
基于三次精调的人脸分割方法
2021-09-10 07:22黄娜赵志刚于晓康
青岛大学学报(自然科学版) 2021年2期
黄娜 赵志刚 于晓康











摘要:针对人脸分割的精度问题,提出了融合网络深层特征和浅层特征的新结构,三次精调人脸检测框,提高人脸分割的精确度。新结构结合通道注意力与空间注意力机制,利用深度分离卷积,为每个通道特征提供各自对应的注意力权重,充分利用深层语义信息与浅层定位信息,为精确分割提供特征信息,三次精调为分割提供准确的检测结果。实验结果相比Mask R-CNN的mAP提高0.1,相比最新方法mAP提高0.2。
關键词:人脸分割;精调;通道注意力;空间注意力
中图分类号:TP391
文献标志码:A
收稿日期:2020-09-30
通信作者:
于晓康,男,博士,副教授,主要研究方向为计算机几何,计算机图形学,计算机视觉等。E-mail: xyu_qdu@163.com
人脸是非常重要的特征,人脸检测、人脸识别、人脸分割等技术广泛应用于安全、通信、医疗、社交等领域。Cuevas等[1]提出对光照变化有健壮性的人脸分割方法;Segundo等[2]提出基于人脸关键点的人脸分割算法;Subasic等[3]提出适用于电子身份文件识别的人脸分割模型;Khan等[4]以多任务的方式提出头部姿态估计和人脸分割的模型;Masi等[5]在人脸检测之后,通过3D投影计算得到完整的人脸形状,再通过已有的人脸分割网络得到有误差的人脸分割,计算两者之间的差异,构造新的损失函数,为人脸分割提供了新思路;Wang等[6]通过强化学习训练模型,分割视频中的人脸。但现实中人脸遮挡的情况复杂多样,现有模型对于不同场景不同弧度的人脸边界,还是无法精确分割。实例分割方法也不断更新,经典方案Mask R-CNN[7]在目标检测网络Faster R-CNN[8]的基础上,加入特征金字塔网络FPN,提出RoIAlign方法代替RoIPooling,仅添加了一个mask分支做分割,取得不错的实验效果。Masklab[9]相比于Mask R-CNN,加入方向预测的分支与mask分支特征结合;MS R-CNN[10]在Mask R-CNN中添加了MaskIoU Head分支完善评分依据。这些提高分割精度的方法多数是通过增加新的任务分支,来提供给mask分支补充信息,辅助分割任务以获得更好的效果,但没有关注目标检测和网络中间层特征对分割精度的影响。近年来在CNN中应用注意力机制的研究逐渐展开,Hu[11]认为通道注意力SE模块能够提高分类任务的准确率;BiSeNet[12]借鉴SE模块,将注意力机制应用到语义分割任务中;SKNet[13]利用注意力机制融合不同层的特征;Woo[14]提出相加融合通道注意力和空间注意力分支特征。但这些已有的空间注意力对不同通道并没有区分,使网络中间层特征没有得到充分利用,同时检测结果不准确也造成了人脸分割不精确,本文针对以上问题提出改进方法。
1 方法分析与方案
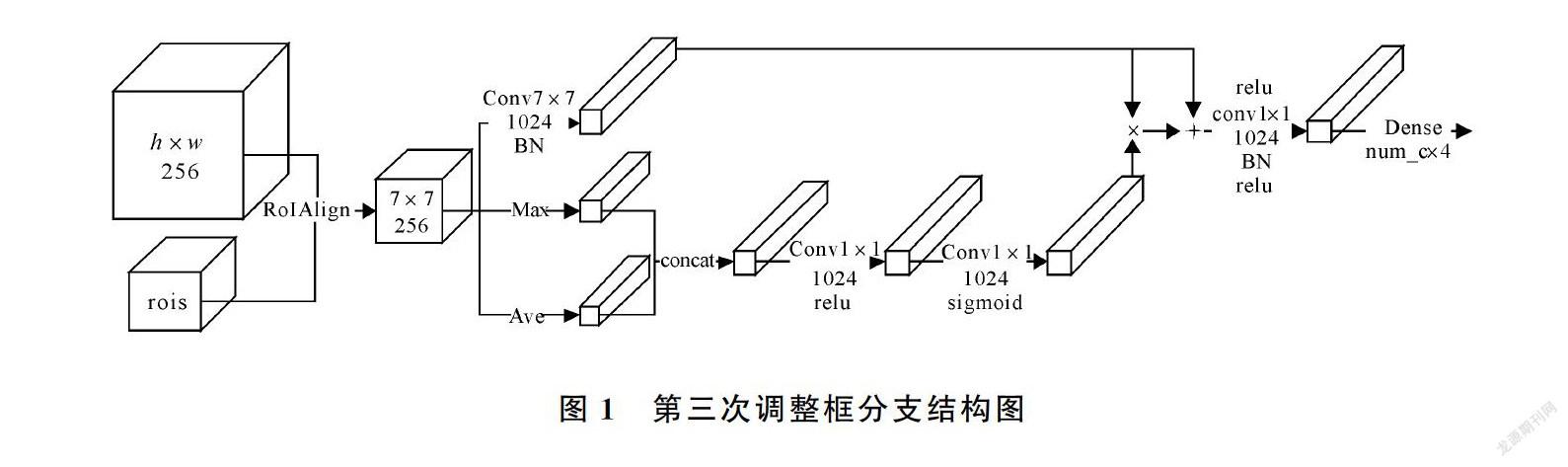
在分割任务中,检测阶段的结果至关重要,通常将检测框紧贴实例的边界定义为好的检测结果。人类脸型有多种,加上不同发型遮挡,不同姿势角度的拍摄,使图像中人脸边界弧度不同,甚至存在尖角,这给检测和分割任务增加了困难。二阶段检测通常采用两次相同的框体调整方法,先对框体的中心位置进行调整,再以中心位置为基准,调整框体四条边的位置。在调整四条边的位置时,对上边界和下边界使用相同的调整值,对左边界和右边界使用相同的调整值。存在的问题是,在中心位置没有得到准确调整时,后续进行的边框调整并不准确。针对此问题提出了改进方法,加入第三次调整分支,固定框体的中心位置不动,给出四条边各自不同的调整值。在测试过程中,串联在第二次框体调整之后,进行第三次精调。在训练过程中,训练目标由初始极值点与真实极值点计算差值得到,损失函数采用smoothL1损失函数。第三次精调分支结构如图1,对于RoIAlign截取到的7×7×256的人脸特征,分别进行无边界填充的7×7卷积操作、全局平局池化和全局最大池化操作,拼接两种池化的结果,输出特征维度为1×1×512,一层1×1的卷积+relu激活,一层1×1的卷积+sigmoid激活获得通道感知。得到的通道感知与7×7的卷积结果相乘,作为残差分支加入7×7的结果分支再做一次relu激活。最后经过一层1×1的卷积+BN操作+relu激活,全连接调整维度,得到4条边各自的调整值。
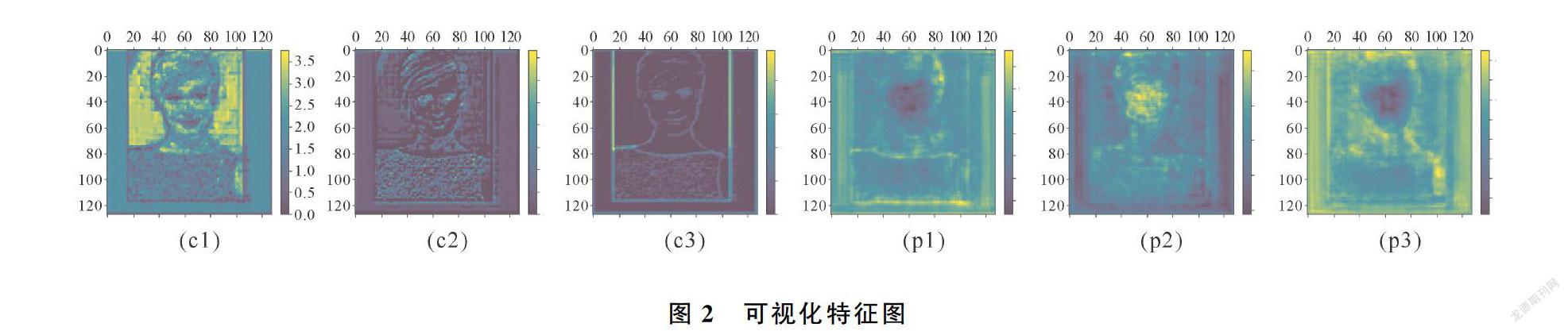
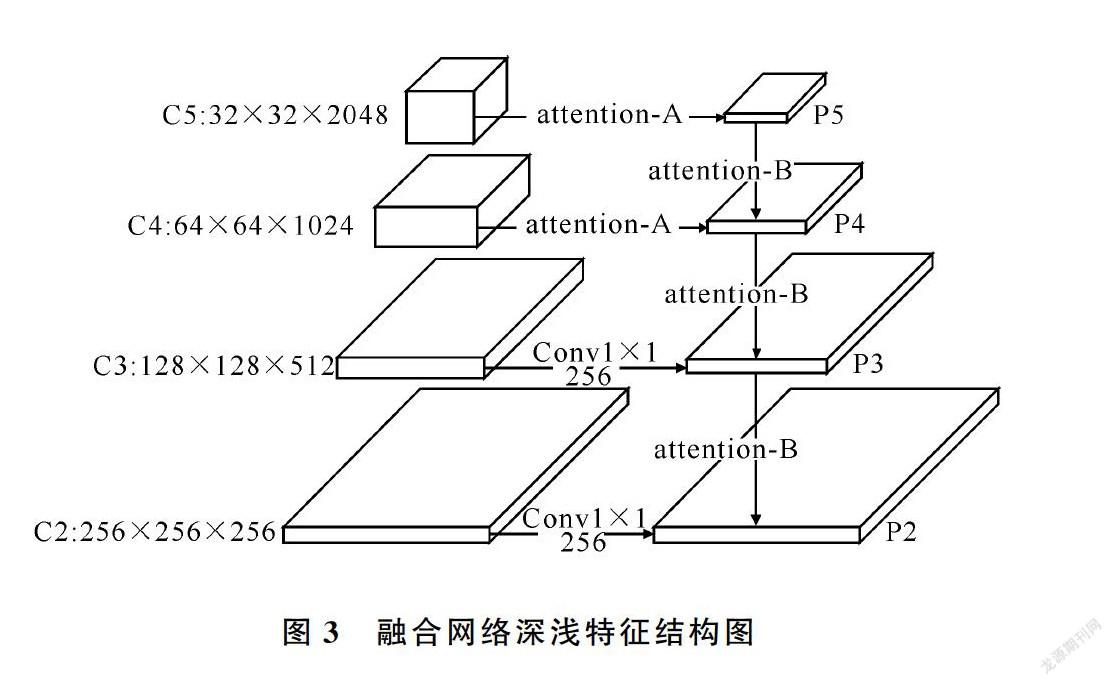
特征金字塔网络FPN将网络深层的语义信息传递到浅层,浅层特征有了语义信息的补充,但是定位信息有所丢失,影响人脸分割结果,尤其是小面积人脸,因为小面积人脸的特征是在网络浅层截取的。图2的(c1)、(c2)、(c3)为主干网络resnet-101的C3特征,叠加深层特征后为(p1)、(p2)、(p3),叠加后的特征更模糊不清。PANet[15]改进了FPN也只是考虑将浅层定位信息传递到网络深层。针对以上问题,本文结合注意力机制,提出融合深浅特征的新结构,充分利用网络深层特征和浅层特征。主干网络resnet-101的C4、C5层的输出通道数分别是1 024、2 048,通过1×1的卷积降维到256个通道,信息的损失很大,因此对于C4、C5层特征,由模块attention-A替换普通的1×1的卷积,如图3。
模块attention-A的结构见图4,先对输入特征分别做全局平均池化和全局最大池化,拼接两种池化的结果,第一次全连接降维到128通道+relu激活,第二次全连接调整维度与输入特征通道相同+sigmoid激活,得到各通道的权重,与输入特征对应通道相乘,受resnet的启发,再与输入特征相加。经过attention-A,有利的通道特征获得更大的权重,特征得到了增强。已有的基于空间的注意力是应用于所有通道的,由此提出注意力模块attention-B,结合通道注意力机制和空间注意力机制,为每个通道特征生成各自不同的注意力,具体结构如图5所示。对于输入特征Input,三个并列的分支分别做上采样操作、全局平均池化操作和全局最大池化操作。对上采样放大后的特征先进行
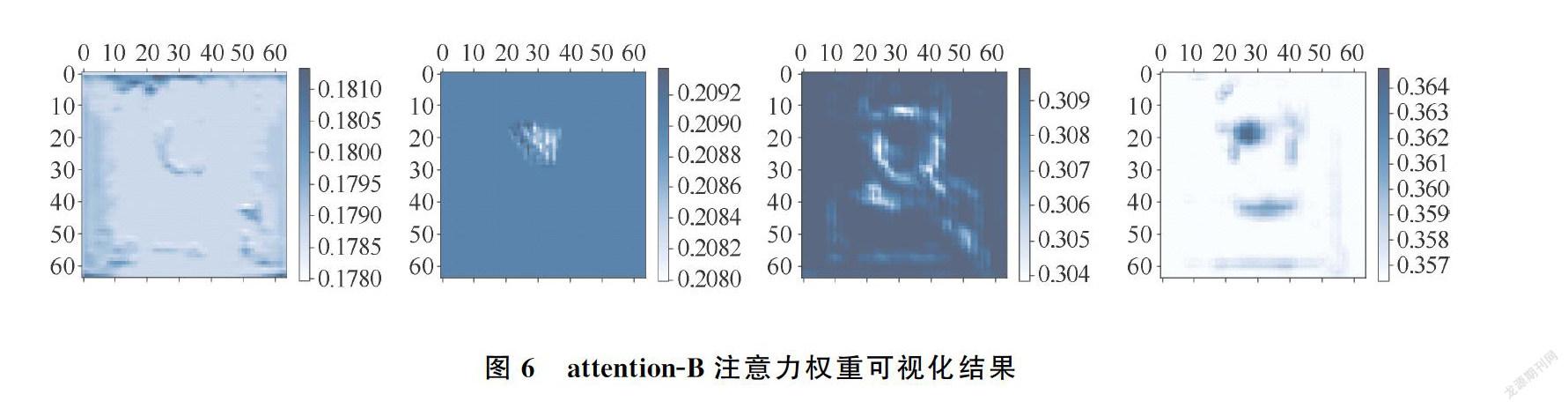
一层3×3Depthwise卷积操作+relu激活,再进行一层3×3 Depthwise卷积操作+sigmoid激活,得到每个通道各自的空间注意力。全局平均池化操作和全局最大池化操作的结果相拼接,一层全连接层降维到128通道+relu激活,一层全连接层恢复维度到256通道+sigmoid激活,得到通道注意力。将两种注意力相乘,再与放大的特征相乘。受文献[12]启发,再将相乘的结果与放大特征相加,得到经注意力机制引导的深层特征,加到浅层特征中。图6可视化C5到C4层的attention-B生成的权重,证实能够得到每个通道不同的注意力。
2 实验
为使模型得到有效训练,训练集需要多种面积的人脸图像,本文实验组合了300 Face in Wild数据集、Multi-Task Facial Landmark (MTFL)数据集、coco数据集中不同大小的人脸图像,其中训练集1 800张,验证集240张,使用labelme标注工具制作训练目标,实验选用resnet-101做主干网络,为减少GPU内存的使用,设定resnet-101的C1-C4层不参与训练,使用在coco数据集预训练的权值。由本文提出的attention-A、attention-B结构融合深浅层特征,第一、二次的框体调整与RPN网络的调整方法相同,第三次框体调整由本文提出的第三次精调分支调整,调整后截取对应的特征进行分割预测。整体损失函数为
L=Lrpn_class+Lbox1+Lclass+Lbox2+Lbox3+Lmask(1)
其中,Lrpn_class表示RPN网络的前背景分类损失,Lbox1表示第一次框体调整分支的损失,Lclass表示最终的分类损失,Lbox2表示第二次框体调整分支的损失,Lbox3表示第三次精调分支的损失,Lmask表示人脸分割mask的损失,L计算整体损失和。每次迭代训练1 800张图,共迭代200次,初始学习率0.03,学习率衰减0.01,权重衰减为0.000 1,动量为0.9。实验环境Intel(R) Core(TM) i5-3570K CPU,Nvidia GeForce GTX 1080 GPU,tensorflow-gpu2.0,keras2.3。
2.1 人脸检测实验结果
图7展示了Mask R-CNN和本文方法的人脸检测结果,实验过程中主干网络、参数设置一致。可见本文提出的第三次精调分支是有效的,三次调整后的检测框能更好的贴合人脸。表1和表2计算了人脸检测的平均IoU和IoU阈值在0.5~0.95之间的mAP,本文方法的结果更优。其中IoU是预测框pre_box和真实框gt_box的交集和并集的比值
IoU=pre_box∩gt_boxpre_box∪gt_box(2)
评价指标mAP由准确率Precision和召回率Recall计算得到。准确率Precision
Precision=TPTP+FP(3)
召回率Recacll
Recall=TPTP+FN(4)
其中,TP表示被预测为正,实际也为正的样本数量;FP表示被预测为正,实际为负的样本数量;FN表示被预测为负,实际为正的样本数量;TN表示被预测为负,实际为负的样本数量。大于IoU阈值的记为正样本,小于IoU阈值的记为负样本。平均准确率AP的计算取召回率变化的节点划分区间,取对应区间准确率的最大值与区间长度相乘作为区间AP,最后区间AP相加得到最终的平均准确率AP,mAP是计算多种IoU阈值的AP均值。
2.2 人脸分割实验结果
Mask R-CNN、文献[5]和本文方法的人脸分割结果如图8,实验结果证明第三次精调分支能有效提高检测的准确度,进而提高人脸分割的精确度。本文提出的深浅层特征融合结构能更好的结合网络深层的语义信息和浅层精确的定位信息,对弧度较大的人脸边界分割更精确。表3计算了三种方法的AP和mAP,IoU由预测人脸mask和真实人脸mask label计算得到。由表中数据可见本文方法的准确率更高,文献[5]由于网络结构较简单,特征提取不够充分,准确率略低,但为人脸分割领域提供了新思路。表4使用同样的验证集测试,比较了文献[5]和本文预测mask与真实mask label的IoU,结果表明本文算法的分割精確度更高。由于增加了一次框体调整步骤,融合深浅层特征的结构也比单纯卷积操作复杂,本文算法整体复杂度略高。表5计算了Mask R-CNN、文献[5]和本文方法的测试用时,分别为处理50张图像和200张图像的用时。由于文献[5]的模型网络结构较为简单,用时很少,本文方法由于网络结构较为复杂,用时略长,但精确度更高。
3 结论
本文提出融合深浅层特征的新结构,充分利用网络深层语义信息和浅层定位信息,三次精调检测框。通过给出四条边框各自不同的调整值,提高人脸检测的准确度,进而提高人脸分割的精确度。但在人脸分割任务中,对于头发等细致的物体对人脸造成遮挡时,分割的精度还有待提高。现有的人脸分割网络计算量较大,如何精简网络算法,提高计算速度,也是今后继续深入研究的方向。
参考文献
[1]CUEVAS E, ZALDIVAR D, PEREZ M, et al. LVQ neural networks applied to face segmentation[J]. Intelligent Automation & Soft Computing, 2009, 15(3):439-450.
[2]SEGONDO M P, SILVA L, BELLON O R P, et al. Automatic face segmentation and facial landmark detection in range images[J]. IEEE Transactions on Systems Man & Cybernetics Part B Cybernetics, 2010, 40(5):1319-1330.
[3]SUBASIC M, LONCARIC S, HEDI A. Segmentation and labeling of face images for electronic documents[J]. Expert Systems with Applications, 2012, 39(5):5134-5143.
[4]KHAN K, AHMAD N, KHAN F, et al. A framework for head pose estimation and face segmentation through conditional random fields[J]. Signal, Image and Video Processing, 2019, 14(1):159-166.
[5]MASI I, MATHAI J, ABDAIMAGEED W. Towards learning structure via consensus for face segmentation and parsing[C]// 33rd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, 2020:5507-5517.
[6]WANG Y J, DONG M Z, SHEN J, et al. Dynamic face video segmentation via reinforcement learning[C]// 33rd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, 2020:6957-6967.
[7]HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[C]// 16th IEEE International Conference on Computer Vision (ICCV).Venice, 2017:2980-2988.
[8]REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 36(6):1137-1149.
[9]CHEN L C, HERMANS A, PAPANDREOU G, et al. MaskLab: Instance segmentation by refining object detection with semantic and direction features[C]// 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, 2018:4013-4022.
[10] HUANG Z J, HUANG L C, GONG Y C, et al. Mask scoring R-CNN[C]// 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, 2019:6402-6411.
[11] HU J, SHEN L, SUN G, Squeeze-and-excitation networks[C]// 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Salt Lake City, 2018:7132-7141
[12] YU C Q, WANG J B, PENG C, et al. BiSeNet: Bilateral segmentation network for real-time semantic segmentation[C]// 15th European Conference on Computer Vision(ECCV). Munich, 2018:334-349.
[13] LI X, WANG W H, HU X L, et al. Selective kernel networks[C]// 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach, 2019:510-519.
[14] WOO S, PARK J, LEE J, et al. CBAM: convolutional block attention module[C]// 15th European Conference on Computer Vision (ECCV). Munich, 2018:3-19.
[15] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]// 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, 2018:8759-8768.
[16] WANG F, JIANG M Q, QIAN C, et al. Residual attention network for image classification[C]// 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, 2017:6450-6458.
Face Segmentation Method Based on Three-fold Fine Tuning
HUANG Na, ZHAO Zhi-gang, YU Xiao-kang
(College of Computer Science and Technology, Qingdao University, Qingdao 266071, China)
Abstract:
As regards the precision of face segmentation, a new structure combining the deep and shallow features of the network was proposed, and the face detection frame was fine-tuned three times to improve the accuracy of face segmentation. The new structure combined the mechanisms of channel attention and spatial attention, and utilized depthwise separable convolution to provide corresponding attention weight for each channel feature. And semantic and location information were fully used to provide feature information for precise segmentation, and the third fine-tuning provides accurate detection results for segmentation. Compared with Mask R-CNN, the experimental results of this paper increase mAP by 0.1 and 0.2 compared with the latest method.
Keywords:
face segmentation; fine-tuning; channel attention; spatial attention
