
基于Image_Caption的车厢场景自适应描述
2021-09-10 07:22刘铮周述正赵祎婷卢铭娜
交通科技与管理 2021年16期
刘铮 周述正 赵祎婷 卢铭娜
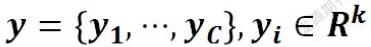
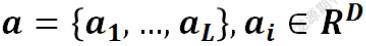

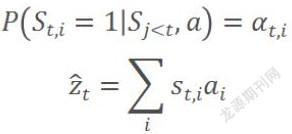
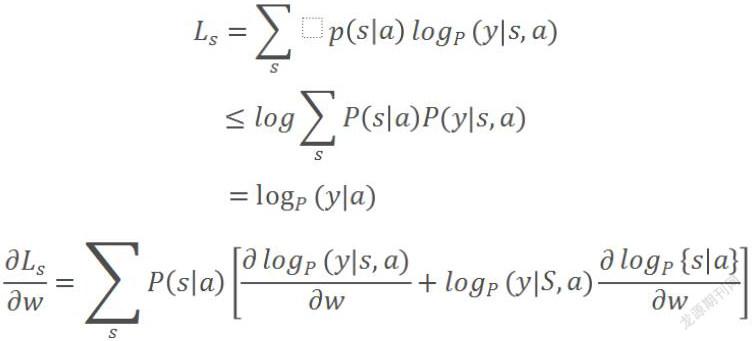
摘 要:图像自适应描述(Image_Captioning),是指以图像为输入,通过模型和计算来输出对应图像的自然语言描述。这一领域是结合了人工智能两大方向:计算机视觉和自然语言处理。将图像自适应描述算法应用于地铁车厢内部情况检测,有利于车站管理人员迅速全面掌控车厢内部情况,快速应对车厢内部突发情况。有利于提示车厢内部乘客互相照顾,提高车厢内部优质资源分配合理性(如残疾人以及孕妇让座)。
关键词:图像自适应描述;人工智能;车厢
1 图像自适应描述算法
Image Caption(图片描述)模型中,以图片数据作为输入,经过CNN进行卷积提取图片特征信息最终形成图片的特征图信息,而后attention模块对提取的特征图进行加强与抑制,作为后续进入LSTM模型的输入数据,不同时刻的attention数据会受到上一时刻LSTM模型输出数据而有所调整,LSTM模型最终输出文本信息。
2 模型细节
2.1 encoder模块
Image Caption(图片描述)模型的最终输出为一个长度为C的句子,其中yi指句子中的第i个词,这个词属于一个k维实数的词向量,其中K是字典长度。在encoder阶段,文中使用的是CNN(卷积神经网络),用于提取特征图向量集合,这些特征图向量后续会被作为注释向量。
通过CNN会提取L个特征图向量,命名为a,每一个都是D维向量用来代表图片的一部分。同时为了保留特征图与2维图片的关系,本文中的特征来自于较浅的卷积层,由此保证后续的decoder阶段,能够通过选取所有特征图的子集而选择性聚焦到图片的部分位置。
2.2 decoder模块
在decoder阶段模型使用的是 long short-term memory (LSTM,长短时记忆模型)network,图片的说明文字由本模型生成,在预测每一个词的时候都会需要使用背景向量、前一時刻的隐藏层向量、前一时刻的词向量。
decoder节段是一个标准的LSTM过程,每个LSTM需要以下输入:
(1)背景变量Z,来源于图片经过CNN提取特征后,再使用attention进行过滤后的向量。(2)前一时刻的隐藏层向量h。(3)前一时刻的词向量E,此时的词被转化为embeding向量。
2.3 背景向量Z的计算
背景向量Z的含义,Z是在t时刻,输入图片数据的动态表达,Z是基于输入图片数据的,后续的加工依赖于注释向量a。随着时间的不同,Z向量随前一时刻输出的y而变化。
(1)通过att函数计算第i张特征图ai与上一时刻隐藏向量ht-1的关系eti。
(2)使用归一化,将eti转化为概率值,成为attention系数αti,αt既是指t时刻attention的集合。
(3)特征图集合a中元素分别于attention系数中αti计算得到t时刻背景向量 。
3 attention机制--hard attention
计算特征图与隐藏向量间关系时用到了att函数(hard attention ),hard attention是使用一种随机的方法计算attention系数α。首先先设定一个t时刻的位置变量st,st是指在t时刻生成词的时候模型需要聚焦于图片的哪些位置。在hard-attention 模型中,st是一个one-hot编码向量,st,i中最大的值为1,其余均为0。该模型会把与生成下一个词最相关的特征图提取出来并将其他特征图抛弃。
4 损失函数
5 实验与分析
(1)实验环境:Cpu:E5-2630L v3 内存:64g Gpu:NVIDIA GeForce 3090。
(2)训练数据为flickr8k数据集。
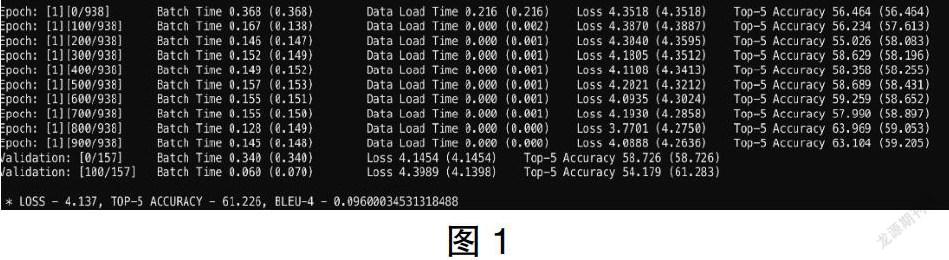
(3)网络构建及训练:本次实验特征提取模型采用densenet121,epoches设置为2 000,encoder_learning_rates设置为1e-4,decoder_learning_rate设置为4e-4。
(4)测试结果:
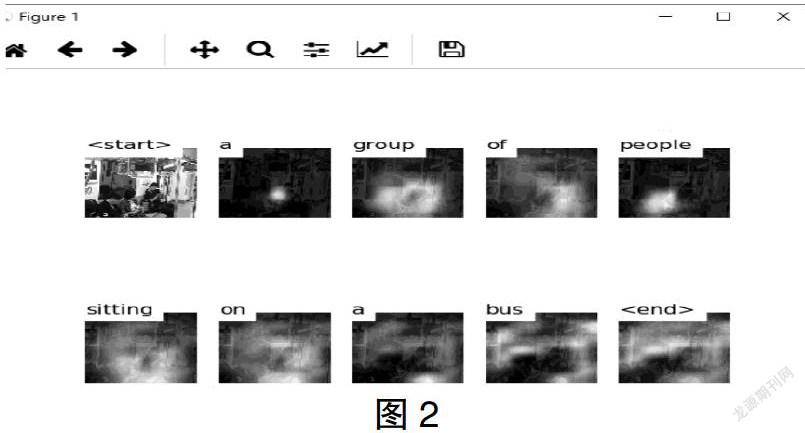
经过2 000轮的训练后,使用轨道车厢内部图片对模型进行验证。识别描述的准确率在80%以上。
6 结束语
经过研究后发现image_captioning算法在地铁车厢这一场景,可以对乘客行为进行较为合理的描述,在轨道车厢内部安防领域具有较大前景,具有智能度高,易推广等优点,极具开发潜力。
猜你喜欢
环球时报(2020-06-11)2020-06-11
科学Fans(2019年6期)2019-07-26
商界(2019年12期)2019-01-03
阅读与作文(英语初中版)(2018年8期)2018-12-27
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
青春(2017年5期)2017-05-22
南风窗(2016年19期)2016-09-21
南风窗(2016年19期)2016-09-21
小小说月刊(2010年9期)2010-05-14
