
基于改进GLR 算法的英语翻译智能识别模型设计
2021-10-10 03:55宋晓焕梁金伟刘晓连
电子设计工程 2021年19期
宋晓焕,梁金伟,刘晓连
(西北大学现代学院基础部,陕西西安 710000)
在全球化背景下,国际通用语言为英语,并且使用越来越广泛。但是,各行业都缺乏高英语能力人才。针对我国市场需求,要重视学生的英语语言能力[1]。在英语语言能力中,英语能力为重点,要想在日常交流实践中使用英语,应加强英语语音纠正和学习。以往完全根据教师传授,不仅需要大量的人力资源,并且实现比较困难,所以,开发英语翻译智能识别模型尤为重要。该模型能够监测学生英语发音,并且提出纠正意见。传统英语翻译智能识别模型和设置存在一定的问题,无法对英语翻译精准识别,且无法纠正学生英语发音,还会误导学生发音,对英语学习造成影响[2]。基于以上问题,文中研究了基于GLR 算法的英语翻译智能识别模型,从而自动化识别英语翻译。为了验证模型的有效性,文中对模拟环境开展仿真实验。
1 英语智能识别算法
1.1 创建短语语料库
智能翻译模型中使用的语料库具有重要作用,语料库可用于存储双语短语资料,并且对英语、汉语中的短词语的词性进行精准标注,规范每个短语功能,提高英汉机器翻译过程中短语自动识别算法的时效性和精确性,使英汉机器翻译更加精准[3]。图1为短语语料库信息流程。

图1 短语语料库信息流程
文中所设计的英语翻译智能识别模型短语语料库中的单词有70 多万个,满足实际使用需求。如图1 所示,短语语料库的针对性比较强。文中通过英汉机器翻译短语语料,对不同的短语语料时态进行全面区分,标注英汉短语语料;语料标记方式包括层次、数据与加工3 个部分,数据类型为文本格式,层次使用对齐和词性的方式,加工方式使用人机主动沟通方式直接互动,开展英文翻译的一系列常规操作,提高短语语料翻译的精准性[4]。
1.2 短语语料库词性识别
一般地,因为词性识别结果中的GLR 算法偶然性比较大,识别数据点具有较高的重合概率,因此无法满足现有词性识别的精准度。文中所分析的改进经典GLR 算法利用短语中心对短语结构进行分析,降低数据点重合概率,提高词性识别精准度。利用四元集群计算改进GLR 算法的短语前后文似然性[7]:

式中,S为开始符号集群,为CN中元素,VN为循环符号集群,VT为终止符号集群,α为短语动作集群。
假如P表示α中任意动作并且存在于VN,通过推导可得出:

式中,θ、c、x、δ分别表示动作右侧符号、约束值、中心点符号、标记方式。
改进的GLR 算法规定识别线性表最上面的符号和θ一致,约束值x需为真,中心点符号c需为数值,不能为空值。只有超过3 个标准的识别结果,才是短语词性的识别结果[8]。
2 英语翻译智能识别模型
根据数据收集、处理与输出对智能识别模型进行规划,图2 为英语翻译智能识别的总体架构。

图2 英语翻译智能识别的总体架构
2.1 模型设计流程
对英语翻译智能识别模型所需要实现的功能进行规划整体模型设计,图3 所示为模型设计流程。此模型能够实现数据的收集、输出与处理。使用数据采集装置收集语音信号,之后利用音频输入设备将英语信号输入到处理系统中,对数据信号进行处理,处理后结果在相应客户端与显示器中输出,用户通过显示器或者客户端能够对英语翻译自动化识别结果进行查看[9]。

图3 模型设计流程
2.2 英语信号处理
对模型设计后就要开展详细设计,有计划收集英语信号并且处理,但是因为英语语音信号具有干扰因素,如人体本身发音不标准、设备不完善等,因此所收集的语音信号信息并不是百分百精准。为了提高精准度,要对收集的语音信号进行加工处理,包括分帧、加重、端点监测与加窗等[10],图4 所示为英语信号的处理过程。
科技人员既是科技成果开发者,也是加快转化的促进者,虽然已出台政策明确保障科技人员在成果转化中的权益,但实际操作依然面临制度难点。高校和研究开发机构对科技成果转化人员的评价和管理制度不完善,“重论文、轻成果”“重立项申请、轻成果转化”等现象依然存在,一定程度影响了科技人员从事成果转化的积极性。
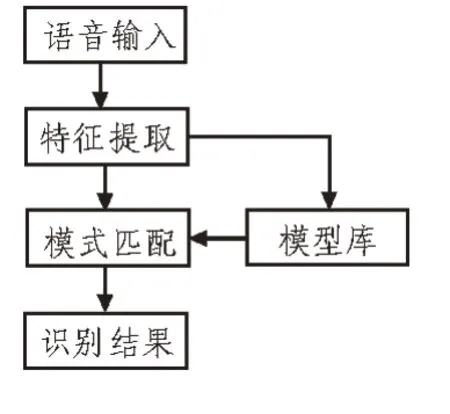
图4 英语信号的处理过程
利用数字滤波器实现语音信号加重处理,并完善重音检测系统,具体方法为:使用符号F1、F2 分别表示元音谱特征的第一、第二共振峰,其和舌位前后、高低相关。基于此,利用神经网络对非重音和重音区分之后就能够利用分类器系统输出位置置信度,从而对元音音准进行衡量,进而选择最佳语音信号。文中使用信噪比为6 dB的高频信号提升预加重数字滤波器对语音信号高于800 Hz的频段进行技术处理。加重系数α位于0.9~1.0 之间,加重处理信号y(n)的计算公式[11]为:

式中,x(n)是输入语音信号,信号处理之后对语音信号进行第二步处理,使用半帧交叠方法实现分帧操作。为了精准分析语音信号,将语音信号划分成为t帧,计算公式为:

实现分帧操作处理后对语音信号进行加窗操作,为了清楚地展现语音效果,选择矩形窗w(n),计算公式为:

利用双门限比较法实现加工后语音信号的端点监测,从而迅速寻找起始点与结束点,以便对数据处理和存储。利用该方法能够降低干扰项,提高监测精准性[12]。
2.3 提取特征参数
为了进一步提高系统运算效率,降低和语音信号无关的数据干扰,应统一整理相关信息数据,从而寻找参数特征,然后实现后续计算。图5 为提取特征参数的结构。
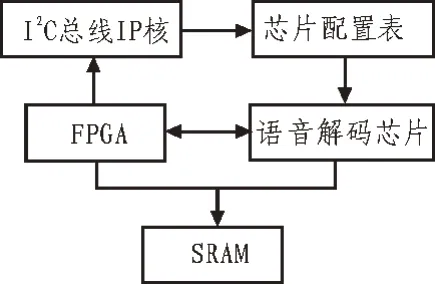
图5 提取特征参数的结构
非周期性连续时间信号利用傅里叶变换计算信号的连续图谱,但是在实际控制系统中得出连续信号离散采样值,所以要通过离散采样值计算信号图谱。快速傅里叶变换FFT 是以离散傅氏变换的奇偶虚实等特性对于离散傅里叶变换的算法改进得到的,一段有限长离散语音信号通过改进得出以下公式[13]:

式中,x[n]是通过采样得出的离散语音序列,X[K]是k点复位序列。
将离散语音序列转变为Mel频率尺度:

式中,Mel(f)是Mel频率,f是实际频率。
对滤波输出开展离散余弦变换DTC,得出语音信号w(n)的特征参数提取结果P,计算公式为:

一段语音信号生成谱图之后要进行加重、加窗、分帧等处理,每个短时分析窗通过快速傅里叶变换能够得到频谱信息,然后利用Mel 滤波得出MFCC 二维图。
使用上述方法,以英语语音智能识别为需求,通过节奏、语速、音准、语调等方面将相关语音信号参数进行提取[14]。
3 实验分析
3.1 有效性验证
为了全面验证英语翻译智能识别模型的有效性,通过实验实现了文中模型的英语翻译校对测试,记录实验过程中的数据,分析系统性能。实验中有400 字符校对词汇量,500 篇短文校对数量,25 kB/s 词汇识别速度。对比校对后与校对前的英语翻译结果精准度,表1 所示为校对前后英语翻译的精准度。

表1 校对前后英语翻译精准度
通过表1 可以看出,英语翻译结果校对前的最高精确度为75.1%,使用文中模块智能识别之后,精确度高达99.1%,两者精准度具有较大的差别,验证了系统英语翻译智能识别模型的有效性。
3.2 识别节点分布对比
为了将设计模型的优势充分展现出来,在实验过程中使用基于句法与短语的智能识别模型实现对比实验。记录实验过程中各个系统的节控点位数量,对节控分布情况进行分析。节控点位分布能够描述英语翻译语义、语境关联程度,节控点位密集分布表示系统英语翻译识别具有较高的精准度。图6和图7 均为系统识别节控点位的分布情况,图6 中的节控点位分布紧凑,说明系统识别性能比较高,校对结果更加精准,并且使英语翻译过程中语境不连贯问题得到解决;图7 中基于句法和短语的识别系统节控点位分布松散,但是在第1、4、5 次实验过程中具有节控点位分布紧凑问题,表示系统具有较高的校准精准度,但是翻译结果预警连贯性比较差。其次,此系统节控点位分布松散和紧凑交替变换,表示并不稳定[15]。

图6 文中识别系统节控点位分布
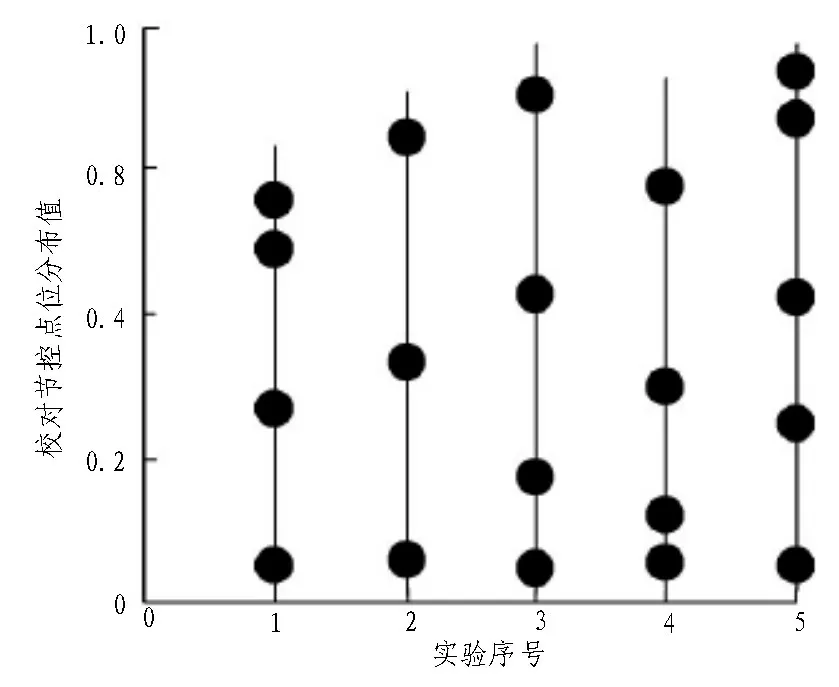
图7 计算机智能校对系统节控点位分布
通过以上描述可知,文中设计英语翻译智能识别模型具有较高的校对精确度,能够对英语翻译结果中语境不连贯的问题进行识别,给出了符合语境连贯性、合理性的翻译结果。
4 结束语
文中针对英语翻译时存在的结构问题,为了解决传统GLR 算法中的数据点重合问题,提出了改进的GLR 算法。利用短语中心点设计改进算法中的短语结构,以解析线性表句法功能,对词性识别结构、英汉结构歧义进行矫正,解决传统计算方法中识别结果精准度比较低的问题,为短语识别提供合理方法。通过文中实验结果表示,基于改进GLR 算法及其翻译对比其他算法计算比较简单,并且难度比较低,满足英语机器翻译工作的需求。
猜你喜欢
四川工商学院学术新视野(2021年1期)2021-07-22
学生天地(2020年28期)2020-06-01
科技进步与对策(2020年9期)2020-05-28
当代陕西(2020年24期)2020-02-01
安阳工学院学报(2018年6期)2018-11-28
网络安全和信息化(2018年3期)2018-03-03
自然资源情报(2017年4期)2017-11-26
海峡姐妹(2016年2期)2016-02-27
当代教育实践与教学研究(2015年2期)2015-02-27
