
学术影响力预测研究进展述评
2021-08-23 05:25霍朝光魏瑞斌
情报学报 2021年7期
霍朝光,董 克,魏瑞斌
(1.中国人民大学信息资源管理学院,北京 100872;2.武汉大学信息管理学院,武汉 430072;3.安徽财经大学管理科学与工程学院,蚌埠 233030)
1 引 言
学术影响力(scientific impact)是衡量科研成果与科研工作者学术贡献和学术影响的重要指标,强调从影响力的角度评估科研产出的学术价值、科研主体的研究贡献以及学术地位等[1-2]。例如,论文影响力、期刊影响力、学者影响力、机构影响力、项目影响力、专利影响力以及软件影响力等[3]。学术影响力预测(prediction of scientific impact)是指在相关学术影响力指标的基础上,解析和利用科学发展的规律,预测相关学术实体的未来影响力。根据预测对象的不同,主要分为论文影响力预测(paper impact prediction)[4]、期 刊 影 响 力 预 测(journal impact prediction)、学者影响力预测(schol‐ar impact prediction)[5]、机构影响力预测(institu‐tion impact prediction)[6]、项目影响力预测(project impact prediction)以及专利影响力预测(patent im‐pact prediction)[7]等。学术影响力预测旨在追踪科学研究前沿,为优化科研资源配置提供支撑,为科研管理赋能[8]。
学术影响力预测是数据驱动科学学预测(pre‐diction in science of science)的重要组成部分[9]。21世纪以前,针对科学的预测主要依赖于专家的决策,由于数据限制侧重定性预测,但是如今科学作为一个不断演化的生态系统,承载着上千万的学者,覆盖上百种学科,每年都有海量的科研成果产出,面对海量的科研数据,定性专家预测成本巨大,并且传统的领域专家决策在及时性和有效性方面势必也大打折扣[8]。现代学术影响力预测强调数据驱动的量化预测研究,强调如何协同多维海量数据提升预测水平[10]。本文从研究对象角度,总结了期刊影响力预测、论文影响力预测、学者影响力预测、机构影响力预测、项目影响力预测以及专利影响力预测六个方面的研究进展,进一步从预测指标、预测方法和预测特征三个维度依次进行归纳,以期揭示学术影响力预测研究范式的内在特征,主要研究框架如图1所示。
2 论文影响力预测
论文影响力预测(paper impact prediction)旨在预测论文未来可能产生的影响,提前从海量的学术论文中准确地识别出具有参考价值的高质量论文,从而实现揭示最新的研究动态、掌握最新的研究方法、促进科研创新的目标[4,11]。论文影响力的产生存在时滞特征,相关研究表明,“睡美人”(Sleep‐ing Beauty)论文在各个领域均是存在的[12],论文影响力预测则可提前预测“睡美人”论文的存在。目前,论文影响力预测主要借助引证指标和替代计量指标开展。
(1)基于引证指标的论文影响力预测。基于引证指标的论文影响力预测,强调将论文影响力预测转化为引文预测(citation prediction),综合各方面的特征构建模型,预测引证的数量。例如,Bai等[13]从论文内在质量、论文影响力衰退状况、论文早期被引数量以及早期引用者的学术影响四个方面,构建论文潜力指数(paper potential index,PPI)模型,对论文的被引量进行预测。但是,科学论文的引文分布形式参差不同,并且会受到各种各样因素的影响[4],单纯从引文历史序列数据很难解析引文的变化规律,因此,研究人员一般综合其他特征预测论文引文的变化。例如,Xu等[14]和Li等[15]分别在多维文献计量特征和大规模文献计量特征基础上,设计卷积神经网络和深度学习模型,对引文量进行回归和预测。Yuan等[16]则针对出版物的内在质量(intrinsic quality)、老化效应(aging effect)、马太效应(Matthew effect)、近因效应(recency ef‐fect)等因素,借助时间递归神经网络(recurrent neural network,RNN)构建了出版物长期引证数量预测模型。Abrishami等[17]借助人工神经网络(arti‐ficial neural network),构建了论文的长期被引量预测模型,将RNN与自编码器(auto encoder)结合,进一步提升了预测的准确率。基于引证指标的论文影响力预测,虽然预测目标十分明确,但是预测难度却不可小觑,不同模型对不同学科论文的泛化能力也有待进一步验证。
(2)基于替代计量指标的论文影响力预测。替代计量(altmetrics,alternative metrics)强调追踪科学文献在网络社交媒体、学术型或通用性网站平台和学术型社交媒体平台等传播和热议状态,反映科学成果的影响力[18],与引证指标相比,时效性更高。例如,Eysenbach[19]以Journal of Medical Internet Research期刊上的论文为例,证实众多论文在Tweets中的不同状态,有助于对三天后高被引论文的预测。Hassan等[20]以论文在Twitter中的正负情感来预测研究成果的早期影响力,发现情感与被引量呈显著正相关,人们在社交媒体中关于研究成果讨论的情感极性和情感值有助于综合预测论文的影响力。也有研究证实,替代计量指标与被引数量的弱相关性,质疑基于替代计量指标进行影响力预测的效力[21-22]。不过李纲等[23]则反向验证了论文、作者、期刊等特征,对于学术论文的社交媒体可见性预测的重要性。由此可见,替代计量指标和引证指标对论文影响力预测均具有一定的作用。
论文影响力预测的相关特征。论文影响力相关特征是论文影响力变化的自变量,是对论文影响力的外在表征,主要涉及学术论文、论文作者、载文期刊以及其他属性特征等。其中,论文特征主要包括论文主题的成熟度[11]、论文题目长度、论文长度、论文参考文献数等[24-25];作者特征主要包括作者影响因子(author impact factor)、署名作者数量(the number of authors)、作者所在机构的国度(country)、作者权威性(authority)等[26];期刊特征主要包括期刊的总被引数、期刊影响因子(jour‐nal impact factor)、期刊的主题分布等[27];其他属性的特征主要有机构的学术排名、机构的声誉以及论文是否以特刊形式发表等[28-29]。详细情况如表1所示。
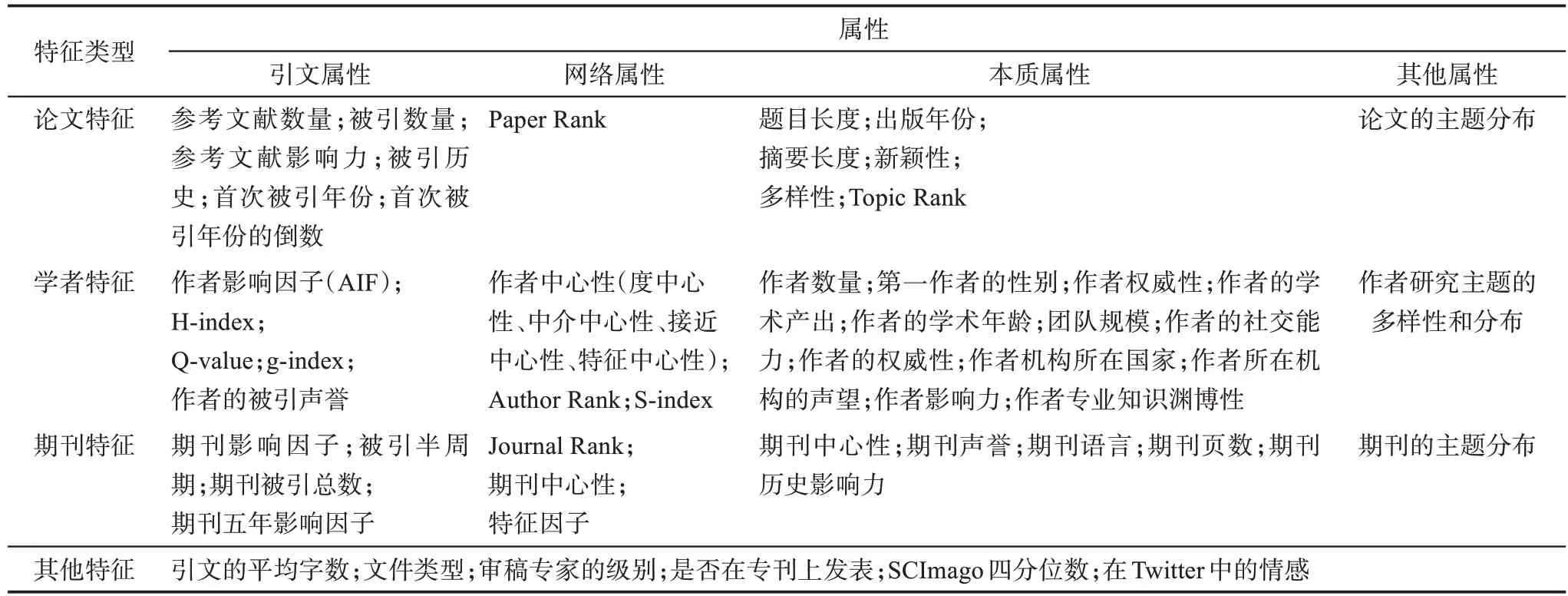
表1 论文影响力预测相关特征
3 学者影响力预测
学者影响力预测(scholar impact prediction),也称学者学术表现预测(author performance predic‐tion),强调对学者的学术发展和学术成就进行预测[30]。传统研究中,主要是学者影响力评估方面的研究,预测研究相对较少,比较有代表性的预测研究工作主要围绕学者影响因子(author impact fac‐tor,AIF)[31]、H-index[32]、Q-value[33]以及引文数量等量化指标开展,相关指标和预测模式如图2所示。该预测模式旨在量化学术数据,结合学者发表的论文、研究的方向、所在团队以及学术年龄等特征构建AIF、H-index、Q-value等指标,从而进行评估和预测。
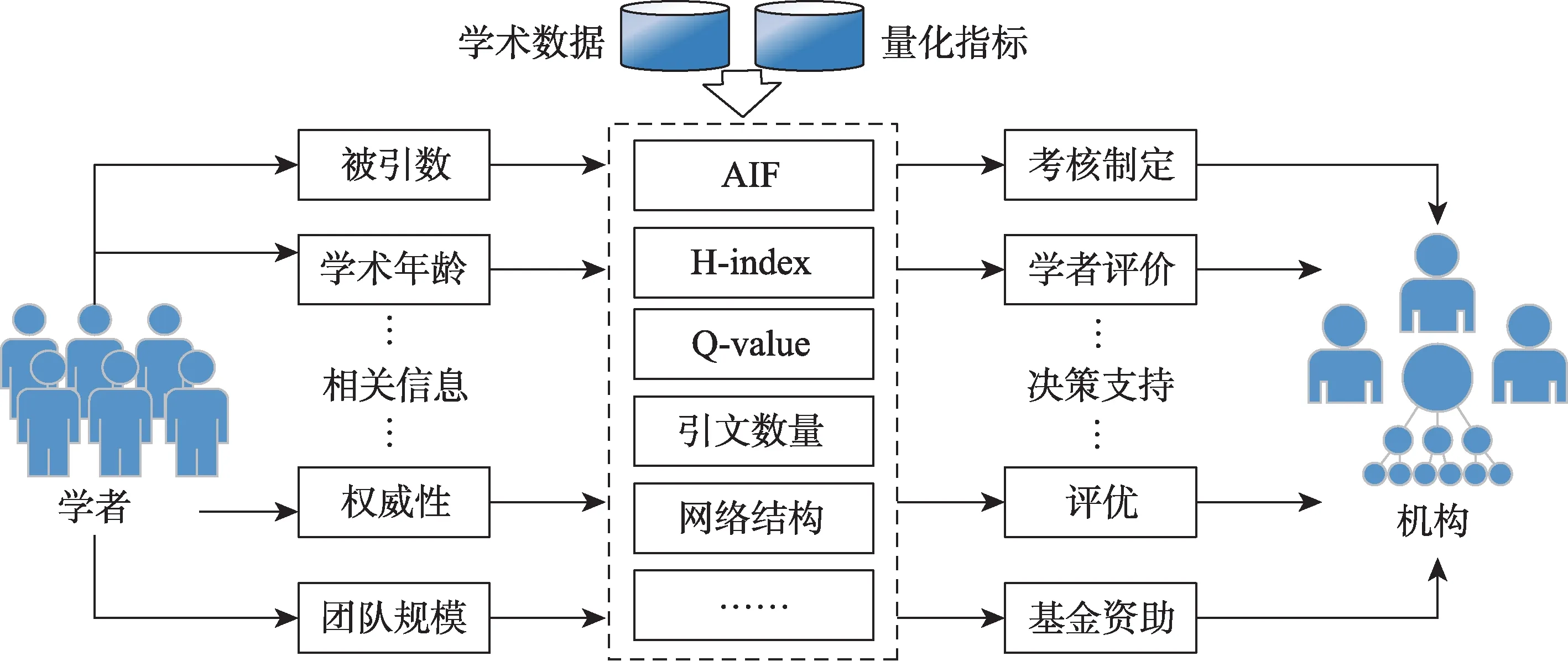
图2 基于量化指标的学者影响力评价与预测框架
(1)基于学者影响因子的学者影响力预测。学者影响因子借鉴期刊影响因子发展而来,用于评估和预测学者未来的影响力。Bornmann等[34]以272921位学者发表的6495715篇论文数据为例,验证了期刊影响因子在评估和预测学者方面的有效性,同时,也反映出不能单独用期刊影响因子作为评价标准,需要综合考虑学者研究的新颖性和重要性、学术声誉以及先前所在机构的声誉。学者影响因子指标基于引证的思想,在研究中往往通过限定3~5年的时间窗口进行预测,但是研究表明,学者发表的最具影响力的学术成果在其学术生涯中是随机分布的[33],面对随机分布的、限定时间窗口的学者影响因子预测存在一定的局限。
(2)基于H-index、Q-value等指数的学者影响力预测。H-index侧重从学术质量视角对学者的影响力进行量化,最早由Hirsch[35]提出,是学者影响力预测的一项重要指标。基于H-index指标,Acuna等[36]通过机器学习方法,在3293个学者数据集上验证了预测的效度。Ayaz等[37]则以计算机领域210万篇论文的作者为例,通过回归的方法检验不同特征组合下的预测准确率。Mistele等[38]在H-index指标基础上进一步整合引文数量(citation count)形成新指标,通过神经网络方法预测学者未来的表现。但是H-index也同样存在时间窗口的问题,因此,Sinatra等[33]提出了Q量化随机模型,解析学者科研产量、个人能力以及运气对学者影响力的作用,为每个学者定义唯一的Q值,衡量学者在学术生涯中随机发表的成果,从而预测学者影响力的演化。
(3)基于引文数量的学者影响力预测,多凭借引文数目单一指标反映学者的影响力。例如,Ne‐zhadbiglari等[39]以总被引量来衡量学者的流行度(popularity),以计算机领域的50万学者为例,通过计算学者以及其他学术特征与流行趋势聚类中心(cluster centroids)的距离,训练分类模型预测学者的流行度。Panagopoulos等[40]则在引文数量的基础上,进一步提出学者KPIs(key performance indica‐tors)指标,综合社交性(sociability)、中心性(centrality)、加权合作影响(weighted collaboration impact)等合作方面的特征和幂率图方面的特征(power graph feature),通过构建无监督学习聚类模型,预测学术新星(rising stars)。
(4)基于网络结构的学者影响力预测。强调从学者所在的异构学术网络角度衡量其在网络中的地位和重要性,并用于预测学者的影响力和探测学术新星[3]。例如,Zhang等[41]借助结构洞和信息熵理论,阐述学者在学术网络中位置的重要性,利用AIRank(author impact rank)方法挖掘具有多学科特性影响力较大的学者。Zhang等[42]综合考虑作者的被引数、作者之间的相互影响以及不同学术实体之间相互强化对学者的影响,提出了ScholarRank方法评价学术新人的影响力。Zhang等[43]根据学者变化状态的不同,将其划分为不同的类型,提出PeP‐SI(personalized prediction of scholars’impact)学者影响力预测模型,对不同类型学者分别应用改进的随机游走算法进行预测,充分利用了学术网络的动态变化对学者影响力的作用。
学者影响力预测的相关特征如表2所示。学者影响力预测主要涉及学者、学者发表的论文、刊载成果的期刊以及社会特征四类。在学者特征方面,主要涉及学者在某一主题方面的权威性、学者的生产能力、学者的社交能力、学者当前H-index等,强调学者自身的属性和能力;在论文特征方面,主要涉及学者论文的发文时间、署名以及共同署名的论文数、论文的衰退情况等[36],强调由论文状态的变化所引发的学者状态变化;在期刊特征方面,主要涉及学者在权威期刊上的发文数、成果所在的期刊数、期刊水平等,强调学者在权威期刊上的发文能力和被认可程度;在社会特征方面,学者在合作网络中的中心性、位置等合作特征(collaborative features)以及幂率图特征(power graph features)方面,分析学者在学术圈内声望和地位的社会特征也受到众多关注[40,44],关于学者影响力预测研究中所使用的相关特征,详细情况如表2所示。

表2 学者影响力预测相关特征
4 其他学术实体影响力预测
1)机构影响力预测
机构影响力预测(institution impact prediction),强调对机构的学术表现进行预测。机构影响力预测常常以机构的论文为指标,将机构影响力预测转化为对论文数目的预测。Sandulescu等[45]以Microsoft Academic Graph数据为例,分别验证了概率预测模型、线性回归预测模型、梯度增强决策树(gradi‐ent boosted decision trees)等不同模型以及综合模型对机构论文数目预测的效度,研究发现机构的影响力具有较强的延续性,机构先前的影响力很大程度上决定了机构未来的影响力。由此可见,机构的影响力更加持久、稳定和综合,一旦得以树立影响就会很长远,打造学术团队、树立机构权威意义深远。Xie[46]将研究机构影响力预测的任务转化为时间序列回归问题,通过对机构下一年被录论文数目的预测来预估机构未来的影响力,验证了机构论文排名特征(paper-rank features)、项目委员会会员特征(program committee membership features)等对机构影响力的作用,研究发现,简单的线性模型比复杂的预测模型更稳健。Bai等[6]以机构署名的录用论文数为指标,利用相关特征提取方法验证机构的地理位置(geographic location of institution)、当地GDP(gross domestic product)等特征与机构影响力的关系,构建了新型机构影响力预测模型,发现不同出版物在录用论文时,对机构重要性的考量机制不同,机构特征的重要性仍然是相对有限的。受机构影响力有效指标的限制和机构影响力预测多元复杂的困扰,目前,关于机构影响力预测的研究相对处于初步发展阶段。
2)期刊影响力预测
期刊影响力预测(journal impact prediction),侧重于对期刊影响因子、影响指数等预测。Wu等[47]以期刊影响因子(journal impact factor)为目标,利用论文的被引频次预测期刊的影响力,并以Sci‐ence、Nature以 及LIS(library and information sci‐ence)领域期刊数据为例,验证了该模型的有效性,在确保准确率的前提下,将预测结果提前官方数据4个月。李秀霞等[48]从作者特征维度,构建了反应期刊内部特征信息的作者特征空间向量,利用曲线回归的方法对期刊影响力进行预测,实验证明,该期刊影响力预测模型与4年后对应期刊的影响因子具有较好的吻合度,从作者层面可以提取有效的特征辅助,对期刊影响力的预测。张耀辉等[49]借鉴学术迹划分状态的方法,构建马尔科夫模型预测期刊的发展情况,动态定量地表达了学术期刊未来的学术稳定性,为期刊提供了一种有效的预测分析方法,但是其对于期刊状态的划分标准和通用性还有待进一步加强,依托转移概率矩阵的预测方法,在更大的数据集上效果可能更好。丁筠[50]借助学术期刊影响力指数(journal clout index),构建BP(back propagation)神经网络预测模型,以综合性人文、社会科学类的632本期刊为训练集,预测了19种图情领域核心期刊的CI(clout index)值。期刊作为学术成果的一种载体,对期刊影响力的预测更多的是回归到论文层面,通过论文影响力预测实现对期刊影响力的预测。但是,从期刊层面来讲,期刊的刊发周期、审稿周期、刊载量以及被收录情况都是影响期刊影响力的因素,因此,对期刊影响力的预测不仅要把握论文这一主要因素,还应综合上述其他相关因素。
3)项目影响力预测
项目影响力预测(project impact prediction),强调对项目未来的影响力进行预测,从众多科研项目申请书中筛选出能取到较大成果的项目,以最小的财政支出最大化科研产出[51]。项由于项目评估本身就是对项目的可行性和未来产出等进行预估,从而资助比较有潜力的项目,因此,目影响力预测是项目评估的重要内容。以往关于项目影响力的预测,多借助专家对申请书等材料的定性分析来进行。例如,从项目的创新提升(promoting innovation)、合作培养(fostering collaboration)、战略地位(posit‐ing in strategic areas)等方面预估项目未来的影响力[51]。朱卫东等[52]综合科研项目的评估指标体系和选择流程,提出了一种系统性的基于证据推理规则的科学基金项目评估决策模型,用历史评估结果准确性衡量专家评价信息的可靠性,分别赋予不同评估权重和等级,并以1225项目国家自然科学基金管理学部项目为例,验证了该预估模型的有效性。限于基金以及项目数据的可获得性,目前,量化项目影响力预测研究相对较少。但是,随着国家自然科学、社会科学等基金数据的开放,未来基于客观基金产出数据的项目评估和预测将会得到迅速的发展,从数据层面揭示优秀项目的特征,从基金主持者、参与者、前期研究成果、学术团队、学术机构、学术资源、国际交流、项目选题热度、项目意义等信息中提取相关特征,构建项目影响力预测模型,提升对项目影响力的预测。
4)专利影响力预测
专利影响力预测(patent impact prediction),强调对专利未来的价值进行预测。鉴于众多学者会将其提出的新方法和新技术成果申请为专利,因此,在学术领域,专利也是一种重要的学术产出。专利影响力是专利价值的重要表现之一,预测专利的影响力有助于引导资本迅速将技术转化为生产力,有助于从专利角度反映学者以及机构的学术表现。专利文献与科学文献均具有引证关系,故相应引文预测方法同样也适用于专利预测[7]。同时,专利也具有类似共词网络的相似网络。例如,马瑞敏等[53]在专利相似网络领域细分的基础上,根据同类预测准则,以4年内被引频次、同族专利数、专利宽度、权利要求数、科学关联度5个指标作为预测指标,构建支持向量机模型对核心专利进行预测。目前,关于专利的研究更多的是集中在评价方面,预测方面的研究相对较少。专利在未来能否取得较大的影响或产出,不仅取决于专利本身的属性,更与市场、产业、社会等发展紧密相关,因此,对专利影响力的预测,不仅要综合考量专利本身的特征,还应综合市场需求、产业背景、技术发展、国民教育等各方面因素,在追踪专利影响的基础上,提高对专利影响力预测的精度。
5)相关特征
机构、期刊、项目、专利等影响力预测具体涉及的特征如表3所示。虽然学术实体之间是相互影响的,在预测某一种实体时互为特征,但是不同学术实体的影响力预测也有其独特之处。其中,机构影响力预测特征主要涉及被录论文的排名特征(ac‐cepted paper-rank features)、项目委员会成员特征(program committee membership features)、机构在不同刊物中的表现特征(cross conference features)、机构在不同阶段的表现特征(cross phase fea‐tures)[46]、机构历史得分(historical scores of institu‐tion)、作者影响因子、机构先前得分的加权移动平均等特征[31,45]。期刊影响力预测特征主要涉及作者数、第一作者、作者发文数、作者论文被引频次、期刊被引频次、期刊论文下载量、期刊的基金论文比以及期刊的历史表现等特征[47-48,50]。项目影响力预测主要涉及项目的被资助者、期刊影响因子、资助成果等方面的特征。而专利影响力预测主要涉及专利宽度、同族专利数、科学关联度、科研资源、学术机构水平、私营机构合作质量等特征。

表3 其他学术实体影响力预测相关特征
5 学术影响力预测体系
随着数据驱动科学预测模式的发展,近年来,关于学术影响力预测的研究呈现出井喷式的发展状景,从Science[8-9]、Nature[36]、PNAS[54]等国际交叉学科顶刊,到Journal of Informetrics、JASIST、Sciento‐metrics等LIS领域较好的期刊,均有一定的学术影响力预测研究成果发表,学术影响力研究逐渐步入数据驱动预测新阶段。总结学术影响力预测研究的核心内容,主要包括学术影响力预测指标体系、学术影响力预测方法体系以及学术影响力预测特征体系等三大体系。
1)学术影响力预测指标体系
在预测指标方面,引证指标、影响因子、发文量、被引量、学者奖励等均是量化科学的有效指标,但这些指标也存在着一定的不足[9]。基于引证的相关指标存在着周期长、时间滞后等不足。替代计量指标相对具有较强的时效性,其测度样本范围更广,测度也更加多样和开放[55],在一定程度上可以规避假引用、马太效应等形成的高被引现象,是衡量科学文献等影响力的新途径和指标[56],但是替代计量指标也存在数据覆盖比例、数据质量、数据来源等方面的问题[57-58]。只有整合两类指标的优势,在确保质量和稳定性的前提下,融合同行评议与社会影响力等新维度综合开展学术评价和预测,才能揭示不同科学领域各自科研系统生态的发展规律。
此外,各类指标之间具有较强的依附关系,学者、期刊、机构等影响力根源于论文的学术影响力,论文影响力增强,学者影响力也会增加,相应机构也会获得提升,学者、期刊、机构等共同组成了一个个小的学术共同体,构建了包含知识创造者、知识传播媒介、学术资源、学术团队在内的学术生态。只有各学术实体的综合影响力,才能表征学术共同体的整体水准,任何单一指标由于自身缺陷均,难以达到学术影响力评价和预测的要求。例如,Hirsch批评自己提出的H-index学者学术影响力评价指标,反思了该评价指标对学术创新的不利影响,以及由于学术评价所导致的学术资源倾斜问题,并建议综合学科领域、作者署名位置、合作者数量等各方面情况综合评价学者[59-60]。由此可见,过分倚重单一指标极易扼杀学术创新,综合衡量各学术实体的整体水平,构建成熟的学术共同体评价指标,才是评价和预测科学影响力的关键。
2)学术影响力预测方法体系
统计回归类方法和机器学习方法,是学术影响力预测的两大主要方法体系。统计回归类方法强调利用学术实体自身的变化规律,合理选择自变量,确定因变量与自变量的关系,通过回归拟合的方式,预测影响力的变化,其方法体系如图3所示。可以发现,统计回归类方法常采用线性函数以及多项式函数表示变量与自变量的关系。例如,线性回归(linear regression)[36]、分位数回归(quantile regression)[28]、半连续回归(semi-continuous regression)[61]、梯度增强回归树(gradient boosted regression trees)[62]、逐步回归(stepwise regression)[25]、ARIMA(autoregres‐sive integrated moving average mode)时间序列模型以及VAR(value at risk)等多元时间序列模型(mul‐tivariate time series)[46]。与机器学习方法相比,统计回归方法没有特征辅助,将能够影响学术影响力的因素看作自变量,通过分析和挖掘自变量以及自变量与因变量的关系,构建回归模型,拟合学术影响力的历史序列数据[63],用模型表征影响力的波动规律,提升对学术实体未来影响力的预测。由于统计回归类方法一般对自变量有着较为明确的定义,数学推理过程严格[30],因此,模型解释简单直观,但也存在无法处理高维数据、无法囊括大量自变量等问题,预测能力和准确率较为有限。
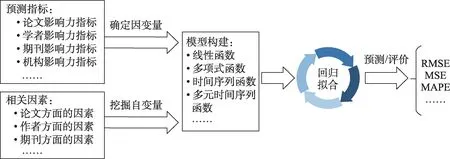
图3 学术影响力预测的统计回归方法体系
机器学习方法强调从学术实体自身以及其他相关信息中提取特征,从而训练相关机器学习模型或者深度学习模型,在特征辅助下对学术影响力进行预测,机器学习方法体系如图4所示。机器学习方法没有将与学术影响力相关的因素直接作为自变量构建到模型中,而是将所有影响到学术影响力变化的因素统称为特征,其认为特征与预测指标之间存在复杂的非线性关系。机器学习方法没有直观的模型,每个特征与预测指标之间的具体关系无从得知,也无法解释各个特征对预测指标的作用大小,只能通过特征组合验证最终的准确率。机器学习方法强调通过学术大数据提取论文、学者、期刊、项目、机构、专利等多维特征,适用于大数据场景,并且数据量越大越有利于特征的提取和模型的提升。在以往研究中,用到的算法和模型主要包括梯度增强决策树(gradient boosting decision trees,GB‐DT)[45]、XGBoot、支持向量机(support vector ma‐chine,SVM)、随机森林(random forest)[28]、K最近邻(Knearest neighbor,KNN)、神经网络(neu‐ral network)[38]、BP神经网络[50]等机器学习模型,以及CNN(convolutional neural networks)、1D CNN、LSTM(long short-term memory)等深度学习预测模型[14-15]等。与统计回归类方法相比,机器学习方法具有较高的准确率。

图4 学术影响力机器学习预测方法体系
3)学术影响力预测特征体系
传统的学术影响力预测涉及的特征多聚焦于论文、学者、期刊、机构、项目等学术实体的本身属性和关系,彼此之间互为特征。例如,预测论文的影响力时,往往利用学者以及期刊的特征,预测学者时又往往利用论文、期刊等方面的特征。此类研究常常将别的特征视作相对不变的依据,忽略了互为特征一同演化的客观事实。与传统学术影响力预测研究相比,数据驱动的学术影响力预测更加强调从海量数据中提取相关特征来构建协同预测模型,而有效的特征体系则是该协同预测模式研究中的重点。
以学术异构网络(bibliographic heterogeneous network)表示各学术实体特征之间的动态协同演化情况如图5所示。图5中以节点表示学术实体,以节点的面积表示学术实体的影响力,以时间片的形式表示学术实体的动态演化。随着时间的推移,学术实体在不同时间片时影响力发生了变化,有的影响力减弱(节点面积变小),有的影响力增强(节点面积变大),不同学术实体协同演化,或互相促进增强,或一同衰落消亡;连边表示了不同实体之间的关系。图5描述了不同学术实体之间的复杂关系,沿着学术实体之间的真实关系,快速找到影响目标对象的因素,能够有效提升学术影响力的预测质量。

图5 不同学术实体特征之间的动态协同演化概念图
6 研究展望
本文系统地梳理了论文、学者、机构、期刊、项目和专利六个方面的学术影响力预测研究进展,概括了学术影响力预测研究的指标体系、方法体系和特征体系三大体系。随着数据生产要素化、数据开放与数据共享的进一步推动,有望形成新的综合性指标。在科学衡量学术影响力的基础上,为预测提供新的目标;随着特征提取技术和时间序列预测方法的发展,有望形成新的学术影响力预测模式,完善学术影响力预测方法体系;随着结构化、半结构化和非结构学术数据的融合,有望从海量学术数据中进一步提取有效特征,丰富学术影响力预测特征体系,进一步提升学术影响力预测的准确性。
(1)数据要素化促成新的学术影响力综合性指标。在学术影响力预测指标体系方面,其一,相关引证指标和替代计量指标因各自存在的问题制约了其独立进行评价和预测的可行性,只有整合两项指标,才能在确保质量和稳定性的前提下,融合社会影响力新维度综合进行学术评价和预测,破除SCI至上的学术观,提高指标对新兴领域和创新观点的敏感性。其二,应综合社会认同、同行认同、专家认同、期刊认同等及时反馈影响力情况,分阶段进行针对性的科学预测,结合领域和学科特点,揭示不同学科领域各自科研系统生态的发展规律。例如,在机构影响力预测方面,所使用的指标相对比较单一,过于倚重论文数目和质量,缺乏衡量机构综合实力的有效指标。机构影响力应该在学术影响力评估的基础上,综合考虑社会影响力,全方面考核机构绩效,并以此为指标,探索相关的影响因素,预测机构未来可能产生的影响。其三,论文、学者、机构、期刊、项目以及专利等以学术共同体的形式存在,共同构成了包含知识创造者、知识传播媒介、学术资源和学术团队在内的学术生态,只有各学术实体的综合影响力,才能更有效地表征学术共同体的整体水准;只有良好的学术生态,才能确保学术研究的有序发展。
随着数据生产要素化的深入发展,各个领域势必会进一步加强对各个维度数据的积累和存储,因此,未来在学术影响力指标方面,应强化对学术共同体整体影响力的评估,充分利用各个领域积累的关于学术的多维数据,规避论文、学者、机构、期刊等单一指标表征学术影响力的不足,整合多维数据和指标,构建能够代表各个学术共同体的综合性指标,为整体学术影响力预测提供可靠依据。
(2)特征提取技术和时间序列预测方法促成学术影响力预测新模式。统计回归方法体系和机器学习方法体系都有各自的优势和发展空间,但是随着数据的开放和积累,随着数据驱动预测模式的成熟,机器学习方法体系将会发挥更大的作用,尤其是以机器学习、深度学习、广度学习(broad learn‐ing)等为代表的相关模型。例如,计算机领域逐渐发展成熟的长短期记忆人工神经网络(LSTM)、图 神 经 网 络(graph neural networks,GNN)[64]、Time2Graph[65]时间序列模型等,新的预测模型在学术影响力预测方面的应用有望进一步提升预测精度。
与此同时,深度学习等相关模型不仅是预测的有效方法,也是特征提取的有力工具。研究证明,基于深度学习的特征提取算法有效提升了学术实体在文本、网络等方面的特征提取工作,尤其是近年发展起来的广度学习,可为多源异构学术数据融合和协同预测提供一系列的规则和算法[66],有望融合多源异构学术特征甚至跨越学科隔阂,为论文、学者、期刊、项目、机构等学术实体影响力的预测,提供了一种新的协同预测模式,整合特征提取技术和时间序列预测方法形成学术影响力预测新模式,完善学术影响力预测方法体系。
(3)进一步融合多源异构学术数据,丰富学术影响力预测特征体系。论文、学者、期刊、机构、项目等学术实体互为特征,面对海量的动态协同演化的特征实体,如何提取有效特征来构建协同预测模型,是学术影响力预测研究的重点。特征提取的前提是有效的特征刻画,在于如何利用结构化、半结构化和非结构化的学术数据,虽然以往在学术异构网络、科学知识图谱方面已有大量研究,但是如何将海量学术实体之间复杂的真实关系刻画出来,如何将不同领域甚至跨学科的学术实体有效地融合在一起,并提取出有效的特征,是学术大数据面对的棘手问题。例如,可以利用图神经网络,在更广泛的学科范围内进行多源异构网络融合,通过广度学习网络对齐、网络嵌入等框架将不同领域的学术实体整合在一起[67-68],将多维数据融合在一起,构建囊括多学科数据的异构网络,在动态刻画的基础上,为预测对象提供尽可能丰富和全面的特征池,由此从特征层面提升相关机器学习以及深度学习等预测模型的性能。
(4)规避偏见,预见美好。学术影响力是大科学时代学术分工细化的产物,但是作为科研政策工具和评价指标,如何衡量学术影响力自始至终存在着许多争议和偏见[69]。基于学术影响力计算之上的预测势必也存在一定的不足,因此,如何规避关于学术影响力的争议,如何规避预测的偏见,强化对边缘化弱势群体的保护,强化对新颖想法和研究思路的包容度,才能大力鼓励跨学科研究,才能鼓励开拓新的研究领域[9,70]。鉴于此,学术影响力预测应着重为科学研究提供更多选择,帮助科研工作者提前发现未来具有较大影响力的方向或选题,应强调为科研决策提供支持,强化预见美好,这样才能尽力规避学术影响力评估中的负面影响,只为预见科学之美。
猜你喜欢
管子学刊(2022年2期)2022-05-10
中北大学学报(自然科学版)(2022年2期)2022-05-05
管子学刊(2022年1期)2022-02-17
社会科学(2021年5期)2021-10-27
产经评论(2021年3期)2021-08-12
产经评论(2021年1期)2021-04-06
商周刊(2019年2期)2019-02-20
NBA特刊(2018年14期)2018-08-13
人大建设(2017年11期)2017-04-20
影视与戏剧评论(2016年0期)2016-11-23
