
基于分解-组合的预测模型在金融时间序列上的应用
2021-09-23 01:53周耀鉴袁晨迅
电子技术与软件工程 2021年14期
周耀鉴 袁晨迅
(中北大学软件学院 山西省太原市 030051)
1 背景
时间序列分析作为金融市场分析的核心任务,由于其固有的非平稳性、噪声性和混沌性,越来越受到人们的重视,大量文献表明,利用ARIMA[1]、GARCH[2]、Markov模型[3]、SVM模型[4]、灰色模型[5]、神经网络[6]等单一模型对金融时间序列进行预测是可行的。考虑到单一模型的局限性,很多学者利用混合模型对金融时间序列进行预测,一般认为其包括:非线性和线性组合模型、基于参数优化的预测模型、基于分解组合的预测模型以及上述模型的组合模型[7]。
在上述不同类型的组合模型中,基于分解-组合的预测模型已经被人们广泛接受,分解的基本思路是采用分解技术将原始时间序列分解为一系列子序列,再采用预测技术对各个子序列预测后相加即得预测结果。典型分解技术包括EMD分解,EEMD分解,CEEMD分解,DWT分解等,各子序列的典型预测技术包括前述各种单一预测模型。
上述基于分解-组合模型的方法均全部基于一次性分解,即事先一次性分解全部数据(包含训练数据和待预测数据)。这意味着事先假设未来数据是已知的,显然这违背了预测的目的。针对这一问题,本文对一次性分解和实时分解进行了详细的分析和探讨。首先本文介绍了EMD和LSSVM的相关原理;接着利用上证指数进行了具体的实证分析;最后,将一次性分解方法、实时分解方法以及单一模型进行进行比较,并分析了结果出现的原因。
2 相关工作
2.1 经验模态分解(EMD)
经验模态分解法是对时间序列进行平稳化处理,从而将一个信号中不同尺度的变化或趋势逐步分解成一系列不同特征尺度的数据序列。每一个序列称为一个本征模态函数(即IMF)。其中每个IMF代表原始信号的尺度变化分量,而余项通常代表原信号的趋势或均值[8]。本征模态函数必须满足两个条件:
(1)在整个数据序列中,极值点的数量和零交点的数量必须相等或相差一;
(2)数据序列相对于时间轴是局部对称的,即任何时间点的局部均值为零。
经验模态分解的主要过程如下:
(1)找到待分解信号X(t)的全部极大值和极小值点,利用三次样条函数分别拟合为该信号的上包络线e+(t)和下包络线e-(t),可以求得两条包络线的平均值m1(t):



图1:基于分解的时间序列预测方法(以EMD为例)

X(t)与第一个IMF分量的差值r1(t):

(3)选取r1作为原始信号进行过程(1)与(2)直到EMD分解过程出现中止过程即结束,中止过程通常采用两种判断准则:一种是最后一个IMF分量或者残余量小于预设值,另一种是残余量变成一个单调函数或者常量。经验模态分解的最终结果可表示为:

其中,ci(t)—第i个IMF分量,代表原始信号X(t)中不同特征尺度的信号分量;rn—剩余分量,反映了原始信号X(t)的变化趋势。因此,EMD可以将信号X(t)分解成m个不同频率的平稳分量(IMF)和一个趋势项之和。相关分解原理图见图1所示。
2.2 最小二乘支持向量机(LSSVM)
LSSVM的模型由下式给出[9]:

其中x=[x1, x2,…xi,…xK]对应训练集的输入,K是训练集的长度。y=[y1, y2,…yi,…yK]T对应训练集的输出,其是x和K的函数。xi∈Rn, yi∈R,Rn对应n维空间向量,R对应一维空间向量,i=1,2…K。α(K)=(a1, a2,…,aK)T代表待求的拉格朗日乘子,b为常值偏差,它们均为待求量。k(x,xi)为核函数,取不同的核函数可以得到不同的支持向量基,由于高斯径向基函数(RBF)结构简单,泛化能力强,本文采用RBF作为模型的核函数。在利用LSSVM模型之前,有两个参数需要选取,这两个参数分别是核参数σ和正规化参数γ。其选择将直接影响到支持向量机的学习和泛化能力,参数选取的方案很多,常用的有交叉验证法、k-折交叉验证法、进化算法和留一法等,本文采用留一法来选取这两个参数。

图2:一次性预测(左)和实时预测(右)的过程

图3:2019年上证指数的部分时间序列
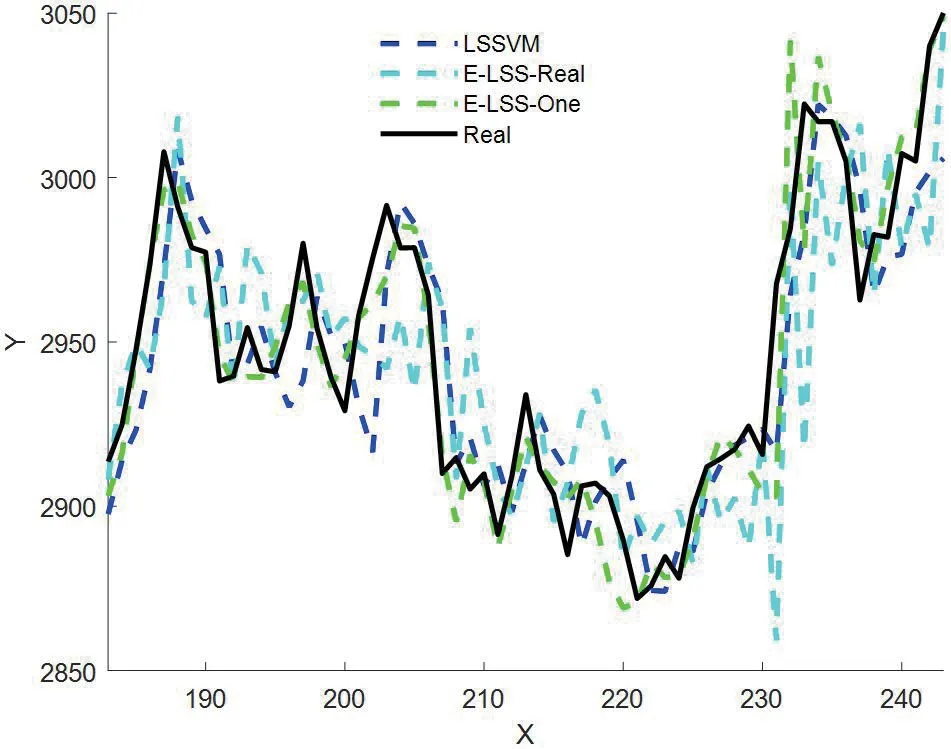
图4:不同方法下的预测结果比较

图5:波动性对比
3 模型搭建与实证分析
在前文提到,在预测中有两种处理数据的预处理方案:一次性分解和实时分解。在前者中,其对所有数据(包括已知和未知数据)只进行一次分解。而实时分解只针对训练部分,将其分解为许多不同的子序列。随着时间的推进,在获取新的真实数据之后,对训练数据进行更新和重新分解。之所以将它们进行区分,是因为这两种不同的数据预处理思路将导致完全不同的预测结果。这两种不同的分解方法流程图如图2所示。
下面以2019年的上证指数的日线进行实证分析,该数据共有244个,时间序列如图3所示。
固定时间窗长度为183,采用滚动单步预测。在基于一次性分解预测中,先对244个数据进行分解,在实时分解的预测中,滚动分解时间窗内的数据。图4给出了从184-244周期的单步预测结果。
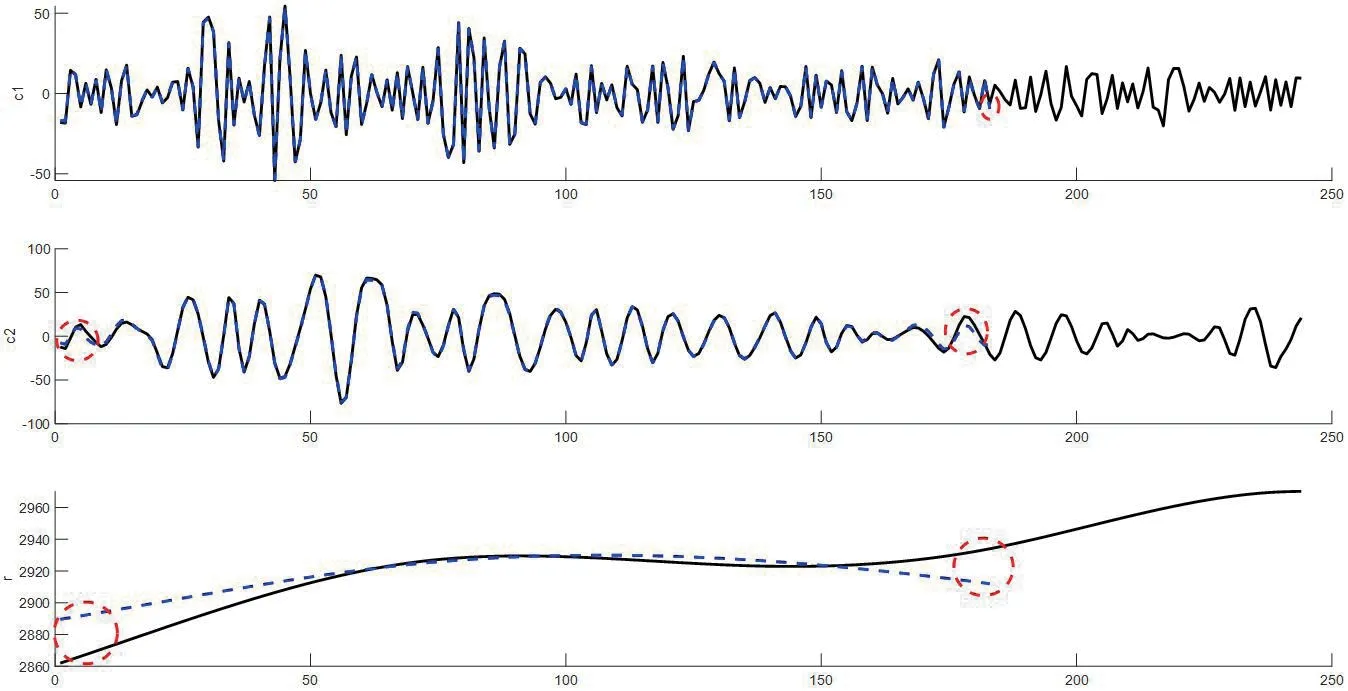
图6:端点效应
接着采用如下三个常用评价(MAE、MAPE、RMSE)指标对预测结果进行分析,具体结果如表1所示:


表1:三种不同评价指标下的预测结果比较
从表1可以看到,一次性分解预测方法远好于不使用EMD分解的预测方法,而实时性分解预测方法却不如不使用EMD分解的预测方法。
下面对这个问题进行分析,首先,一次性分解预测方法优于不加EMD分解的方法,其原因在于:
(1)其利用了全部数据的信息;
(2)其分解实现将非平稳的序列分解为平稳序列;
(3)每次利用的子序列的训练部分几乎没有波动性。
而实时分解比LSSVM还差的原因在于:
(1)其只利用部分数据的信息。
(2)虽然其也实现了非平稳数据分解为平稳数据这一目的,但每次所利用的子序列波动性非常大,波动性表现在两方面:一是分解级数可能不同,二是同级数的子序列差异性很大,具体分析如图5所示。
(3)端点效应严重,如图6所示。
4 结论
本文对分解-组合的金融时间序列预测模型进行了详细的探讨,利用EMD-LSSVM模型,并使用上证指数具体分析了单一LSSVM模型、一次性分解混合模型以及实时分解混合模型预测结果及其局限性,为接下来继续改进金融时间序列分析及预测提供了更好的思路。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
基层中医药(2021年12期)2021-06-05
英美文学研究论丛(2018年1期)2018-08-16
纺织科学研究(2017年6期)2017-07-03
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
电测与仪表(2014年23期)2014-04-04
计算物理(2014年2期)2014-03-11
