
基于改进的N-gram模型和知识库的文本查错算法
2021-10-15 12:49旷文珍
计算机应用与软件 2021年10期
王 琼 旷文珍 许 丽
1(兰州交通大学自动化与电气工程学院 甘肃 兰州 730070) 2(兰州交通大学研究院甘肃工业交通自动化工程技术研究中心 甘肃 兰州 730070)
0 引 言
随着人工智能发展新时代的到来,语音识别技术已被广泛应用,但在实际应用中,现有的语音识别引擎还存在领域知识不够丰富的问题。面对专业领域对语音识别的特殊要求,研究者们主要对语音识别模型进行了研究,提出一系列的新模型和方法,如:文献[1]提出了基于声学状态似然值得分模型及监督状态模型的语音识别特征融合算法;文献[2]提出了一种基于随机段模型的发音信息集成方法;文献[3]构建了一种基于声学特征空间非线性流形结构新型声学模型;文献[4]对基于隐马尔可夫模型的电力调度语音识别系统进行了研究。也有部分学者从语音识别后文本入手,通过自然语言处理技术进行研究,来提高专业领域内的语音识别率。
目前市场上成熟的语音智能识别软件针对日常用语的识别准确率已取得了不错的效果。但铁路车务系统对行车指挥用语有标准化要求,现有的语音智能识别软件无法满足,识别的错误类型主要有散串错误和同音字错误,其中散串错误是指将词组识别为连续的单字,如将“红光带”识别为“宏光代”。同音字错误又分为两种情况,一种是将正确词组识别为同音异意词,如将“道岔”识别为“刀叉”;还有一种是铁路信号领域内一些字母或数字特殊规定,如“DG”规定发音为“dao gui”,被识别为“捣鬼”。还有部分当行车组织人员使用简略化、地方化用语表述时,造成的识别错误,如“1”发音为“dong”,被识别为“动”。针对以上问题,本文主要完成以下工作:
(1) 构建二元语法模型和三元语法模型实现语音识别后文本散串查错,并对模型中产生的数据稀疏问题,采用Witten-Bell平滑算法解决,同时对平滑后的N-gram模型进行改进。
(2) 构建专业术语查错知识库实现语音识别后文本同音字及特殊规定查错,实现知识库的自动更新,并对错误文本与知识库匹配的算法进行相应的设计。
1 语音识别处理系统框架设计
本文系统在已成熟的语音识别技术基础上增加自然语言处理模块,加入专业领域内的标准化知识库,使系统在识别通用语言的基础上提高专业领域语音识别准确率。系统主要包含四大模块:科大讯飞语音识别引擎模块;中文分词模块,即预处理模块;基于N-gram模型结合专业术语知识库的查错模块;纠错模块。系统结构如图1所示。

图1 语音识别及识别后文本处理结构
为了节省开发时间,系统调用了国内最早研究语音技术也是技术最成熟的开放式科大讯飞语音云平台[5]相应的API接口,将语音识别的任务传递给语音云平台,然后对科大讯飞语音云平台识别后的文本采用中文分词算法进行预处理,为后续的查错提供基础。查错模块主要由专业术语查错知识库和N-gram模型组成。纠错模块通过构建纠错知识库结合相应的纠错算法实现。由于查错作为纠错的基础,查错模型的构建直接影响纠错的结果以及语音识别准确率,本文主要对查错模块进行研究。
2 N-gram模型及查错
n元语法模型(N-gram模型)作为自然处理领域内一种常用的数学建模方法,被广泛应用。如文献[6]利用N-gram模型字接续和词接续关系,同时构建了自动查错知识库进行查错,该算法采用的二元接续关系检查局部字词级错误是有效的,但对于整个文本的查错不足。文献[7]采用一种音素匹配法结合改进了的n元语法模型的方法对语音指令进行理解,利用N-gram模型间接获取未被识别的音素,该方法针对小语料库,为语音识别后文本关键字的提取提供了一种思路。文献[8]设计了一种条件随机场(CRF)和N-gram散串联合的查错模型,该模型只针对字错误查找,对于长距离的错误以及语法、语义级的查错方法有待改进。本文利用N-gram模型对相邻词或字预测能力分别构建二元语法模型(n=2)和三元语法模型(n=3),通过分析词间的N-gram值从而判定识别错误点。下面对N-gram模型构建及查错实现过程进行介绍。
2.1 N-gram模型
对N-gram模型描述为[9]:假设xi为当前将要出现的语言符号(包括字符、词和短语等),则预测xi出现的概率时,需考虑前面曾出现过的若干个语言符号对它的影响,如果只考虑前面出现的n-1个语言符号(xi-n+1xi-n+2…xi-1),则xi的出现概率可由条件概率p(xi|xi-n+1xi-n+2…xi-1)来估计。假设语音识别后文本为s=x1x2…xm,则N-gram模型通过概率分布p(s)来描述s出现的概率,计算式表示为:
p(s)=p(x1)p(x2|x1)…p(xm|x1x2…xm-1)=
(1)
式中:x1x2…xi-1为第i个词的历史。N-gram模型中n值表征当前预测词与前n-1个历史相关,n值越大,模型所反映的句子中词与词的关联越准确。由于铁路车务系统用词大多为两字词和三字词,且识别后文本为短文本,选取n=2和n=3即可满足查错要求,称n=2和n=3时的模型为bi-gram(二元)模型和tri-gram(三元)模型,计算式分别表示为:
(2)
(3)
式中:p(xi|xi-1)为bi-gram概率值;p(xi|xi-2xi-1)为tri-gram概率值;Nfre(xi-1)表示词语xi-1在整篇语音识别后文档中出现的频率,同理Nfre(xi-1xi)、Nfre(xi-2xi-1xi)、Nfre(xi-2xi-1)表示相应词语在整篇语音识别后文档出现的频率。在利用训练语料估计参数模型时,由于只选取所有分词后语料中的部分词作为训练语料,未能完全覆盖语料中所有词,存在数据稀疏问题[10],所以,本系统采用Witten-Bell平滑插值平滑算法解决,即利用低阶的N-gram模型向高阶的N-gram模型插值[11]。平滑后的bi-gram模型、tri-gram模型,计算式分别表示为:
pwb(xi|xi-1)=λxi-1p(xi|xi-1)+(1-λxi-1)pwb(xi)
(4)
(5)
式中:λxi-1为高阶和低阶模型的权重值。本系统采用分段方法,利用先验知识将可能具有相似λxi-1值的语料归结在一起进行训练确定λxi-1的值,最后确定λxi-1为0.7。
2.2 N-gram模型的改进及查错
bi-gram模型为判断相邻两词(字)xi-1和xi是否接续提供了基础。利用bi-gram模型进行查错时,通过判断xi与xi-1的pwb(xi|xi-1)值或xi与xi+1的pwb(xi|xi-1)值是否满足阈值α1,即可判断xi与xi-1或与xi+1接续,从而判断xi是否错误。而对于一些临界词,如“信号机故障”,其中:“信号机”和“故障”的N-gram值都很高;而词间字“机故”作为临界词其N-gram值却很低,但不能认定“机故”就是识别的错误位置。
为了进一步对阈值判定提供依据,本文通过对语音识别错误点xi相邻字的N-gram值分布得到适当的权重值实现对错误点的准确定位。例如,语音识别前文本为“2号道岔扳动至反位,钩锁器加锁”,对词“道岔”识别的结果,是以“2号道岔”计算得到的pwb(xi|xi-1)为主要判定值,还是以“道岔扳动”计算得到的pwb(xi|xi+1)为主要判定值,下面以bi-gram模型为例说明。
若要判断当前词xi是否为识别错误点,通过计算pwb(xi|xi-1)、pwb(xi|xi+1),并加以权重,从而实现错误的准确判定,改进后的模型计算所得值记为P(xi),计算式表示为:
P(xi)=(1-β)Pwb(xi|xi-1)+βPwb(xi|xi+1)
(6)
式中:β用于衡量前词和后词对识别错误点定位的重要程度,通过后续实验部分确定β值。
由于语料中某些词语出现频率较少,如“钩锁器”和“加锁”在5 000条语料中分别只出现了两次,很有可能导致模型错误识别词串,但“钩锁器加锁”几乎同时出现,即共现概率很大,两词具有很强的依赖关系。互信息是一种计算两个随机变量之间共有信息的度量,当两个随机变量相关时,其互信息大于零,互信息越大,结合程度越强,当变量之间不存在依赖关系时,它们的互信息小于零[12]。在利用N-gram模型查错基础上,加入互信息作为二次判别条件,对语料库中单独出现频次低,但共现频次高的词语错误提供了查错依据。
对词(字)与词(字)间互信息的定义为:
(7)
式中:若文档中共有词串M个,则p(xi-1xi)=Nfre(xi-1xi)/M,p(xi-1)=Nfre(xi-1)/M,p(xi)=Nfre(xi)/M。
利用互信息查错时,当两词间的I(xi-1xi)或I(xixi+1)满足阈值α2,则认为xi与xi-1或xi与xi+1结合的程度很大,xi出错的概率很小。利用改进后的N-gram模型和互信息联合查错算法实现步骤如下:
(1) 分别计算pwb(xi|xi-1)、pwb(xi|xi+1),从而得到p(xi)。若p(xi)≥α1,xi无错,转至步骤(5),否则转至步骤(2)。
(2) 计算I(xi-1xi),若I(xi-1xi)≥α2,则xi与xi-1可靠接续,可确定xi无错,转至步骤(5),否则转至步骤(3)。
(3) 计算I(xixi+1),若I(xixi+1)≥α2,则xi与xi+1可靠接续,可确定xi无错,转至步骤(5),否则转至步骤(4)。
(4)xi错误,将xi存储于错误字符数组中,转至步骤(5)。
(5) 检查是否i>length[s],若满足,则查错结束,否则i=i+1,转至步骤(1)。
实验中的α1、α2和β由实验部分确定其具体值。通过改进后N-gram模型和互信息联合查错算法,散串错误基本都可确定。但针对同音词及特殊规定词语识别错误,需构建专业术语查错知识库来实现查错。
3 专业术语查错知识库
语音识别后文本的查错不仅依赖于上下语境,还需要相关专业领域知识融合解决。目前针对特定领域语音识别后处理已经有所研究,如文献[13]通过构建基于全信息语音识别文本常识知识库,构建了语法、语义、语境三层知识库实现了对语音识别后文本的纠错,但该方法需要大量的语料,造成存储和更新语料库的不便。文献[14]构建了语境知识库,并计算了词语语义相似度以及词语与语境核心词的语境关联度,结合词序因素、语义语法知识对识别后文本进行了查错纠错,但纠错算法还需完善,且知识库不够充足。张仰森等[15]提出三层语义搭配知识库,采用“HowNet”抽取词语的义原信息,生成词语-义原搭配知识库,该方法在文本查错召回率和准确率上有了很大的贡献,但所采用的句型较为简单,未考虑语法结构和词语间的语义限制。由于本文系统针对的文本为语音识别后的文本,只是破坏了句子词语间表层的结构,且句子的结构比较固定,因此不需要进行全面的句法分析,只需构建相应的专业术语规则知识库即可查找错误。
3.1 知识库构建
在铁路车务系统中,描述一个对象及其动作采用的句型基本固定,如“D1107次司机,兰州站转换为非常站控,2道停”,句型结构为“名词(n)+动词(v)+状语(adv)”,其中对于车次号“D1107”以及股道名“2道”,这类词准确定位了场景中的对象,需要进行准确识别。并且铁路车务系统车机联控中对个别字母或数字发音有一定的特殊规定如“DG”“D”规定发音为“dao gui(道轨)”“dong(动)”,还有部分数字由于工作人员地方口音等因素造成发音不准确,如“0”“1”“2”和“7”等经常分别发音为“dong(洞)”“yao(幺)”“lia(俩)”和“guai(拐)”等,还有部分同音异意词如“道岔(刀叉)”“扳动(搬动)”“加锁(枷锁)”和“反位(反胃)”等都是需要依靠专业术语查错知识库来实现查错的。
本文从相关网页及现场收集到大量铁路车务标准用语文本数据,由人工录入至铁路车务接发车培训系统采用科大讯飞识别引擎进行语音识别训练,并统计识别后文本已分词后词语出现的频次,形成音似词序列,构成如表1所示的查错知识库结构。

表1 专业术语查错知识库
该查错知识库采用适应关键字的更新原则,在首次语音识别前录入行车组织人员语音信息,进行知识库规则初始化。在进行语音识别过程中由操作人员录入语音,由系统识别为关键字序列,采用似然匹配算法将该序列与标准序列匹配,并对系统进行阈值设定,当匹配率高于一定阈值时自动将误差项更新至专业术语查错知识库中,同时人工可干预评判,从而提高识别速度与准确性。图2为某一场景下的对专业术语查错知识库适应性更新过程。
由于知识库采用适应关键字更新方法,针对车务系统领域内出现的新词可通过提取关键词的方法,由系统识别为关键词后,进行系统知识库训练学习来更新扩展知识。且对于识别后文本若出现同义表达时,可采用上下文词语间的互信息构建词语搭配知识库进行纠检错。由于本文系统主要针对语音识别后文本查错研究,极少词组会被识别为同义词,绝大多数为发音相同,系统识别为同音异义词序列,因此对词语搭配知识库的构建未进行陈述。
3.2 似然匹配法
若w1,w2,…,wn为语音识别文本分词后的的表示,z1,z2,…,zm为专业术语查错知识库中的音似词序列,定义匹配函数为:
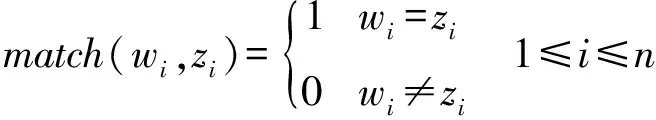
(8)
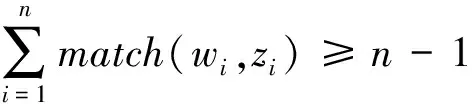
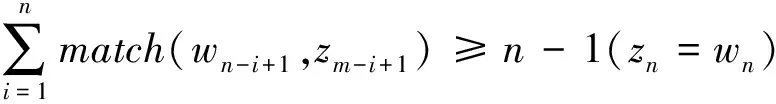
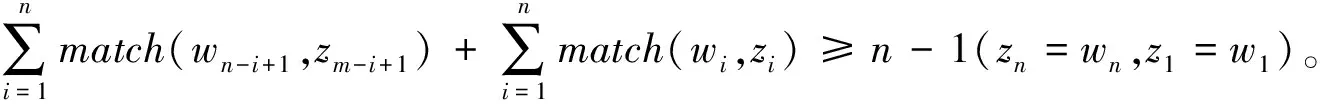
(wn-i+1,zm-i+1)=m(z1=w1,zn=wm)。
则称词串w1,w2,…,wn和词串z1,z2,…,zm似然匹配,若匹配成功,则可确定此处存在错误。
该匹配算法的缺点是只能对语音识别后的错误词串已存入知识库的音似词序列的错误进行定位,若识别后出现错误的词串在训练过程中未出现,未能存入查错知识库的音似词序列,则无法确定该词是否有错。该匹配算法也可作为纠错算法对语音识别错误点进行纠错,可由音似词序列追溯至专业词存储位置并匹配到对应的正确词实现。本文只讨论查错算法,纠错算法将不再赘述。
4 实验与结果分析
4.1 实验参数选取
4.1.1α1的确定
对铁路车务标准用语“5号道岔现场扳动到反位钩锁器加锁”进行分词后得到“5号/道岔/现场/扳动/到/反位/钩锁/器/加锁”,对其bi-gram模型、tri-gram模型的N-gram图仿真如图3所示。
对语音识别后文本经分词后得到“5号/道岔/现场/搬动/到/反胃/勾/索/器/枷锁”,对其bi-gram模型、tri-gram模型的N-gram图仿真如图4所示。
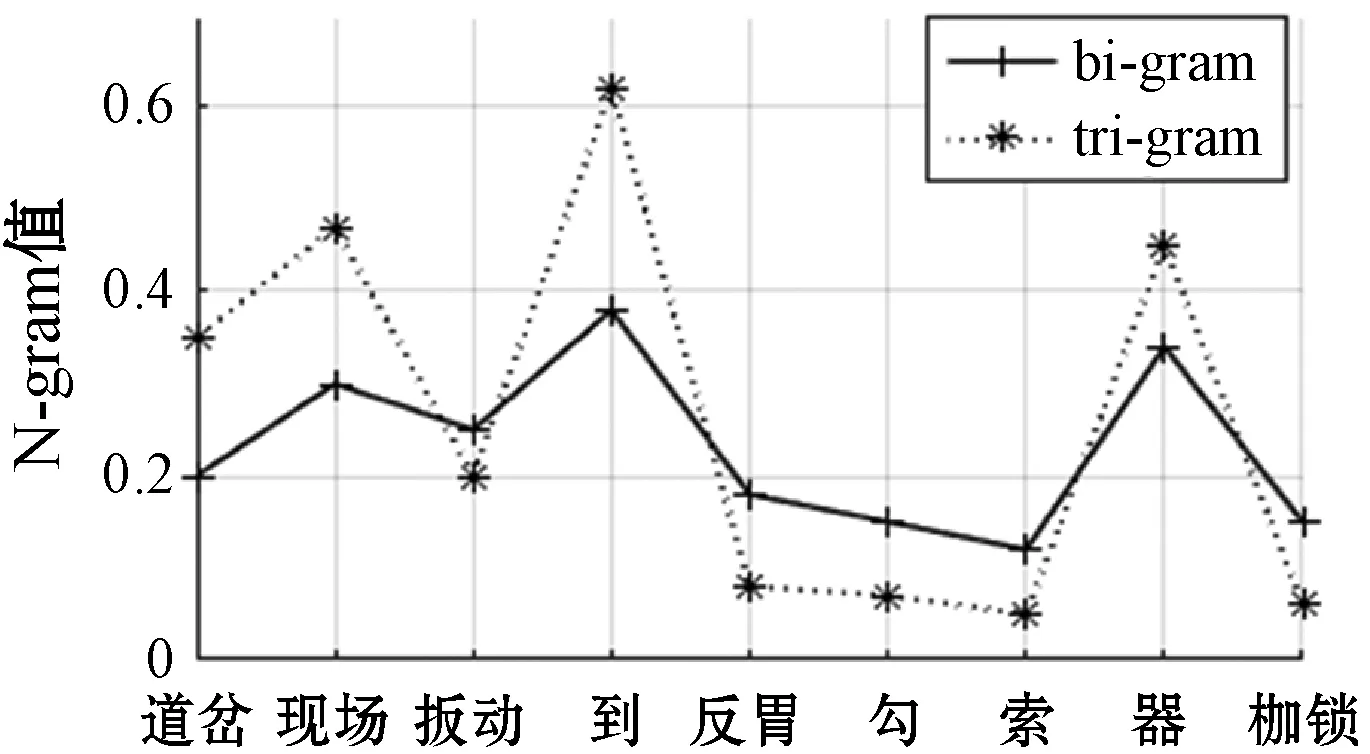
图4 语音识别后文本N-gram图
由图3可得tri-gram模型的N-gram值比bi-gram模型的N-gram值均高出0.2左右,反映语音识别前文本中词与词的紧密关系更加准确。图4中在错误点处tri-gram模型的N-gram值比bi-gram模型的N-gram值均低出0.05左右,显然当n=3时所反映的语音识别后文本中相邻词语的关联度更贴近语义,对语音识别错误点的定位也更准确。因此以图4为基础可得语音识别错误点的N-gram值低于0.1,又选取70条语音识别后已分词文本,共287个词和字,其中错误词组163个,对163个词组仿真得到如图5所示错误词组N-gram值分布图。

图5 错误词组N-gram分布图
由图5可得大部分错误词组N-gram值均低于0.1,只有个别词组的N-gram值高于0.1,该部分词组则是由于同音字或专业术语规定发音造成的识别错误,利用N-gram未能查找出,因此由图5可确定α1为0.1。
4.1.2β的确定
为对α1判定语音识别错误点提供更可靠的依据,分别对语音识别错误点在其对应的语音识别前相邻词(字)的tri-gram概率值和语音识别后相邻词(字)的tri-gram概率值的分布情况进行了仿真,得到了语音识别前相邻字的tri-gram概率值分布图如图6所示,语音识别后相邻字的tri-gram概率值分布图如图7所示。
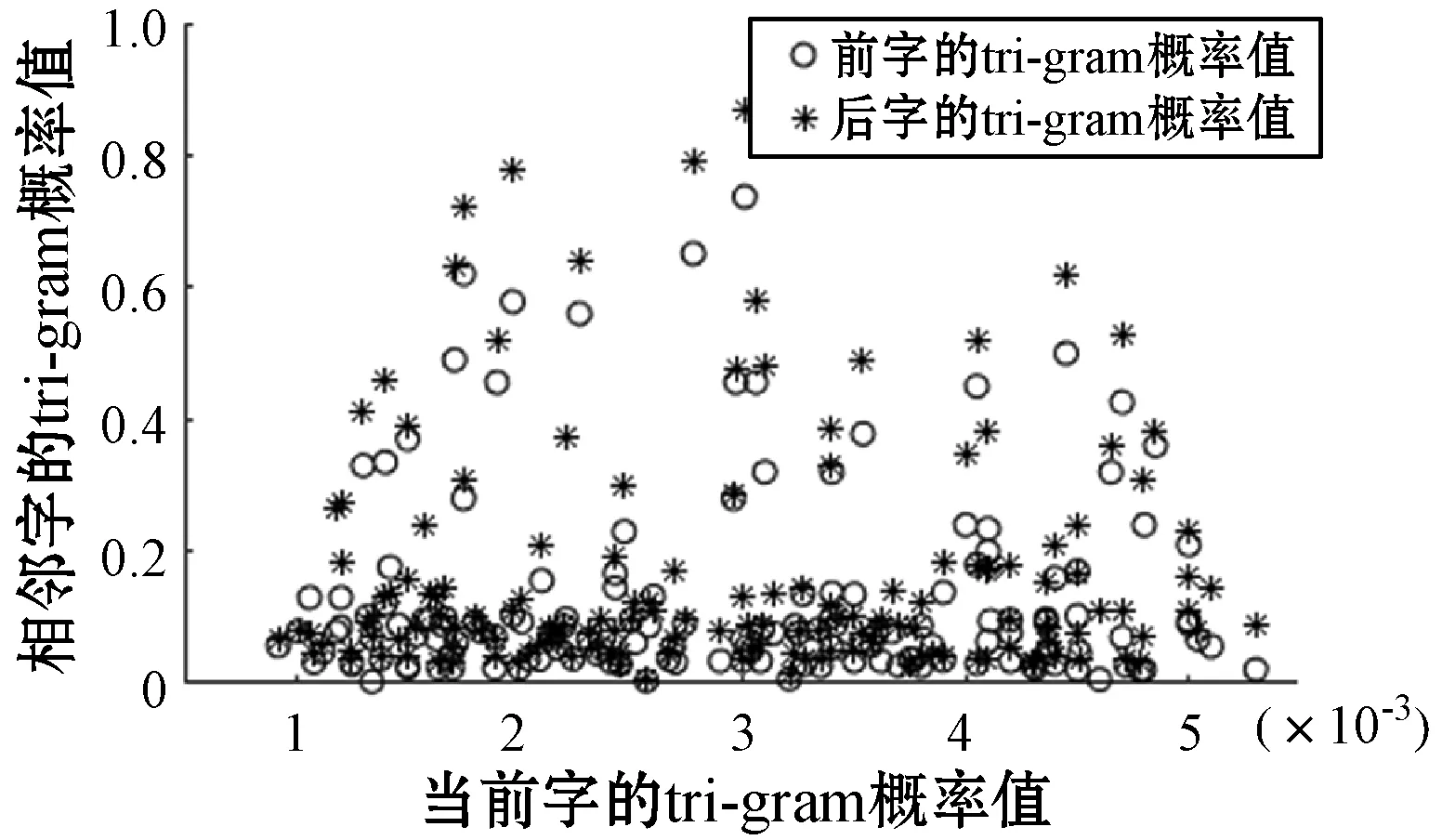
图6 语音识别前相邻字的tri-gram概率值分布图
由图6和图7可得语音识别错误点在其对应的语音识别前相邻词(字)的tri-gram概率值的分布基本一致且相对吻合。语音识别后文本中识别错误点相邻词(字)的tri-gram概率值的区分性较大,后字的tri-gram概率值大部分低于0.1,而前字的tri-gram概率值绝大多数大于0.1。显然后字的tri-gram概率值为α1判定错误点起到的作用更大,因此在对N-gram模型改进中给予后词更大的权重。
为确定β的最优值,通过对70条识别后文本共163个错误词组128个散串错误实验,β=0.8时系统的识别率、召回率及F值均最高,因此取β为0.8。
4.1.3α2的确定
为确定阈值α2,提取测试语料所有词(字)(共2 432个)的互信息值和频次,将其构成2×2 432的矩阵,对矩阵中的数据进行区间化处理。实验表明当区间划分为20等份时,阈值体现的词(字)与词(字)的结合紧密程度越具区分性。因此将2×2 432的矩阵归一化为20×20的矩阵,矩阵中的每个值为互信息和频次在对应区间内的词(字)和词(字)结合出现个数。互信息与频次的密度值对词(字)和词(字)结合出现个数的覆盖趋势如图8所示。

图8 互信息和频次密度对词结合覆盖率趋势
可以看出,互信息和频次密度对词(字)与词(字)的结合覆盖率呈上升趋势,当覆盖率达到8.9%时,其互信息和频次对应的密度值为89,对统计到的语料中出现频率较少的专业词汇基本覆盖,对词(字)的结合具有较大的区分性。将该密度值逆推转化得到互信息对应的区间为[1.5,2.1],因此α2确定为2.1。
4.2 实验结果分析
在实验条件相同情况下,选取800条铁路车务标准用语文本中的400条作为训练文本,400条作为测试文本。由人工录入至铁路车务仿真培训系统,通过统计识别后文本,包含散串错误207个,同音字错误87个,将识别后的文本分别采用文献[6]、文献[7]和文献[8]方法,与本文算法进行实验对比,结果如表2所示。

表2 实验结果对比(%)
相比文献[6],本文算法除利用二元语法模型外加入了三元语法模型和互信息共同进行查错,而文献[6]只利用词间和字间接续关系查错,本文算法所涵盖的文本上下文信息更全面,且对文本中单独出现频次低、共现频次高的词语错误查找更精确;相较文献[7]本文算法召回率提高了45.69百分点,主要原因是文献[7]所构建的数据库是基于领域的指令集,数据库缺乏铁路信号领域知识,导致语音识别后文本中有关领域特殊规定及专业词汇错误未被查找出来;相比文献[8],本文算法通过对N-gram模型改进,增加了N-gram模型对上下文信息的利用,加快了对错误的定位,并使系统的召回率提高了17.69百分点,但对于错误类型没有明确区分,这也是后续需要改进的。
5 结 语
本文对语音识别后文本采用了基于改进的N-gram模型和知识库联合查错方法。首先建立了witten-Bell平滑的N-gram,通过对平滑后的N-gram模型增加后词对当前词查错的权重值,提高了查错的准确率;其次建立了自动更新的专业术语知识库,增强了N-gram模型的领域特征,且采用自动更新知识库的方法,极大地提高了领域内文本的查错率和召回率。因此该算法具有一定的应用价值。
本文采用加权法改进了N-gram模型的同时也增加了模型的复杂度和计算量,并且知识库只针对铁路信号领域中的车务系统用语,应用领域较单一,后续可通过应用外部数据源,从更深的句子结构中挖掘构造知识库。
猜你喜欢
北京大学学报(自然科学版)(2022年1期)2022-02-21
现代计算机(2021年33期)2022-01-21
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
健康人生(2019年4期)2019-10-25
现代商贸工业(2016年22期)2016-12-27
新课程·小学(2016年10期)2016-12-12
——基于与QuestionPoint的对比
新世纪图书馆(2014年11期)2014-02-23
读写算·高年级(2009年3期)2009-11-16
教学与管理(理论版)(2009年9期)2009-11-04
