
基于Spark的证据邻域粗糙并行分类高效算法
2021-09-15 08:02丁卫平鞠恒荣秦廷桢黄嘉爽
南京理工大学学报 2021年4期
李 铭,丁卫平,鞠恒荣,孙 颖,秦廷桢,黄嘉爽
(南通大学 信息科学技术学院,江苏 南通 226019)
近年来,随着现代化信息技术的蓬勃发展,数据的指数式增长给传统的数据挖掘和分析技术带来了严峻挑战,也给各行各业的发展带来了宝贵机遇。大数据不同于传统数据,其具有潜在价值高和数据密度低等特点[1],大数据的挖掘为众多研究人员提供了许多宝贵的机遇。传统的大数据处理技术主要通过云计算平台[2]利用云计算、分布式计算以及并行计算将大规模数据切分成多个数据子集,降低数据规模,使其可计算,但无法删除数据中的冗余属性,减少数据间的不确定性。
粒计算逐渐发展成人工智能领域的一个新分支,它的核心思想是对信息和知识进行粒化、层次化,通过不同的粒度结构来处理问题。粗糙集理论[3]是主要的粒计算模型之一,它能够处理和分析决策过程中的不确定性信息。在粗糙集中,属性约简算法[4]是一个重要的概念,通过删除冗余数据和属性来减少数据的复杂性和不确定性。如何利用粗糙集理论从大规模数据中挖掘出巨大的潜在价值早已成为众多学者研究的课题之一。针对大规模数据的“5V”特性,梁吉业等[5]和Li等[6]详细地分析了粒计算模型处理大规模数据的可计算性、有效性和时效性。Qian等[7,8]通过深入研究MapReduce编程框架中的Map操作和Reduce操作,通过Map操作计算等价类,再通过Reduce操作对相同键值的等价类进行聚合,提出了基于MapReduce的并行知识约简算法。为解决大规模数据的实时性和不完备性问题,张钧波等[9]和Hamed等[10]基于不同的粗糙集扩展模型实现了基于MapReduce的并行近似计算和并行属性约简算法。在上述研究中,众多研究人员解决了经典粗糙集模型无法处理大规模数据集的局限性问题,同时也利用粗糙集属性约简算法删除大规模数据中的冗余属性并提高计算效率。但是,上述研究并没有解决经典粗糙集无法直接处理数值型数据以及Hadoop MapReduce在读写过程中产生多余损耗和迭代计算性能差等问题。
为了避免数据离散化过程中造成部分信息丢失,Hu等[11]基于邻域关系提出了邻域粗糙集模型,它能够直接处理数值型数据。在邻域粗糙集模型中,可以根据不同的邻域半径得到不同的邻域空间样本,从不同的粒度来刻画整体样本空间。
基于邻域粗糙集模型,Hu等[12]提出了邻域分类器。不同于传统的K邻近(K-nearest neighbor,KNN)模型中选取最近的k个样本,邻域分类器是在某个邻域半径下通过未分类样本的邻域空间内所有样本来近似刻画此样本。邻域分类器因其良好的分类性能在分类问题中得到广泛应用。然而,邻域分类器在决策过程中采用的是多数投票机制,根据未分类样本邻域空间中数据对象的类别标签进行预测。多数投票机制没有考虑到邻域样本之间的空间差异性[13]和邻域样本标签的不确定性[14,15]。为解决多数投票机制的两个不足之处,Denoeux[14]将其提出的D-S证据理论应用到KNN分类器中,利用所有邻域空间样本的融合证据支持信息预测样本标签,提高了分类精度;Zhang等[15]将D-S证据理论引入KNN分类器后,再将其与集成学习机制结合,提出了D-S驱动的KNN集成分类器。目前,将D-S证据理论用于融合粗糙集理论决策过程中证据支持信息的研究较少。
相较于Hadoop MapReduce,Spark是基于内存的类Hadoop MapReduce分布式计算框架。Spark框架会将中间数据存储到内存中,不会因多次读写而产生多余的损耗。同时,Spark的迭代计算的性能远优于Hadoop MapReduce。Chelly等[16]针对大规模数据预处理,基于Spark框架提出了分布式粗糙集扩展模型,在Spark计算过程中将数据缓存于内存中减少了不必要的时间损耗;Zhou等[17]分别介绍了基于MapReduce和Spark的粗糙集扩展模型研究现状,并分析两种扩展模型之间的差异性。然而,大规模数据中不仅存在名义型数据,还存在数值型数据。上述研究中,大多数的粗糙集并行扩展模型只适用于名义型数据,无法直接处理大规模数值型数据。
基于以上讨论,本文提出基于Spark的证据邻域粗糙并行分类高效算法(Efficient algorithm of evidences neighborhood rough parallel classification based on spark framework,SENRPC)。此算法主要分为两部分:首先针对大规模数值型数据,本文实现了基于Spark的邻域决策错误率并行属性约简算法,删除数据中的冗余属性并减少数据间的不确定性;然后针对多数投票机制的不足之处,本文实现了基于Spark的邻域证据并行分类算法,能够并行融合邻域中类内样本和类间样本的证据支持信息,提高对未分类样本的分类准确率。
本文主要工作如下:
(1)为了解决Hadoop MapReduce框架存在多余的时间损耗和迭代性能差的问题,本文基于Spark框架实现了并行属性约简算法和并行分类算法;
(2)为了解决经典粗糙集模型无法处理数值型数据的问题,本文在Spark框架下引入基于邻域决策错误率的邻域粗糙集模型,并通过并行属性约简算法去除冗余属性;
(3)为了解决多数投票机制没有考虑到邻域样本之间的空间差异性和标签的不确定性的问题,本文在Spark框架下引入D-S证据理论并行融合分类决策过程中的证据支持信息,提高了模型分类精度。
为更好地体现本文算法的有效性,本文通过不平衡数据[18]实验来评估算法的分类性能。
1 基础知识
1.1 邻域粗糙集
Lin等[19]根据距离度量将样本空间中不同的样本划分成多个模糊信息粒簇,提出了模糊邻域系统,并将邻域系统引入粗糙集模型中提出了邻域粗糙集的原始模型。Hu等[11]从数值空间邻域粒化的角度重新定义和诠释了邻域粗糙集模型。
δB(xi)={xj|xj∈U,disB(xi,xj)}
(1)

(2)
(3)
定义3[11]在决策信息系统S=〈U,C∪D,V,f〉中,有B⊆C,那么决策属性D相对于条件属性子集B的依赖度定义如下
(4)
式中:|·|表示集合中的元素个数。
考虑到依赖性度量主要是根据正域来评估信息表的一致性,忽略了边界域中模糊信息对决策过程的影响。Hu等[11]认为并非所有落入边界域的样本都会存在误分类情况,只有少数样本不能被识别,并针对依赖性度量无法反映出边界域样本分类的真实情况,提出了邻域决策错误率用于评估属性子集的性能。
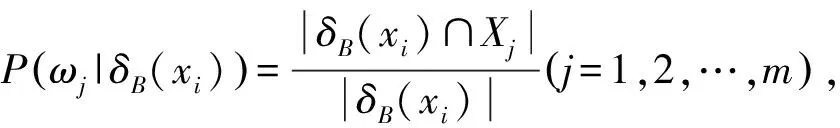
(5)
可得邻域决策错误率(Neighborhood decision error rate,NDER)的定义如下
(6)
式中:M表示样本数。
1.2 D-S证据理论
D-S证据理论[14]是基于信任函数的证据融合理论,是概率论中贝叶斯理论的扩展。在传统的贝叶斯概率理论中,一个问题的答案是所有可能答案中可能性最大的答案;而在D-S证据理论中,一个问题的答案是所有可能答案对问题支持信息融合得到的最终答案。
定义5[14]在辨识框架Ω下,可将样本空间划分成多个子集集合Ω={X1,X2,…,Xd},其中任意子集Xs对应于一个数M∈[0,1],可称M为幂集2Ω在区间[0,1]上的基本概率分配函数,并且此函数满足
M(φ)=0
(7)
(8)
式中:不可能事件的基本概率置信度为0,M({Xs})为Xs的基本概率函数。
若对于任意的Xs⊆Ω且M({Xs})>0,则可称A为M的一个焦元,即对Xs的支持信任度量。
定义6[14]由基本概率分配函数可知,信任函数Bel和似然函数Pl的定义如下
(9)
(10)
式中:Bel({Xs})为Xs中全部子集基本置信度之和,Pl({Xs})为对Xs的非否信任度,即对Xs似乎可能成立的不确定性度量。
1.3 Spark框架
Spark是基于内存存储的大规模快速并行计算框架。相较于Hadoop MapReduce而言,Spark具有计算速度快、易用性好和通用性高等特点[20]。Spark框架在计算过程将中间数据存储到内存中,当内存溢出时,可将数据存储到磁盘上。Spark框架在Map和Reduce算子的基础上,衍生出转换和行动两类弹性分布式数据集(Resilient distributed dataset,RDD)算子,并提供4种编程语言的API。同时,众多开发者基于Spark框架推出了Spark SQL、Spark Streaming、MLLib和GraphX等一系列组件[21],形成了一个大规模数据处理的云计算平台。
Spark任务执行过程主要分为两个阶段[20,21]:第一个阶段从Hadoop分布式文件系统(Hadoop distributed file system,HDFS)上读取数据生成RDD对象,并根据RDD之间的依赖关系构建有向无环图(Directed acyclic graph,DAG),将不同的RDD算子操作划分成不同的任务;第二阶段通过集群管理器将不同的任务分配给不同的子节点执行。Spark任务运行流程如图1所示。
行常规西药治疗,即:①选用剂量为0.5 g的多索茶喊和250 mL的9%生理盐水进行静滴治疗(1次/d);②除了使用多索茶喊外还可以服用布地奈德(0.1 mg/次,2次/d)。
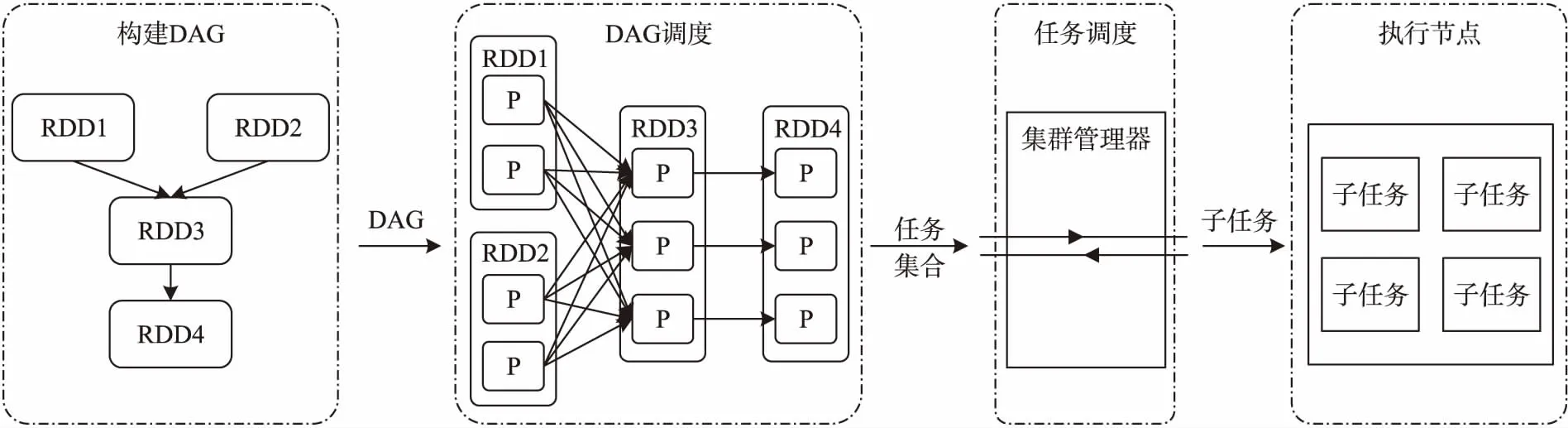
图1 Spark任务运行流程图
2 基于Spark的证据邻域粗糙并行分类高效算法
基于以上讨论,为解决上述不足之处,本文提出了基于Spark的证据邻域粗糙并行分类高效算法。此算法在Spark框架下分别实现了并行属性约简算法和并行分类算法,提高了模型的计算效率和分类精度。
如图2所示,SENRPC算法数据处理的过程如下:
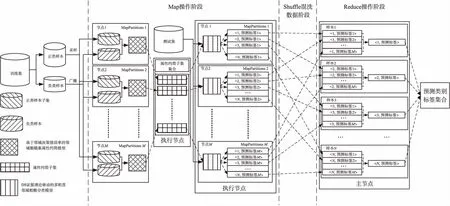
图2 基于Spark的证据邻域粗糙并行分类高效算法的数据处理过程
(1)将数据集划分成训练集和测试集,对训练集进行并行欠采样降低训练集的不平衡率,并得到多个训练子集;
(2)在子节点上对于相应的训练子集,基于邻域决策错误率评估出每个条件属性的属性重要度,并且根据属性约简的停止准则得到满足条件的属性约简子集;
(3)根据属性约简子集集合对训练子集集合和测试集进行更新,分别形成新的数据集,在子节点上利用D-S证据理论驱动的邻域分类器对测数据集进行分类,将得到的预测类别标签集合发送到主节点上,然后根据多数投票机制得到最大概率的类别标签。
2.1 不平衡数据的并行随机欠采样预处理
本文通过基于Spark的并行欠采样算法来降低数据的不平衡率(Imbalance rate,IR)和扩充数据集规模。首先,从正类样本数据中随机并行抽取与负类样本相同规模的数据;然后,将其与负类样本数据重构,生成多个新的数据子集。
定义7对于一个决策信息表S=〈U,C∪D,V,f〉,其中U={x1,x2,…,xM},假设正类样本集合UP={y1,y2,…,yP},负类样本集合UN={z1,z2,…,zN},且P+N=M。通过并行欠采样得到新的决策信息子表集合{S1,S2,…,Sm}的定义如下
Si=〈Ui,C∪D,V,f〉
(11)
基于如上讨论,本文设计如下算法1:不平衡数据的并行随机欠采样处理(Imbalance data parallelize random undersampling,IDPRUS),降低数据集的不平衡率,同时通过并行机制对数据集进行重构和扩充,扩大数据集规模。

算法1不平衡数据的并行欠采样IDPRUS算法
输入:决策信息表S=〈U,C∪D,V,f〉;
输出:决策信息子表集合{S1,S2,…,Sm};
1: 在主节点上,从本地读取数据集,创建SparkSession对象,并将数据类型转换成Dataframe类型;
2: 根据类别标签筛选出正类样本集UP和负类样本集UN;
3: 对于所有的子节点slavei(i∈{1,2,…,m});
4: 将UN广播到所有子节点上;
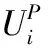
7: 返回新的决策信息子表集合{S1,S2,…,Sm}。
2.2 基于Spark的邻域决策错误率并行属性约简
为解决Hadoop MapReduce框架的不足之处,本文在MapReduce框架的基础上利用Spark开发平台实现了可编译性和易用性更高的并行属性约简算法。本文率先引入基于邻域决策错误率的属性约简算法,并实现了基于Spark的邻域决策错误率并行属性约简,筛选出不同数据子集中的冗余属性,降低数据规模和计算时间,提高计算效率。
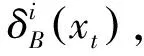
(12)

(13)
式中:2N表示决策信息子表Si中的样本数。
定义10[11]在决策信息子表Si中,有Ri⊆C,若Ri为Si基于邻域决策错误率的属性约简子集,则Ri需要满足:
(1)NDERiRi≤NDERiC;
根据上述属性约简过程,对候选属性的属性重要度定义如下。
SIG(a,Ri,D)=NDERiRi(D)-NDERiRi∪{a}(D)
(14)
基于以上定义,本文设计如下算法2:基于Spark的邻域决策错误率并行属性约简(Neighborhood decision error rate parallelize attribute reduction based on spark,NDER-PARS)算法。算法2首先将决策信息子表集合{S1,S2,…,Si,…,Sm}发送到相应的子节点slavei上;然后计算决策信息子表Si中每个条件属性的属性重要度,将属性重要度值最大的条件属性添加到属性约简子集Ri中;然后计算属性约简子集Ri的邻域决策错误率,直到满足NDERiRi≤NDERiC;最后,输出属性约简子集集合{R1,R2,…,Rm}。
算法2基于Spark的邻域决策错误率并行属性约简(NDER-PARS)算法
输入:决策信息子表集合{S1,S2,…,Sm},邻域半径δ;
输出:属性约简子集集合{R1,R2,…,Rm};
1: ∅→{R1,R2,…,Rm};
2: 对于所有子节点slavei上的决策信息子表Si(i=1,2,…,m);
4: 选取最大属性重要度及其对应的属性ak;
5: 如果候选属性ak的属性重要度SIG(ak,Ri,D)大于0,那么
6: 将属性ak添加到属性约简子集Ri中;

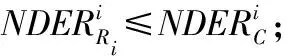
9: 得到属性约简子集Ri;
10:输出属性约简子集集合{R1,R2,…,Rm}。

2.3 基于Spark的邻域证据并行分类算法
在属性约简子集集合{R1,R2,…,Rm}上,对决策信息子表集合{S1,S2,…,Sm}进行更新,得到新的决策信息子表集合{S′1,S′2,…,S′m},其中S′i=〈Ui,Ri∪D,Va,f〉。
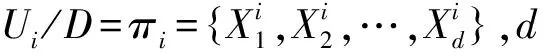
(15)
Mt,j(πi)=1-β
(16)
式中:0<β0<1,γq>0。

(dis(xt,xj))2})
(17)
(dis(xt,xj))2})
(18)
q=1,2,…,d
(19)
(20)
式中:K为归一化因子,其定义如下[14]
(21)
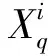
(22)
(23)
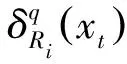
(24)
在决策信息子表集合{S′1,S′2,…,S′m}中,可得未分类样本xt的预测类别标签集合为{ω1t,ω2t,…,ωmt}。根据投票策略,可得未分类样本xt在决策信息表S下的预测类别标签定义如下
(25)

基于以上讨论,本文设计如下算法3:基于Spark的邻域证据并行分类(Parallelize neighbor-hood D-S evidence classifiers based on spark,PNDSCS)算法。在邻域粗糙并行分类算法的决策过程中,并行融合整个邻域空间内的证据支持信息。本文在不同属性约简子集上从多个粒度结构并行计算邻域中类内样本和类间样本之间的证据支持信息。该算法在分类决策过程中充分地考虑了邻域样本数据分布的紧密性,提高了分类过程的计算效率和分类准确度。
算法3基于Spark的邻域证据并行分类(PNDSCS)算法
输入:决策信息表S=〈U,C∪D,Va,f〉,邻域半径δ,未分类样本xt;
输出:xt的预测类别标签ωt;
1: 根据算法1进行不平衡数据并行随机欠采样处理,得到决策信息子表集合{S1,S2,…,Sm};
2: 根据算法2进行并行属性约简,得到属性约简子集集合{R1,R2,…,Rm};
3: 对于所有的子节点slavei上的决策信息子表Si进行更新得到新的决策信息子表S′i(i=1,2,…,m);
4: 计算决策类划分πi和待测样本xt的邻域空间δRi(xt);
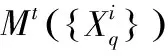
7: 根据式(24)计算在决策信息子表S′i下的预测类别标签ωti,并发送到主节点master上;
8: 在主节点master上得到未分类样本xt在决策信息子表集合{S1,S2,…,Sm}下的预测类别标签集合{ω1t,ω2t,…,ωmt};
9: 在主节点上根据式(25)进行聚合操作得到未分类样本xt的最终预测类别标签ωt;
10:输出未分类样本xt的预测类别标签ωt。
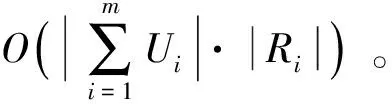
3 实验和结果分析
本文通过6组UCI不平衡数据的分类实验,检验了SENRPC算法的性能。本文采用的实验平台为PC(Intel(R)Core(TM)i7-10875H CPU@2.30 GHz,RAM 16 GB),Windows10家庭中文版操作系统,开发工具为JetBrains PyCharm,使用Python语言实现实验中相关算法。本文在Windows10系统上搭建MapReduce Hadoop-2.7.1和Spark-3.0.0-preview的模拟环境平台,集群运行模式采用本地模式“local”。
3.1 实验数据集
本文从UCI机器学习数据库中选择了6个不平衡数据集,相关统计信息如表1所示。

表1 数据集描述
本文利用留出法(hold-out)按照4∶1的比例将原始数据集切分为训练集和测试集。通过算法1降低数据的IR为1,并利用Spark的并行计算机制将数据规模扩充为15个数据子集。经过预处理后的数据集相关统计信息如表2所示。
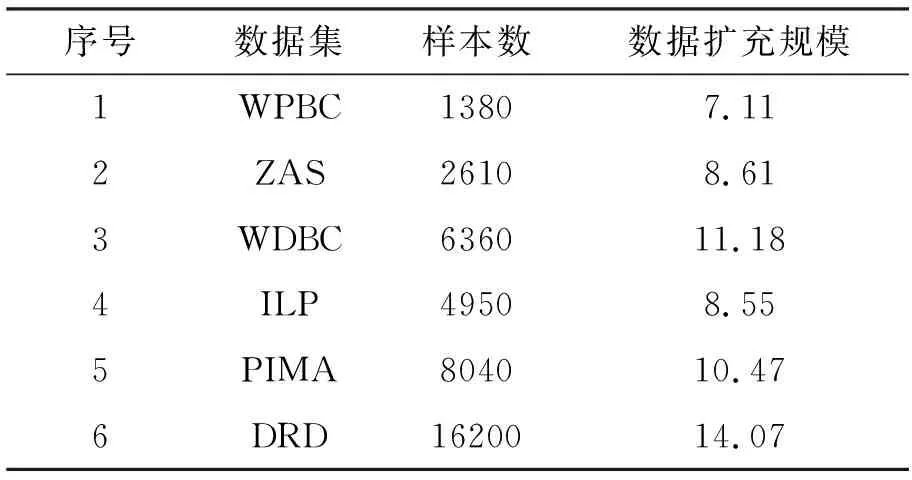
表2 经过预处理后的数据集描述
3.2 实验评估指标
在分类问题中,最常用的评价指标为准确度(Accuracy),但是该指标无法反映出分类模型对不平衡数据中负类数据的学习能力。本文在混淆矩阵的基础上采用查准度(Precision)、特异度(Specificity)和G-均值(G-mean)指标评估分类器对不平衡数据中正类数据和负类数据的学习能力,同时根据实验的运行时间俩评估算法的计算性能。
查准率的计算公式定义为
(26)
特异度的计算公式定义为
(27)
G均值的计算公式定义为
(28)
式(26~28)中:TP是真正例,TN是真反例,FP是假正例,FN是假反例。
3.3 实验结果与分析
为了检验SENRPC算法在计算时间和分类方面的性能,本文基于6组UCI不平衡数据进行了计算时间和分类性能方面的对比实验,实验中对比算法选取邻域分类算法(Neighborhood classifier,NEC)[12]、证据邻域分类算法(Evidence neighborhood classifier,ENEC)[14]、Spark框架下的邻域并行分类算法(Parallel neighborhood classifier based on spark,SPNEC)。表3给出在相同数据规模下4种算法的计算时间值。
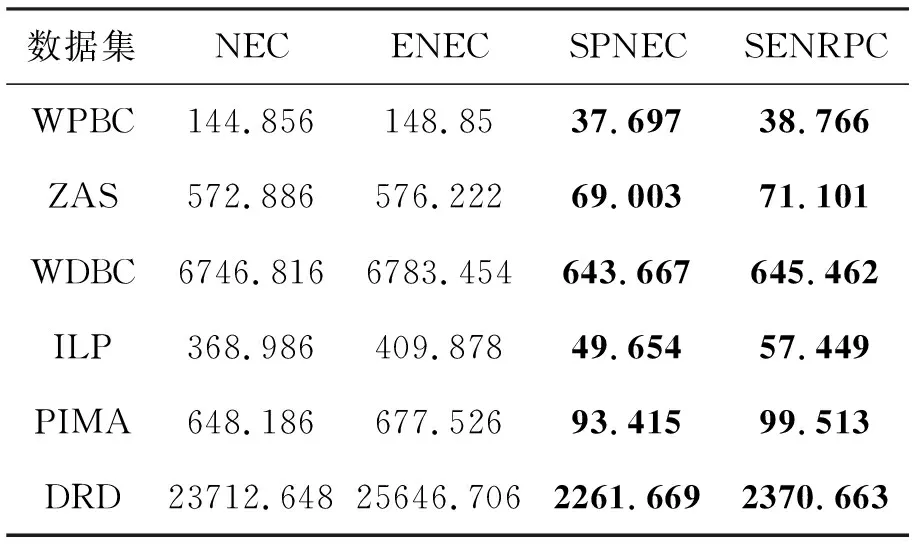
表3 计算时间 s
从表3可以看出,基于Spark框架的SPNEC和SENRPC两种算法的计算时间远小于另外两种传统算法NEC和ENEC,而且在一定范围内随着数据规模的增大,减少的计算时间也越大。这表明通过Spark并行计算机制可以有效地提高NEC和ENEC两种算法的计算效率,减少其计算时间。因为ENEC算法在分类过程中需要计算邻域样本之间的融合证据支持信息,所以其计算时间会比NEC算法多一些。同时,SENRPC算法并行融合邻域空间内的证据支持信息的时间少于ENEC算法,这表明SENRPC算法减少了计算证据支持信息的时间。
从图3和图4可以看出,在大部分数据集上,SENRPC算法的查准率和特异度指标性能远优于传统的NEC和ENEC两种算法,Precision值基本在80%以上且最终趋向于稳定,Specificity值基本在60%以上且最终趋向于稳定。这表明了SENRPC算法加强了模型对负类样本的学习能力,提高了模型对负类样本的分类性能。
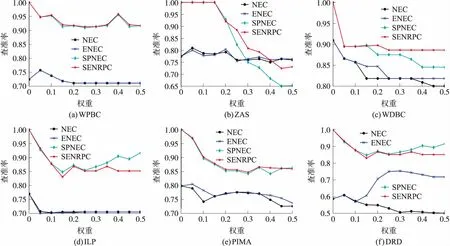
图3 分类查准率比较
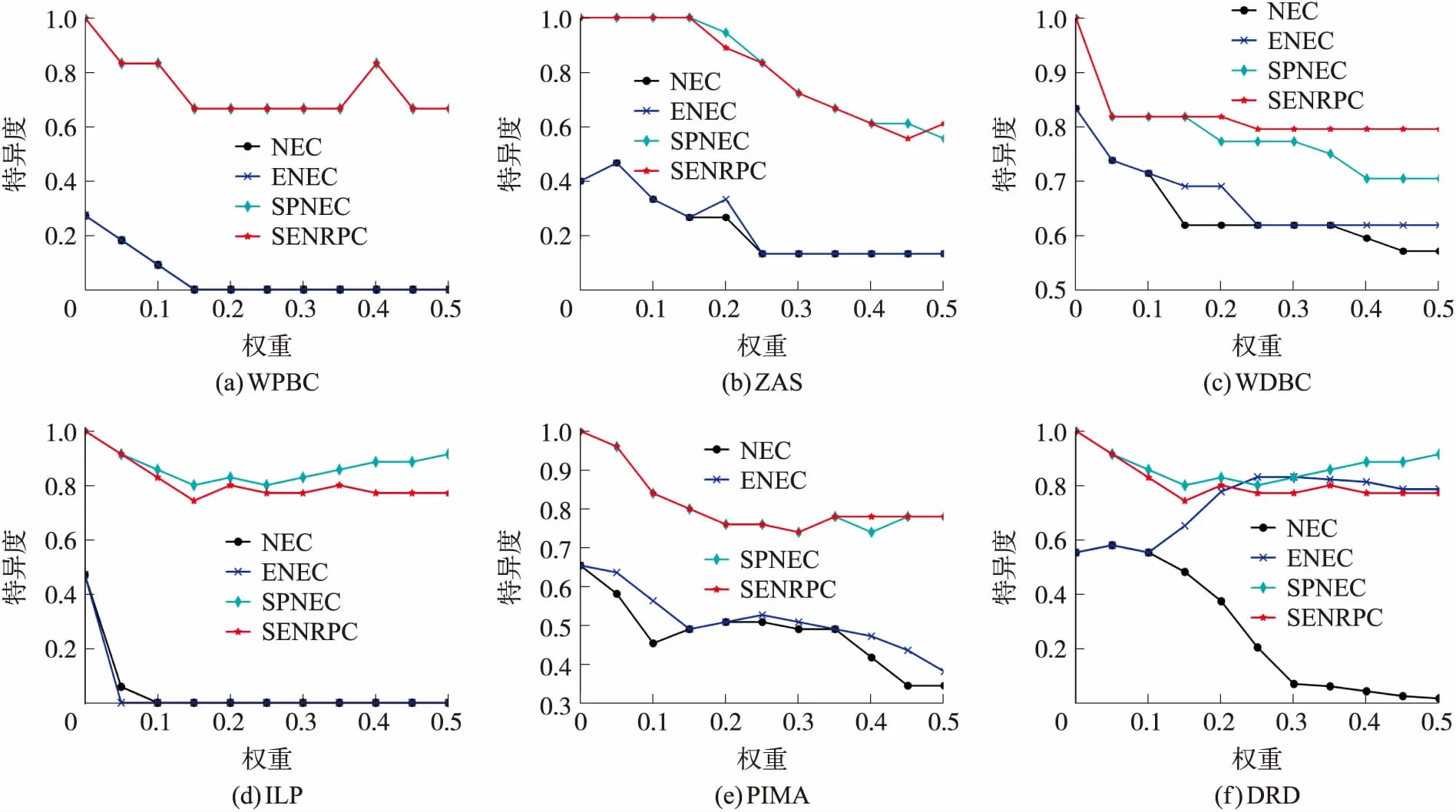
图4 分类特异度比较
从图4可以看出,在WPBC和ILP这两个数据集上,传统的两种算法NEC和ENEC的特异度性能随着邻域半径的增大最终趋向于0,这表明NEC和ENEC两种算法对负类样本的学习能力减弱,无法对负类样本准确分类;在DRD数据集上,随着邻域半径的增大,邻域空间内的正类样本增多,NEC算法的分类精度降低,而ENEC算法的分类精度不断提高并趋向于稳定。
从图5可以看出,针对大部分数据集SENRPC算法在G-均值指标上的性能远优于其余的3种算法,G-mean值基本在60%以上且最终趋向于稳定。这表明SENRPC算法对于数据样本中正、负类样本的综合分类性能是4种算法中最优。
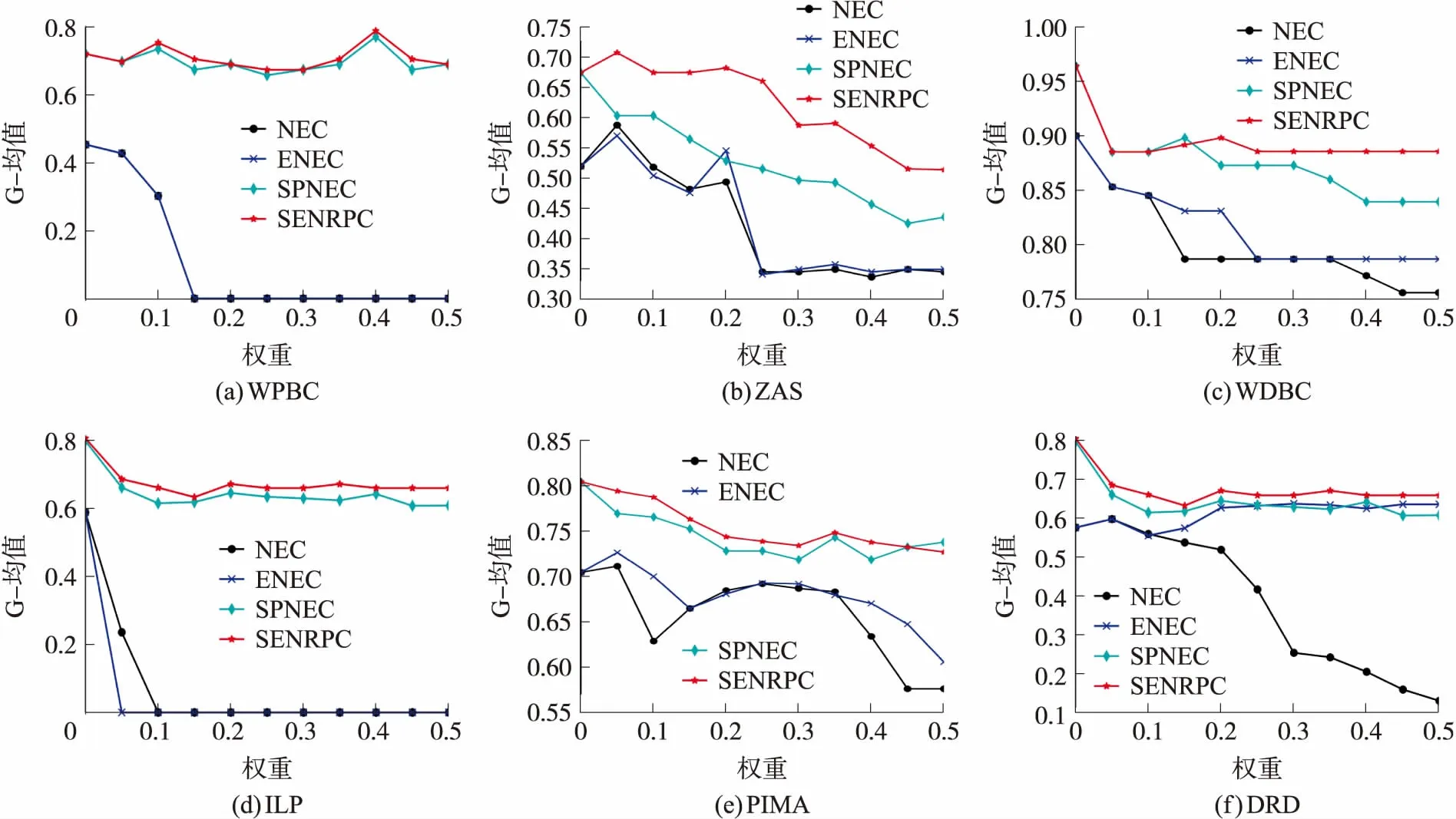
图5 分类G均值比较
综上可知,本文SENRPC算法可以删除大规模数据中的冗余属性,降低数据规模和计算时间,提高计算效率。同时,本文SENRPC算法对不平衡数据的分类性能良好,可以提高模型对不平衡数据整体分布的学习能力和分类性能。
4 结束语
本文首先针对大规模数值型数据,将Spark并行计算机制与基于邻域决策错误率的属性约简算法进行结合,实现了并行邻域属性约简算法,降低属性约简的计算时间。然后,针对多数投票机制的不足之处,将证据理论引入邻域分类器,实现了基于Spark的邻域证据并行分类算法并行融合决策过程中的证据支持信息。最后,在主节点上通过Reduce操作聚合所有子节点的预测类别标签得到最终的预测类别标签。本文提出的SENRPC算法能够删除大规模数据中的冗余属性,降低数据规模,减少数据之间的不确定性;在分类过程中,并行融合邻域空间中类内样本和类间样本之间的证据支持信息,得到更精确的分类结果。但是,在部分数据集上,现有的D-S证据理论组合方式对分类精度提升不多,如何通过更好的D-S证据理论组合方式融合整个邻域空间的证据支持信息提高模型的分类精度是本文接下来需要深入研究的问题。
猜你喜欢
农业工程学报(2022年7期)2022-07-09
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
逻辑学研究(2021年3期)2021-09-29
波谱学杂志(2021年3期)2021-09-07
南京大学学报(数学半年刊)(2020年1期)2020-03-19
小型微型计算机系统(2019年10期)2019-11-11
小型微型计算机系统(2019年9期)2019-09-09
计算机与生活(2019年3期)2019-04-18
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
都市丽人(2015年4期)2015-03-20
