
基于机器学习算法的干眼预测模型研究
2021-09-15 03:24苏佳山程冬梅
国际眼科杂志 2021年9期
张 弛,王 萍,苏佳山,程冬梅
0引言
干眼是指由泪液的量或质或流体动力学异常引起的泪膜不稳定和(或)眼表损害,从而导致眼部不适症状及视功能障碍的一类疾病。其发病率非常高,根据流行病学调查结果显示,世界范围内干眼的发病率约为 5.5%~33.7%[1-2],其中我国发病率约为21%~30%,干眼患者有眼部干涩、异物感、烧灼感、视疲劳、视力波动等不适,严重者可导致眼表,尤其是角膜组织干燥、角化或融解、穿孔,造成角膜盲。因此干眼的正确有效诊断尤为重要[3]。干眼症状无特异性,临床上诊断干眼,除了临床症状外,还需要结合各种眼表检查的客观参数综合判断,如泪液分泌试验(Schirmer Ⅰ test,SⅠt)、荧光素染色泪膜破裂时间(FBUT)、非接触式泪膜破裂时间(NI-BUT)、泪河高度(TMH)、角膜荧光素钠染色(FL)评分、睑板腺功能评分(MG-SCORE)等[4]。但这些单个指标的临床意义有限,哪些指标对干眼的诊断更有参考价值,它们之间的联系又是什么,目前未见相关报道。
数据挖掘是生物信息学的重要内容之一,可以将获得的零散数据转换成便于读写输出的信息,再进一步用多种数学工具进行分析建模,从而找出这些数据的联系和规律,为临床诊断、治疗提供帮助和参考[5]。本研究拟运用数据挖掘技术,分析正常人和干眼患者各眼部检查参数,寻找诊断干眼的相关性指标,建立干眼预测模型。
1对象和方法
1.1对象选取2020-03/2021-01于我院确诊的干眼患者218例436眼纳入干眼组,其中男101例202眼,女117例234眼,年龄20~70(平均41.32±5.13)岁。纳入标准:(1)符合干眼诊断标准,根据《中国干眼临床诊疗专家共识》(2020)中干眼的诊断标准[6]:1)有下列主观症状之一:干燥感、异物感、烧灼感、视疲劳、畏光、疼痛、流泪、视力波动、眼红;2)眼表疾病指数(OSDI)问卷评分≥13分;3)NI-BUT≤10s 或SⅠt≤10mm/5min;(2)年龄18~72岁。排除标准:(1)继发于系统性红斑狼疮(SLE)、类风湿性关节炎(RA)和系统性硬化症(SSc)等干眼患者;(2)既往有眼部过敏、手术、配戴角膜接触镜、角结膜感染性疾病等病史。选取同期在我院进行健康体检的健康人群212例424眼纳入正常对照组,其中男113例226眼,女99例198眼,年龄18~72(平均43.19±6.22)岁。纳入标准:(1)无干眼症状和体征;(2)年龄18~72岁。排除既往有眼部过敏、手术、配戴角膜接触镜、角结膜感染性疾病等病史者。本研究经医院伦理委员会审批通过,所有研究对象均知情同意。
1.2方法
1.2.1检测指标
1.2.1.1OSDI问卷评分采用OSDI问卷进行干眼主观症状评分,问卷内容包含眼部症状(眼干、灼热感、异物感、眼痛、畏光和视力波动等)、视觉相关功能、环境因素。由12个问题组成,每个问题评分0~4分,0分为无症状,1分为有时侯有症状,2分为一半时间有症状,3分为绝大多数时间有症状,4分为总有明显症状。OSDI评分=(25×总得分数)/回答问题数,总分0~100分。
1.2.1.2SⅠt 无麻醉条件下使用Schirmer试纸(5mm×30mm),头端内折置入受检者下眼睑外中1/3交界处的结膜囊,嘱受检者轻闭眼5min后,测量5min内泪液浸湿试纸的长度。
1.2.1.3FBUT 用荧光素钠试纸触及下睑结膜囊,嘱受检者瞬目3~4次使荧光素涂布于眼表,双眼平视前方,从末次瞬目至角膜出现首个黑斑的时间为泪膜破裂时间。测量3次,取平均值。
1.2.1.4NI-BUT 暗室环境下,受检者双眼自然睁开,使用Keratograph 5M中Placido盘投影至受检者角膜的表面并对焦,注视中心红点,再嘱其充分瞬目3次后尽可能保持睁眼,自动记录泪膜破裂时间。测量3次,取平均值。
1.2.1.5TMH 暗室环境下,受检者在测试前充分瞬目3次,采用Keratograph 5M拍照记录泪河高度图像。测量3次,取平均值。
1.2.1.6FL评分用荧光素钠试纸触及受检者下睑结膜囊,将角膜划分为4个象限,在裂隙灯钴蓝光下观察角膜染色情况。角膜染色在每个象限的评分为0~3分:0分为无染色;1分为小于30个染色点;2分为大于30个点但未融合成片;3分为出现融合或出现丝状物及溃疡。4个象限的得分相加为每眼的总评分,共0~12分。
1.2.1.7MG-SCORE 通过Keratograph 5M睑板腺成像技术对睑板腺结构进行评估,每只眼的上下睑分别进行评分记录,评分标准:0分:睑板腺无缺失;1分:睑板腺缺失比例<1/3;2分:睑板腺缺失比例为1/3~2/3;3分:睑板腺缺失比例>2/3。
1.2.2预测模型的构建和验证方法不同的机器学习算法适合于不同的数据集,本研究分别使用Random Tree、KNN、Decision Stump、Random Forest、SVM、Naïve Bayes、C4.5决策树等机器学习算法构建干眼预测模型,通过5组交叉验证结果评估该模型的预测能力,并采用受试者工作特征曲线(receiver operating characteristic curve,ROC)及曲线下面积(area under curve,AUC)评估各算法的预测能力。在5组交叉验证中,将数据集分成5个子集,其中4个子集作为训练集用于建模,1个子集作为测试集检验模型,共进行5次计算,得到5个值,取平均值即5组交叉验证的结果。具体流程如下:(1)收集数据,构建用于建模的数据集;(2)对训练集进行特征筛选,去除冗余的变量,建立特征子集;(3)使用机器学习算法对训练集进行模型构建;(4)对建立的模型进行评估;(5)使用独立测试集对模型的预测能力进行验证。本研究所有的机器学习计算均在Linux系统下采用开源软件WEKA进行。
1.2.2.1数据库构建分别从干眼组和正常对照组各随机选取100例200眼受检者的数据组成测试集,其余干眼组118例236眼、对照组112例224眼受检者的数据作为训练集。

1.2.2.3机器学习算法
1.2.2.3.1C4.5决策树决策树是一种用来表示判定规则的树结构。通过对训练样本集训练,可以构造出一棵可表达一定规则的决策树,该树对样本空间进行了划分。当使用决策树对未知样本预测时,该算法利用已生成的树,从根结点开始对样本的属性测试其值,并顺着分枝向下移动,直至达到某个叶结点为止。此叶结点代表的类即为该样本的分类结果[7]。
1.2.2.3.2KNN KNN即K-最近邻(K nearest neighbors),适用于分类和回归的非参数方法。特征空间中的K个最接近的训练样例(即样本点)作为输入,输出值有2种情况,当N=1时,输出对象是简单的最近邻样本点;而当它存在K个值(N≠1时),输出值是K个最近邻的平均值[8]。
1.2.2.3.3RandomTree 基本思路:设属性集{X=F1,…,Fk,D}为建造树型提供大体结构,其中包括非决策属性Fi(i=1,2,…,k)和决策属性D(d1,d2,…,dm)。Fi(x)表示x的属性Fi值[9]。
1.2.2.3.4NaïveBayes Naïve Bayes即朴素贝叶斯算法,是无监督学习的一种常用算法,通过联合概率[P(x,y)=P(x|y)P(y)]建模,运用贝叶斯定理求解后验概率[P(y|x)],将后验概率最大者对应的类别作为预测类别[10]。
1.2.2.3.5Bagging Bagging是最常用和最实用的集成学习算法之一,旨在结合许多弱分类器获得强分类器,通过建立许多独立的训练数据集生成一些独立的分类器,然后将它们组合起来,以多数投票构建最终的分类器[11]。
1.2.2.3.6SVM SVM即支持向量机(support vector machine),是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面[12]。
1.2.2.3.7DecisionStump Decision Stump也称单层决策树。该算法可对每一列属性进行一次判断,由一个内部节点(根节点)与末端节点(叶节点)直接相连,叶子节点即最终的分类结果[13]。
1.2.2.3.8RandomForest Random Forest即随机森林(RF),该方法结合Bagging和随机选择的特征被独立引入,以构建具有可控变化的决策树集合[14]。
2结果
2.1特征筛选采用CFS方法从全体数据中筛选出特征子集,该子集包含4个变量,即SⅠt、NI-BUT、TMH、FL评分。
2.2预测模型的构建和验证采用Random Forest算法进行建模时,模型的预测准确率高于其他算法,干眼组和正常对照组的预测准确率分别为91.8%和85.2%,总预测准确率为88.5%,见表1。模型的验证结果显示,Random Forest算法的ROC曲线和AUC面积均优于其它算法,见图1、2。尽管Random Tree和Random Forest算法的干眼预测准确率最高,但与其他算法相比较,各个算法之间的总预测准确率相差并不是十分大,说明选取的这些算法具有可行性。由于部分机器学习方法的参数可能对模型的预测准确率有一定的影响,因此本研究对Random Forest算法的参数进行了优化,结果显示,当模型参数numTrees为9时,正常对照组、干眼组和总预测准确率均大于90%,优于其它参数,见图3,故选择该参数条件建立最终的干眼预测模型。采用测试集对该模型的预测准确率进行评估,结果显示,测试集中正常对照组、干眼组和总预测准确率分别为91.7%、97.6%和94.6%。
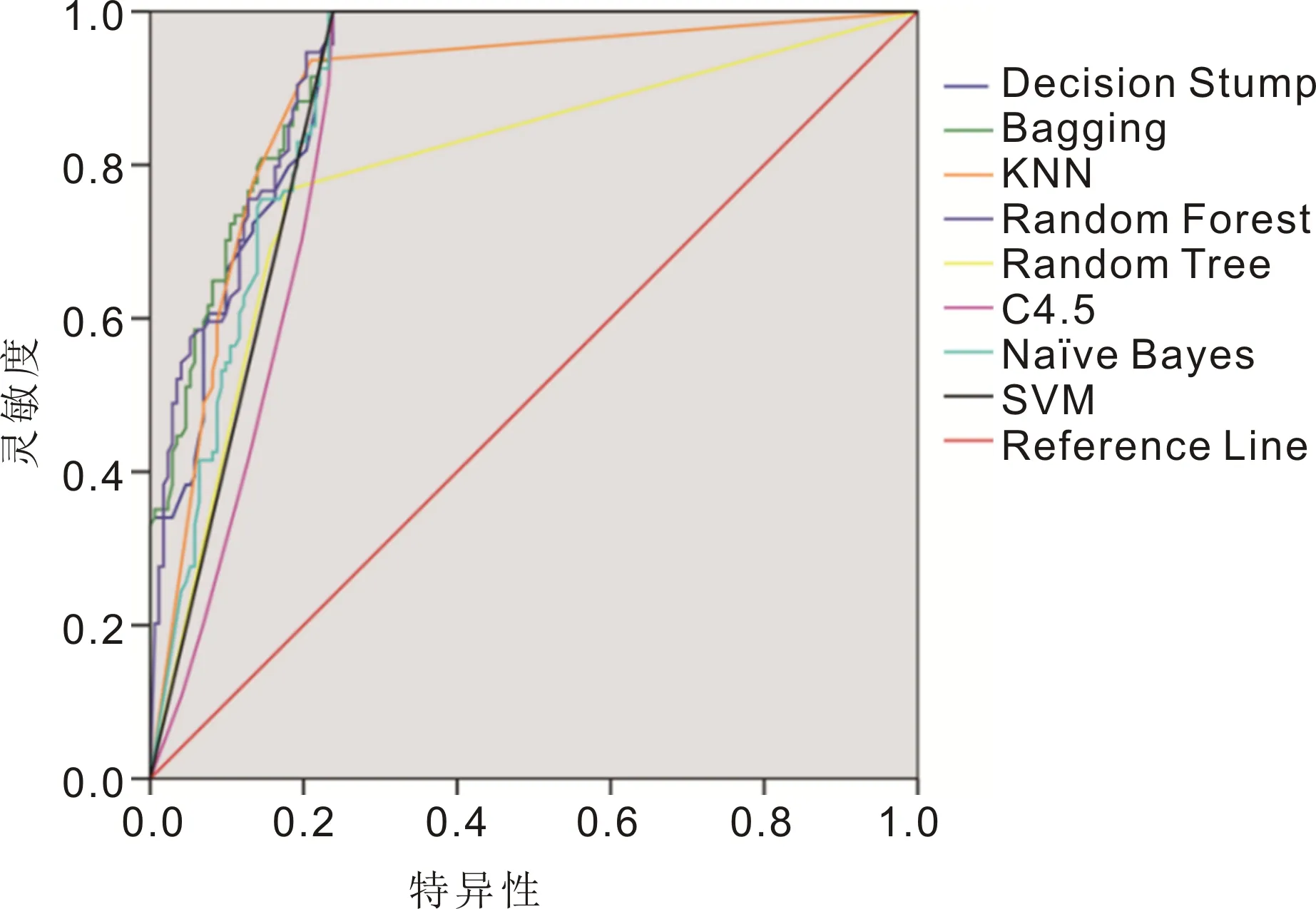
图1 不同算法预测能力的ROC曲线。
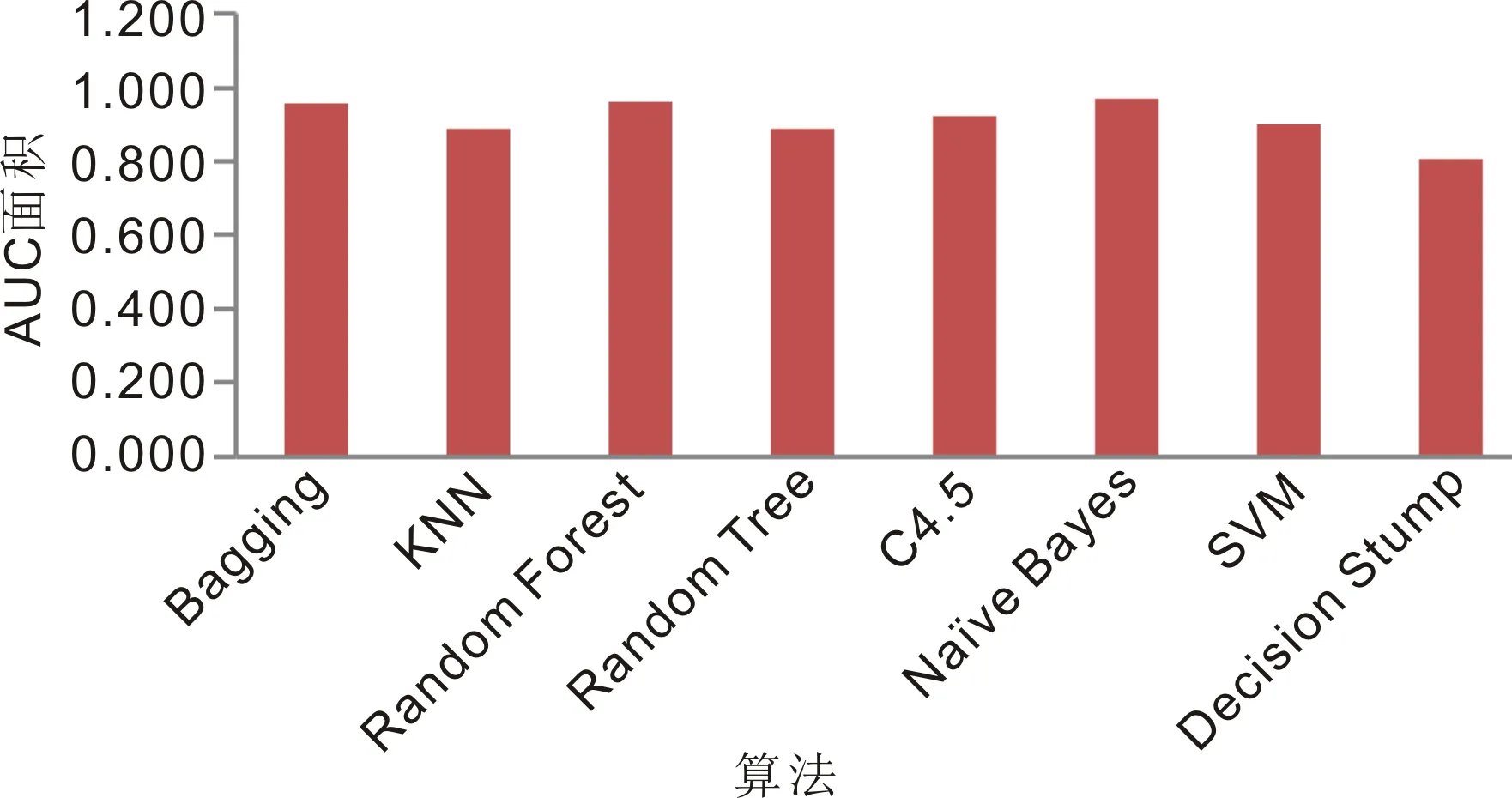
图2 不同算法的AUC面积。

图3 Random Forest算法参数优化后的预测准确率。
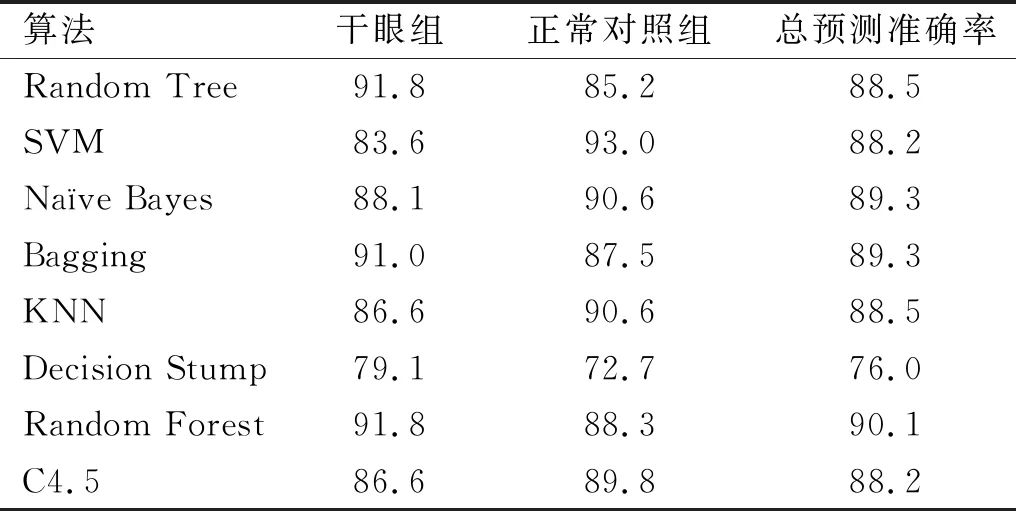
表1 特征子集采用不同算法的预测准确率%
2.3特征变量的干眼预测准确率采用Random Forest算法进行单因子变量预测能力进行评估,结果显示,FL评分和NI-BUT是筛选出的特征变量中干眼预测准确率较高的两个变量,均超过74%,见表2,表明这两个变量对干眼的诊断是最重要的。
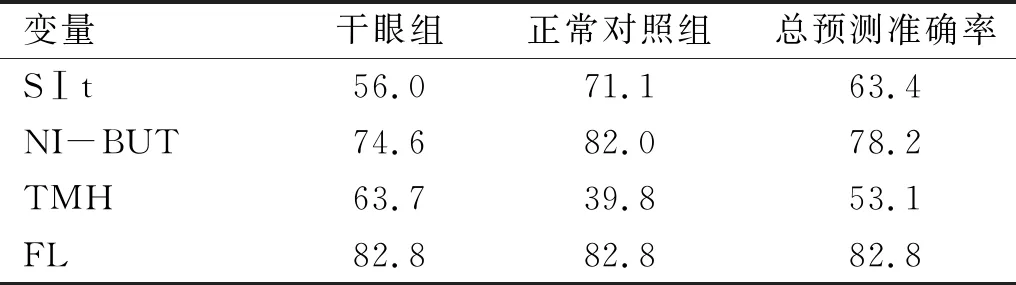
表2 单因子变量的预测准确率%
3讨论
目前对干眼的诊断指标较多,本研究采用诊断干眼常用的检测参数,针对20~70岁受试对象进行检测,对得出的数据进行数据挖掘和分析。本研究中通过变量筛选,选择NI-BUT、SⅠt、TMH和FL评分4个特征变量构建预测模型,得出FL评分和NI-BUT与干眼有较强相关性。
FL评分是通过染色实验准确判断角膜上皮损伤情况。荧光素衍生物染色若为阳性,提示存在干燥失活的上皮细胞。眼表细胞完整性受损时,可被特定染料着色,染色程度与眼表损伤的严重程度具有相关性。因此,眼表细胞染色可评价上皮细胞的屏障功能和完整性,本研究显示FL评分对干眼的预测准确性达82.8%,说明此指标可作为干眼严重程度的评价指标之一。NI-BUT是基于Placido环投射原理,结合自动分析软件,检测泪膜随时间破裂的位点和时间[15]。FBUT虽然检查方法便捷,适合临床使用,但属于侵入性检查[11],一定程度影响了泪膜的真实状态,因此对于处于临界范围的干眼,诊断会存在偏差。NI-BUT的重复性及其与传统FBUT测量值的一致性一直存在争议,但因其操作对眼表扰动小,近年来逐渐在临床推广,本研究发现NI-BUT的预测率在70%以上,是干眼的强相关影响因素。SⅠt是评估干眼的主要指标之一。本研究通过数据分析发现,SⅠt在干眼预测模型中总预测准确率在60%以上,这已经是干眼预测模型中相关影响因素里较强的指标了,计算的结果可以佐证临床调研的试验结果,说明干眼患者其泪液分泌量相比正常人显著降低。TMH是角结膜表面光带与下睑睑缘光带交界处的泪液的液平高度,可以通过该高度在一定程度范围内反映泪液的分泌量,但它在干眼预测模型中总预测准确率只有53.1%,比起其他3个特征变量,准确性偏低。
机器学习的重要目标之一是通过分析有限的样本进而对未知样本进行测试,得到最精准的估计结果。本研究收集了218例干眼样本,尝试用多种机器学习方法构建干眼预测模型。结果显示,Random Forest可以较好地对干眼患者进行识别。但是,相对于国内干眼患者这个群体,样本量偏少。一般当样本量较小或模型过于复杂时会出现过拟合[16],如具有相对于观测次数太多的参数存在等。通常过拟合将具有预测性能不佳的情况,因为其可以夸大小幅波动的数据[17]。本研究中,为了避免出现过拟合,我们采用独立测试集进行外部验证,从而降低过拟合的风险。
本研究通过数据挖掘的计算及临床数据的处理对干眼的影响因素进行预测,结果显示,Random Forest算法普遍要比其他算法学习器具有更加准确、稳定的预测效果。对于部分算法,如支持向量机等,在实际操作的时候,需要选择相对应的操作参数[18]。但是这些操作参数的选取在国际上现在没有确切的执行标准,对于操作者来说,一般是凭借经验进行选择,对于初步接触算法的操作人员来说具有一定难度。此外,由于参数的选取数值不同,会对结果产生很大偏差。建立参数优化模型可以解决参数选择的困难,并且在预测准确率时,可以得到最优的预测方案[19]。本研究中,我们通过变量筛选找出强相关变量,寻找干眼相关的新指标,进而用于临床诊断。基于以上变量,本研究采用不同算法分别构建干眼的预测模型,结果显示,所建模型的干眼预测准确率均高于75%。说明本研究所选用的特征变量泛化能力很强,适用于多种算法。但是考虑到实际临床中的假阴性或假阳性,因此有必要追求高预测准确率。通过所建立的预测模型,我们可以对一些干眼初期的疑似病例进行判别或预警,从而达到早诊断、早干预的目的。本研究不足之处在于纳入样本量偏少,在今后的研究中,将和其他眼科机构进行多中心合作,进一步扩大样本量,提高模型的预测准确率。
猜你喜欢
保健医苑(2020年8期)2020-08-19
中国生殖健康(2019年9期)2019-01-07
基层中医药(2018年10期)2018-12-06
基层中医药(2018年3期)2018-05-31
首都食品与医药(2018年3期)2018-03-18
科技视界(2018年33期)2018-02-21
中国医药指南(2017年3期)2017-11-13
西南国防医药(2016年6期)2016-12-01
中国中医眼科杂志(2015年1期)2015-12-28
中国中医眼科杂志(2015年1期)2015-12-28
