
基于人工智能技术的情感语义识别应用研究
2021-09-22 16:12杨睿刘家兴宋梦娇徐俊浩李冉冉王力卉
科教创新与实践 2021年28期
杨睿 刘家兴 宋梦娇 徐俊浩 李冉冉 王力卉

摘要:本文着眼于大众情感需求,利用日益完善的人工智能技术,实现人机间情感交流,为人类创造一个可以向人工智能程序寻求陪伴、尽情倾诉的机会。该研究致力于利用与人工智能的人机交互,结合互联网时代心理咨询服务的特征,填补大众情感缺口。
关键词:情感倾向分析;语义识别;人工智能;人机交互
1、 绪论
情感识别作为情感计算的一个关键分支,同时也是语义识别的一个重要应用方向,涉及到心理分析、人工智能、信号处理等多个技术领域,具有很高的研究价值,已经被应用于情感陪伴、心理评估、舆情分析等多个方向。
由于现代语言,尤其是网络用语的多样性,传统文本主题分类方法不能有效完成情感倾向识别。基于语义特征的情感倾向识别方法,可以分析得出原始文本所包含的明确情感倾向,更有利于完成情感区分。
实现基于人工智能技术的情感语义识别应用,需从语言语义识别和情感倾向分析两方面展开研究,其中情感倾向分析是关键环节。
2、 语言语义识别研究
2.1语义的表示
自然语言可通过分布语义,框架语义,模型论语义等三种主要途径进行表示。还可使用领域(domain)、意图(intent)、词槽(slot)等三种形式来表示语义。
(1)领域(domain)
通常按语言数据来源来划分领域。统一行业背景或专业范围内的语言数据划分为统一领域,如医疗、交通等。领域在语法中可看作句子的主语。
(2)意图(intent)
意图类似语法中的谓语,是指对语义领域内数据进行的动作或操作,比如查找交通等。
(3)词槽(slot)
指语义领域的属性,可看作语法中的宾语,如交通类型。
2.2语义识别的层次
(1)应用层
应用层是指语义的使用层面,如行业应用等。
(2)NLP技术层
NLP技术层是指对自然语言经过技术手段进行加工、处理转化成机器语言,或将机器语言合成自然语言。
(3)底层数据层
底层数据层是指语义的领域来源。
3、 情感倾向分析研究
情感倾向性分析又称情感分类,是指针对给定的文本,识别其情感倾向是积极的还是消极的,或者是正面的还是负面的,是情感分析领域研究最多的问题。
通常网络文本包含大量主观性内容和客观性内容。其中客观性内容是对事物的客观描述,不带有感情色彩和情感倾向;而主观性内容则是笔者对客观事物的看法及思考,帶有或强或弱的喜好厌恶等情感倾向。
显而易见,情感分类的对象是带有情感倾向的主观性文本,因此情感分类首先要进行内容的主客观性分类。文本的主客观分类主要以情感词识别为主,利用基于情感词典的特征表示方法和分类器进行词汇的主客观性识别分类,能够提高情感分类的速度和准确度。基于情感词典的方法具体来说就是,先对文本进行分词和停用词处理等预处理工作,再利用构建好的情感词典,对文本进行情感倾向分析,即字符串匹配,从而挖掘正面和负面情感信息。
下面分别介绍情感词典构建和情感倾向分析的情况。
3.1情感词典构建
情感词典的构建是情感分类的前提和基础。实践中的情感词典可归为4类:通用情感词、程度副词、否定词、领域词。一般词典使用过程中包含两部分,词语和权重。
现阶段情感词典的构建方法主要是利用已有电子词典进行扩展,例如对经典词典WordNet的扩充,在建立种子形容词词汇表的基础上,利用WorldNet中词间的同义和近义关系判断情感词的情感倾向,并以此来判断观点的情感极性。如确有需要,也可通过语料来训练新的情感词典,或建立专门的领域词典,以提高情感分类的准确性。
实际工作中有很多开源情感词典可供选择,例如BosonNLP情感词典。该词典是基于微博、新闻、论坛等数据来源构建的情感词典。此类开源词典还有知网情感词典等,大大降低了情感语义识别应用开发者的工作难度,有效调高其工作效率和质量。
3.2 情感倾向分析
(1)情感词典文本匹配算法
基于语义情感词典的倾向性计算不同于以来大量训练数据集的机器学习算法,主要是利用情感词典及句式词库分析文本语句的特殊结构及情感倾向词,采用权值算法代替传统人工判别或仅利用简单统计的方法进行情感分类。
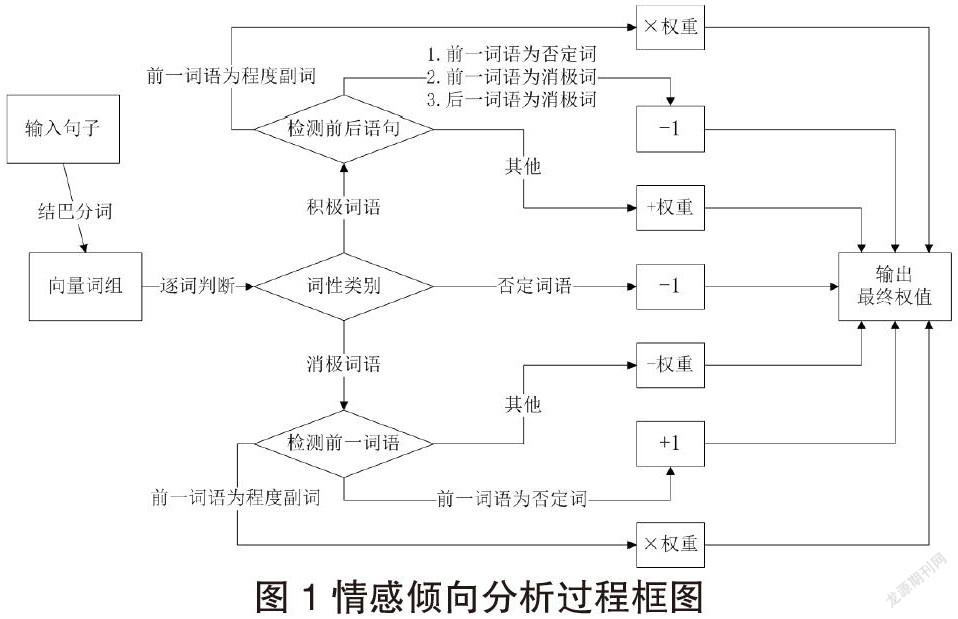
基于词典的文本匹配算法相对容易实现,效率较高。此类算法的原理是,完成语句分词后,逐个遍历所得词语。如果有词语命中词典,则进行相应权重处理:
①正面词权重为加法;
②负面词权重为减法;
③否定词权重取相反数;
④程度副词权重则与其所修饰词语权重相乘。
(2)倾向性计算算法
前文介绍的情感词典文本匹配算法给情感强度不同的情感词赋予不同权值,之后就由倾向性计算算法进行加权求和,最终输出的权重值,就可以区分文字所表达的是正面的、中性的,还是负面的情感了。
利用如式(1)所示加权平均算法计算,可有效提高通用领域情感分类的效率和准确率。
其中,Np、Nn分别代表表达正面情感和负面情感的词汇数目;wpi、wpj分别代表正面情感词汇和负面情感词汇的权值。
(3)确定阈值判断文本倾向性
一般情况下,加权计算结果为正,是正面倾向;结果为负,是负面倾向;得分为零则表示无倾向。一般采用自然语言中经常使用的正确率、召回率和方差分析F值来评判算法效果。
以上情感倾向分析过程如图1所示。
基于情感词典的方法和基于机器学习的分类算法相比,虽属于粗粒度的倾向性分类方法,但由于不依赖标注好的训练集,实现相对简单,对于普遍通用领域的网络文本可有效快速地进行情感分类。
4、 结论
本文深入研究了情感语义识别技术,利用情感词典对文本内容进行情感分析。本文所提出算法可以自动识别文本中的核心实体词,对包含主观信息的文本进行情感倾向性判断。由于采用了开源情感词典和相对粗颗粒的情感倾向分析算法,本文所设计应用的情感判断效果还有待提高。训练针对性更强的情感词典,以及引入可以使得分析算法更精细的神经网络技术,应是未来研究中重点考虑的方向。
参考文献:
[1]刘腾飞,于双元,张洪涛等.基于循环和卷积神经网络的文本分类研究[J].软件,2018,39(01):64-69.
[2]吴亚熙,岑峰.基于卷积神经网络的多层级目标检测方法[J].软件,2018,39(4):164-169.
课题项目:本文为沈阳师范大学校级大学生创新创业训练计划资助项目《基于语义识别的人工智能陪伴app——“智慧陪伴”》(项目编号:202113067)成果。
猜你喜欢
科学Fans(2019年6期)2019-07-26
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
科技创新导报(2016年23期)2016-12-23
电脑知识与技术(2016年26期)2016-11-24
计算机教育(2016年7期)2016-11-10
南风窗(2016年19期)2016-09-21
南风窗(2016年19期)2016-09-21
科教导刊·电子版(2016年17期)2016-07-16
