
自动化测试设备模型化及其排列熵算法应用
2021-10-26 13:15孙卫波
机械制造与自动化 2021年5期
孙卫波
(歌尔股份有限公司,山东 潍坊 261041)
0 引言
作为中国民营企业500强的A股上市企业,歌尔股份在声学设备、光学设备等电子设备生产领域拥有较大产能,特别是近年来在VR、AR、腕带、手表等设备的加工、检测过程中,亟待一种可以有效提升生产良品率的检测方案[1]。
1948年香农提出信息熵概念以来,熵值定律在社会工程学中得到了大量应用,直至今天,各种熵值算法仍然是社会工程学中的最前沿研究课题。从工业工程角度来看,任何企业的良品率不可能达到100%,而良品率的决定因素来自加工生产线的逆熵状态。所以,根据不同生产线的检测结果获得加工体系中的逆熵状态,是对大型电子加工企业良品率检测控制的重要途径[2]。
该研究基于排列熵算法,设计一种针对大型多业务电子加工工厂检测体系的产品质量熵模型,同时设计相关的检测评价体系[3]。
1 排列熵向产品质量熵的算法拓展
如果采用传统的故障树评价模型,将会形成一个规模庞大的传导算法[4],此种算法因为数据不完备且大部分传导函数均采用回归函数,存在较大的误差,无法对企业的实际运行情况作出准确评价[5]。而深入分析电子产品生产线的管理过程,发现劳动密集型工作环境中庞大的员工数量、高新电子加工体系中大量高精度生产设备等,均存在较难克服的熵增压力,系统熵一旦略有提升,就会导致良品率急剧下降[6]。所以,电子产品加工体系必须维持在高复杂度的低熵状态,才可以满足良品率控制需求。电子加工厂的实际产品质量管控过程,即是不断向系统内输入逆熵的过程[7]。
香农提出的信息熵基函数如公式(1)所示。
(1)
式中:pi为第i个节点的熵值;n为系统内的可控制节点量。
假定一个系统中有n个可控制节点,系统的最佳运行状态允许该n个可控制节点存在m种可组合模式,即该n个节点在m种组合模式中,可以产出质量合格的电子产品,一旦其处于其他组合模式下,必然导致加工环节出现问题,导致生产线产出次品。该过程在解析几何中的图形表达模式如图1所示。

图1 排列熵发生值投影图
图1中,在n个控制节点允许m种排列模式下,数据发生情况基本保持正态分布,即当m=n/2时,数据生产概率最大,当m=1或者m=n时,数据生产概率最低。实际企业管理过程中,生产线的n值非常大,如一个生产线拥有60名员工及130台设备,此时的n值至少应控制在190,而此时可用的组合状态,可认为<5,甚至=1。通过现场质量管理,确保复杂系统在少数几个运行状态下,防止出现人员误操作问题,防止出现设备运行故障,这是现场管理的重要目标。图中的概率曲线,即排列熵函数,如公式(2)所示。
(2)
式中数学符号含义如前文。
当前大型计算机无法计算超过100的阶乘,因为超过100的阶乘被看做是无意义大数。n=190时,其结果约为10400,且实际经营过程中,所有人员数量和所有设备数据的和可能≫190,甚至材料因素也应该考虑到排列熵中。因此,公式(2)在实际数据统计过程中并不能直接支持管理数据挖掘需求。所以在此基础上,研究产品质量熵的定义,以期得到可用的数据结果[8]。
从排列熵角度入手,该产品质量熵的实际表现,应为图1中对Y(m)在良品状态域下的线性积分与Y(m)在全值域范围内(m∈[0,n])的线性积分的比值。因为m值必须是正整数,所以该积分过程可以写成累加函数,故产品质量熵根据排列熵函数的写法,应为公式(3):
(3)
式中:b1、b2为生产良品所需的m值;n为生产线的控制点数量;δ为产品质量熵。
2 反算产品质量熵的算法设计
2.1 整体思路
上述分析中,产品质量熵的原理得到直观展示,但其仍然需要计算大数阶乘,所以当前计算计数仍然无法对其进行处理,需要从另外角度,利用产品质量检测大数据在人工智能算法中反推产品质量熵[9]。
前文分析中,产品质量熵是决定良品率的必要条件,即在良品率数据中,可以通过数据深度挖掘,直接获得其产品质量熵的表达情况。歌尔股份的多条生产线,均可以获得良品率数据,这些数据直接反映出上述产品质量熵。即产品质量熵增加,则良品率下降;产品质量熵下降,则良品率上升[10]。
该数据挖掘方法基于神经网络算法,通过对良品率数据的深度迭代回归,反推每条生产线、每个车间以及全公司的产品质量熵数据,进而根据产品质量熵数据,反推公司在人事管理、设备管理、总部工作流程管理等领域存在的问题。即该算法的实际数据需求如图2所示。

图2 神经网络数据需求示意图
图2中,因为歌尔股份的每条生产线、每个车间均构建了完整的良品率检测控制体系,系统可以根据每天核算部门汇总的生产线及车间良品率数据进行统计,使用2层多列神经网络对其进行分析。对良品率的分析过程使用分别独立的卷积神经网络进行数据处理得到生产线或者车间的产品质量熵参考值,进而使用生产线数据卷积模块对所有生产线产品质量熵数据进行二次卷积,使用车间数据卷积模块对车间产品质量熵进行二次卷积。在此两个数据卷积模块之后,构建一个多列神经网络,每一列分别针对人事管理工作、设备管理工作和总部流程进行评价[11]。
该研究发现产品质量熵在良品率数据中有显著表达,虽然其信噪比较低,但可以使用深度迭代回归的神经网络卷积分析,得到其表达参考值,进而利用产品质量熵的实际表现,反推可能引起产品质量熵变化的人事、设备、流程管理条件。
2.2 卷积神经网络与产品质量熵的计算
以歌尔股份为例,公司生产线现场管理中,以天为单位计算生产线的良品率,进而汇总成车间良品率;以周为单位对生产线基层管理者进行绩效考核以及问题训诫;以月为单位进行工资结算和奖惩执行。即如果以30天为周期,采集近30天内生产线的良品率数据,理论上可以控制住整个产品质量变化周期,从而得出较为客观的产品质量熵表达结果。所以,将30天内的良品率数据作为卷积神经网络的输入数据,使用卷积神经网络体系,在多项式节点函数下进行数据卷积,形成1个输出值,该值可以训练为产品质量熵结果。如图2所示,该系统针对每条生产线、每个车间进行单独管理,单独训练,单独应用。
多项式节点函数的基函数如公式(4)所示。
(4)
式中:Xi为前一层次中第i个节点的输入值;Y为节点输出值;j为多项式阶数,此处选择0~5阶多项式进行累加处理;Aj为第j阶多项式的待回归系数,每个节点共6个待回归系数。
针对每个生产线或车间的卷积神经网络共30个输入项,隐藏层4层,分别为23节点、17节点、7节点、3节点,输出层为1个节点,输出一个双精度浮点型变量。
针对所有生产线和所有车间的卷积网络,受制于生产管理架构中的生产线数量和车间数量,不同生产任务条件下的数值变化较多,但可以根据实际生产需求,在软件中控制每层隐藏层的节点量,后一层与前一层相比,不低于前一层节点数的40%。
2.3 多列神经网络与管理控制绩效评价结果的生成
多列神经网络数据来源为前置的生产线数据卷积神经网络模块的输出值和车间数据卷积神经网络模块的输出值,共2个输入值,每一列多列神经网络输出1个输出值。该神经网络的统计学意义并非数据卷积,而是挖掘数据中存在的内在规律,寻求产品质量熵与特定管理模块的管理效果的关系。所以,该神经网络模块首先应该采用对数节点函数进行扩列,采用对数节点函数构建2节点的输入层,进而使用3层隐藏层,分别为3节点、7节点、19节点,节点函数为对数节点函数,进而使用二值化节点函数构建2层隐藏层,分别设计9节点、3节点,最终用二值化节点函数构建输出层。
对数节点函数的基函数如公式(5)所示。
Y=∑(A·logeXi+B)
(5)
二值化节点函数的基函数如公式(6)所示。
Y=∑(A·eXi+B)-1
(6)
式中:Xi为前一层次中第i个节点的输入值;Y为节点输出值;e为自然常数,此处取近似值e=2.718 281;A、B为待回归系数。
3 模型的应用实践与效能验证
3.1 神经网络的训练过程
在Matlab数据分析系统中加载Simulink组件形成神经网络的运行环境,使用歌尔股份2019年~2020年两年的实际ERP数据作为训练数据,包括所有生产线和车间每天的良品率数据,人事部门管理绩效评价数据、设备部门管理绩效评价数据、运营部门管理绩效评价数据。作为中间值,因为各生产线及车间的产品质量熵数据无法直接计算,所以,将良品率数据作为输入值,将绩效评价数据作为输出数据进行直接训练,中间生成的产品质量熵数据作为中间数据管理。
该训练中输入2年共24个月的运行数据,模型收敛后,再使用该系统对2019年和2020年的数据进行试算,最终得到以下训练成果,如表1所示。
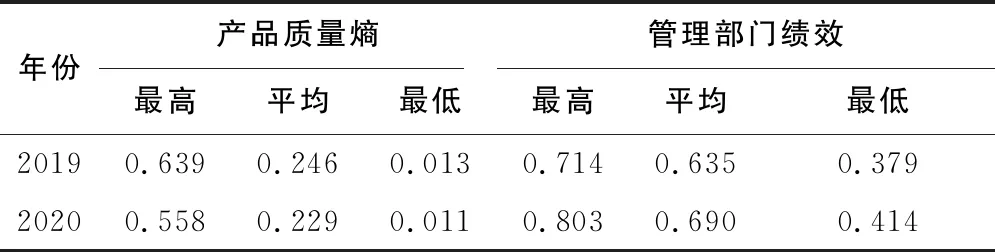
表1 神经网络训练结果表
表1中,2020年较2019年产品质量熵一定程度降低,管理部门绩效一定程度提升。观察两组评价数据,得到图3。

图3 神经网络训练结果投影图
从图3中发现产品质量熵的评价结果与企业绩效评价结果基本呈现逆相关关系,即产品质量熵评价值降低,会给出更高的企业绩效评价结果,认为该系统具有一定的可用性。
3.2 检测设备的模型化与现场应用
歌尔股份使用的检测设备,如VR、AR、腕带、手表等设备生产线的检测设备,均为生产线配套设计的半自动化测试设备。质检员实际操作中,需要将待检测产品置入设备中,设备综合检测后给出质量合格判断结果。部分生产线需要多台测试设备串联进行测试。
该模型应用在歌尔股份全生产体系后,无须对这些检测设备进行拆改,而是采集其并网接口相关数据汇总到集团公司数据中心使用该模型算法进行数据分析。基于该模型的良品率分析系统于2021年1月1日在歌尔股份投入应用,至今已经实现所有生产线的全覆盖。
3.3 算法效能验证
2021年1月1日该系统在歌尔股份投入应用,截至发稿时已经应用3个月时间,判断该系统应用后的良品率结果,如图4所示。图4中,即便在该系统投入应用的第1个月,企业的良品率持续稳定在(98.0±0.05)%左右,2021年2月,企业综合良品率达到98.24%,2021年3月,企业综合良品率达到98.75%,保持了持续提升的趋势。此处企业综合良品率是企业良品产量占全部产量的比值,综合了所有生产线和所有车间的良品率数据。
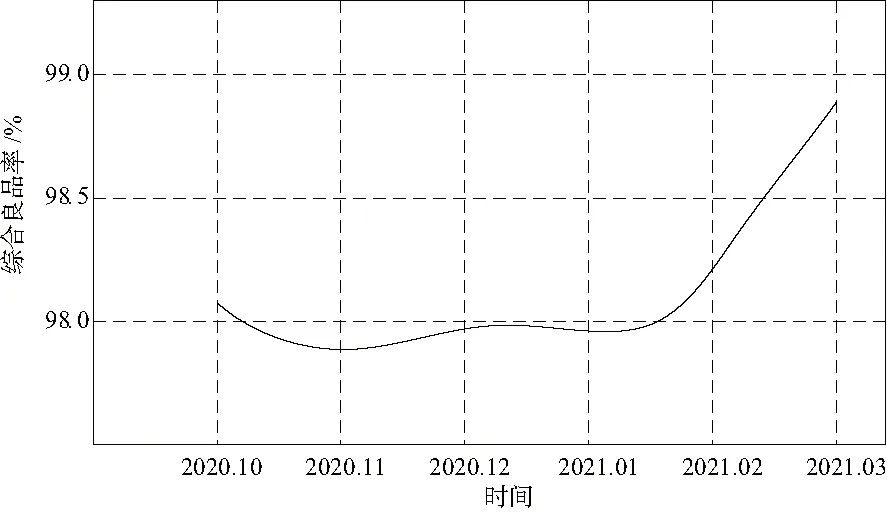
图4 系统应用后对综合良品率的影响
4 结语
综合上述研究发现,企业综合良品率受到企业车间生产线现场管理中的排列熵控制能力影响,但因为当前对排列熵的计算过程,受到当前大型计算机最大算力的制约,无法直接计算。所以该研究通过良品率实际发生值的数据反推产品质量熵(产品质量相关参数的排列熵比值),进而通过产品质量熵的多列神经网络计算企业内的人事、设备、流程管理能力绩效结果。该系统投入应用后,有效促进了歌尔股份的企业综合良品率,且该提升过程在该系统投入应用后,处于持续上升的过程中,未来预期可将歌尔股份的综合良品率提升到99%以上。
猜你喜欢
今日农业(2021年13期)2021-11-26
锻压装备与制造技术(2021年2期)2021-07-19
英才(2019年11期)2019-12-27
中国眼镜科技杂志(2019年9期)2019-11-11
劳动保护(2019年7期)2019-08-27
中国电子报(2019年2期)2019-07-03
英才(2019年12期)2019-02-18
质量技术监督研究(2018年1期)2018-03-26
现代企业文化(2016年1期)2016-12-23
新农业(2016年20期)2016-08-16
