
基于注意力残差编解码网络的动态场景图像去模糊
2021-09-23 08:53杨飞璠李晓光
应用光学 2021年4期
杨飞璠,李晓光,卓 力
(北京工业大学 信息学部,北京 100124)
引言
模糊是图像退化的主要降质因素之一,在图像采集的过程中,由于受到相机抖动、图像场景深度变化及物体运动等因素影响,往往会出现模糊退化现象。由于动态场景下的模糊图像复原通常是模糊核非均匀的病态逆问题,这使得模糊图像盲复原技术成为一个极具挑战性的计算机视觉问题。
传统的模糊图像盲复原方法[1-6]往往需要对模糊核作出假设,利用自然图像的先验信息复原清晰图像。大部分传统方法的研究主要集中于解决简单的目标运动、相机平移、旋转等因素产生的运动模糊,对于解决实际情况下由复杂因素引起的模糊仍有较大困难。
卷积神经网络(convolutional neural network,CNN)以其强大的特征学习能力使计算机视觉任务性能得到极大的提高。近年来,提出了基于CNN 的去模糊算法。早期基于学习的算法[7-9]遵循传统方法的去模糊步骤,使用CNN 代替传统方法来估计未知的模糊核。Schuler 等人[7]采用由粗到精的方式,采用多个CNN 网络迭代优化模糊图像。Sun 等人[8]和Yan 等人[9]将模糊核参数化,通过分类和回归分析对模糊核进行估计。这类算法的图像复原质量取决于模糊核估计的准确性,一旦模糊核估计错误往往使复原效果不佳。现在越来越多的方法开始采用端到端的深度网络直接学习模糊图像与清晰图像之间的映射关系。Nah 等人[10]设计了一个多尺度网络,以迭代的方式提取图像的多尺度信息,逐步复原清晰图像。Tao等人[11]提出了共享参数的尺度递归网络模型。Kupyn 等人[12-13]将去模糊任务作为图像风格转换的一种特殊情况,利用CNN 对模糊图像到清晰图像的映射进行建模。但是,这类方法大部分采用相同的网络权重,缺乏对非均匀模糊的自适应性,对于复杂的动态场景模糊图像的复原能力有限,容易造成复原图像的平均化。
视觉注意力机制能够定位图像中的目标并捕捉感兴趣的区域特征,已经成功应用于识别和分类问题[14-16]。模糊图像复原的目标是将图像中的模糊部分还原成清晰图像,因此图像中的模糊区域是我们复原和关注的主要目标,注意力机制的出现有望对图像去模糊任务带来帮助。目前,注意力机制在图像复原任务中的应用较少。论文[17]将注意力机制应用于多降质因素图像复原任务中。Purohit 等人[18]提出了一个自注意模块来处理空间变化模糊。实验结果表明,在大多数情况下,结合模糊图像空间变化特性设计的网络在去模糊任务中往往有更好的效果。尽管如此,结合注意力机制的图像去模糊方法依然有限。
本文针对现有算法缺乏对模糊图像复原的动态自适应性,设计了基于注意力残差编解码网络的动态场景图像去模糊算法。网络通过多个残差模块和模糊空间注意力模块提取空间变化的模糊特征。进一步,将全局-局部残差连接引入编解码网络,减少特征丢失,解决由网络深度带来的训练困难的问题,更好地利用特征。本文提出的方法能够自适应感知模糊的空间变化,动态复原模糊图像。
1 基于空间注意力的残差编解码图像去模糊网络
1.1 整体网络结构
为了提高模糊图像复原网络对空间变换模糊特征的感知能力,本文提出了基于空间注意力的残差编解码图像去模糊网络。通过利用空间注意力机制,从网络结构上实现动态捕获空间变化的模糊特征,以指导复原网络输出清晰的高质量图像,提高处理复杂模糊图像的鲁棒性。该方法提出的整体网络结构如图1所示。该网络以编解码网络为基础,加入4 个空间注意力模块(spatial attention module,SAM)。同时,为了更好地利用模型参数,采用全局-局部残差连接策略融合各阶段卷积特征。首先,编码阶段包含3 个尺度,每个尺度由1 个卷积和6 个残差模块[19]组成,每个尺度第一个卷积的输出和最后一个残差模块输出之间通过局部残差连接进行跨层相连;然后,4 个SAM 对编码阶段提取的特征进一步细化,使网络获得更有效的信息;最后,解码阶段由2 个转置卷积和3 个卷积层组成,通过融合全局残差连接特征生成具有清晰边缘结构的复原图像。

图1 整体网络框架Fig.1 Structure diagram of overall network
1.2 空间注意力模块
注意力机制在人类视觉系统中起着重要作用,视觉注意力机制能够定位图像中的目标并捕捉感兴趣的区域特征。模糊图像复原的目标是将图像中的模糊部分还原成清晰图像,因此,在网络中引入可捕捉模糊区域及其周围结构信息的注意力模型对解决非均匀模糊问题具有重要意义。本文在编解码网络的中部加入4 个SAM,以在空间维度感知非均匀模糊图像的重要特征并进行自适应特征细化,同时抑制冗余信息。如图2所示,SAM 由两部分组成:密集连接单元和空间注意力单元。首先,利用密集连接单元进行多层特征融合,充分利用各层特征信息,更广泛地提取模糊图像中的信息。然后,通过在密集连接单元后添加空间注意力单元提取模糊图像在空间位置上的重要信息,抑制冗余特征,更有效地利用特征。下文对密集连接单元和空间注意力单元作详细介绍。

图2 空间注意力模块网络结构Fig.2 Structure diagram of spatial attention module network
1)密集连接单元。特征提取是提高复原效果的重要方式,本文采用密集连接单元提取丰富的图像特征,减少特征丢失,提高特征利用率。密集连接单元具体的网络结构见图2所示。每个密集连接单元由6 个瓶颈层和1 个过渡层组成。
瓶颈层。每个瓶颈层包含1 个3×3 的卷积层,在每个卷积层后,添加了1 个IN(instance normalization)操作和1 个ReLU 线性激活函数。所有的瓶颈层之间均采用密集连接的方式进行连接,即每个瓶颈层的输入是前面所有瓶颈层输出的叠加,每个瓶颈层的输出都将作为后面每个瓶颈层的输入。这些连接能够充分融合多层特征,更好提取图像信息。
过渡层。将多个瓶颈层叠加后,最终输出的特征通道数为所有瓶颈层生成的通道数之和。为了减少最后特征图的通道数,本文在堆叠的瓶颈层后添加过渡层。过渡层由1 个3×3 的卷积层组成,该操作将减少输出特征图的通道数,从而减少后续的计算量。
2)空间注意力单元。由于动态场景中获取的模糊图像不同空间位置的模糊程度存在差异,引入空间注意力机制能够帮助网络在抑制冗余信息的同时,更有效地从模糊图像中有选择地提取重要特征。Woo 等人[16]提出了混合注意力模块CBAM(convolutional block attention module),该模块分别在通道和空间2 个维度上提取有意义的特征,以捕获重要信息并进行自适应的特征细化。该模块能够较为方便地嵌入到其他网络中,增强了网络特征学习的能力。因此,我们在密集连接单元后添加CBAM 模块中的空间注意力模块,来细化特征并增强网络的特征提取能力。与大部分二进制掩膜不同,我们的空间注意力单元通过sigmoid 激活函数得到注意力特征图,使注意力特征图中的元素为0~1 之间数值,元素的数值越大表示其对应位置获得了更多关注。由于模糊的非均匀性,图像的模糊程度在空间上是变化的。因此,这种注意力的意义在于使模糊图像不同位置的关注度存在一定的差异。
空间注意力单元利用多池化特征融合策略帮助网络有效提取特征的空间位置信息,具体网络结构如图2所示。首先,在通道维度提取输入特征图F∈RC×H×W的最大池化(max pooling)特征Fmax∈R1×H×W和平均池化(average pooling)特征Favg∈R1×H×W;然后,将池化操作得到的两个特征图拼接;最后,利用卷积操作得到注意力特征图A∈R1×H×W。其中,max pooling 和average pooling 能够分别保留特征的边缘和背景信息,两者拼接能为下一步的卷积操作提供丰富的特征信息,保证注意力网络准确提取图像的空间位置信息。具体步骤如(1)式所示:
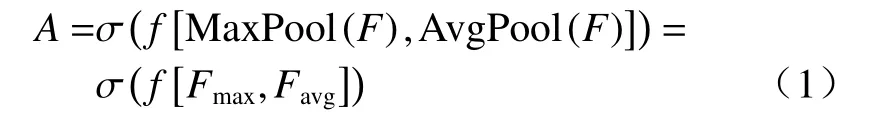
式中:A和F分别代表空间注意力单元的输入及其提取的注意力特征图;f和σ分别代表卷积操作和sigmoid 激活函数;[]表示拼接操作;Fmax和Favg分别表示提取的最大池化特征图和平均池化特征图。
在设计的网络中,我们将4 个SAM 串联连接,将上一个SAM 的输出作为下一个SAM 的输入,得到的多层特征传递给下一个SAM。动态场景下的模糊图像往往包含复杂的场景和空间非均匀的模糊特征信息。本文设计的方法可以使网络捕获动态模糊图像在每个卷积层的特征信息,并融合SAM 的局部特征,提高特征传播效率和特征利用率。也就是说,该方法通过提高网络的整体性能,获得更为详细的图像特征。
1.3 全局-局部残差连接
CNN 提升了图像复原算法的效果,但网络深度的增加提高了模型训练的难度。为了进一步减少信息丢失,改善网络训练过程中出现梯度消失现象,在网络中引入全局-局部残差连接策略,如图1所示。具体来讲,在编码阶段,每个尺度第一个卷积的输出和最后一个残差模块输出之间通过局部残差连接进行跨层相连。在解码阶段,加入全局残差连接指导网络生成具有清晰边缘结构的复原图像。
1.4 损失函数
本文通过最小化图像内容损失来训练所提出的网络模型,从像素层级对整体复原网络进行约束。内容损失函数用来计算输出去模糊图像与对应清晰图像之间的均方差损失(MSE,mean square error),如公式(2)所示:

式中:x和Xgt分别代表输入的模糊图像及其对应的清晰图像;ϕ(·)表示提出方法的整体网络结构。
2 实验结果分析
在本节中,我们进行了比较全面的实验结果分析,2.1 节介绍了提出方法的实验设置,2.2 节给出了消融实验结果,2.3 节给出了实验所用数据集以及对比实验结果。
2.1 实验设置
实验使用Ubuntu16.04 系统,采用NVIDA GeForce GTX 1080 Ti GPU 进行模型的训练和测试,使用PyTorch 平台搭建网络框架。本文采用ADAM 优化器[20]更新网络参数。实验中,设置学习率为10-4,β1、β2分别为0.9 和0.99,每次迭代batch size 设置为4。训练过程中的数据增强策略包括:1)随机水平或垂直翻转;2)随机旋转90°或-90°。从原始图像裁剪256×256 像素大小的图像作为网络输入。
2.2 消融实验
为了验证本文提出的空间注意力模块和全局-局部残差连接策略对于整体网络复原性能提升的作用,在GoPro 数据集上进行了两组消融实验。以未加入空间注意力模块和全局-局部残差连接策略的网络作为基础网络(Baseline),在基础网络中依次加入全局-局部残差连接、空间注意力模块,来验证对网络性能的提升作用。表1 为消融实验的客观结果。从表中可见,加入全局-局部残差连接网络(GL-Net)的客观结果高于基础网络,说明采用全局-局部残差连接策略能充分利用多层卷积提取的特征,提高模糊图像复原效果;本文提出的采用全局-局部残差连接策略的空间注意力编解码网络(GL-AttentionNet)性能达到了最优。实验结果表明,空间注意力模块对复原效果有较大影响,通过对提取的特征赋予不同权重,可使网络关注于重要部分,而抑制不重要部分。

表1 消融实验在GoPro 测试集上的平均PSNR、SSIM 结果Table 1 Average PSNR and SSIM results of ablation experiments on GoPro test set
2.3 GoPro 数据集的实验结果
早期基于学习的方法使用模糊核与清晰图像卷积合成模糊图像,由于生成模型较为简单,使合成数据不适用于解决真实情况下的图像去模糊。文献[10]采用对高速相机拍摄视频中的连续帧取平均的方法合成真实模糊图像得到了GoPro 数据集。该数据集包含3 214 幅成对的模糊/清晰图像,每幅图像大小为720×1 280 像素,涵盖多种场景,模拟复杂动态场景下的非均匀模糊。图3 展示了部分GoPro 数据集的示例图像,每幅图像都有各自场景特点,且图像模糊程度各异,具有模糊空间分布不均匀的特点。本文采用GoPro 数据集训练整体网络,按照与文献[10]相同的设置,划分为2 103幅训练集和其余1 111 幅测试集。本文采用峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity index,SSIM)指标对算法进行定量评价。

图3 GoPro 数据集Fig.3 GoPro data set
我们在GoPro 测试集上与现有5 种动态场景去模糊方法进行了对比实验。这些方法包括:Nah 等人提出的方法DMSCNN[10],DeblurGAN[12]、DeblurGAN-v2[13]、SRN[11]以及Gao 等人提出的方法DSDeblur[21]。其中:Nah 等人[10]的方法采用端到端的网络结构复原图像,取得了不错的去模糊效果;DeblurGAN[12]将生成对抗网络应用于图像去模糊任务,该方法能够较好地复原图像细节;Deblur-GAN-v2[13]能够复原出包含丰富的边缘轮廓信息;Gao 等人提出的算法[21]在GoPro 数据集上实现了较好的主客观结果;SRN 算法[11]将递归网络应用于图像去模糊任务。表2 列出了不同方法的客观实验结果。从实验结果可见,本文方法PSNR 指标最高,SSIM 指标与其他方法相当、与最高指标相差较小,相差为0.03。从运行时间看,本文方法复原一幅图像的平均时间为0.53 s,在对比方法中运行速度最快,说明本文提出的方法时间复杂度低。

表2 不同方法在GoPro 测试集上的平均PSNR、SSIM 结果以及复原1 幅图像的平均时间Table 2 Average PSNR,SSIM results on GoPro test set with different methods and average time of restoring an image
图4 为对比实验的主观结果。我们选了3 幅具有代表性图像,第1 幅图像为远距离场景下车辆快速运动引起的局部模糊;第2 幅图像为由相机抖动引起的全局模糊;第3 幅图像为近距离场景中行人快速运动带来的模糊。从图4 中可以看到,DeblurGAN 算法对于复杂模糊的复原能力有限。DeblurGAN-v2 算法生成的复原图像仍然存在模糊平均现象。DMSCNN 算法能够较好地复原图像细节,但仍然有模糊存在。本文提出的方法可以在高动态场景下对模糊图像进行复原,得到了边缘清晰的复原图像。从图中可以看出,本文的方法对于场景中快速运动的汽车、车牌上的文字以及模糊的人脸都有较好的复原效果,证明了本文算法的有性。

图4 GoPro 测试集的主观结果Fig.4 Subjective results of GoPro test set
3 结论
本文提出了基于注意力残差编解码网络的去模糊方法。该方法以编解码网络为基础,加入空间注意力模块自适应地选择提取特征的权重,使网络获得更有效的信息。为了更好地利用特征,采用全局-局部残差连接策略融合各阶段卷积特征,生成具有清晰边缘结构的复原图像。实验结果表明,本文提出的去模糊网络在公开数据集上取得了较好的峰值信噪比值和结构相似性值,并且主观结果上也能复原出包含清晰纹理边缘特征的图像,证明了提出的算法对于动态场景下的模糊图像有较好的复原能力。
猜你喜欢
疯狂英语·新悦读(2022年8期)2022-09-20
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
陶瓷学报(2020年6期)2021-01-26
北京航空航天大学学报(2020年10期)2020-11-14
紫禁城(2020年8期)2020-09-09
自动化学报(2019年6期)2019-07-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
河南科技(2015年8期)2015-03-11
