
俄语孤立数字语音识别研究
2021-09-23 07:05纪佳昕
现代计算机 2021年23期
纪佳昕
(信息工程大学洛阳校区,洛阳471003)
0 引言
自动语音识别(ASR)是指机器识别和理解语音信号并将其转换为文本或命令,根据信息执行人的各种意图[1],是一门融合了生理学、计算机科学、模式识别与人工智能的交叉学科。语音识别实践起源于1952年贝尔实验室研发的特定人独立英文数字识别系统,随着统计模型、神经网络等机器学习方法的兴起和发展,面向汉语和英语的语音识别技术逐渐趋于成熟并走向实用化。
目前,国内有关俄语语音的研究主要集中在双语发音比较和语音教学领域[2],使用统计和深度学习方法建模俄语声学特征的实践相对较少。王彤[3]结合全局约束和早弃策略改进DTW算法,提高了俄语短指令集的识别率和识别速度;杨政[4]构建了基于Se⁃quence-to-Sequence的俄汉语音翻译模型,避免了传统语音翻译错误级联的问题;吴敏[5]提取多种声学特征,设计对比实验探索了适用于俄语军事语音的识别模型,丰富和拓展了国内俄语语音识别的实验成果。
隐马尔可夫模型-高斯混合模型(GMM-HMM)是语音信号处理中广为应用的统计模型。在GMM-HMM中,HMM模块负责建立状态之间转移概率分布[6],每个状态可以是一个音素或词,可对应多帧观察值;GMM模块则通过多个高斯函数的线性组合负责生成HMM的观察值概率。本文收集了俄语孤立数字的音频语料,开展基于GMM-HMM模型的俄语数字识别研究,从词汇量、说话人特征和发音方式三个角度看,属于小词汇量非特定人孤立词识别范畴,可为俄语电话号码识别、语音区号识别等非特定人连续数字识别提供研究基础和参考。
1 俄语数字语音特点分析
1.1 语音结构分析
俄语书写系统使用33个西里尔字母,分为元音和辅音,辅音又分为清辅音和浊辅音。俄语遵循“元音中心”的论点,按照元音划分音节。一个词有几个元音,便有几个音节,没有复合元音[7],每个音节包含的辅音个数不限。俄语数字的音节构成如表1所示。
由表1可知,这十个数字中,多数为单音节词,存在一个三音节词。各词之间相同特征较多,其中五个词包含元音e,处于重音位置时发[э]音,非重音位置发[и]音。各 有 两 个 词 含 有 元 音o、я和и。数 字6|шесть、7|семь含有同一元音且发音相同。从组合特征上看,除数字1|один外,其他词均以辅音开头,多音节词通常以辅音和元音交替的方式组合而成。
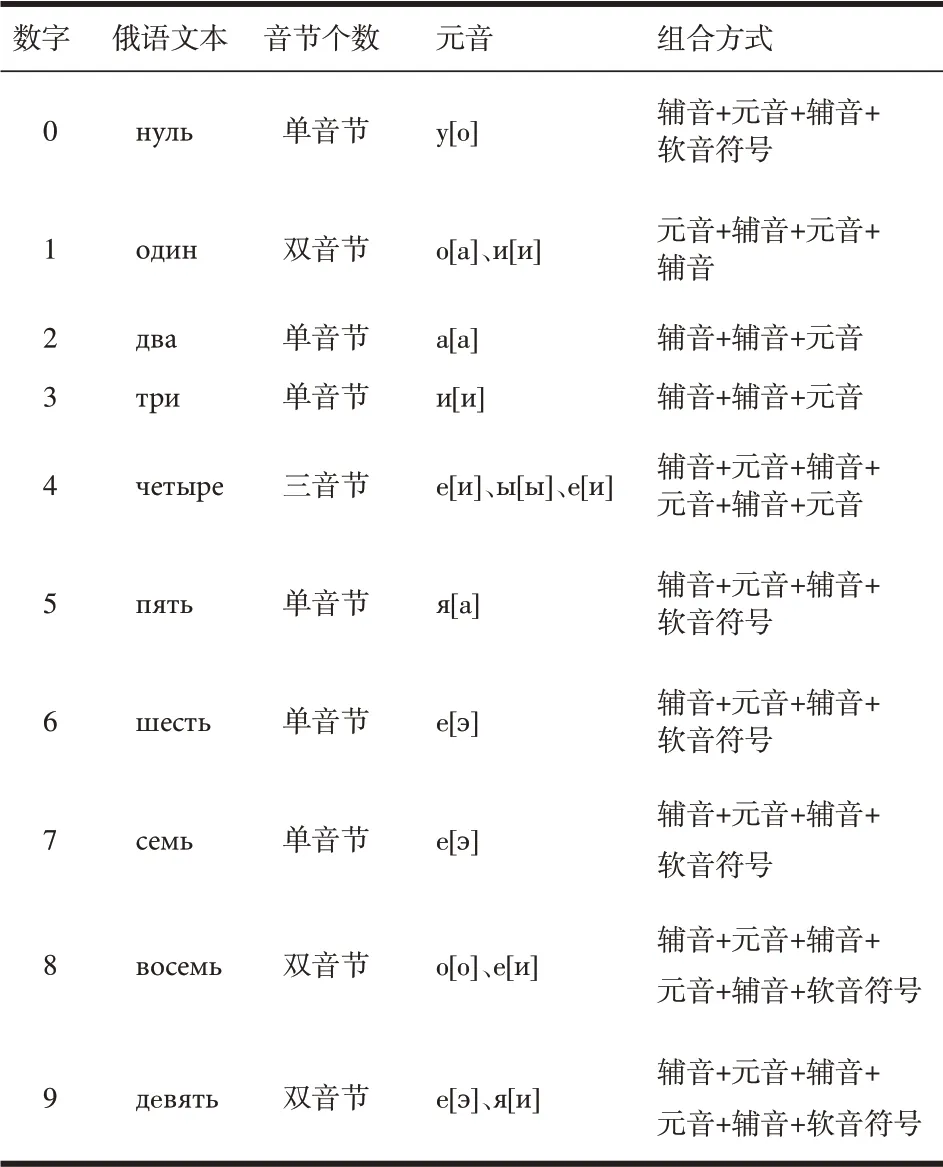
表1 俄语数字音节构成
1.2 相同元音音素共振峰分析
共振峰是语音能量比较集中的区域,决定了元音的音质。俄语的元音都是浊音。实验发现,元音发音舌位的高低和前后分别与第一、第二共振频率(F1、F2)有关。舌位越高,F1越小,舌位越靠前,F2越大。文献[8]收集整理了俄语元音的共振峰频率,反映在俄语数字中,如表2所示。
由表2可得,多数单元音发音特点与统计数据基本一致。如и属前高元音[9],因此F1值相对较小,F2值高,y为后高元音,所以F1值和F2值都较低,я、a为后低元音,F1高,F2低。部分数字为多音节词,共振峰值依靠多个元音的共同作用。

表2 俄语数字的元音共振峰频率
实验发现,不同语境下,同一元音的共振峰值也有所差别。以含有相同元音e的单音节词шесть|6和семь|7为例,将这两个数字的音频剪辑到一起,再用Praat观察两个数字的共振峰,可以发现二者的第一共振峰曲线在元音段比较相近,而семь|7发音时存在元音鼻化现象,使得семь|7元音段的F1值稍低于шесть|6,如图1所示。

图1 шесть|6和семь|7的共振峰比较
2 俄语数字语音识别流程
图2给出了俄语数字语音识别流程,分为信号数字化及预处理、特征提取、生成参考模式库和模式匹配几部分。预处理部分对信号进行适当放大和增益控制,将模拟信号转换为数字信号,以便存储和处理;特征提取即使用一些特征参数来表示信号,随后利用文本和语音训练数据建立特征模板库和相应模型;最后在识别阶段,提取待识别语音特征参数,并将之与模板库的特征一一比对,从中选取相似度最高的参考模板作为识别结果。

图2 俄语数字语音识别流程
2.1 语音数据预处理
预处理发生在信号的采样和量化之后,包括预加重、分帧和加窗等步骤。预加重是对语音高频部分进行加重,目的是去除口唇辐射对信号的影响,增加语音的高频分辨率[10]。设n时刻语音采样值为x(n),则预加重处理后的结果表示为:

α为预加重系数,且0.9<α<1.0。
分帧的理论依据是语音信号的短时平稳性,即认为基因频率在短时范围内是相对固定的[11]。语音信号的分帧是通过为可移动的有限长度窗口加权实现的。为保持帧与帧之间平滑过渡,采用交叠分段的方法,设置帧长为25ms,帧移与帧长的比值取1/2。常用的窗函数有矩形窗和汉明窗两种。本实验使用汉明窗,其函数为:

定义窗函数后,语音信号的分帧处理实际上就是对各帧进行一定的变换和运算。
2.2 双门限法端点检测
端点检测的目的是确定语音词中有话段的起止位置,剔除信号中的无声段和噪音段,使得识别模型聚焦于有效语音帧序列的特征。实验采用双门限法配合使用短时能量和短时平均过零率两个时域特征实现语音起点和终点的检测。
(1)短时平均能量。语音具有短时平稳的特征,即语音状态不会在短时间内发生突变,语音能量亦然。一般来说,浊音的能量值高于清音。由此,可将短时平均能量作为区分俄语轻音和浊音的依据。短时平均能量是信号值平方经过一个窗函数的滤波输出所得到的信号。n时刻某语音信号的短时平均能量En为:

其中N为窗长,ω(n)为窗口函数。
(2)平均过零率。通常,清音的过零率高于噪音及无声部分。可以使用平均过零率参数将信号的清音和噪声部分区别开来。短时过零率是单位时间穿过坐标系横轴的次数,其计算公式为:

(3)双门限端点检测思路。双门限端点检测方法综合运用了短时能量和短时过零率来检测俄语数字的发音起始位置[12]。图3分别以三音节词чет́ре|4、单音节词шесть|6、双音节词всемь|8为例,给出原始信号及其短时能量和过零率的时域特征。
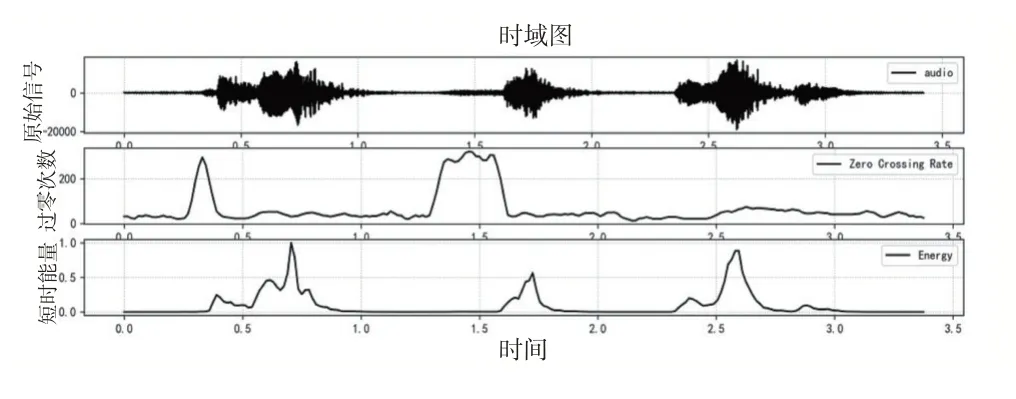
图3 三个俄语数字语音双门限特征参数示意图
双门限端点检测方法设有三个阈值,前两个是语音能量的阈值,最后一个是过零率的阈值。其判定步骤如下:
(1)一级端点判决:选取一个较高的门限T2,使得语音信号的能量包络大部分位于此门限之上,粗略提取初始语音段;选取一个较低的门限T1,并从初始语音段的起始点和终止点分别向左向右搜索,找到短时能量的轮廓与T1相交的两点,该两点确立的语音段即为利用短时能量判定的语音段;
(2)二级端点判决:确定一个平均过零率门限T3,并从第一阶段的语音段开始再次向左向右搜索,分别找到短时平均过零率低于T3的两点,则此两点确定为语音的起点和终点。
2.3 特征提取
语音识别和说话人识别实践最常用到的语音特征是梅尔倒谱系数(MFCC)。与其他特征相比,MF⁃CC与实际频率的对数分布大致对应,分析方法更符合人耳的听觉特性。MFCC特征提取流程如图4所示,具体步骤为:将预处理后的时域信号经过快速傅里叶变换(FFT)得到各帧频谱,并对语音信号的频谱取模平方得到语音信号的谱线能量,将能量谱通过一组含有M个滤波器的三角形滤波器组,如此同一语音参数将不会因发音人的音调高低而有所差别,从而突显语音的原始共振峰。然后对所有的滤波器输出做对数运算,再进一步做离散余弦变换(DCT)即可得12维MFCC。

图4 MFCC特征提取流程
重音是构成俄语节律的重要要素,能够反映语言的韵律特征[13]。俄语重音的音强较强,响度也较大[14],对应短时能量值也较大。相同条件下,不同音节产生语音流的短时平均能量各不相同,可作为俄语语音的一个重要区分特征。提取每一帧的对数能量作为一维特征参数,计算方法如下,其中N为分析窗的宽度,表示第t帧中第n个点的信号。

以上13维倒谱参数只反映语音静态特性,因此需计算其一阶二阶差分谱组合成共39维的特征参数,以描述语音的变化方向、变化速度等动态特征,通过两种信息的融合,更好地完成对语音信号特征的描述。
2.4 模型训练
模型训练整体流程如图5所示。首先将预处理后的各数字的训练音频经过特征对数提取等步骤生成MFCC矩阵,矩阵中的每一行代表相应数字一帧语音的声学特征。每个数字设一个特征列表,存储该数字所有训练集的MFCC矩阵,共生成十个列表,分别用于模型参数估计和训练。每个数字对应一个HMM模型,共得到十个模型。识别阶段,利用相同的方式得到待识别特征矢量矩阵并将其与各模型进行匹配,使用前向-后向算法计算该矩阵在每个孤立数字HMM上的输出概率,得分最高者对应数字标签即为判决结果。
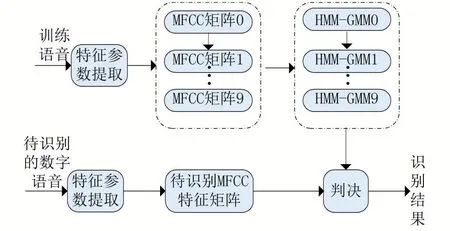
图5 模型训练流程
3 实验及结果分析
3.1 实验准备
(1)语料采集。语料采集选择在安静的教室环境中进行,采集对象为10名俄语专业学生,录音人年龄范围为21-27岁,其中男性5人,女性5人。采集设备为Adobe Audition CS6,环境为安静的教室。语音的采样频率为8kHz,编码方式为16bit线性PCM,单声道,Windows下wav文件格式。录制规模为每人3遍,每遍依次录制0-9的发音,每个发音间隔1 s左右。每遍采集的数据保存为一个音频文件,共计30个。最后将每个音频文件人工切割成单个数字的发音文件,最终得到300个原始语音信号样本,每个样本时长约为1 s。
(2)实验环境与评测指标。开展俄语数字语音识别的实验环境为Windows 10操作系统,开发语言为Python 3.7,使用python_speech_features、sklearn、mat⁃plotlib库实现模型训练和图表绘制。采用识别准确率评价系统的性能,识别准确率定义如下:

3.2 实验结果
采用五折交叉验证法,训练集:测试集=4:1,240条语音样本用于训练,60条作为测试。实验过程采用对比验证的方法,将10个数字的13维组合特征及其一阶二阶差分参数进行对比,通过对隐藏状态数(components)及迭代次数(iterations)进行调整,观察模型参数对系统性能的影响,得到测试集上的准确率如表3所示。

表3 模型正确率变化
从实验结果可以看出,模型的隐藏状态数和迭代轮数会对模型性能的影响较为突出。当MFCC维度为13时,模型在状态数为5,迭代次数为50时达到最佳性能84.3%;当MFCC维度为39时,模型在状态数为5,迭代次数为60时性能最优,最优值为89.7%。图6给出了最优状态数下迭代次数对两种特征维度的模型性能的影响。整体上看,39维特征训练出的模型,其识别正确率整体上高于13维特征训练出的模型,且二者最佳性能相差5.4%,说明融合了一阶二阶差分参数的MFCC可以描摹俄语数字更为全面的语音特征。
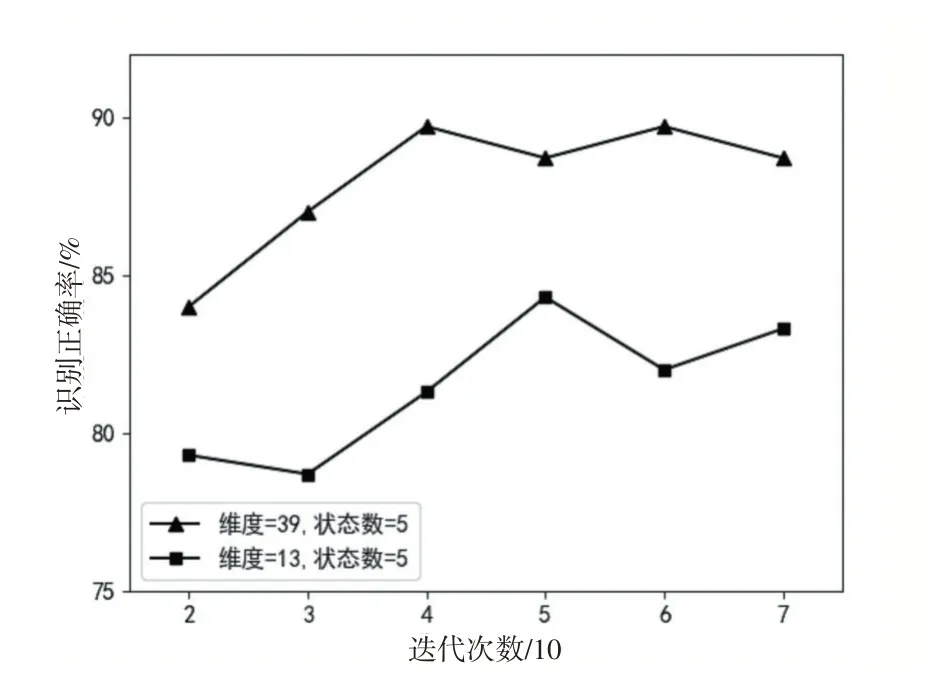
图6 最优状态数下迭代次数对模型性能的影响
为进一步探究单个数字识别效果,取模型性能最优时十个数字的正确率,得到表4所示。由表4可得,除了семь|7之外,绝大多数数字的准确率达到80%,7个数字识别准确率在90%及以上,尤其数字од́н|1,在测试集上得到了100%的识别结果。识别效果相对较差的数字为4、7、9,对以上误识别率较高的数字进行错误分析,发现三者之间互为易混淆数字。

表4 单个数字识别正确率
以上结果一定程度上印证了语音特征分析模块的相关结论。从元音构成的角度看,三个数字都含有相同的元音e且发音相同,共振峰均值相近,增加了相互误识别的几率;从音节构成上看,三音节词构成复杂,发音特点更加难以表征,这些都为模型判决带来了困难。而оди́н|1作为唯一以元音开始的数字词语,发音特性与其他数字的区别更为明显,因此得到了良好的识别结果。要想提高总体识别率,还需着眼于探索易混淆数字间的属性差异,并将其显式地引入特征矩阵中,有目的地展开区分性训练,以确保模型学习到它们之间更细微的差别。
4 结语
根据语音识别的基本原理和相关算法,在训练语料有限的条件下开展了基于GMM-HMM的俄语离散数字语音识别研究。一方面,尝试从语音学角度出发,分析十个数字声学特征的相似性,得出共振峰值接近和易混淆的数字,并结合Praat软件进行了分析验证;另一方面,在实验层面完成了数字音频切分及预处理、双门限法端点检测、声学特征提取、模型训练和判决的俄语语音识别流程,定量分析正确率达到89.7%,验证了模型和实验方法在小规模数据集上的可行性,为连续俄语数字语音识别研究提供了一定的参考借鉴。
同时可以看到,基于GMM-HMM的俄语孤立数字识别正确率还有一定的提升空间,后续应进一步结合语音学特征,改进易混淆俄语数字的区别性声学特征提取方法,并设计更多对比实验来验证模型算法对俄语语音的适应性。
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
考试与评价·七年级版(2021年1期)2021-08-14
考试与评价·七年级版(2020年1期)2020-10-23
兵器装备工程学报(2020年3期)2020-04-22
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
火力与指挥控制(2019年4期)2019-06-14
今日财富(2019年34期)2019-01-14
——探索古俄语的奥秘
长江丛刊(2018年23期)2018-11-14
现代职业教育·职业培训(2015年9期)2015-10-21
小学生时代·大嘴英语(2014年6期)2014-11-04
