
模拟数量变化对全同胞似然比的影响
2021-09-10 12:24宋翠芹
科学与生活 2021年7期
摘要:探讨模拟群体数和STR对同胞似然比(LR)的影响,为法医遗传学中LR临界值的确定提供依据,可作为参考。用家庭S3软件模拟100~100万对全同胞,分别有15、19、29和39个STR,观察似然比(LR)的分布及阳性率、阴性率、假阳性率、假阴性率的变化。事实证明当模拟种群数量超过105个时,LR值分别为99%、95%、5%和1%,当模拟种群数量低于104个时,LR值波动较大,并且范围很大。当似然比为1时,15个STR系统的灵敏度为98.01%~99.0%;对19个STR系统进行了分析,结果为99.0% - 99.3%;29个STR系统占99%~99.85%;39个STR系统占99.93%~100%。当似然比为1时,所有被试实验题的假阳性率为:15个STR系统的假阳性率为1.7225,19个STR系统的假阳性率为0.7370,29个STR系统的假阳性率为0.1311,39个STR系统的假阳性率为0.0593。当STR基因座数变化时,LR值也在变化,主要变现为:由15个增加到39个时,LR值的中位数、均值、最大值、最小值、99%、95%、5%、5%,1%,标准差也相应增加。从而得出模拟种群规模是影响LR分布的重要因素;在一定数量的人群中,识别系统在检测系统中增加STR的数目,可以获得更好更高的LR值。
关键词:模拟数量变化;全同细胞;似然比
除了传统的亲子鉴定,他们提供的基因信息较少和被鉴定人的特殊性,对复杂的亲属关系进行识别细胞总数有一定差距,由于能力有限,一般无法完成更多的仿真数据。因为目前在法医遗传学领域没有系统的公式和观点,所以需要更严谨、更科学的统计数字来确定全体同胞之间的关系。
本研究的目的是,在大样本数据的基础上进行模拟和亲合方法遗传学中,评价不同STR系亲缘关系概率的计算,总模拟量对全民辨识似然比的影响。家族3是根据DNA数据推断亲子鉴定概率计算的自由软件,利用传统的似然比可以计算和模拟最大项数,可以模拟106对数据。本文采用家族3软件模块,共提出100至100万对全同胞,分别为15人、19人、29人和39人STR系统识别同胞时,不同模拟数的似然比的差异。
1.材料及方法
1.1建立假设实验
本研究采用家庭3软件对四种不同的STR,进行分析模拟了100到100万对全同胞数据,它们是:15个STR系统(ABI标识符),19个STR系统;29 STR系统;39 个STR系统,这些系统全部是商用的. 在模拟试验中,设置相应的全参数同胞个体和无关个体。到目前为止,可以建立以下两个测试假设:
原始假设H0:个体1和2是同胞(在生物学方面,他们有同一个生父和同一个生母。)
备选假设:个体1和个体2没有任何关系,就是两者之间不会同一个生父。
1.2、参数设置
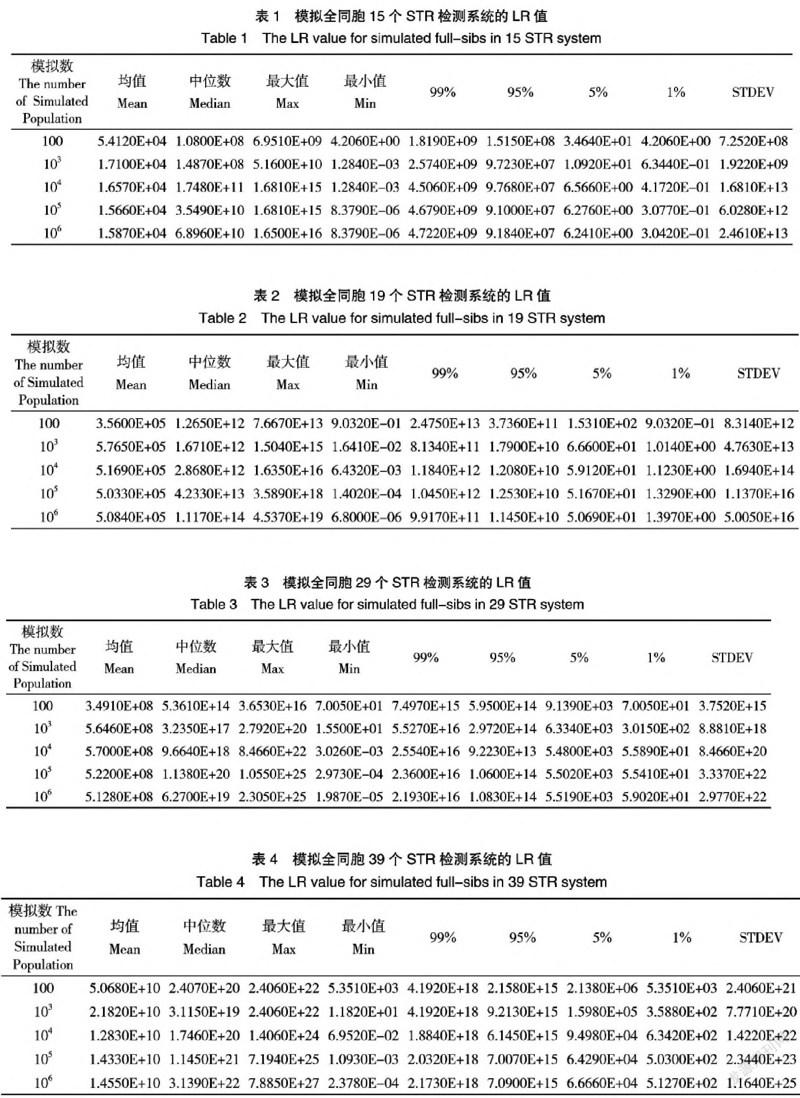
模拟实验前,在软件家族3中设定以下这几个参数:①忽略系统中等位基因的检测突变;②群体遗传指数设为0;③在软件中,将先验参数设置为默认值;④设定可能性比值(LR)的范围为0.1到1×108.模拟次数为100,1×103,1×104,1×105和1×106。收集统计所有的模拟数据,结果包括单个1和2的输入数,根据数据和模拟数据得到的平均值、中值、最大值、最小值,99%、95%、5%、1%,以及%,STEDV的LR值。当设置在LR阈值时,家族3将产生相应的阳性(敏感性)结果和假阳性(1-特异性)结果。对于每个系统,当LR阈值在1到106之间时(表5-8),我们记录了和比较了该方法的灵敏度和假阳性率。
1.3、结果分析
为了分析似然比的分布情况,对得到的LR值进行分类,LR的拟合线图生成,主要由IBM SPSS 22.0.R.和Graphpad 5.0生成。K-S是用来检测研究LR的分布情况。
2.结果
2.1、LR值的统计学参数和STR数量的关系
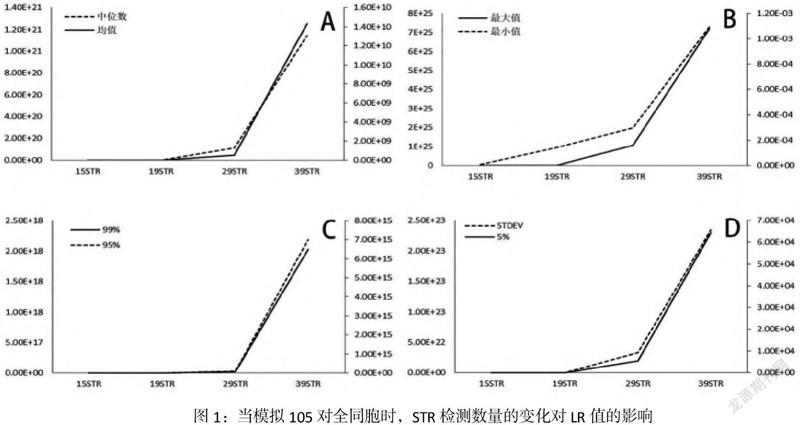
能够看到个体1和个体2的全同胞指数(全同胞指数、FSD和LR值)。发现当STR基因座数从15个增加到39个时,LR值增加,包括中位数、平均值、最大值、最小值、99%,95%、5%、1%和标准偏差相应增加(见图1)。
结果表明,增加检测系统中STR的数目,可以提高检测效率,可以得到更高的LR均值和一个更大的极点。STDEV值随LR的增加而增加。(表1-4)
2.2、LR值和模拟人群数量之间的关系
在一定的情况下时,并且模拟种群的数量都超过1×106时(表1-4),LR的中位数、平均值和标准差增加。随着模拟种群数量的增加,LR的最大值和最小值都会增加或减少。当模拟总体数较少时(100到10000),尽管LR中值的差异很小(在相同的数量级上),然而,LR的平均差異非常显著,见图2。但当模拟人口超过105,99%,95%和,5%和1%的LR值保持相同的数量级。除此之外,LR最大值和最小值的分布表明,随着模拟种群规模的增大和模拟量的膨胀,LR将有一个极值(图2)。考虑到这个世界真正的人口,极值问题就会出现在真正的人口中,并且可能大于表1-4中的数据。
3.讨论
由于软件和计算机仿真能力的限制,我们无法进行仿真超过106数据。STDEV值随时间的增加而增加,模拟次数增加了10-1000倍,这反映了LR值和极值的很大变化。同时,平均数和平均数字变异没有太大的变化,约为10倍。这反映了当模拟次数超过104时,系统被认为是稳定的。此外,系统中STR的数量越多,灵敏度和假阳性率也越高。
3.1、STR数量的影响
阈值的灵敏度是在设定一定的阈值时能够被检测到两组的假阳性率均为0。根据LR的定义,当LR大于1时,支持H0,反之支持H1。实际上,例如当LR大于100时,更可能选择更高的LR阈值来降低误判率。因此,在一定的阈值情况下,真阳性率和假阴性率就会产生。其中,误判率是假阳性率和假阴性率之和。随着阈值的增大,系统的灵敏度降低,假阳性率会随着假阴性率的增加而降低。根据本文得到的数据,统计分析得出,设定适当的LR阈值可以检测出系统的判断能力,遗传标记的数目可以提高系统的灵敏度,同样的人口规模,总体趋势是,随着遗传标记数量的增加以及随着阈值的增大,会降低假阳性出现的概率。
3.2、模拟全同细胞数量的影响
通过模拟103-104个系谱,法医科学家找到了10个亲属的LR在体内的分布。我们发现这种模拟会降低LR阈值和存在一定程度的假阳性。本文由39哥STR组成检测过程中,LR阈值设置为1-108,模拟量为1000对全同细胞,未在所有兄弟姐妹中发现假阳性。值得注意的是,模拟数量是1× 104时或者LR阈值0.1时假阳性率也会出现。
在实际情况中,如果两个人在识别过程中得到L当数据值超过100000时,可以100%确定整个同级关系。当LR大于105时,假阳性率变为0。但是,我们应该警惕假阳性的出现。根据现实世界中,对于大量的兄弟姐妹来说,假阳性的概率应该很低。因为现在还没出现具有更大的模拟功能的软件,因此,我们只能根据实验得到的数据进一步计算了同胞的数量,并由此进行推断。
结语:
在本文中,我们模拟了大量的全同胞数据,找到了其LR分布存在的一定规律,然而,并没有被考虑基因和基因座之间的联系,并且还会出现STR基因座突变的存在。虽然建立了5种突变模型,但本研究未进行突变模拟。这种突变确实存在,而且在LR值分布中起着重要作用。另外,有报道称我们的模拟基因vWA-D12S391、D5S818-CSFIP0、D21S11之间的联系较弱,但由于其在法医遗传学中的作用,它广泛应用于免疫分析试剂盒中,他们之间的联系可以不作为参考。本研究的模拟结果可为法医遗传学和辨识似然率临界值的确定提供了参考,更为准确的分析亲属关系准备了做出了一定的贡献,能起到一定的作用。
参考文献:
陈子翔,王福振,陆惠玲,等,判别函数在同胞鉴定中的应用[J],中国法医学杂志,2012,27(2):129—132
个人简介
宋翠芹,出生年月日:1992年4月21日,女,汉,江苏徐州人,本科,助理,目前在南京鉴云技术咨询有限公司从事DNA实验室相关工作
南京鉴云技术咨询有限公司 210000
