
基于科普拉函数的电、热负荷及风电出力间的相关性分析与建模
2021-09-14 01:23杨柳,李明
吉林电力 2021年2期
杨 柳,李 明
(国网通化供电公司,吉林 通化 134001)
随着我国大规模的风电并网,给电网的运行也带来了一定的冲击,风电与热、电负荷在时间和空间上均可能存在较强的相关性,如果不考虑这种关系将会影响风电的合理消纳及风能的利用效率[1-2]。因此,在电网经济调度中有必要对风电与热、电负荷间的相关性进行精确建模,以量化变量的随机性给电力系统带来的影响,实现电网安全经济运行。
研究变量间的相关性问题的关键在于正确处理非正态随机变量之间的相关性[3]。 科普拉(Copula)理论作为多元分析方法中的一种方法,能较准确描述多元变量的相关结构,被广泛应用于两个(或多个)随机变量的依赖结构建模。该方法被用于许多领域的研究,包括金融[4]、风电场相关性分析[5]、洪水风险分析[6]、频率分析等[7]。文献[8]提出构造混合Copula函数来模拟两个风场之间的风速相关性,但没有关于模型结构和验证的细节。文献[9]基于动态Copula理论构建风光联合出力模型,用动态相关系数来描述相关性,并将其运用于数据驱动的风光联合系统中。文献[10]采用的是线性相关性建模,这对于非线性的变量无法准确地描述。鉴于此,本文提出采用Copula函数来推断Copula参数及构建风-电-热相关性模型。以某地区的热负荷、电负荷和风电出力作为数据样本,验证Copula建模的有效性,结果表明所提方法的准确性和合理性。
1 Copula理论及相关性评价指标
1.1 Copula理论
Copula是一个无论其单变量分布如何,“连接”或“耦合”两个或多个与时间无关的变量的数学函数。设H是具有边际单变量分布F和G的联合累积分布函数,X和Y是连续的二维随机变量。斯科拉(Sklar)定理指出当F和G连续时,存在唯一一个确定的Copula函数C(·)满足:
H(x,y)=C[F(x),G(y)]
(1)
Sklar定理也可以推广到多元分布的联合分布函数。
1.2 相关性指标
在非正态分布情况下,需要引入能够很好测量随机变量相关性的指标,通常通过参数和经验依赖性度量之间的理论关系来估计,如肯德尔(Kendall)秩相关系数τ和斯皮尔曼(Spearman)相关系数ρ,若τ>0,表示变量间呈正相关;τ<0,表示变量间呈负相关[11]。ρ相关系数也呈同样的变化关系。设两随机变量X,Y的分布函数分别为F(x),G(y),若u=F(x),v=G(y),则两变量之间的相关性可由τ和ρ相关系数得到,即:
(2)
(3)
2 基于Copula函数变量相关性分析与建模
Copula模型的一个显著优点就是变量的边缘分布不受限制,它可以将边缘分布和变量间相关性分开研究,所以由Sklar定理将Copula函数模型的建立分步来完成:第一步,确定变量的边缘分布,由变量的历史数据可确定边缘分布;第二步,选取适当的Copula函数,只有选取合适的Copula函数才能准确的反应变量之间的相关结构;第三步,参数估计,得出Copula函数模型中的未知参数估计值。
2.1 边缘分布估计
一般情况下,边缘分布的确定有两种方式,一种是参数方式,另一种是非参数方式。参数方式是指假设随机变量服从某一确定的分布,比如一些常用的分布,然后根据极大似然估计法估计分布中的参数,最后进行检验;非参数方式是指不需要事先假设随机变量服从哪种具体形式,而是以经验分布与核密度估计为基础,将经验分布代替整体随机变量分布,最后采用极大似然估计方法对模型的参数进行估计。在实际中,边缘分布的确定对变量间的相关性分析是十分重要的,如果选取不当,将会影响最终数据的拟合效果。所以本文采用非参数方式,基于核密度的估计方法来确立随机变量的边缘分布,对于已知的数据样本,核密度估计的结果主要取决于窗宽h的选择。设随机变量X的样品点为(x1,x2,…,xn),n为样本个数,在任意点x处的概率密度函数f(x)的核密度估计为:
(4)
其中h为窗宽或带宽,K(·)为核函数,起到一种加权作用,任一点x处的密度函数估计值的大小与该点附近所包含的样本点的个数有关,若样本点较稀疏,则估计值较小,反之则较大。对f(x)积分可以得到变量的边缘分布函数F(x),再将边缘分布函数转换为均匀分布U,对于r∈(0,1)存在:
P[F(x)≤r]=P[X≤F-1(r)]=
F[F-1(r)]=r⟺F(x)=U
(5)
2.2 Copula函数模型的确定
最优Copula函数的选取包括两个方面,一是Copula函数参数的确定,二是Copula函数类型的确定。选取合适的备选Copula函数的方法有很多种,根据分析数据的特点来选择合适的备选Copula函数。本文采用图形法,通过二元频率直方图来选择合适的备选Copula函数。如果两变量的二元频率直方图是非对称的,则可以选择冈贝尔(Gumbel) Copula函数和克莱顿(Clyton) Copula函数,如果是对称的,则选择法兰克(Frank) Copula函数、Norm Copula函数和t-Copula函数;如果二元频率直方图反应尾部的相关性,则可以选择Gumbel Copula函数、Clyton Copula函数和t-Copula函数,如果不反应尾部相关性,则选择Frank Copula函数和Norm Copula函数。在得到的各Copula函数所对应的最优参数的基础上,通过平方欧式距离检验模型的拟合度,将平方欧式距离最小的备选Copula函数作为最优Copula函数。
2.3 参数估计
在确定了边缘分布和最优Copula函数后,通过原始数据和选取的Copula函数进行模型的参数估计,采用分步极大似然估计法对变量间的Copula未知参数进行估计。根据式(6)可知,采用分步极大似然估计法进行估计,步骤为:
(6)
a.求参数θ1和θ2的极大似然值:
b.把θ1和θ2带入下式,求出Copula函数中的参数α:
3 算例分析
本文选某地一年的风力发电和电、热负荷的数据进行分析,它代表了在某地区一年中热负荷和电负荷的基本趋势和风电场输出功率的波动情况,算法流程见图1。目前变量间的相关性分析仅考虑在二元变量间进行分析,所以风-电-热三变量需要分成两两一组进行分析。

图1 算法流程
3.1 确定变量的边缘分布
采取基于核密度的估计方法来确立随机变量的边缘分布,其不需要事先假设随机变量服从哪种具体形式,只从数据本身出发,通过与经验分布对比检验核密度估计的准确性。图2分别为电负荷、风力发电和热负荷的经验分布函数和核分布估计图,由图2可知该方法可以很好地拟合样本数据,所以核密度估计是准确的。

图2 边缘分布函数
3.2 选取合适的Copula函数
在确定了电负荷、风力发电和热负荷的边缘分布后,绘制电负荷和风力发电、电负荷和热负荷、风力发电和热负荷的二元频率和频数直方图,由于篇幅有限,仅对电负荷和风力发电进行分析,其余两组分析方法相似。电负荷和风力发电的频率直方图见图3,从图3中可以看出电负荷和风电出力的二元频率直方图具有基本对称的尾部,所以初选Norm Copula函数和t-Copula函数来描述变量之间的相关结构。

图3 电负荷和风电出力的频率直方图
3.3 参数估计
确定了变量的边缘分布和选取合适的Copula函数后,通过各变量的原始数据,采用分布极大似然估计法对所选取的Copula函数进行参数估计,表1为电负荷和风电出力模型估计所得到的参数,其中皮尔森(Pearson)系数用来描述变量间的线性相关程度,Kendall秩相关系数表示随机变量间变化趋势一致相关性,Spearman秩相关系数表示随机变量间变化趋势一致与不一致的概率之差倍数,自由度为t-Copula模型中的参数,平方欧氏距离反映了Copula函数模型拟合的情况,数值越小,代表模型拟合的越好,图4和图5为得到的模型。
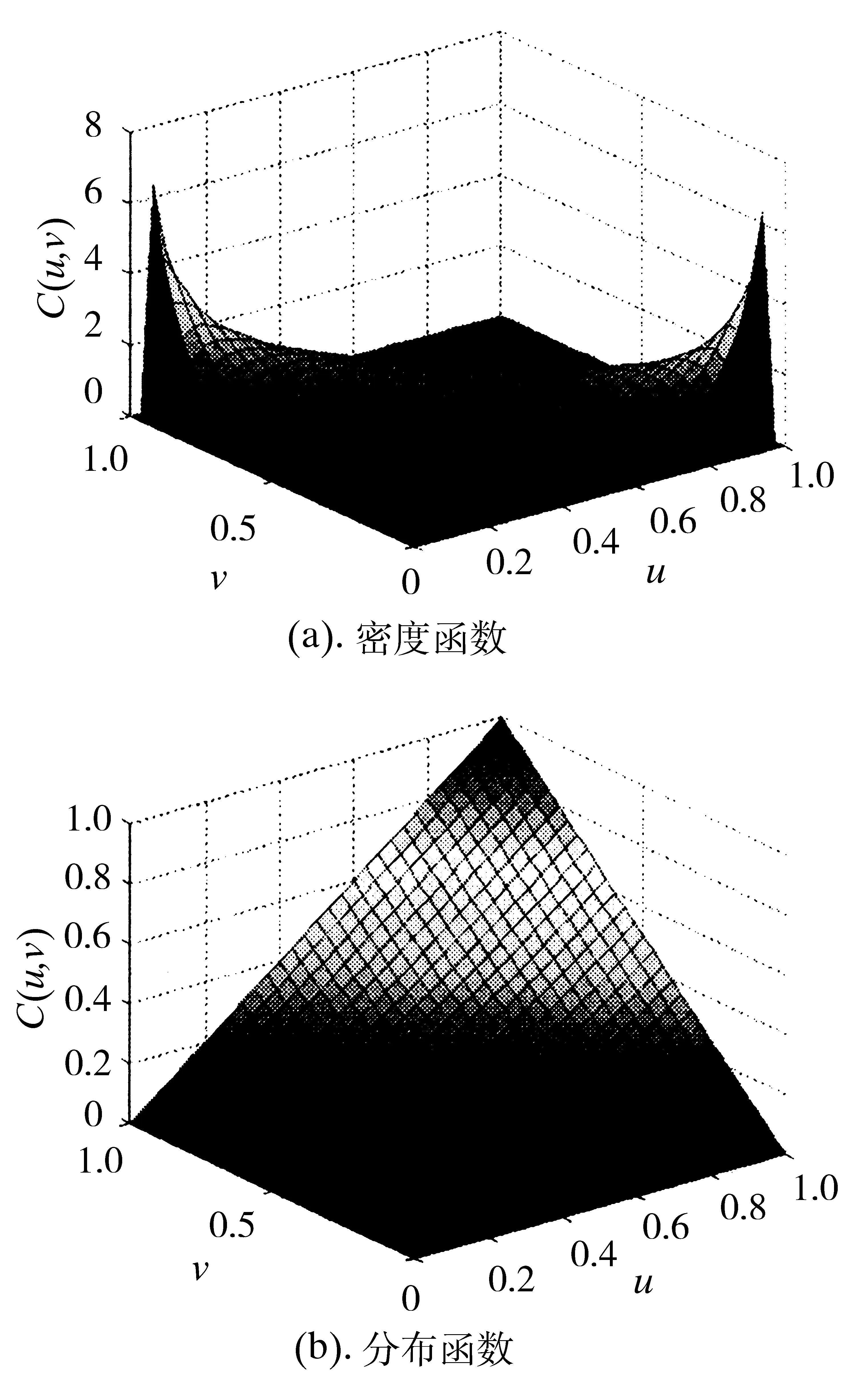
图4 电负荷和风电出力Norm Copula密度函数和分布函数

图5 电负荷和风电出力t- Copula密度函数和分布函数

表1 电负荷和风电出力的参数估计
3.4 模型评价
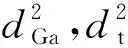
(7)

从图4和图5可以看出,电负荷和风电出力中的二元t-Copula函数的密度函数比二元Norm Copula函数的密度函数具有更厚的尾部特征,说明t-Copula函数可以更好地拟合电负荷和风电出力之间的相关关系。
4 结论
热负荷、电负荷和风电出力三者之间的相关性对于风电合理消纳、提高风能利用效率具有重要的意义。本文以Copula理论为基础,首先确定变量间的边缘分布,然后采用分布极大似然法对模型进行估计,最后通过平方欧式距离对所选取的Copula函数模型进行拟合优度检验。实例分析表明,t-Copula函数可以更好地描述电负荷与风电出力之间的相关性,并且可以准确地描述变量间的尾部相关性,避免了只关注秩相关系数的缺点。
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
哈尔滨工业大学学报(2022年5期)2022-04-19
北京航空航天大学学报(2020年10期)2020-11-14
摄影之友(影像视觉)(2018年12期)2019-01-28
初中生世界·八年级(2017年3期)2017-03-24
统计与决策(2017年2期)2017-03-20
潍坊学院学报(2016年6期)2016-04-18
系统工程与电子技术(2016年2期)2016-04-16
电测与仪表(2016年23期)2016-04-12
河南电力(2016年5期)2016-02-06
