
一种基于意图的设计模式排序与优化方法
2021-08-27 06:38历子谦
计算机技术与发展 2021年8期
关 慧,历子谦,吕 颖
(1.沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110028;2.辽宁省化工过程工业智能化技术重点实验室,辽宁 沈阳 110142)
0 引 言
软件工程的发展使得设计模式的使用成为一种合理的实践,使用设计模式是解决开发团队中反复出现问题的首选方法,它可以避免“造轮子”,也可以简化针对正在解决问题部分的解决方案进行交流[1]。但是在没有任何工具的支持下,要找到正确的设计模式来解决给定的设计问题是非常困难的,因为确定设计模式对给定问题的适用性很大程度上依赖于软件开发人员的经验,而且对于不熟悉设计模式且不知道如何找到最佳模式的新手开发人员来说也是极其困难的[2]。此外还有大量的设计模式,如Booch 2006,Coad 1995,Douglass 2002等,对于非常了解模式的开发人员也十分具有挑战性[3-4]。设计模式主要由设计意图、适用性、结构等部分组成,H.Kampffmeyer[5]认为设计意图部分是理解设计模式的最短路径,因此通过设计模式意图的处理对于设计模式的选择是十分有必要的。
1 相关研究
很多学者就设计模式的选择做了相关的研究。M.R.J.Qureshi等[6]在问题驱动帮助用户选择设计模式上做了一番研究,设计模式中一些特定的场景的表达,需要人工参与解释,这样有利于相对精确地选择正确设计模式,但对于问题来说,通常是静态或者通用,而且在模式数量巨大的情况下,构造问题也是一个极具挑战性的任务。Suresh S等[7]使用文本分类和文本检索技术,为每个设计模式类训练一个分类器,但分类器的分类能力与样本容量和稀疏密度密切相关;Hussian等[8]基于本体和文本匹配场景,基于本体方法的缺点在于构造很昂贵,并且给方法自动化带来障碍。Gupta等[9]使用了归一化互相关帮助用户选择模式,归一化互相关技术已经广泛应用于机器视觉,用图像中的相关程度匹配引申到设计模式的匹配上,优点是给类图之间比较提供了量化的方法,但只在结构上判定两个设计是否相似,其正确性也有待斟酌。Smith等[10]设计的选择方法,基于在设计文档或代码中检测反模式的设计模式,在代码级推荐设计模式是一个好的想法,但在代码开发阶段再考虑设计模式为时已晚,因为软件已经设计好了,还需要更改就变成很麻烦的事。Issaoui等[11]使用了一个相似矩阵来比较从设计中提取的词语(类名、方法名等)和模式参与者扮演的角色,并与设计人员交互,获得设计片段的上下文的文本描述,通过预先设计的模式问题精炼结果,该方法改进了单一使用某个方面选择模式的缺点,但设计问题需要提前设计,当模式数量巨大时同样将面临问题。P.Gomes等[12]采用了一种基于案例推论的方法,案例表示在过去的软件设计中已经应用了模式的情况,用类图来描述案例,但其缺点是图并不总是有用的,也不能产生相关性分数。W.Muangon等[13-14]提出了一种基于案例推理和形式概念分析相结合的内聚技术的解决方案,这种集成使得检索组织能够构造一个完整的设计问题描述,用来寻找合适的设计模式。
2 基于意图的设计模式排序
本方法通过Stanford Parser对设计模式的意图文本和设计模式实际问题做文本预处理,得到相应的词对集,表示成相应的向量,通过定义的词对匹配评分函数,为设计模式意图和实际问题评出相似度评分,降序排序得到设计模式的排序结果。整体流程如图1所示。

图1 方法整体流程
2.1 文本预处理
从文本提取关键词使用Stanford Parser的Stanford Dependency parser[15-16]生成表述每个句子中成对单词之间的语法依赖类型。在语法分析器提供的48个Type dependency(Td)中,只有四个提供了与输入问题相关的实体和意图[17],分别如表1所示。

表1 四种Td的含义与组合词性
词形还原(Lemmatization)被用来还原单词形态,其使用已知单词形式组成的字典,并考虑单词在句子中的作用,将单词标准化为词元。
例如:Decorate模式的意图“Attach additional responsibilities to an object dynamically. Decorators provide a flexible alternative to sub classing for extending functionality.”解析见表2。

表2 Decorate模式意图抽取Td结果
文本预处理通过上述两个方法,首先将设计模式意图解析成语法关系,提取所需的单词对,然后通过词形还原获得标准化后的单词。
2.2 文本向量
设计模式的意图通过解析成单词对,表示成为设计模式向量(DPV),当输入问题时,产生输入问题向量(IPV),每种模式的DPV和IPV之间需要计算一个相似度,根据计算得出的相似度得分进行排序。由于不同Td之间相应位置词的词性有所不同,组合的方式不同,所以将文本预处理获得的单词对分为多个集合,分别为nsubj,nsubjp,dobj和nmod。
DPV与IPV之间的关系如图2所示,Xi,Yi分别表示DPV与IPV的TdSet中的元素。
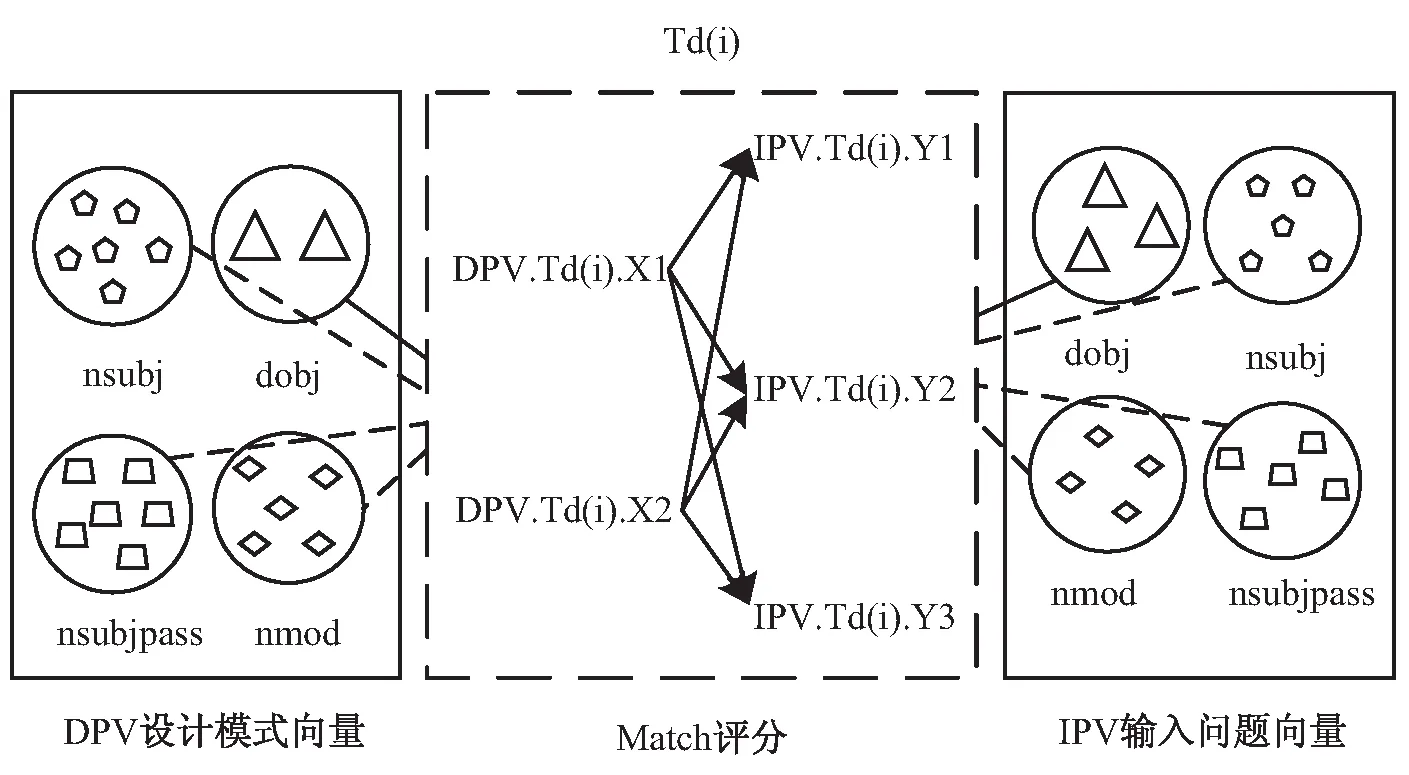
图2 文本向量之间的关系
2.3 Match评分
为了增加关键词的匹配,考虑WordNet中同义词(synonyms)、上位词(hypernyms)、下位词(hyponyms)的匹配,当匹配的是词汇的上位词和下位词时,从匹配得分中扣除惩罚项(Ps),由于单词对比单个单词所蕴含的语义信息更丰富,所以当两个单词都得到匹配时,则获得一定奖励。例如“provide alternative”和“supply alternative”的计算匹配得分为:(1)“supply”是“provide”的上位词,所以匹配的分为1-Ps;(2)“alternative”和“alternative”是相同的词,匹配得分为1;(3)两个词都匹配上,额外获得奖励1。所以总分为(1-Ps)+1+1。文中定义算法如下:
以下伪代码中synonyms(a,b),hypernym(a,b)和hyponym(a,b)在返回a,b在WordNet中是否为同义/相等,a是否为b的上位词和a是否为b的下位词,返回的是boolean型。
输入:A,B分别是设计模式和问题相应TdSet中的一个元素,Ps是惩罚项,syn,hyper,hypo分别为同义、上位和下位词的匹配是否开启的参数,取值boolean型。
输出:Score是A,B两个Td的相似性评分。
步骤:
初始化:govscore=0,depscore=0
if synonyms(A.gov,B.gov) & & syn==true then
govscore+=1
end if
if(hypernym(A.gov,B.gov)& & hyper==true) ||
(hyponoym(A.gov,B.gov)& & hypo==true) then
govsocre+=1-Ps
end if
if synonyms(A.dep,B.dep) & & syn==true then
depscore += 1
end if
if (hypernym(A.dep,B.dep)& & hyper==true) ||
(hyponoym(A.dep,B.dep)& & hypo==true) then
depsocre+=1-Ps
end if
Score=govscore+depscore
if depscore>0 & & govscore>0 then
score+=1
end if
Return scorsse
WordNet中的Td类型不同,搭配的词性不同,所以匹配时将不同集合分别计算,计算公式如下:
其中,Tdi∈{nsubj,nsubjp,dobj,nomd}。
2.4 相似度函数
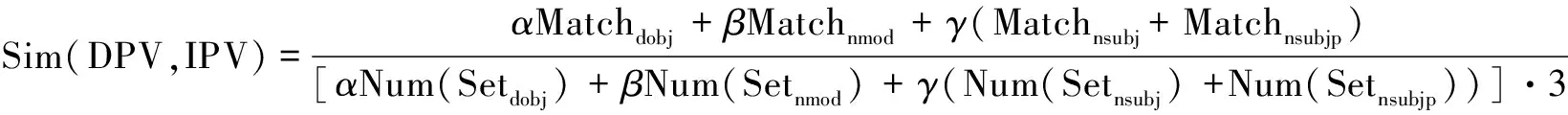
其中,α,β,γ为权重参数;DPV为设计模式向量;IPV为问题向量;Num(SetTdi)为设计模式Td集合中元素的数量;MatchTdi(DpSet,IpSet)为设计模式与问题在Tdi上的匹配评分。
相似度函数性质:
(a)相似度的值应在[0,1];
(b)当进行比较的两个向量属性相同时,相似度为1,完全不同时,相似度为0。
证明:
设:设计模式向量为DPV,输入问题向量为IPV。
(1)当DPV≠IPV时,Sim(DPV,IPV)=0。
∵DPV≠IPV
∴MatchTdi(DpSet,IpSet)=0,
Tdi∈{nusbj,nsubjp,dobj,nmod}
∵[αNum(Setdobj)+βNum(Setnmod)+
γ(Num(Setnsubj)+Num(Setnsubjp))]*3≠0
Tdi∈{nusbj,nsubjp,dobj,nmod}
∵[αNum(Setdobj)+βNum(Setnmod)+
γ(Num(Setnsubj)+Num(Setnsubjp))]·3≠0
∴Sim(DPV,IPV)=0
Tdi∈{nusbj,nsubjp,dobj,nmod}
∵[αNum(Setdobj)+βNum(Setnmod)+γ(Num(Setnsubj)+Num(Setnsubjp))]·3≠0
∴Sim(DPV,IPV)=0
(2)当DPV=IPV时,Sim(DPV,IPV)=1。
∵DPV=IPV
∴MatchTdt(DpSet,IpSet)=Num(SetTdi)*3
Tdi∈{nusbj,nsubjp,dobj,nmod}
∴αMatchdobj+βMatchnmod+γ(Matchnsubj+Matchnsubjp)=
aNum(Setd0bj)÷3+βNum(Setnmod)*3+
γ(Num(Setnsubj)+Num(Setnsubjp))*3
∴Sim(DPV,IPV)=1
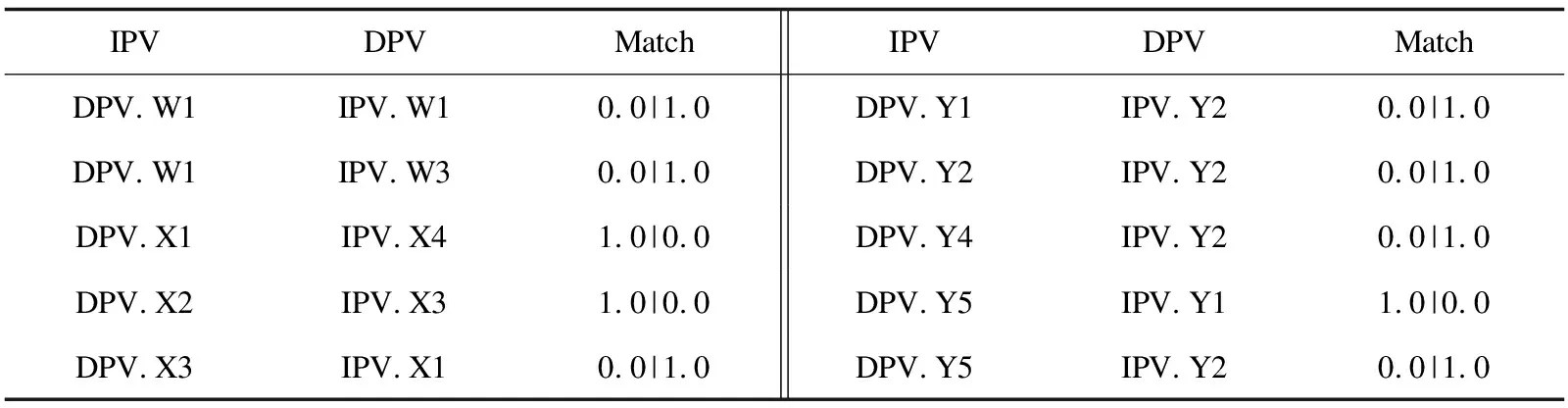
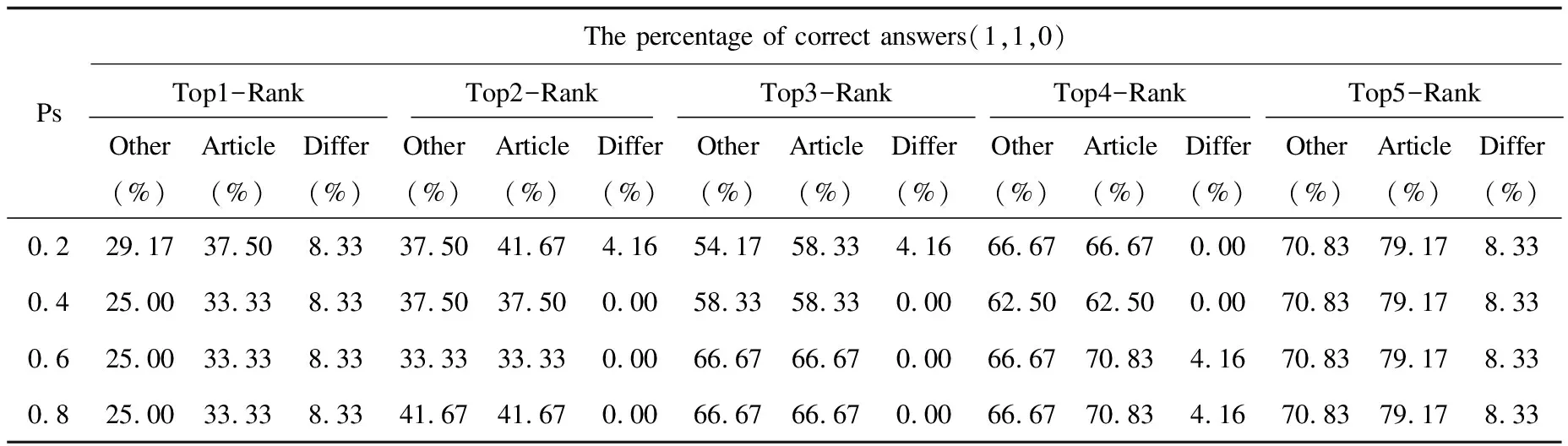
(3)当DPV与IPV部分相似时,0 ∵ DPV与IPV部分相似 ∴MatchTdi(DpSet,IpSet)≤Num(SetTdi)*3 ∴Sim(DPV,IPV)≤1 又∵(1)(2) ∴0 综上,证毕。 有文本两段如下: 设计模式“Visitor”意图:“Represent an operation to be performed on the elements of an object structure. Visitor lets you define a new operation without changing the classes of the elements on which it operates.” 实际设计问题:“Many distinct and unrelated operations need to be performed on node objects in a heterogeneous aggregate structure. You want to avoid "polluting" the node classes with these operations. And, you don't want to have to query the type of each node and cast the pointer to the correct type before performing the desired operation.” 根据语法拆分可获得各自Td集,如图3所示。 图3 拆分Td集结果 首先确定参数,不妨假设参数组合为:α=1,β=1,γ=1,Ps=0.4,syn=true,hyper=true,根据各自Td集内的单词对计算相应的Score,相应求和计算Td集的Match分数,匹配上的如表3所示。 表3 Match结果 由于DPV.Z=Ø,所以相应的Matchnsubjpass(DpSet,IpSet )=0;DPV.W1匹配DPV.W1和DPV.W3都等于1,则取最大值1,则Matchdobj(DpSet,IpSet )=1;DPV.X1,DPV.X2,DPV.X3分别匹配上了IPV.X4,IPV.X3,IPV.X1,所以Matchnmod(DpSet,IpSet)=3;同理,Matchnsubj(DpSet,IpSet)=4。由图3得,Num(Setdobj)=3即在参数为(1,1,1,0.4,true,true,false)时,实际问题与设计模式之间的相似度为24.2%。 参数随着问题实例的增加,精确求解方法变得非常耗时,另外参数确定的状态空间随着参数取值范围和精度的增加而增加,就文中参数而言,共225种组合方式。参数调优模块采用遗传算法的框架,将要解决的问题模拟成生物进化过程,进行多次迭代后就有可能会进化出相对表现较好的参数方案,然而所有的遗传算法都必须具有良好的问题遗传表示,合适的适应度函数才能有效的工作,因此定义规则与适应度函数如下。 编码是应用遗传算法时要解决的首要问题,也是设计遗传算法的一个关键步骤。需要确定的参数有α,β,γ,Ps,syn,hyper,hypo共7个。α,β,γ是三种词集的相应的权重,对不同设计模式数据集[17-18]经过10轮,每轮200代的遗传测试显示,在数值在0~10之间浮动会对相应适应度值有较显著的影响,其他数值几乎无明显影响,所以文中参数设置取[0,10]之间,Ps是惩罚项,取值范围为(0,1),精确到小数点后2位,syn,hyper,hypo分别是同义词,上位词,下位词的开关参数,取布尔值,各参数取值范围如表4所示。 表4 参数取值范围 为了表示以上参数,文中采用二进制编码的编码方式。二进制编码具有编解码操作方便,交叉编译便于实现,符合最小字符集等特点。假设某一参数的取值范围为[Umin,Umax],用长度为l的二进制编码符号串表示该参数,则δ为该二进制编码的精度。 以上参数用31位的二进制符号串表示,其分布如图4所示。 图4 31位染色体的遗传表示 从编码后的基因型向可用参数的表现型转换的方式称为解码。假设某一参数的编码为bkbk-1bk-2…b2b1,则解码公式为: 遗传算法中,群体的进化过程就是以群体中各个个体的适应度为依据,通过一个反复迭代的过程,不断寻找求出适应度较大的个体。所以适应度函数的确定也十分重要。设Rank为相似度排名后设置展示的数量,RankNum[i]为问题对应的设计模式在Rank结果中位于第i位的总数量,则适应度函数定义如下: 当排名越靠前的数量越多时,Fitness的值越大,并且适应度缓慢增加,有利于寻找到最优解。 文中提供两组设计模式数据集与一组安全设计模式数据集。 设计模式数据集: 安全设计模式样本集合(46)[17]。被分为8类,系统访问与控制体系结构,访问控制模型,身份识别与认证,操作系统访问控制,安全互联网应用,防火墙体系结构,企业安全与风险管理,账单。 Gof模式组[18]是设计模式主要参考书籍之一,面向对象设计模式样本集合(23),被分为3个粗粒度类别,创建型、行为型、结构型。 实际问题数据集: 为了测试所提出的排序方法的有效性,从不同的资源中检索出实际问题,根据专家意见,检索出已经解决和映射的设计问题 (1)46个安全设计模式集合的问题[17]。 问题1:“When objects are created we define the rights processes have to them. These authorization rules or policies must be enforced when a process attempts to access an object.” (2)24个设计模式集合的问题[19]。 问题2:“One of the dominant strategies of object oriented design is the "open closed principle". Figure demonstrates how this is routinely achieved encapsulate interface details in a base class, and bury implementation details in derived classes. Clients can then couple themselves to an interface, and not have to experience the upheaval associated with change: no impact when the number of derived classes changes, and no impact when the implementation of a derived class changes.” (3)7个面向对象设计模式的问题[20]。 问题3:“Design a system for drawing graphic images: a graphic image is composed of lines, rectangles, texts, and images. An image may be composed of other images, lines, rectangles, and texts.” 4.2.1 46个安全设计模式集合的问题 文中使用三组参数在安全设计模式与实际问题的数据集上进行测试,实验结果如表5所示。 表5 不同参数在前rank5中的匹配情况 文中设置三组参数和一组经过遗传算法调优后得到的参数组,经过计算得相应的匹配率结果和各TopN-Rank的总匹配占比,如图5所示。表中反映了在Rank为5时,所有实际问题中正确匹配的设计模式出现在前TopN-rank的个数和所有出现在Rank5的实际问题中在实际问题集中的占比率(即匹配率)。在经过遗传算法调优的参数组合后,出现于前n的匹配数目明显上升。Top1-Rank下,相对参数组1和参数组3,优化组的匹配个数上升至19,匹配率由原来的67.39%上升至76.09%,涨幅8.7%。相同匹配率的参数组2与优化组相比,优化组的Rank匹配率整体上涨了5.72%。 图5 Top-n Rank匹配在总匹配中占比 整体上,优化组相比其他参数组的匹配率上升了5.72%至9.13%不等,匹配率占比也高于其他参数组,经过遗传算法的调优参数,使得准确的结果明显前移,让更多的正确结果出现在了靠前的位置。 4.2.2 ChannaBou 2018的对比 在设计模式数量14,实际问题数量24的情况下,对比如表6所示。 表6 参数设置(syn,hyper,hypo)为(true,true,false)其他方法[16]与文中方法的对比 通过选取相同的设计模式集合[7]和实际问题集[19-20],在经过参数调优后获得的数据如表6所示,Other和Article分别为其他方法和文中方法的表现,Differ表示两种方法表现的差值。在参数syn,hyper,hypo设置为true,true,false时,Ps分别在0.2,0.4,0.6,0.8的情况下,使用文中的参数调优方法后,使得各TopN-Rank的数量明显增加,Top1-Rank下,各Ps的值下涨幅8.33%,Top5-Rank下涨幅8.33%,整体涨幅4.16%至8.33%不等,效果可观。 受人工设置参数的局限,通过遗传算法寻找相对较优解替代人工设置参数。实验一的结果表明,经过调优后文中方法得到的结果相对人工定义的参数组合表现较好,使匹配率得到了相应的提升,同时也使得更多正确的结果出现在了靠前的位置。实验二的结果显示,通过与本方法相近的方法的对比,在经过遗传算法调优后,匹配率都得到了相应的提升,相同参数的情况下,Top1-Rank的匹配率均上调8.33%,Top5-Rank的匹配率相应的上调8.33%,比同类的方法能获得更多的匹配结果,本方法的实验表现总体较优。 提出了一种基于意图的设计模式排序方法,定义了相关的词对match规则,并定义了相关的相似度比较办法,随后针对参数取值依赖人工的问题,引入了遗传算法对相应的参数计算相对优值,最后通过实际问题的数据集对所提出的方法进行了验证和分析。实验结果表明,该方法在经过遗传算法的调优后,相对其他的方法有一定的提高,在其他相关设计模式上也表现较好。由于硬件和时间的限制,文中测试的程序和数据集有限,结论有一定局限性。下一步工作,一方面提高数据集的种类和数量,另一方面对意图不易表达的设计模式进行深入的研究。2.5 示 例

3 参数调优
3.1 编 码(Encode)



3.2 解 码(Decode)
3.3 适应度函数(Fitness function)

4 实 验
4.1 实验数据集
4.2 对比实验


5 结束语
猜你喜欢
计算机仿真(2022年8期)2022-09-28包装工程(2022年11期)2022-06-20江苏教育研究(2022年8期)2022-04-27新世纪图书馆(2021年12期)2021-01-19智富时代(2018年7期)2018-09-03智富时代(2018年7期)2018-09-03智富时代(2018年4期)2018-07-10智富时代(2018年4期)2018-07-10科学家(2016年13期)2017-09-29当代旅游(2016年10期)2017-04-17
