
基于最小二乘参数估计的和谐型机车故障数据统计模型建立方法*
2021-09-11 10:03李忠厚艾厚溥
铁道机车车辆 2021年4期
李 昊,李忠厚,蔡 两,艾厚溥
(1 中国铁道科学研究院集团有限公司 机车车辆研究所,北京100081;2 中国铁道科学研究院 研究生部,北京100081)
科学的数据分析是将数据资源转化为效益的有效方法。和谐型机车自2007年起批量配属,2018年开始产生最高等级修程,经过10多年的运用检修和修程修制改革的不断摸索,积累了大量的经验数据。深入开展数据分析方法研究与实践,是进一步掌握机车可靠性规律,不断深化修程修制改革的重要手段。
目前和谐型机车检修执行计划预防修和以可靠性为中心的维修相结合的修程修制体系,C1~C4修为段级修程,C5、C6为高级修程。和谐型机车可视为一个可修复系统,机车整车的可靠性在检修完成后会得到恢复,特别是高级修程后,其可靠性会发生一定变化。因此应以高级修周期作为统计样本对和谐型机车的可靠性进行分析。
和谐型机车是机械、电子、计算机、自动控制、材料等技术的集成,是一个复杂的系统。通过大量的调查和研究表明,复杂技术装备的失效率曲线不再是单一的浴盆曲线[1]。其故障规律主要由以下几种情况叠加而成:
(1)和谐型机车机械活动部件的失效,其故障率符合传统的失效理论,即其失效率遵循浴盆曲线,具有明显的早期失效期、偶然失效期和耗损失效期。
(2)电器、电子、通信部件,其故障规律不再符合传统的浴盆曲线。电子、电力、微机控制系统的器件其失效率随时间增长而下降,下降到一定程度时保持稳定。
(3)机车进行高级修程维修工作时,部件的车上拆装、车下分解、软件更新等作业均会产生一定的维修次生故障,从而带来一定的早期失效。
(4)和谐型机车在修程修制改革后一个高级修周期为110万km,根据机车运行速度的不同,折合成时间约为3~5 a。随着运用时间、高级修次数的增加,运用检修人员的经验得到积累,融合工艺进步、管理水平提高等多种因素也会带来机车质量的提高。
1 数据来源与规律初探
文中采用和谐型电力机车在修程修制改革前一个高级修周期(100万km)内发生设备故障时的走行公里观测值作为统计数据,共1391条数据,数据概况如图1所示。

图1 和谐型机车故障数据概况
故障数据对应的机车样本数在各公里区间有所不同,具体见表1。

表1 各公里区间机车样本数统计表
以百万公里平均故障率作为评价指标对和谐型机车故障规律进行判断[2],设在第i个运行间隔[iΔt~(i+1)Δt]内有Ni台机车投入运行,期间累计发生Δri次故障,则该运行间隔内的百万公里平均故障率λˉi为式(1):

得到机车一个高级修周期内百万公里平均故障率,如图2所示。

图2 百万公里平均故障率统计
根据机车故障数据初步分析结果,结合连续型随机变量常见分布的特点,假设机车故障符合威布尔分布。
威布尔分布在可靠性工程中的应用很广[3],尤其在描述轴承的寿命过程用得较多。大量实践说明,凡是因局部失效或故障引起全局失效的元件、器件、设备、系统等的寿命分布服从威布尔分布[4],其概率密度函数为式(2):
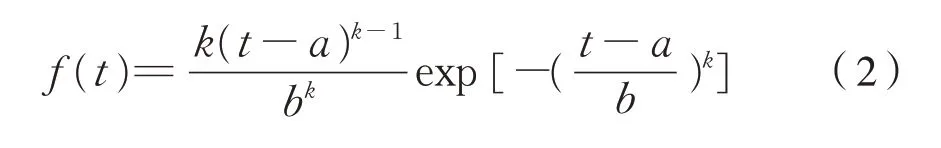
式中:k为形状参数;a为位置参数;b为尺度参数。
2 机车故障数据的参数最小二乘估计
由于机车故障从一个高级修周期开始即有可能发生,因此取位置参数a=0,用两参数威布尔分布对数据进行分析,其累计概率密度函数为式(3):
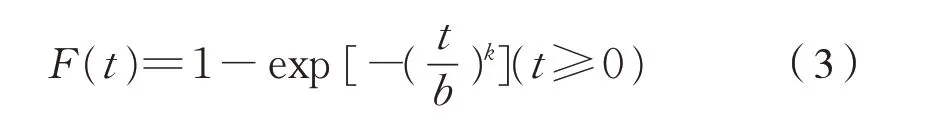
设线性回归方程为式(4):

对式(3)进行线性变换[5]得式(5)~式(8):

参数的最小二乘估计是以因变量的估计值与观测值二者之差的平方和最小作为拟合最优的评判标准。在已经获得样本观测值的情况下,假设参数估计量已经求得到,为和̂,并且是最合理的参数估计量,那么直线方程式(9):

根据最小二乘法,使式(10)最小。
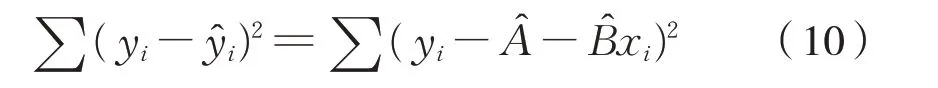
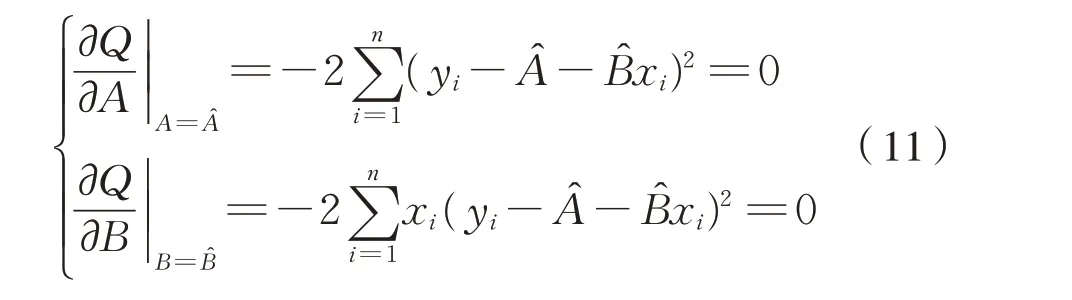
解上述方程组得式(12)和式(13):
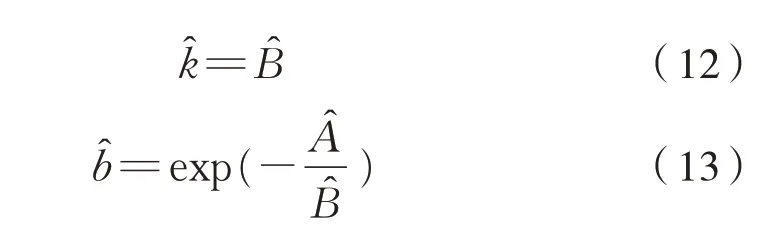
3 机车故障数据的假设检验与统计模型建立
首先建立假设,确定显著性水平:H0:样本所来自总体的分布为威布尔分布;H1:样本所来自总体的分布为非威布尔分布。取显著性水平α=0.05。
采用Kolmogorov-Smirnov检验法进行假设检验(下文简称:K-S检验),K-S检验是一个拟合优度检验,研究样本观察值的分布和设定的理论分布是否吻合,通过对2个分布差异的分析确定是否有理由认为样本的观察结果来自所假定的理论分布总体。
K-S检验的基本思路是:先将数据的理论累积频率分布[6]与观测的经验累积频率分布加以比较,求出它们最大的偏离值,然后在给定的显著性水平上检验这种偏离值是否是偶然出现的。
F0(X)为已知的样本累计分布函数,记样本所来自总体的累计分布函数为F(X),判断样本数据X1,……,Xn是否来自某个特定分布函数F0(X),此时需要检验的原假设H0为:F(X)=F0(X)。已知样本经验分布函数为S(X),为F(X)的一个近似,因此若H0成立,S(X)与F0(X)应相差不大。先计算检验统计量Dn,然后查D临界值表确定统计判断。
该检验方法的检验统计量Dn为式(14):

计算K-S检验统计量,计算过程见表2。

表2 故障数据K-S检验计算表
因显著性水平α=0.05,n=1391,查临界值表,当样本数量大于35时临界值为0.08761[7],因Dn<临界值,故接受原假设,即样本所来自的总体符合参数为k=0.718494692,b=1807593.396的威布尔分布。如图3所示。
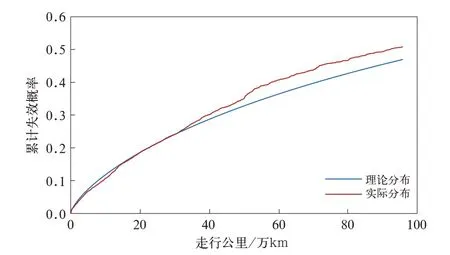
图3 机车故障理论分布与实际分布对比
在已知机车运用故障的分布后,即可建立统计模型对一个高级修周期内机车故障进行统计分析。以k=0.718494692,b=1807593.396给出机车整车可靠性指标的函数:
可靠度函数为式(15):

失效率函数为式(16):

4 结论
通过对和谐型机车运用故障数据的分析,得出了以下结论:
(1)通过参数的最小二乘估计可以有效地对一个高级修周期内和谐型机车运用故障数据进行参数估计,根据K-S检验的结果,可以接受机车故障数据符合威布尔分布的假设,建立的统计学模型基本符合机车运用故障实际情况。
(2)由图3可以看出,理论分布与实际分布在50万km后的拟合优度要低于50万km前,是因为在50万km后的机车样本和数据量均低于50万km前,而最小二乘参数估计的计算方法决定了其建立的理论分布更贴近数据量大的部分。如50万km后数据量进一步积累,则拟合会更优。
(3)和谐型机车的质量规律是多种因素叠加而成的,不同类型、不同系统、不同部件的故障均有其规律。随着运用时间的不断增加,不同高级修周期内的质量规律也会发生变化。现场技术人员应加强数据累积,在整车故障统计分析的基础上,深入开展数据分析,进一步掌握机车质量规律,并应用到机车可靠性评价、设备健康管理等领域。
猜你喜欢
少儿画王(7-10)(2022年6期)2022-07-18
哈尔滨工业大学学报(2022年5期)2022-04-19
消费电子(2021年7期)2021-08-10
北京航空航天大学学报(2020年10期)2020-11-14
浙江大学学报(理学版)(2019年4期)2019-08-15
下一代英才(2018年4期)2018-05-21
科学与财富(2018年9期)2018-05-14
商周刊(2016年22期)2017-09-30
智富时代(2017年4期)2017-04-27
智富时代(2017年4期)2017-04-27
