和虚拟机的处理速度,使用2.1 节中的计算方式,就可以得到任务在虚拟机上的执行时间和执行成本。
在RIOPSO 算法中,粒子群的速度、位置和惯性权重值的更新都是根据评价函数的取值是否变化,来进行迭代更新的。在参数设置中,个体学习因子C1和群体学习因子C2的取值,对实验结果有所影响。当C1=1,C2=0 时,说明当前的粒子只受其个体最优值pBest影响,对当前的全局最优粒子的学习能力为0;而C1=0,C2=1 时,说明当前粒子的更新只受全局最优gBest的影响,对该粒子个体的学习能力为0。在本文中将个体学习因子C1和群体学习因子C2均设置为0.5。
本文实验中各项参数设置如表4 所示。

Table 4 Setting of experimental parameters表4 实验参数的设置
在本文进行的实验中,除算法改进策略不同外,均使用相同的数据集和实验参数,在同一模型和同一环境下对云资源调度问题进行求解。
4.2 算法性能指标评价分析
使用算法NSGA-Ⅰ、NSGA-Ⅱ、NSGA-Ⅲ和MOEA/D 与本文提出的RIOPSO 算法求解云资源调度的问题。
(1)NSGA-Ⅰ算法。非支配排序遗传算法,与遗传算法相比在选择算子执行之前,根据个体间的支配关系进行了分层。
(2)NSGA-Ⅱ算法。带有精英保留策略的快速非支配多目标优化算法,采用了拥挤度比较的策略,是一种基于帕累托最优解的优化算法。
(3)NSGA-Ⅲ算法。在NSGA-Ⅱ算法的基础上,提出一种参考点的选择操作,代替NSGA-Ⅱ算法中的拥挤距离的选择操作。
(4)MOEA/D 算法。一种基于分解的多目标进化算法。
使用上述算法解决云资源调度问题时,分别计算此时的IGD、HV 和C-Metric,以此量化各个算法的性能。
(1)IGD 是算法的综合性能评价指标,对帕累托前沿上的解与算法获得的解的最小距离进行计算。IGD 的值越小,说明算法得到的解分布越均匀,同时收敛性越好。
(2)HV 对非支配解覆盖解空间的大小进行度量,HV 的值越大,证明该算法解的质量越高。
(3)C-Metric的计算基于帕累托解集的支配关系,该性能指标通过两组帕累托前沿计算收敛性能。例如C(A,B)=1 表示B中的所有个体均被A中的支配,而C(A,B)=0 则表示B中的个体没有被A支配。
表5 所示为五种算法的性能对比结果。性能指标结果使用均值进行记录。

Table 5 Performance comparison of five algorithms表5 五种算法性能对比
从表5 中可以看出,RIOPSO 算法在IGD 性能比较中,具有最小的IGD 值,说明RIOPSO 算法获得的解集分布均匀,能够使种群更好地收敛到近似帕累托前沿面,综合性能较好。通过超体积指标HV 看出,RIOPSO 算法获得的非支配解与参考点之间构成的目标区域空间最大,相对于其他四种算法也具有最好的求解性能。从C-Metric 覆盖率来看,RIOPSO算法中支配关系均少于其他几种算法,这是由于RIOPSO 算法使用正交初始化的策略,在初始阶段就获得了较高质量的解集,从而获得收敛性能更好的最优解。
综上所述,使用本文算法改进策略在求解云资源调度问题时能够在提高解质量的同时,使算法的综合性能更好。
4.3 模型对比
由于在实际生活中,云资源调度的过程中存在任务执行的异步性和不确定性,本文使用三角模糊的方法,对问题模型进行了处理,使结果更加贴近实际。下面本文将对执行时间确定和不确定两种情况的实验结果进行比较。将每一个确定的执行时间进行三角模糊表示时,要对执行时间模糊之后的数进行左右范围的确定,设置式(10)和式(11)中的参数α1=0.9,α2=1.2。相同的任务规模通过评价函数的平均值进行比较。图3 为确定模型和模糊模型的对比结果。通过图像可以看出,使用模糊模型,评价函数的值将会比确定模型下的评价函数的值高,这意味着对于不确定因素的考虑是很有必要的。如果忽略这些不确定的因素,将会导致实际效果和理论估计效果产生偏差而降低系统的效率。

Fig.3 Model comparison图3 模型对比
4.4 算法性能对比
为了分析本文提出的改进策略的具体优势,将本文提出的RIOPSO 算法与其他三种算法进行对比分析。其中SPSO(re-randomization particle swarm optimization)算法使用了重新随机化的策略[31],没有对问题的初始条件进行改进。SWPSO(re-randomization inertia weight particle swarm optimization)算法将重新随机化和实时更新惯性权重进行结合[32],初始化种群时使用的是随机方法。OPSO(orthogonal initialization particle swarm optimization)算法使用正交初始化种群的方式[33]对PSO 算法进行优化。
为了能够更直观地看到本文算法的效率和更好的寻优能力,将本文提出的RIOPSO 算法,同上述提到的SPSO、SWPSO、OPSO 算法进行对比分析,在任务规模为100、200、300,虚拟机个数为5 的情况下,对四种算法分别进行寻优测试,并且进行记录,实验结果如图4~图6 所示。其中横纵坐标分别代表迭代次数和算法对应的评价函数值。

Fig.4 Comparison of algorithm optimization capabilities(100 tasks)图4 算法寻优能力对比(100 个任务)

Fig.6 Comparison of algorithm optimization capabilities(300 tasks)图6 算法寻优能力对比(300 个任务)
由图4~图6 可以发现OPSO 算法和RIOPSO 算法的初始评价函数均优于其他两种算法,这是因为初始解的质量高,相应的也就提高了粒子群的搜索效率,证明了正交初始化策略的有效性。但是从迭代曲线中看出,由于粒子在搜索最优解的过程中可能会陷入局部最优状态,OPSO 算法并不一定能获得优于其他三种算法的解。相对比SPSO 算法,SWPSO算法和RIOPSO 算法在控制粒子搜索范围的基础上增加了对粒子搜索速度的控制,这使得粒子在搜索过程中能够跳出局部最优,更好地收敛到全局最优解。从图中还可以发现,无论是在大规模任务还是小规模任务中,综合了以上三种策略的RIOPSO 算法,都能够使用较少的迭代次数得出优于其他三种算法的解,减少了算法的运行迭代时间。因此RIOPSO 算法能够具有寻优速度快,寻优能力强,寻优效果好的特点。
为了验证在相同的任务数,不同的虚拟机数的情况中,RIOPSO 算法的能力,在4 个不同的数据集上进行了多次测试,任务和虚拟机的个数分别为(100,5),(100,10),(100,15),(100,20),实验结果取平均值后如图7 所示。其中横坐标表示任务数为100 时对应的虚拟机的数目,纵坐标表示评价函数值。

Fig.7 Comparison of optimization capabilities under same task scale图7 相同任务规模下的寻优能力对比
通过图7 可以看出,在相同任务数,不同虚拟机数的情况下,RIOPSO 还能够搜索到比以上三种算法更优的解,得到更优的调度方案。
根据图7中各个算法的评价函数值,建立了SPSO算法、SWPSO 算法、OPSO 算法的评价函数值大于RIOPSO 算法的评价函数值的相对差值百分比图像。如图8 所示,横坐标代表虚拟机个数,纵坐标代表相对差值百分比。从图中可以看出,无论虚拟机规模是多是少,相比于其他三种算法,RIOPSO 算法的寻优能力提升最高,进一步证明RIOPSO 算法的有效性。

Fig.8 Comparison chart of algorithm optimization ability improvement图8 算法寻优能力提升对比图
在时间因子t和成本因子c均为0.5 时,使用以上四种算法对不同任务规模的调度模型进行多次实验,对得到的调度方案中的任务运行总时间和任务运行总成本,分别计算取平均值,运行的虚拟机个数均为5。图9 所示为四种算法运行的任务执行总时间,图10 所示为任务执行的总成本。横坐标均为任务规模,纵坐标分别为得到的调度方案中的任务总的执行时间和执行成本。
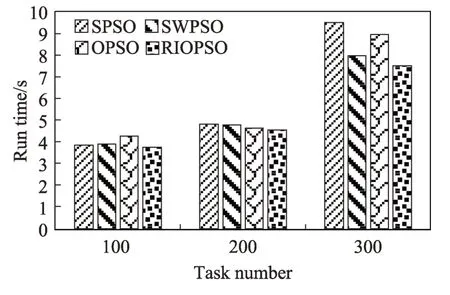
Fig.9 Total time of task execution图9 任务执行总时间
从图中可以看出,无论是任务执行的总时间还是任务运行的总成本,RIOPSO 算法都能够得到最小的值。满足关于得到最小执行时间和最少执行成本的双目标的需要。

Fig.10 Total cost of task execution图10 任务执行总成本
通过以上实验得出,本文提出的RIOPSO 算法在寻优能力和寻优效率方面优于其他三种算法,并且在求解最优的云资源调度方案方面,能够使任务的执行时间更短,执行成本更低,从整体上提高了云资源调度的综合性能。
5 结束语
本文将降低任务的总完成时间和总执行成本作为主要目标,考虑不确定因素对任务的执行时间的影响,使用模糊的云资源调度模型,提出了一种改进的混合PSO 算法对云资源调度问题进行求解。在本文提出的RIOPSO 算法中,使用到了三种切实可行的策略:粒子群的正交初始化、粒子的重新随机化、惯性权重的更新。三种策略分别在寻找最优解,跳出局部最优,提高粒子的收敛能力方面得到了很好的实验效果。使用模糊模型使云资源调度更贴近实际应用。使用RIOPSO 算法对模糊云资源调度方面进行寻优,使得任务的执行时间更短,执行成本更低。相比较于单一的SPSO、OPSO、SWPSO 算法,使用RIOPSO 能够得到更优的解,也更符合实际中的应用。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
南方农业·下旬(2022年4期)2022-05-24
昆明医科大学学报(2022年1期)2022-02-28
北京航空航天大学学报(2021年6期)2021-07-20
北京信息科技大学学报(自然科学版)(2021年2期)2021-05-20
北京航空航天大学学报(2019年9期)2019-10-26
分析化学(2018年12期)2018-01-22
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
理科考试研究·高中(2016年9期)2016-05-14
新高考·高二数学(2015年7期)2015-10-22
