
安全帽检测系统设计
2021-09-27 08:57宁波市镇海蛟川书院钱昱成符水波
电子世界 2021年15期
宁波市镇海蛟川书院 钱昱成 符水波
为解决工地场所人员的安全隐患问题,提出了一种基于计算机视觉技术与人工智能技术相结合的安全帽检测系统。设计了一种与特征图深度融合的改进YOLOv3算法,它能够捕捉到原图像中更多中小型目标物体的图像信息,使得系统模型更加关注、学习这一块图像信息,进而能够更好的完成对安全帽佩戴检测这一任务。实验结果表明,该系统能够对工地中的工人进行实时、高效检测,有效的减少工地场所安全隐患。
据2020年的全国安全生产数据分析,其发现生产安全事故中有94%的原因是作业技术人员的不安全行为所导致,如越权限进入工地场所、违规操作、未正确佩戴安全保护设备、操作失误等行为。在施工过程中,正确佩戴安全帽是一项基本规定。由于缺乏监督,工人不戴安全帽所造成的安全事故时有发生。为了解决施工人员的安全隐患,有必要对施工人员的安全帽进行检查,降低因不正确佩戴安全帽而造成的事故发生率。
生产安全问题一直是一个社会关注度极高的话题。实现智能视频监控安全帽佩戴是安全生产环节必不可少的。胡恬等人使用YCbCr模型,利用不同人群肤色差异进行定位、采取小波变换进行数据预处理,通过训练神经网络检测图像中人员是否佩戴安全帽。杨莉琼利用SVM分类器对脸部上方是否有安全帽进行判断,进而实现对工人安全帽佩戴行为的实时检测和预警。与上述传统方法不同,本文利用基于卷积神经网络,设计了一种安全帽检测系统,能够高效、准确的检测出未佩戴安全帽的工人并给予警告。
1 系统设计框架
检测系统由两块组成,第一块主要用于对人员的安全帽进行检测,第二块实现人员的移动检测。如何更好的实现两者是主要的研究工作,检测流程如下:
(1)现场监控设备捕获人员信息,将视频流通过网络传送至管理系统。
(2)管理系统收到视频后,通过目标检测网络进行安全帽检测。
(3)若检测到人员未带安全帽进行相关信息保存,保留当前帧图片并通知管理人员。
(4)管理人员收到警告信息,纠正违反安全生产行为。
2 网络模型设计
安全帽佩戴检测模块采用YOLOv3为基础框架,该方法能够自主学习目标特征,减少手工特征等人为因素干扰,从而能够具有较高识别性能,对复杂场景下的不同方向、不同形状以及不同颜色的安全帽检测都可以呈现较好的泛化能力和鲁棒性。同时还在网络框架中引入了多尺度预测,在特征图大小分别为13×13,26×26,52×52上进行图像检测。由于不同尺度特征图对不同物体的识别能力有所区别,通过多尺度预测和特征融合的方式能够有效提高图像中物体的检测能力,进而有效的提升整个系统的检测性能。总体框架如图1所示。
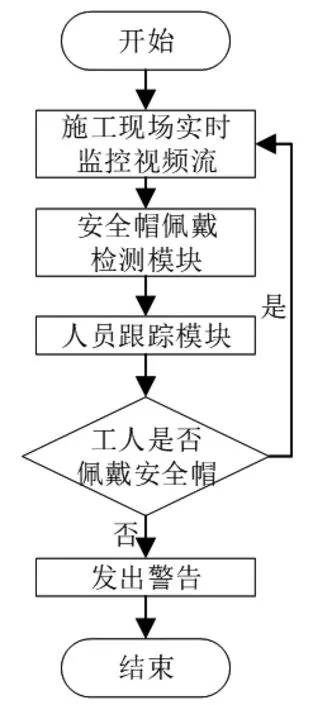
图1 总体框架图
2.1 特征提取网络Darknet-53
文本中YOLOv3的特征提取网络使用的是Darknet-53。与YOLOv2中的Darknet-19不同之处在于多了残差单元模块,和连续的1×1和3×3卷积层。该网络结构共包含了53个卷积层以及5个Max-Pooling层。其中,为了防止过拟合现象的产生,在每个卷积层后都会添加归一化(BN)操作和dropout随机线性失活操作。
2.2 YOLO V3设计思想和改进
YOLOv3是采用多个不同尺度融合的方式进行预测,结合不同特征图对不同尺寸目标的检测能力不同,将不同尺度检测效果最好的特征图进行融合的方式能够提高整体的检测性能。在YOLOv3中,使用的是维度聚类的方式获取先验框从而预测边界框。通过K-means方法对目标框坐标进行维度聚类,进而得到多个不同大小的先验框,然后将其分配到多个不同尺度的特征图上,使得每个特征图都有着更合适的特征先验框。在本文训练过程中,利用二值交叉熵损失进行类别预测。
YOLOv3在目标检测领域的检测效果已经很不错,但是针对本文中的安全帽数据集,仍需要一些改进使其更适应此检测任务。改进方法如图2所示。
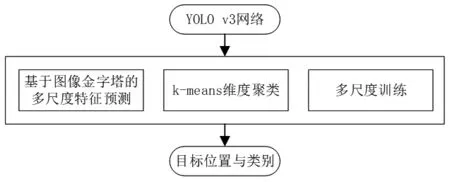
图2 方法框架图
在现实场景中,由于摄像机角度的不同,视频中的目标物体大小也不一致。因此为了更好的检测不同尺寸的安全帽,在YOLOv3的基础上,提出了多尺度图像金字塔融合、k均值聚类和多尺度训练算法改进。考虑到不同尺度适合不同尺寸大小物体的检测,使用多尺度特征预测更能捕捉到图像全面,深层次的信息。为了使图像中的目标更好的检测出来,尽可能的不漏检,在网络进行特征提取后,加入一个更大的卷积层,实现不同尺度大小的物体检测。多尺度融合指的是将不同层次的特征图融合连接操作,得到最终的三组预测特征图,然后在这三组预测特征图上做定位和分类。在实验中,先通过k均值聚类算法在本文自制的工人数据集上得到预测先验框维度。YOLOv3算法中的先验框维度是原先基于COCO数据集上训练得到,这种方式不能很好的满足于我们特定的安全帽佩戴检测任务上,为此需要针对工人安全帽数据集进行聚类操作,来获取对应的聚类中心。
2.3 人员跟踪算法研究
在实际应用场景中,人员都是流动的,摄像头需要不断的捕获人员,有些场景下摄像头拍摄角度不是固定不变的。因此为了更好的定位人员,设计了人员跟踪算法Deep SORT。在实验中初步采用了SORT算法,但由于该算法使用的相关指标只有在状态估计的不确定性较低的情况下才能表现出较好的性能,并且在使用过程中容易引起ID切换,因此在遮挡的情况下SORT算法无法跟踪。而Deep SORT使用更可靠的度量而不是关联度量,并使用卷积神经网络对不同行人的数据集进行预训练,提取行人特征,以增加网络的鲁棒性,从而大大减少了SORT中的ID switches。通过实验验证该算法能够有效减少ID switches,同时在不同场景下的视频流中也能达到很好的检测效果。
3 安全帽检测系统的实现
3.1 系统开发环境
在本系统中,采用了基于YOLOv3的模型,开发工具为pycharm,开发语言主要为python。Keras是目前主流的深度学习开发框架之一,集成了Tensorflow更方便开发人员使用。在特定的开发环境下,使用该语言,能够极大的缩短开发时间,其优点如下:
(1)语法简便,开发环境容易搭建。
(2)封装多个神经网络模块,能够快速搭建网络。
(3)做到CPU与GPU资源切换。
3.2 系统测试
通过设计安全帽检测系统,在工地场景下的工人进行安全帽检测。当监控摄像头下存在未佩戴安全帽的工人时,系统做出警报。为确保系统的实时性,在GPU环境中进行了测试。在实时获取到视频流时,可能由于网络环境等因素的影响造成检测延时,因此使用GPU测试实时性更好。系统接收工地实时监控视频流,然后通过YOLOv3检测视频流中工人是否佩戴安全帽,将检测的结果实时展示在检测视频方框中。实验结果证明本文的系统对于工地场景下的安全帽检测达到了不错的效果,人员是否佩戴安全帽基本上都能被本文所提出的系统所检测出来。系统测试效果如图3所示。

图3 检测效果图
总结:本文提出的特征图深度融合的改进YOLOv3的安全帽检测系统,它能够更加关注于图像的中小型目标,同时能够构建4种不同尺度的特征金字塔,不同尺度的特征可以更全面的捕获到图像中不同尺寸大小的物体,和深层次的语义信息,使得在检测中更为准确的定位安全帽。在实时检测中能够满足快速、准确的要求。
猜你喜欢
机电安全(2022年4期)2022-08-27
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
课外生活·趣知识(2019年4期)2019-09-10
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
电视技术(2014年19期)2014-03-11
华东理工大学学报(自然科学版)(2014年3期)2014-02-27
