
基于神经网络的南海东部砂岩油藏采收率预测方法
2021-10-14 03:06侯博恒崔传智陆水青山吴忠维
油气藏评价与开发 2021年5期
李 伟,唐 放,侯博恒,钱 银,崔传智,陆水青山,吴忠维
(1.中海石油(中国)有限公司深圳分公司,广东深圳518067;2.中国石油大学(华东)非常规油气开发教育部重点实验室,山东青岛266580)
我国南海东部海相砂岩油藏具有构造幅度低、储层物性好、天然水体能量充足等特点,大多数油田实现了高速开发,与陆上油田的开发方式存在差异[1],以往针对陆上水驱砂岩油藏的采收率经验公式不再适用于海相砂岩油藏采收率的预测。此外,常见的采收率预测方法包括数值模拟[2]和室内实验[3-4],这些方法往往需要耗费大量的时间和人力,无法快速对油藏采收率进行预测。
近年来,许多学者通过多元线性回归[5-6]、多元非线性回归[7]和支持向量机回归[8]方法,针对海上水驱砂岩油藏开展了采收率经验公式研究。通常这些方法都是基于少量样本建立的预测模型,经过校正后可用于快速预测油藏采收率,但是当样本数量增多时,往往会出现拟合效果降低的情况,导致预测精度下降。因此,为了准确描述复杂的油藏系统中采收率与其影响因素之间的关系,首先针对影响因素进行主成分分析[9-10],避免影响因素之间的相关性,降低数据冗余性,然后运用神经网络回归[11-14]方法,建立适合南海东部海相砂岩油藏的采收率预测模型,以快速评价油藏开发潜力,指导油田生产。
1 神经网络回归原理
神经网络是一个由模仿人脑神经元的节点组成的网络[15],输入数据经过输入层、隐藏层、输出层的仿神经元结构进行训练[16]。神经网络利用权重值(w)模拟神经元的关联,不同输入信号的重要性用权重来表示。神经元节点会接收经过加权处理后的信号并考虑偏置(b),计算得到加权和,权重越大表示信号越重要。神经网络以该方式存储信息,从而迭代调整权重参数以减少误差,最终得到输出目标的预测模型[17-20]。
建立一个多层神经网络模型,首先要将选择的数据样本分为特征数据集和目标数据集,作为输入样本放入输入层后按照一定比例分为训练集、验证集和测试集。然后,设置隐藏神经元的数量和选择训练算法[21]。最后,不断地训练网络,根据数据样本的回归效果,输出符合精度要求的神经网络回归模型(图1)。研究针对的问题是数据的回归分析,因此用于函数拟合的标准网络是一个双层前馈网络,在隐藏层有一个sigmoid 传递函数,在输出层有一个线性传递函数。
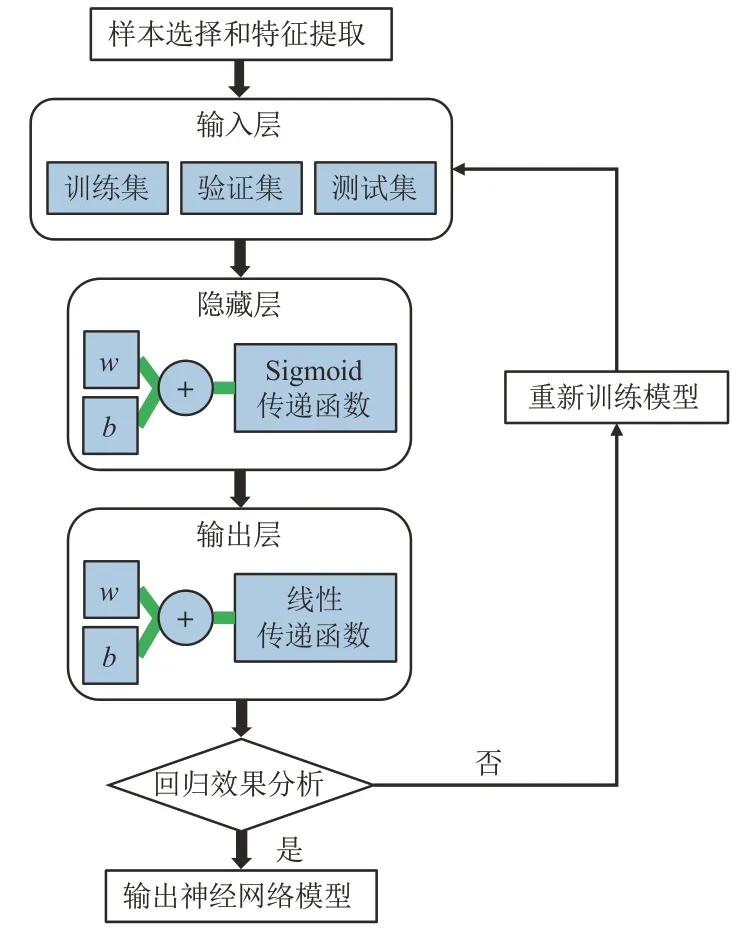
图1 神经网络回归流程Fig.1 Flow chart of neural network regression
2 基于主成分分析法的特征提取
2.1 目标油藏的选取
南海东部已开发的海相砂岩油藏为本次研究对象,该区域油藏的边底水能量强,以天然能量开发为主。通过整理分析实际油田的动、静态资料,优选部分油藏作为神经网络回归的样本。选择样本主要遵循以下原则:①天然能量开发的砂岩油藏;②油藏驱动类型一致;③原油性质相近;④油藏地质特征和开发动态资料准确。
2.2 采收率的影响因素选取
采收率是反映油藏开发潜力的重要指标。研究采收率的影响因素并对采收率进行合理预测将有助于油藏开发潜力评价。采收率的影响因素包括客观因素和可控因素,客观因素一般指油藏的地质参数和流体性质,而可控因素一般指井网密度、采油速度等。
常规的采收率预测方法在实际使用过程中,往往会面临输入参数过少或过多的情况,同时每个输入参数之间可能存在相关性,导致信息重叠,增加了模型的复杂程度,还影响了预测精度。因此,针对采收率的影响因素进行优化分析是模型预测准确的前提。
根据南海东部已开发的海相砂岩油藏的统计资料,选取50个驱动类型为边水的油藏(表1),可获取的采收率影响因素包括:含油面积、油层厚度、孔隙度、含油饱和度、原始地层压力、流度、井网密度、渗透率和地质储量。由于这些参数之间可能存在相互关联,故采用主成分分析法对采收率影响因素进行特征提取,为后续建立采收率预测模型奠定基础。
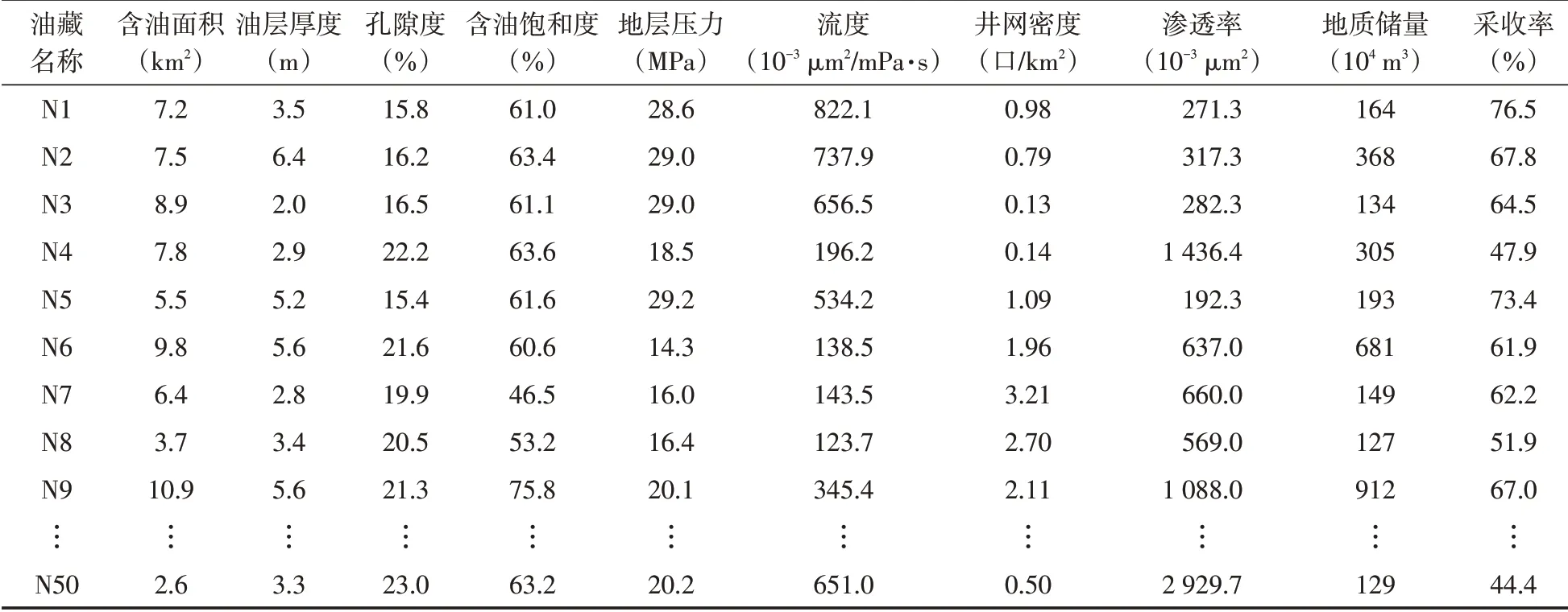
表1 神经网络回归训练样本数据Table 1 Training samples of neural network regression
2.3 主成分分析
由于采收率各个影响因素具有不同的数量级和量纲,故首先需要对特征参数进行标准化处理,以消除数量级和量纲差异可能导致的影响。采用ZScore标准化:

式中:Z为标准化处理后的参数;μ为样本数据的均值;σ为样本数据的标准差;X为样本特征的观测值。
主成分分析(PCA)可以将原来多个特征信息浓缩成几个概括性特征,即降低数据特征的维度并保留原始数据的大部分信息,分析步骤为:
输入经过标准化处理后的n维特征数据集为X={X1,X2,…,Xn},先计算出均值E(X),得到协方差矩阵D(X)。构建出新变量Y为:

Yi是Xi的线性组合,且Y中各成分互不相关。主成分分析相当于一个条件极值问题,应满足:
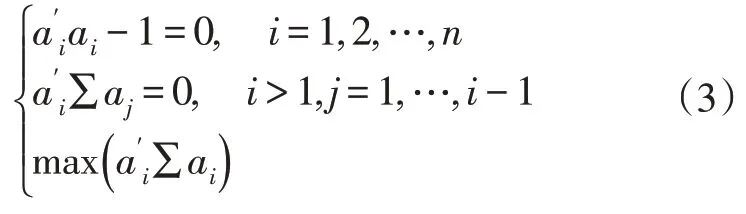
根据式(3),计算协方差矩阵的特征值和特征向量。特征值按大小排序为λ1,λ2,…,λn,ai为λi对应的特征向量。
依据协方差矩阵的特征值大小,选取前k个(k<n)作为主成分。通过方差解释率(或方差贡献率)来表征某一成分包含信息量的大小,其表达式为:
式中:αi为某一主成分的方差解释率;λi为某一主成分的特征值。
k个主成分的累计方差解释率的表达式为:

一般而言,当累积方差解释率大于85%时,就认为大致能反映原始数据的信息。考虑到后续建立采收率预测模型的精度,选取累积方差解释率大于95%的主成分数量。
针对南海东部海相砂岩边水油藏采收率的9 个影响因素进行主成分分析(表2),最终提取得到6个主成分。该6 个主成分方差解释率分别是34.19%,23.84%,17.71%,10.54%,5.23%和4.28%,累积方差解释率为95.79%,说明该6 个主成分可以表达原有9个特征项共计95.79%的信息量。
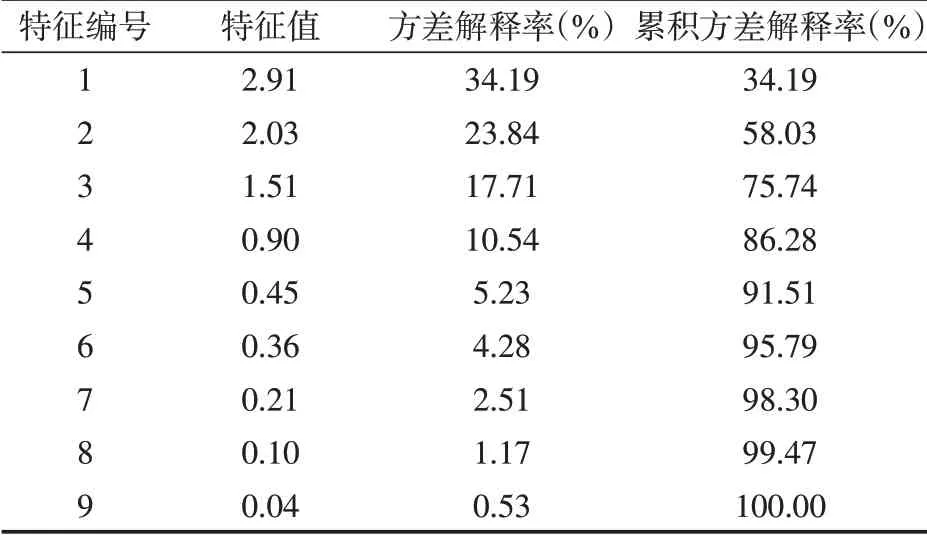
表2 主成分分析结果Table 2 Analysis results of principal component
3 采收率预测及影响因素分析
3.1 采收率预测模型建立
通过利用南海东部50 个边水油藏的实际资料,针对含油面积、油层厚度、孔隙度、含油饱和度、原始地层压力、流度、井网密度、渗透率和地质储量等9个因素进行特征提取,经过主成分分析(PCA)浓缩为6个综合指标作为特征数据集,对应的采收率作为目标数据集。输入样本按照70%、15%和15%分为训练集、验证集和测试集。然后,优化隐藏神经元的数量为10。接着,通过优化训练算法选择Levenberg-Marquardt,该方法更适用于该数据样本的处理。最后,通过反复训练调整网络的权重,得到拟合度理想的神经网络回归模型,见式(6),拟合结果的相关系数为0.936 2(图2),可以看出神经网络回归模型预测采收率的相对误差基本上在15%以内(图中红色实线为45°线,黑色虚线为相对误差15%辅助线)。
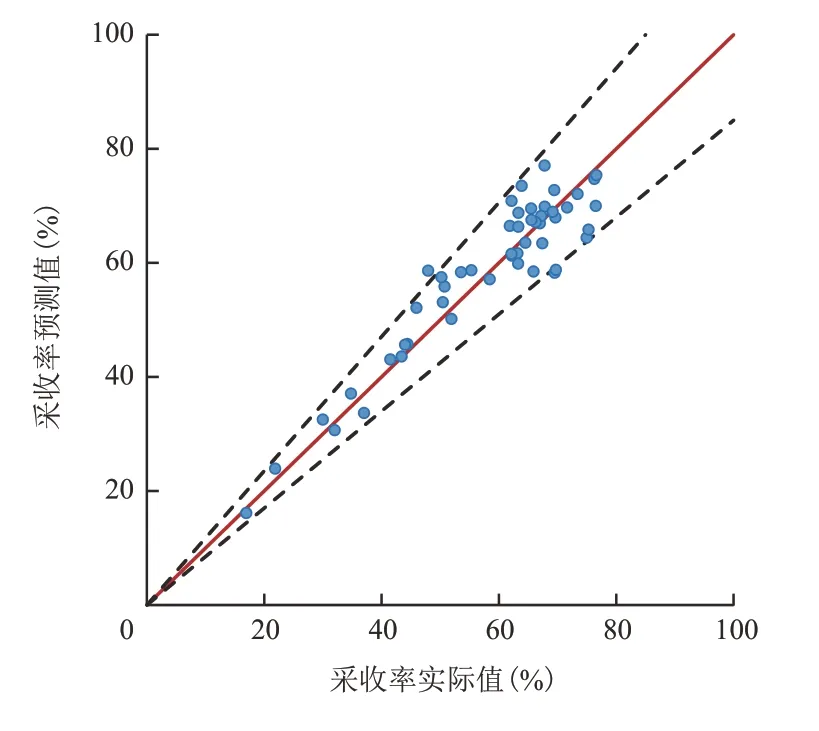
图2 神经网络回归预测采收率拟合Fig.2 Fitting of predicted recovery ratio by neural network regression model
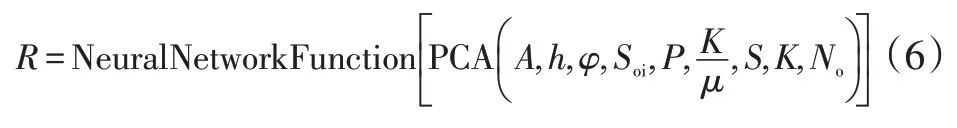
式中:R为采收率,%;A为含油面积km2;h为油层厚度,m;φ为地层孔隙度,%;Soi为原始含油饱和度,%;P为原始地层压力,MPa;K/μ为流度,10-3μm2/mPa·s;S为井网密度,口/km2;K为渗透率,10-3μm2;No为地质储量,104m3。
3.2 模型验证及方法对比
为了更好地对比分析基于神经网络建立采收率预测模型的优越性,笔者还采用了目前常见的支持向量机回归和线性回归两种方法建立了采收率预测模型。
除去表1用于各方法回归的50个边水油藏样本之外,遵循样本选择原则,重新选取了南海东部6 个边水砂岩油藏(表3)作为模型测试样本,分别采用神经网络预测模型、支持向量机回归模型和线性回归模型对测试样本进行采收率预测。
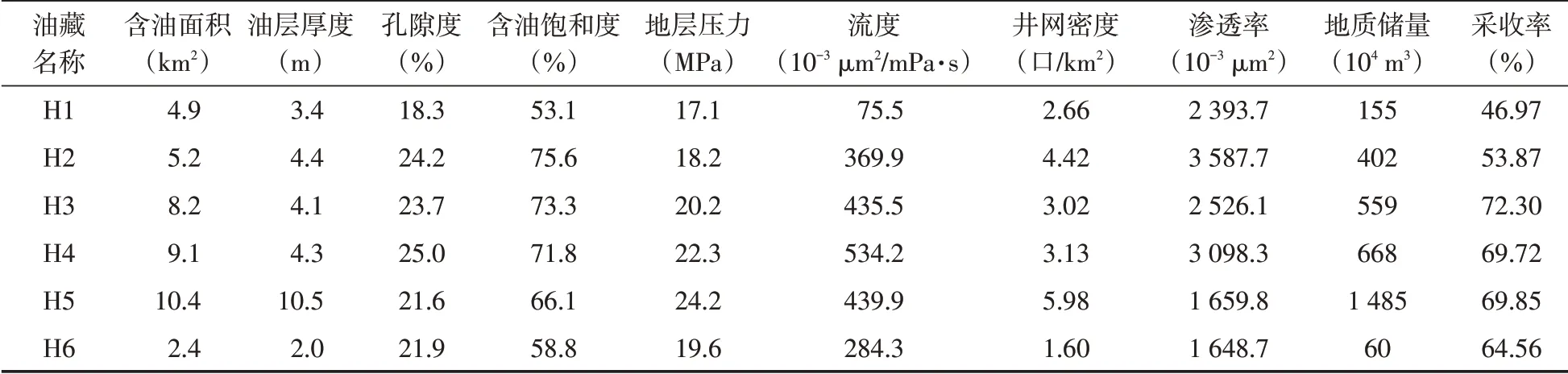
表3 模型测试样本数据Table 3 Model test sample data
由不同模型预测的采收率结果(表4)可以看出,基于神经网络的采收率预测模型计算出的油藏采收率相对误差均低于其他两种方法,表明神经网络模型的预测值更接近实际值,预测精度更高。

表4 不同模型采收率预测结果对比Table 4 Comparison of results predicted by different models
3.3 采收率影响因素分析
基于神经网络预测模型,采用正交试验设计分析影响采收率的主控因素。由于地质储量受含油面积、油层厚度、孔隙度、含油饱和度等因素控制,故分析时不做考虑。根据油藏样本数据中影响因素的变化范围和集中度,确定各因素的水平(表5)。采用L32(49)正交表,共32 组试验,然后利用预测模型计算各组试验的采收率,最后通过方差分析法确定各个因素对南海东部海相砂岩油藏采收率的影响程度(表6)。由结果可知,采收率的主要影响因素为油层厚度、井网密度、流度和渗透率。

表5 影响因素水平Table 5 Influencing factor level

表6 方差分析Table 6 Results of variance analysis
因为南海东部砂岩油藏主要是依靠天然能量开发,所以采收率的可控因素只有井网密度。针对该区域同类型的油藏,可通过神经网络模型快速预测采收率,同时还可以分析井网密度对采收率的影响,并确定一个油藏合适的井网密度。
XJ 油藏是南海东部的一个边水砂岩油藏,其生产过程中主要经历了4次井网加密(图3),井网密度最大为4.1口/km2,油藏采收率为70.86%。利用建立的神经网络模型预测XJ油藏的采收率为75.94%,相对误差为7.17%,并计算了不同井网密度下对应的采收率(图4)。通过对比可以看出,模型预测的采收率在井网密度达到4口/km2后基本保持不变,表明该油藏合适的井网密度约为4口/km2,这与实际情况相符。
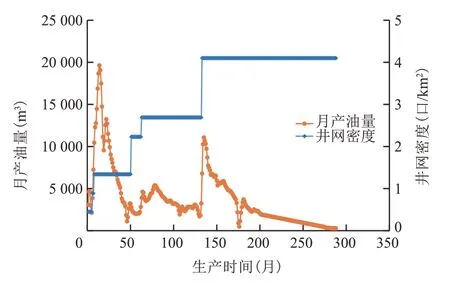
图3 南海东部XJ油藏生产历史曲线Fig.3 Production history curve of XJ reservoir in the eastern South China Sea
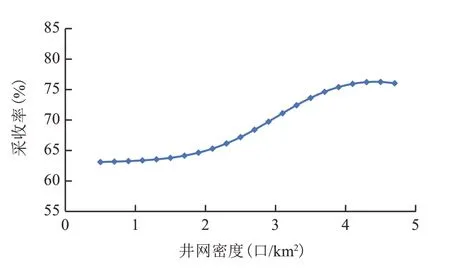
图4 模型预测采收率随井网密度变化关系曲线Fig.4 Relation between recovery ratio predicted by model and well pattern density
4 结论
1)采用主成分分析方法,针对南海东部的边水砂岩油藏采收率的9 个影响因素(含油面积、油层厚度、孔隙度、含油饱和度、原始地层压力、流度、井网密度、渗透率和地质储量)进行特征提取,得到6个概括性指标(即主成分),可解释原始数据95.79%的信息量。
2)基于主成分分析得到的特征数据,运用神经网络回归方法,建立了南海东部砂岩油藏采收率预测模型,与常用的支持向量机回归和线性回归两种方法预测采收率结果相比较,此模型具有更高的预测精度。
3)基于神经网络预测模型,采用正交试验设计得到影响采收率的主控因素为油层厚度、井网密度、流度和渗透率。利用该模型可确定油藏的合理井网密度,从而指导油田生产。
猜你喜欢
矿业工程研究(2022年1期)2022-05-06
新疆地质(2021年1期)2021-04-12
学苑创造·A版(2020年9期)2020-10-13
石油研究(2020年8期)2020-09-07
复杂油气藏(2020年2期)2020-08-31
科学导报·学术(2019年1期)2019-09-10
智富时代(2019年5期)2019-07-05
智富时代(2019年5期)2019-07-05
筑路机械与施工机械化(2019年2期)2019-03-08
建筑工程技术与设计(2015年28期)2015-10-21
