
基于机器学习的源程序自动标注方法
2021-09-15 11:20吴军华
计算机应用与软件 2021年9期
王 瑞 吴军华
(南京工业大学计算机科学与技术学院 江苏 南京 211816)
0 引 言
随着互联网的高速发展,软件开发也越来越火热,并伴随出现了大量开源代码库[1-2]。拥有完善注释的源程序能够提高软件系统的可维护性[2-4],加快软件开发速度。但是当前情况下仅有不到20%的程序有对应的注释,所以急需开发一种自动生成功能描述性注释的方法。
文献[5]提出一种对程序源代码自动生成功能描述性注释的方法,通过在GRU神经网络中增加一个选择门,从特征向量中选择有关于功能且与当前状态相关的特征进行注释,本质上是一种翻译任务。文献[6]提出一种基于模板的生成注释方法,通过模板对程序和注释进行处理,遇到不符合模板的代码和注释则生成的注释效果较差,适用范围太窄。文献[7]提出一种基于数据挖掘的源代码注释自动生成方法,依据文中描述函数注释关键特性的两种提取规则自动生成函数整体注释,但该方法仅限于自动生成Linux内核函数的注释,普遍性不强。文献[8]提出一种使用神经网络训练数据并且利用完全驱动来生成注释的方法,对C语言代码片段和SQL查询语句进行自动注释,这种方法是将源代码当成了普通的文本,没有提取任何程序设计语言所独有的特征与特点,在源代码特征提取方面存在缺陷。针对目前存在的问题,本文采用基于LSTM-GRU网络的机器学习编码解码模型,对程序进行自动注释。
1 方法简介
本文将Java程序作为研究对象。Java程序注释主要有以下几个方面[9]。(1) 类(接口)注释。描述类(接口)的作用及其用法和使用环境、作者、版本、加入的版本、参考类等。(2) 变量注释。描述变量的作用。(3) 方法注释。描述方法的作用、使用方式、返回值、参数说明、用法实例等。
首先,采用双编码器对源程序数据集进行预处理,生成特征向量;利用分词技术、整合成字典并运用编码技术对中文注释关键词集进行预处理。然后,利用基于GRU网络的解码器进行模型训练,通过不断地对参数进行调整,使程序与注释形成映射关系。
2 源程序自动标注双码器模型
本文提出一种基于LSTM-GRU网络的编码器-解码器模型,模型如图1所示。
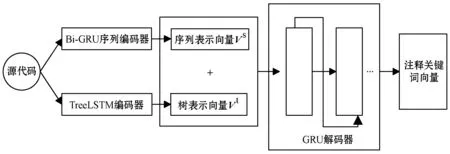
图1 编码器-解码器模型
模型主要应用了LSTM和GRU。GRU[10]和LSTM[11]是RNN的两种主要变体,其目的是对长序列中的长期依赖关系进行建模。RNN是序列建模的重要工具,已成功地应用于多种自然语言处理任务。与前馈神经网络不同,RNN可以对序列元素之间的依赖关系进行建模。
2.1 源程序特征提取
源程序采用双编码器进行处理:序列编码器(Bi-directional Gated Recurrent Unit,Bi-GRU)、TreeLSTM结构树编码器,不仅可以较精确地获得程序的序列信息,还能够得到重要的结构信息,弥补了以往方法注释不精确的缺陷。
定义1程序训练集为P={P1,P2,…,Pn},程序Pm(1≤m≤n)的源程序表示向量集为Vm={vm1,vm2,…,vmi},注释关键词表示向量集为Km={km1,km2,…,kmi}。
2.1.1源程序序列特征向量提取
这里采用Bi-GRU序列编码器提取源程序的序列特征信息。在序列编码器中,利用GRU可以解决RNN中出现的梯度消失问题。

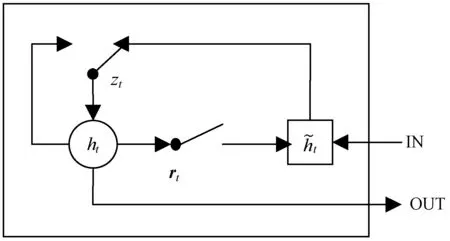
图2 GRU单元模型
而Bi-GRU是由反向GRU与正向GRU结合形成。通过两个方向相反的GRU可以更好地理解上下程序之间的信息与联系,解决了单向GRU不能利用下一时刻编码信息的问题。将Bi-GRU层几个单变量连接的特征向量作为序列编码器的表示向量Vs。模型如图3所示。
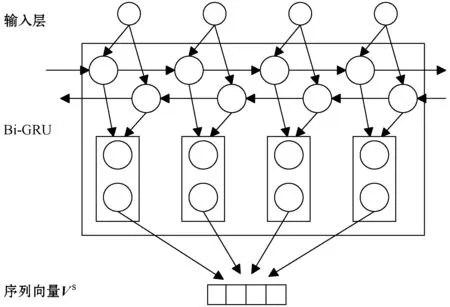
图3 Bi-GRU序列编码器模型
2.1.2源程序结构特征向量提取
源程序结构特征向量采用TreeLSTM结构树编码器进行提取。LSTM网络具备长期记忆功能。整体流程:遗忘→根据现有的输入和上一个cell的输出更新状态→根据现有的状态输出预测值。
Java程序具有三种控制结构,包括顺序、选择(if和switch语句)和循环(while、do while和for语句)结构[12-16]。本文主要针对这三种结构进行特征提取。
代码程序可以抽象为一系列程序节点的集合。程序示例如算法1所示,其中带圈数字是各个位置表示节点的标号。
算法1代码程序
标号 voideven()
① {
② ints=0,i=1;
③ for(i<100;i++)
{
④ if(i%2==0)
{
⑤ s+=i;
}
else
{
⑥ s=s;
}
⑦ }
⑧ }
算法1对应的节点控制流图如图4所示,其中:head表示语句的开始;end表示语句的结束;com表示普通表达式语句。
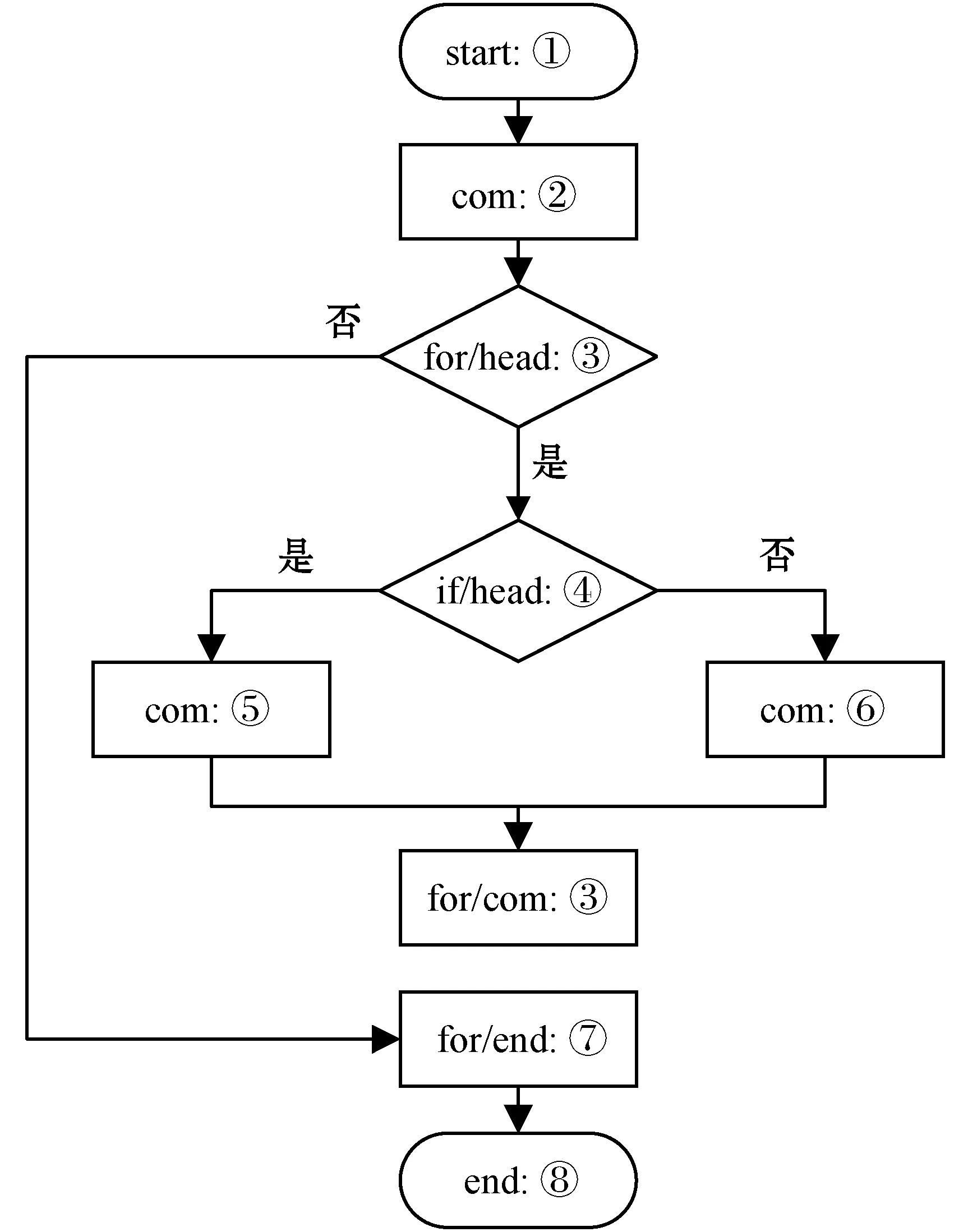
图4 程序转换节点控制流图
本文中使用的TreeLSTM扩展了基础LSTM网络,使其可以提取树形结构网络的特征信息。图5为TreeLSTM编码器模型。
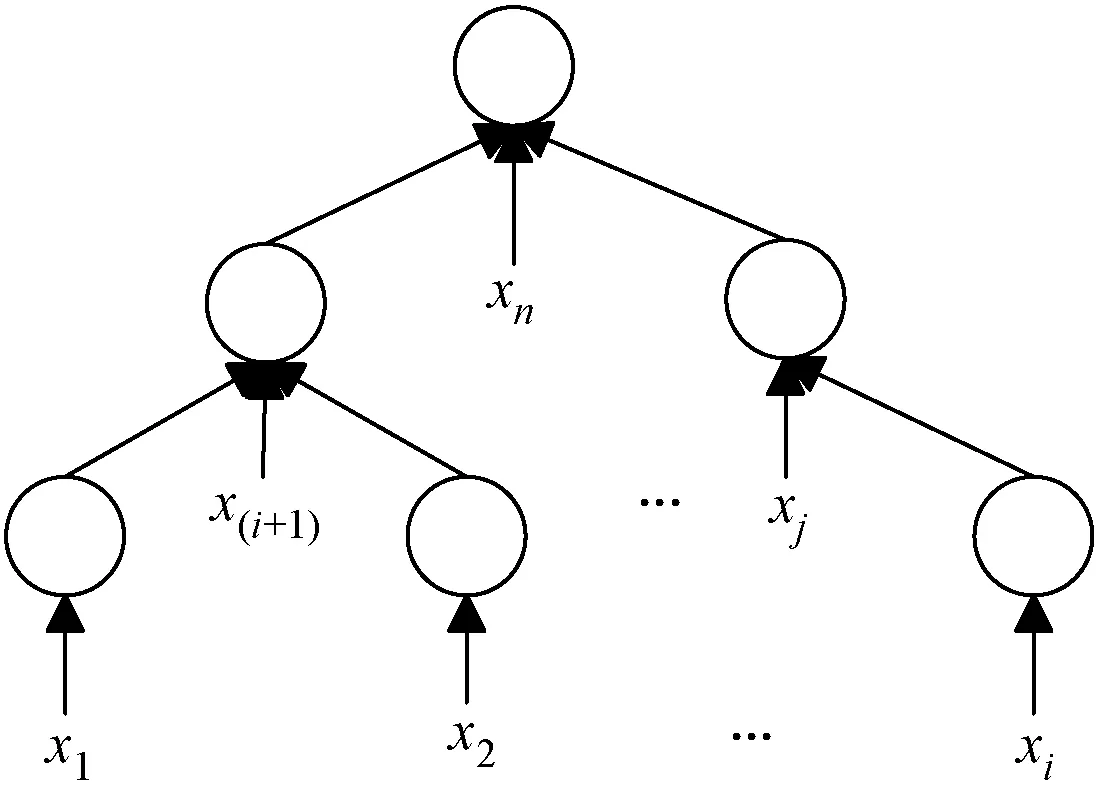
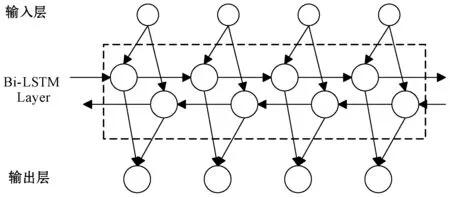
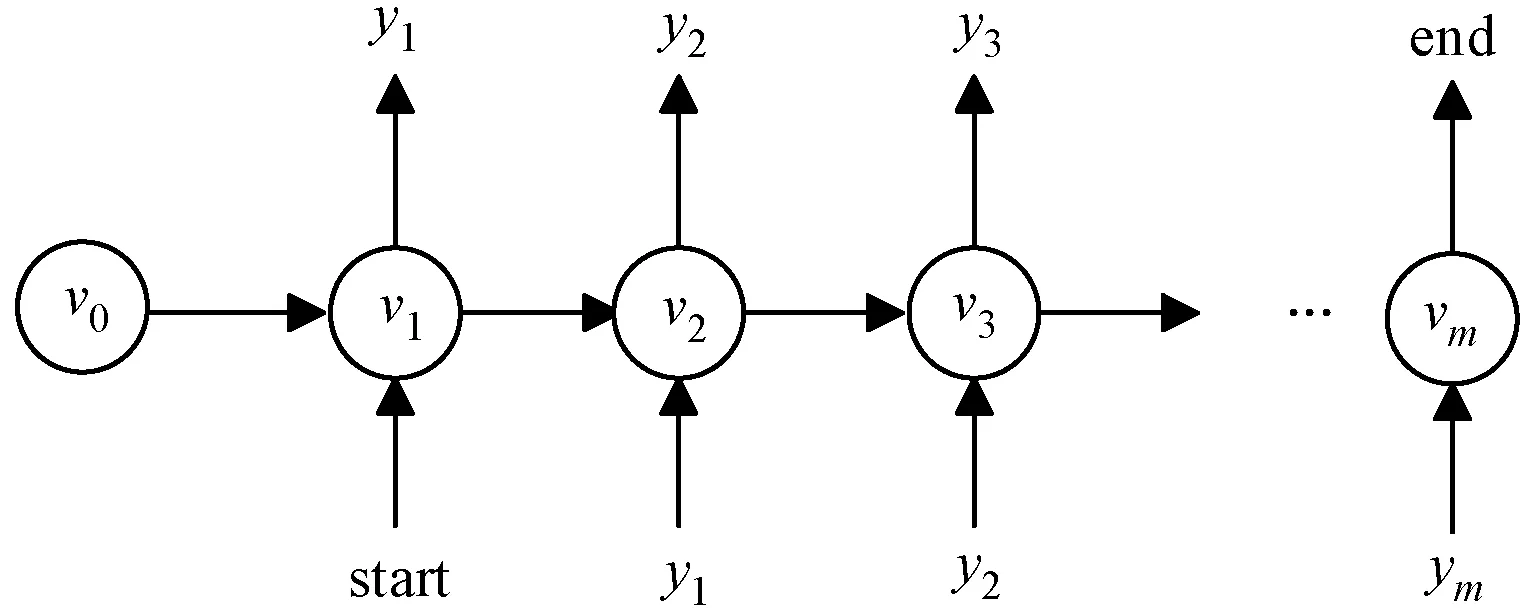
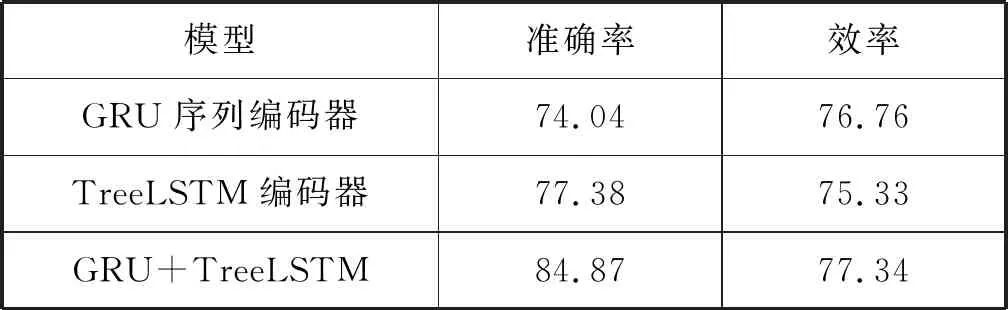
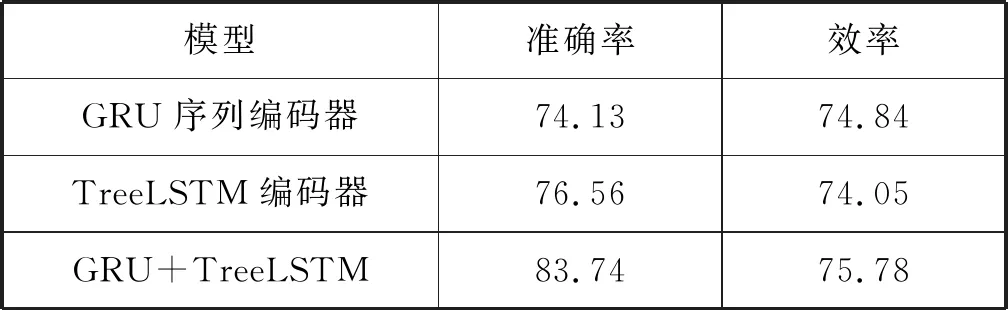
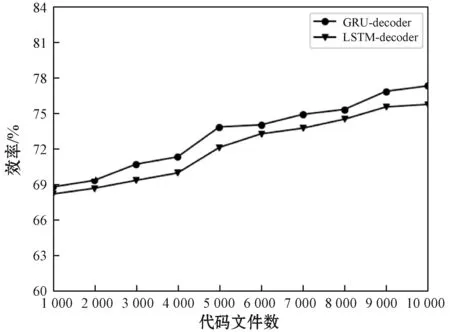
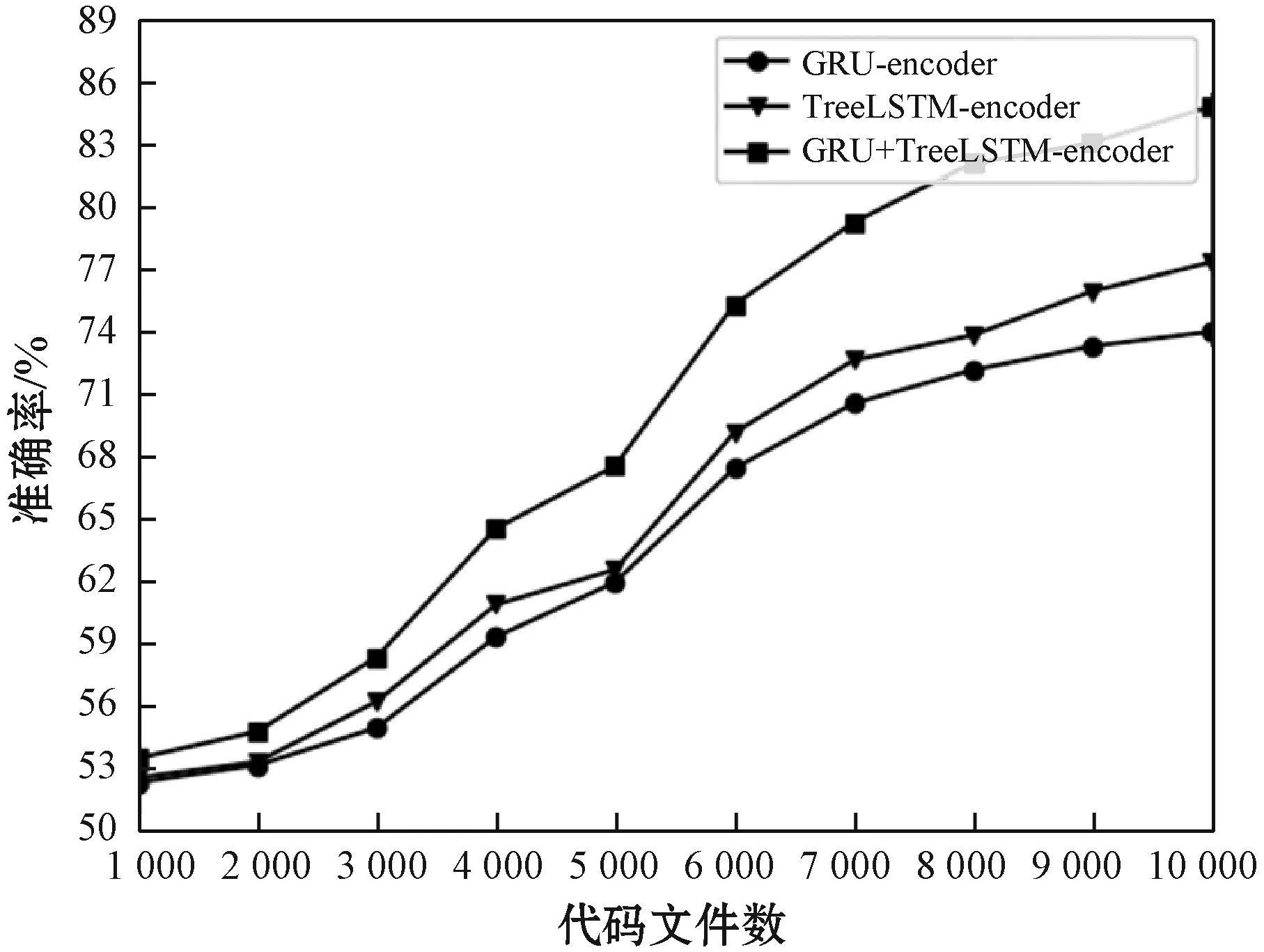
图5 结构树编码器模型(1 根据源程序的结构信息与程序语句构建对应的解析树,对应的抽象语法树序列为x=(x1,x2,…,xn),从所有叶子节点开始从底向上经过LSTM网络遍历至根节点,最终生成的向量用Vt表示。 TreeLSTM更新后的规则如式(1)-式(6)所示,其中C(j)表示抽象语法树中第j个节点的孩子节点集合。 (1) 遗忘: fjk=σ(Wf·xj+Uf·hk+bf) (2) 输入: (3) 输出: (4) 隐藏: ht=oj×tanh(cj) (5) 单元状态: (6) 式中:×表示矩阵元素相乘;xt是本时刻输入的字;Wf、Uf、Wi、Ui、Wo、Uo分别为各个门的权重矩阵;bf、bi、bo是偏置向量;σ是逻辑函数。 计算图如图6所示。 图6 TreeLSTM计算图 注释关键词提取[17-19]包含四步。 1) 对程序中所有注释进行提取:(1) 遇到“//”,(2) 遇到“/*”开始,遇到“*/”结束。 2) 对提取出的词进行关键词提取。本文采用基于机器学习的双向LSTM的分词方法提取关键词。对于分词任务来说,注释中每个词都是平权的,所以本文使用双向LSTM进行分词。LSTM接受相同的输入,但训练方向不同(从左向右做一次LSTM,然后从右向左做一次LSTM),并将它们的结果连接为输出。图7为训练模型。 图7 双向LSTM模型 结果举例如下: Print(cut_word)(‘内层循环控制一次排序次数’)结果:[‘内层’,‘循环’,‘控制’,‘一次’,‘排序’,‘次数’] 3) 利用Python对分词后的结果进行降重。 4) 将分词、降重之后的词整合成字典并进行编码,然后根据每个单词的编号生成其独有的one-hot向量。 字典是一种可变容器模型,可存储任意类型数据。整个字典包含在花括号“{}”中。 定义2字典格式为d={k1:v1,k2:v2,…},其中:k(key)为键,v(value)为值,且键是唯一的,而值不唯一。 解码器使用单向GRU作为注释生成模型。将两个编码器所得到的向量进行拼接,作为输入初值V0。 V0=[Vs,Vt] (7) 图8为单向GRU-decoder模型,在训练过程中,本文需要将误差反馈给前面的各层,即利用反向传播算法,通过对权重不断地修改来减小误差,从而实现对神经网络的训练,令Vm和Km形成相互映射的关系。 图8 单向GRU-decoder模型 为了有效评估模型,我们选用了来自www.Pudn.com联合开发网的高质量数据集,在此网站上约有116 059个实现不同功能的Java文件,且有准确的中文注释。程序数量足够大、注释足够精确是生成合理训练模型重要的一部分。利用爬虫技术收集11 577个Java编程和对应的注释作为数据集。我们将数据集划分为训练集和测试集,训练集包含10 000对源代码和注释,用于训练模型,测试集包含剩下的1 577对源代码和注释,用于评估模型的性能及注释生成效果[20]。 在此次研究中,使用Keras框架构建神经网络[21-23],程序主要在CPU显卡、Python3.68的编译环境下运行。进行充分的实验,在解码器部分对比了不同类型的循环单元:GRU和LSTM。 准确率和效率是评估本次研究中设计模型优劣的重要指标。 GRU是LSTM网络的一种非常有效的变体,在本次实验中,我们分别在三种模型下,查看自动注释的准确率和效率。表1、表2分别展示了当解码器为单向GRU单元、单向LSTM单元,且数据量为10 000个Java文件时三种模型的对比结果。 表1 利用GRU-decoder进行程序自动注释(%) 表2 利用LSTM-decoder进行程序自动注释(%) 可以看出,不管是准确率还是效率,GRU-decoder与LSTM-decoder得到的结果差异都较小,即GRU与LSTM网络效果近似,但效率方面GRU略微优胜于LSTM。 通过点线图可以更直观地观察实验效果。 如图9所示,在双编码器状态下,当数据量较小时,GRU-decoder和LSTM-decoder的效率比较接近,数据量增大后,稍微拉开一些差距,但是差距并不大。 图9 GRU/LSTM decoder效率对比图 图10为在GRU-decoder条件下三种编码器模型的准确率对比图,可以很明显看出利用双编码器对程序进行预处理之后的准确率更高。 图10 GRU-decoder条件下三种模型准确率对比图 本节通过表3展示一些测试集案例,进一步说明本文方法的可行性。 表3 测试集案例 本文结合编码器-解码器提出一种基于机器学习的LSTM-GRU程序自动标注研究方法。与既有技术相比,利用机器学习不仅提取源程序的序列特征,而且提取了重要的结构特征;注释关键词集为提取的中文词库,与以往的机器翻译有所区别。实验表明,本文方法可以较好地对Java程序进行自动中文标注,提高可读性,且训练数据集越多,准确率越高。下一步将考虑在TensorFlow框架下,通过结合其他神经网络或加入Attention机制对源程序进行处理,且扩大数据集来进一步提高准确率和效率;同时对其他程序语言进行测试,检测本文模型的适用范围。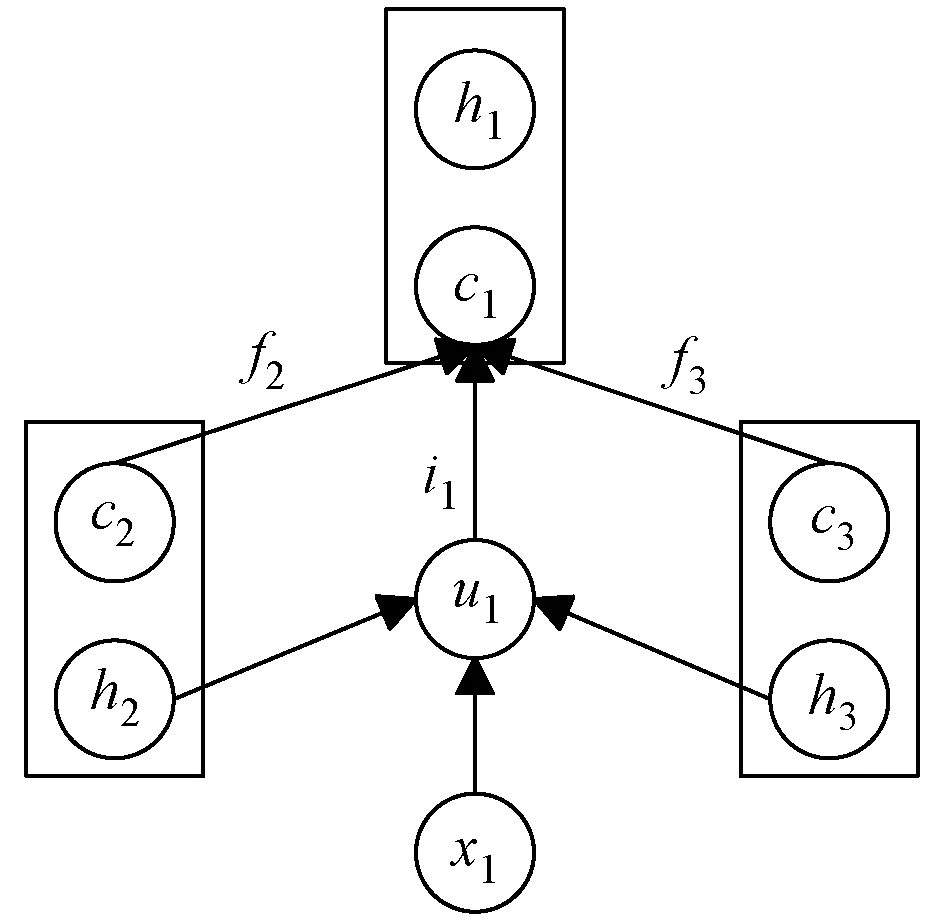
2.2 注释关键词提取

2.3 注释生成模型
3 实 验
3.1 数据集
3.2 实验设置
3.3 实验结果
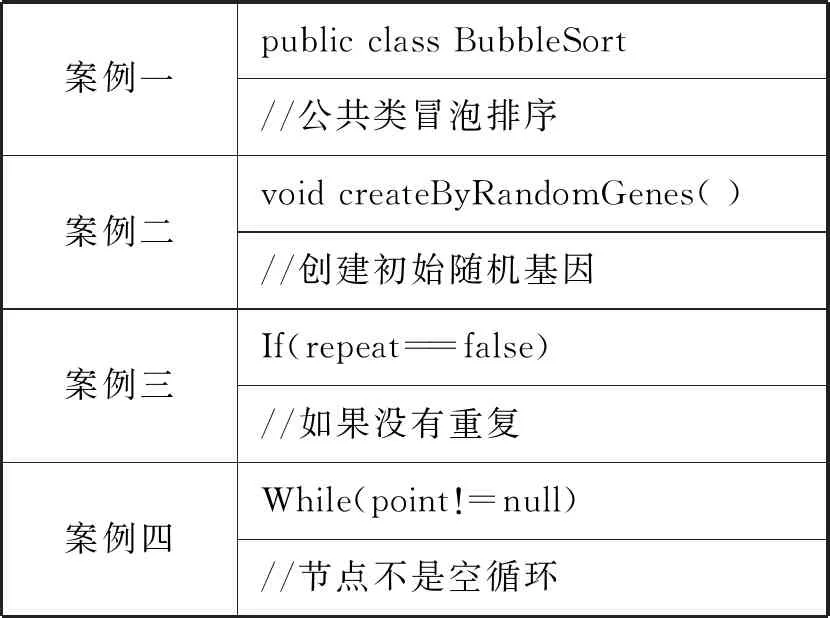
3.4 案例演示
4 结 语
