
基于深度反向投影的感知增强超分辨率重建模型
2021-09-23 08:53杨书广
应用光学 2021年4期
杨书广
(西安建筑科技大学 理学院,陕西 西安 710055)
引言
单图像超分辨率重建(SR)是计算机视觉中的一个经典问题,它的目标是从一张低分辨率(LR)图像重建高分辨率(HR)图像。SR 已广泛应用于视频监控、卫星遥感图像、医学图像、显微镜成像以及图像和视频压缩等诸多领域。虽然针对图像SR 提出了许多解决方案,但由于图像SR 的病态性和较高的实用价值,在计算机视觉领域仍是一个活跃而富有挑战性的研究课题。近年来,深度学习技术,特别是卷积神经网络(CNN)和残差学习,极大地提升了图像超分辨率重建的性能。SRCNN[1]是首个成功采用CNN 来解决SR 问题的模型,它是一个简单的3 层网络,可以学习低分辨率图像LR 和高分辨率图像HR 之间的端到端的映射,在当时取得了超越传统算法的重建效果。随后,各种用于超分辨率重建的卷积神经网络相继出现。He Kim 等[2]通过引入全局残差学习,将网络深度增加到20 层,在SR 性能上取得了显著提高。其他一些模型,如DRCN[3]和DRRN[4],则侧重于权重共享,以减小模型参数的比例。虽然这些方法性能优越,但都需要原始LR 图像的双三次插值版本作为输入,不可避免地丢失了一些细节,且计算量较大。而反卷积[5]和亚像素卷积[6],可以改善这一问题。相比于双三次插值,它们有助于减少原图像的信息损失。为了生成高质量的图像,Johnson 等人提出了基于从预先训练的网络中提取的高级特征的感知损失函数,与使用逐像素损失训练的方法相比,该函数可以重构更精细的细节。近年来生成对抗网络(GANs)[7]在包括单图像超分辨率重建在内的许多计算机视觉任务中都取得了良好的效果。Ledig 等人[8]使用GANs(SRGAN)获得了逼真的自然图像,其在视觉效果上明显优于非GAN 网络重建的图像,但也产生了许多伪细节纹理。
综合来看,目前已有的基于CNN 进行超分辨率重建的方法可以分为两大类。第一种方法将SR 作为重构问题,采用均方误差MSE 作为损失函数来实现高的峰值信噪比(PSNR)和结构相似度(SSIM)值,以SRCNN 等作为代表。然而,这种方法往往产生过度平滑的图像,在纹理细节上难以满足人的视觉感知需要。为了获得更好的感知质量,第二种方法将SR 转换为图像生成问题。通过结合感知损失[9]与生成对抗网络(GAN),这种SR 方法具有生成符合人视觉效果的纹理和细节的潜力,以SRGAN 为代表。尽管GAN 网络生成的高分辨率图像具有良好的感知效果,但也生成了很多原图并不具有的纹理细节,其忠实性很成问题。这表现在GAN 网络生成的高分辨率图像PSNR 和SSIM 值通常都较低。
针对上述问题,本文提出了一种基于深度反向投影的感知增强SR 网络模型,设计了双尺度自适应加权融合的特征提取模块,基于深度反向投影的重建模块和具有U-net 结构的增强模块。采用稠密连接[10]和残差连接以实现图像特征的重复利用和减少梯度消失对模型优化的影响,并引入了可学习的感知相似度[11](LPIPS)作为新的图像感知质量的评价指标和损失函数。模型可以在4 倍下采样因子下重建超分辨率图像,实验结果表明,本文提出的模型在保持较高的PSNR和SSIM 值的同时,感知质量也优于SRGAN 生成的超分辨率图像。
1 模型
1.1 网络结构
网络结构总体分为特征提取模块、重建模块、增强模块,如图1所示。
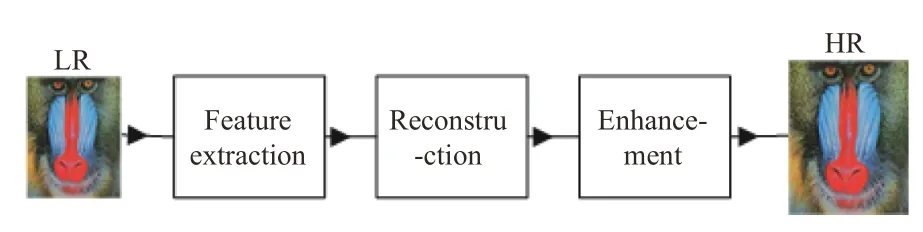
图1 网络总体结构Fig.1 Overall structure of network
本文结合亚像素卷积和逆亚像素卷积设计了双尺度自适应加权融合特征提取模块。该模块有2 个输入分支,一支和原图分辨率相同,另一支通过亚像素卷积得到分辨率减小一半的低分辨率特征图。2 个分支分别通过亚像素卷积和逆亚像素卷积[12]进行上采样和下采样,以实现两组特征图不同分辨率之间的相互转化,相比于常用的池化和各种插值实现下采样和上采样,亚像素卷积和逆亚像素卷积能够完整地保留原特征图的信息。不同分辨率的特征图分别经过上采样和下采样之后,与另一分支分辨率同样大小的特征图并行连接,并分别与各自的可学习的权重向量相乘,以自适应的调节各通道权重,藉此实现不同分辨率之间的自适应信息交互,最后再分别进行卷积,如图2所示。所有卷积核大小均为3×3,步长为1,通道数见表1。每个卷积核之后接PReLU 激活函数。

表1 特征提取模块中各卷积核通道数Table 1 Number of each convolution kernel channel in feature extraction module
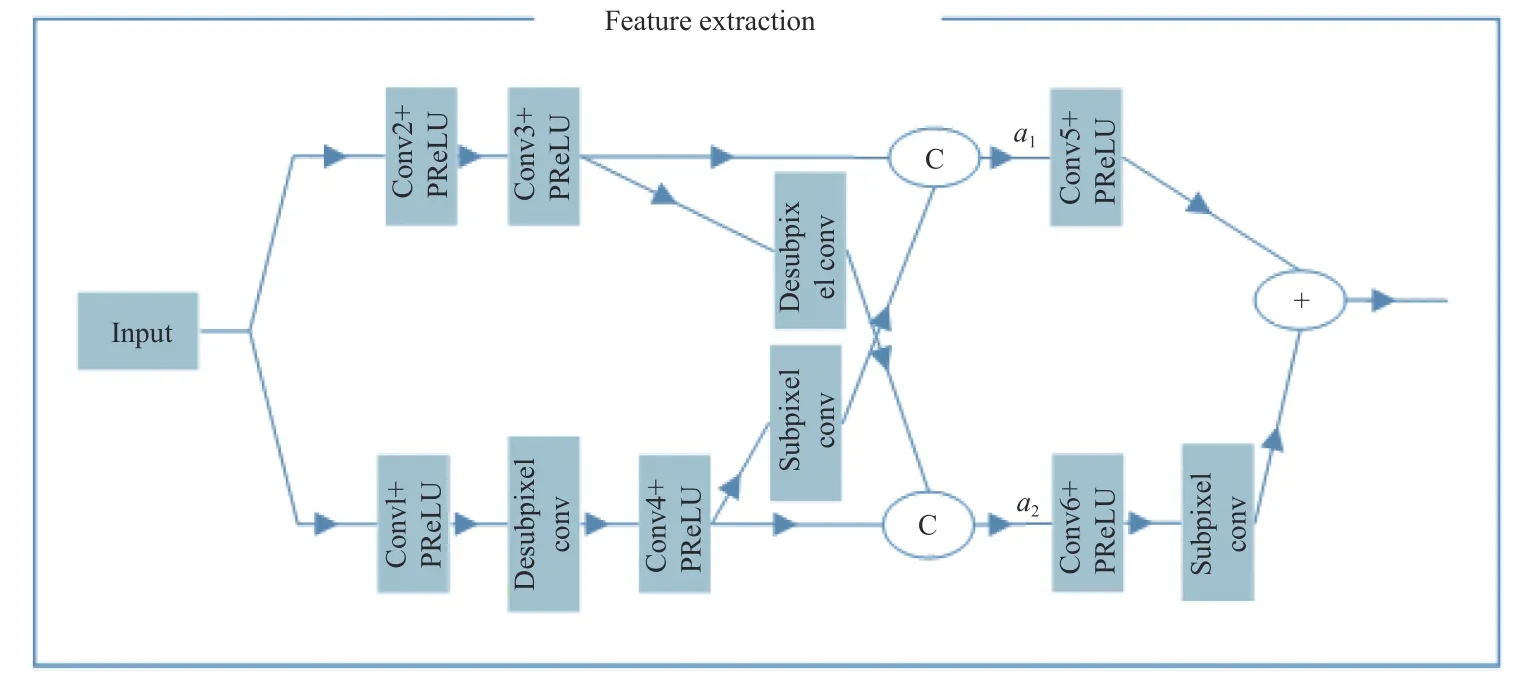
图2 特征提取模块Fig.2 Feature extraction module
亚像素卷积的主要功能是将通道数为c、大小为w×h的特征图组合为新的通道数为c/r2、大小为(wr)×(hr)的高分辨率特征图,其中r为上采样因子。具体来说,就是将原来低分辨特征图的一个像素点扩充为r×r个像素点,利用r×r个低分辨率特征图的同一像素位置的值按照一定的规则来填充扩充后的r×r个像素点。按照同样的规则将每个低分辨像素点进行扩充就完成了重组过程,过程中没有损失任何像素信息,且没有可学习的参数。逆亚像素卷积则是将上述过程反过来,从高分辨率得到下采样后的低分辨率图像,图像分辨率减小而通道数增加。
特征提取模块可用公式表达如下:

式中:Xk(k=1,···,7)为特征图;Cm(m=1,···,6)为卷积核;Xh表示并行连接后的高分辨率特征图;Xl代表并行连接后的低分辨率特征图;表示Xh的第i个通道;c1为Xh的通道数;表示Xl的第j个通道;c2为Xl的通道数;和为可学习的权重向量,初始值为单位向量;Xhw为按通道加权后的高分辨率特征图;Xlw为按通道加权后的低分辨率特征图;*表示卷积运算;S表示亚像素卷积;DS为逆亚像素卷积;P(·)为PReLU 激活函数;Cat(·)表示特征图的并行连接。
重建模块以深度反向投影[13]为基础,将低分辨率特征图4 倍上采样为高分辨特征图。迭代反向投影通过交替使用上采样块(Up-block)和下采样块(Down-block)(见图4)来迭代学习低分辨率和高分辨率图像之间的误差,以更好的重建高分辨率图像。文献[14]证明了反向投影在超分辨率重建任务中的有效性。与文献[13]不同的是,本文采用亚像素卷积代替了原结构中的反卷积进行上采样,这显著减少了网络参数和运算量。本文使用了4 个上采样块和3 个下采样块进行重建,且各个上采样快(下采样块)之间进行了稠密连接,以共享特征图及防止梯度消失,如图3。

图3 重建模块Fig.3 Reconstruction module
第t个上采样块通过亚像素卷积将输入的LR 图像Lt-1上采样为HR 图像经卷积下采样为LR 图像然后将与Lt-1按像素作差,得到再经亚像素卷积得到HR 图像最后将与按像素求和,得到输出Ht,如图4(a)所示。卷积核的参数为:核大小为8,步长为4,填充为2。
上采样块的结构可用公式表达如下:
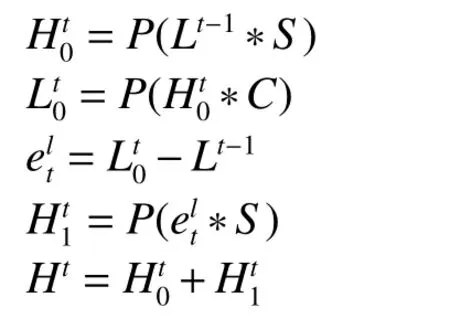
式中:S表示亚像素卷积;P(·)表示激活函数PReLU;C表示卷积核;*表示卷积运算;t=1,2,3,4。
下采样块结构与上采样块类似,如图4(b)所示,用公式表达为

图4 上采样块与下采样块Fig.4 Up-sampling block and down-sampling block

各采样块通道数见表2。

表2 各采样块通道数Table 2 Number of each sampling block channel
增强模块以U-net[15]结构为主体,通过对重建后的图像进行增强以提高视觉感知。U-net 最早用于医学图像分割,其结构特征为:先上采样,后下采样,且同分辨率之间采用跳跃连接[16]。这种结构有助于网络学习到不同尺度的特征,有效避免梯度消失的问题,结合低分辨率和高分辨率信息获得很好的学习效果。这也使得U-net 近年来被广泛应用于图像分割、目标检测、图像生成等领域。
本文设计的U-net 结构如图5。重建后的HR 图像依次和7×7×64、5×5×64、3×3×32 的卷积核进行卷积,得到下采样图像,然后依次进入5 个稠密残差块(见图5 右边),最后再与3×3×32、5×5×64、7×7×104、3×3×3 的反卷积进行卷积得到最终输出的HR 图像。这里跳跃连接是按对应像素求和。除最后一层的3×3 的卷积核填充为1 外,其余填充皆为0,所有卷积核步长均为1。

图5 增强模块Fig.5 Enhanced module
稠密残差块由4 个卷积层组成,依次有32、32、64、128 个通道,所有卷积核大小皆为3×3,填充为1。卷积层之间采用了稠密连接:每一层都以前面所有层的输出作为输入。这种连接方式可以共享稠密残差块内的特征,文献[17]表明,共享底层特征对于图像中结构细节的正确重建非常重要,同时也增加了后续层输入的变化,有助于网络学习到更多信息。最后的输出采用了残差连接。
1.2 损失函数
本文的损失函数使用L2范数,包括像素间的损失Lp以及特征图之间的LPIPS 损失LLPIPS。
记I为原图,ISR为模型的输出图,则
Lp=‖I-ISR‖2
式中‖·‖2表示L2范数。
LLPIPS损失以LPIPS 指标作为损失函数,对于LPIPS 指标的介绍见2.2。模型总的损失L为
L=Lp+λLLPIPS
式中 λ为参数,经实验后,取 λ为0.1。
2 实验
2.1 数据与超参数
本文使用General-100 作为训练数据集,测试数据使用了从Flickr2K 数据集中裁剪的部分图片。训练时对训练集的图像进行随机裁剪得到80×80 像素大小的图像块,然后对图像块进行4 倍因子的下采样以获得低分辨率输入图像。下采样采用Bicubic 算法。
本文使用Pytorch 框架训练模型,学习率为0.000 1,优化算法采用Ranger 算法,该算法结合了RAdam 算法[18]和LookAhead 算法[19],能够使网络更为稳定快速地收敛。模型迭代次数为9 000 次,批大小为30,损失函数曲线见图6所示。

图6 损失函数曲线Fig.6 Loss function curve
2.2 评价指标
本文采用的图像评价指标有峰值信噪比(PSNR)、结构相似度(SSIM)、可学习的感知相似度(LPIPS)。
PSNR 是最普遍和使用最为广泛的一种图像客观评价指标,数值越大说明与原图越接近。然而它是基于对应像素点间的误差,即基于误差敏感的图像质量评价。由于并未考虑到人眼的视觉特性(人眼对空间频率较低的对比差异敏感度较高,人眼对亮度对比差异的敏感度较色度高,人眼对一个区域的感知结果会受到其周围邻近区域的影响等),因而经常出现评价结果与人的主观感觉不一致的情况。
SSIM 是一种评价图像质量的主观评价指标,其值介于0~1 之间,越接近1 说明与原图越相似。SSIM 算法在设计上考虑到了图像的结构信息在人的感知上的变化,该模型还引入了一些与感知上的变化有关的感知现象和结构信息,结构信息指的是像素之间有着内部的依赖性,尤其是空间上靠近的像素点。这些依赖性携带着目标对象视觉感知上的重要信息,因此SSIM 比PSNR 更适于评价图像的感知效果。
可学习的感知相似度(LPIPS)于2018年被提出,是一种基于学习的感知相似性度量指标。与感知损失类似,其方法是:使用预训练网络(如VGG 和Alex)的某些层得到特征图,然后再训练另一个精心设计的网络,网络输出特征图的距离,距离越小说明感知质量越好。实验证明感知相似度比传统相似性度量方法更好。近年来,这一指标多用于GAN 网络生成的图像的评价。相比于PSNR、SSIM 指标,LPIPS 更能反映出由GAN 所生成的图像的感知优势。
2.3 实验结果
实验从Flickr2K 数据集中选取了7 张图片进行测试,在4 倍上采样因子下,将本文的算法结果与Bicubic、SRCNN、SRGAN 的重建结果进行了对比,重建效果展示见图7,对比指标有PSNR、SSIM、LPIPS,对比结果见表3、表4、表5,表中最优结果均加粗显示。

图7 重建效果对比Fig.7 Comparison of reconstruction effects

表3 PSNR 对比结果Table 3 PSNR comparison results

表4 SSIM 对比结果Table 4 SSIM comparison results

表5 LPIPS 对比结果Table 5 LPIPS comparison results
由表3、表4、表5 可见,本文算法在PSNR、SSIM 两项指标对比中,7 个样本中有6 个样本优于对比算法,在基于学习的感知评价指标LPIPS 上则全面优于对比算法。同时可以看到,Bicubic 和SRCNN 在PSNR、SSIM 指标上优于SRGAN,而SRGAN 则在LPIPS 指标上优于Bicubic 和SRCNN。本文算法则在保持高的PSNR、SSIM 值的情况下,同时拥有较低的LPIPS 值。
3 结论
本文提出了一种基于迭代反向投影的感知增强SR 模型,设计了双尺度自适应加权融合特征提取模块、基于深度反向投影的重建模块以及具有U-net 结构的增强模块。结合像素间的损失和LPIPS指标作为损失函数。实验和指标评价表明,相比于SRCNN 模型只追求高的PSNR 和SSIM 值,SRGAN模型只追求高的感知质量而不顾图像细节的忠实性,本文所提出的模型能够在保持较高PSNR 和SSIM 值的情况下,同时获得较好的感知质量。
猜你喜欢
红外技术(2022年11期)2022-11-25
北京航空航天大学学报(2021年9期)2021-11-02
计算机应用(2020年7期)2020-08-06
数学物理学报(2019年3期)2019-07-23
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年9期)2018-11-02
艺术科技(2018年2期)2018-07-23
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
