
基于深度学习的微光条件下图像增强算法
2021-11-01 06:29翁子寒
微型电脑应用 2021年10期
翁子寒
(上海儿童医学中心, 上海 200127)
0 引言
手机设备出于便捷性的考量,其镜头模组的光圈通常较小,从而限制了光电子(Photon)的摄入数量,导致在微光条件下会产生低信噪比的图像[1]。因此一直以来,低照度下的camera图像增强技术一直是影像算法中极具挑战性的难题。最直观的增加ISO感光增益可以提高图像的亮度,但同时也会引入噪声[2]。一些图像后处理方法如图像缩放或直方图拉伸,由于低光子数的影响并不能解决低信噪比的问题而且无疑会增加时间复杂度。此外,一些物理手段例如增加曝光时间,增大光圈或者使用闪光灯等方法,虽然可以增加低照度下图像的信噪比,但都有各自的缺点,例如增加曝光时间时,由于相机抖动或者目标移动的影响会造成成像模糊同时也与快速成像的需求违背[3]。
研究者们提出了微光条件下的去噪,去模糊与图像增强等一系列算法。其中一种经典的方法是直方图均衡化[4],它通过改变图像的直方图分布来改变图像各像素的灰度,进而改善欠曝光下的图像对比度;另一种经典的非线性方法是伽马校正(Gamma Correction),它通过对输入图像灰度值进行幂律变换进而校正亮度偏差,最后的结果是增加黑暗区域的亮度而减少了明亮区域的亮度。此后的方法采用更加全局化的分析与处理,例如文献[5]基于小波系数的局部离散性设计了一种非线性增强函数,以统计建模的方式进行图像对比度增强。文献[6]提出的图像增强方法首先估计初始照度,并使用伽马校正以限制照度分量,接下来迭代地进行基于变化(Variation)的最小化来分离反射和光照分量,以恢复使用输入RGB颜色通道的颜色分量。文献[7]通过选取每个像素通道中的最大值初始化该图像光强度图,然后通过引入一种结构化先验方法以细化此初始光照图,最后根据Retinex[8]理论进行最终图像增强。与此前的方法相反,本文研究的是极端低光下的成像,例如在有限的照度(如月光)和短曝光的条件下,传统相机中的图像处理步骤并不能适用,因此必须从原始传感器Raw数据中重建图像。本文提出了一种解决此类问题的算法,即引入大数据驱动的方法来解决极端低光下摄影的问题。具体来说,我们通过训练深度神经网络来学习低照度下原始数据(RAW Data)的图像处理,该端到端方法隐式进行了一系列算法,包括颜色转换、去马赛克、降噪、伽马校正与自动曝光等。同时它也进一步避免了传统图像处理的多步骤机制存在的噪声放大与误差累积问题。据我所知,这是第一次将深度学习中的全卷积神经网络方法应用于微光条件下camera图像增强处理的领域中。
1 基于深度学习的微光条件下camera图像增强算法
1.1 方法介绍
在获取到成像传感器得到的原始Raw数据之后,传统的图像处理方法会应用到一系列模块,如去马赛克(Demosaiking)、白平衡(White Balance)、降噪(Noise Reduction)、图像锐化(Sharpening)、颜色校准(Color Correction)与伽马校正等[10],如图1所示。

图1 传统的低照度图像增强流程图
此外文献[11]提出使用大量的局部(Local)、线性(Linear)和学习(Learning),即3L滤波器来近似成像系统中的复杂非线性步骤,如图2所示。

图2 3L低照度图像增强算法
此后,文献[9]使用合并同曝光多帧的相同RAW图从而得到更加鲁棒的校准,如图3所示。

图3 基于多帧合并算法的低照度图像增强
虽然此前的方法皆取得了一定的成效,但它们的局限性在于通常假设图像是在稍微昏暗的环境和一般的噪音环境中获取的,皆无法处理极低信噪比的低照度下的图像。
本文提出了使用端到端学习的方法直接处理微光条件下的图像。具体来讲,训练了一种端到端的全卷积神经网络(Full Convolutional Neural Network,FCN)以执行此图像处理的步骤。最近的研究表明,FCN可以有效地代替许多图像处理算法[12-14]。受此启发,本文研究了此网络在极端低光成像中的应用。值得注意的是,提出的算法对原始传感器获取到RAW数据进行操作,而不是对传统相机处理管道生成的普通sRGB图像进行操作。
本文方法的阐述,如图4所示。

图4 本文基于深度学习的低照度图像增强方法
对于传感器获取到的拜耳阵列(Bayer Color Array)[15],我们将其压缩到4个通道,相应地将每个维度的空间分辨率降低了2倍。此后为了减少暗电流[16]对图像信号的影响,需要进行黑电平校正(Black Level Correction)[17],即从已获得的图像中减去暗电流信号。然后图像矩阵被输入至深度卷积神经网络当中,输出12通道的图像。最终使用子像素卷积(Sub-pixel Convolution)将图像恢复至原始分辨率。
在网络的选择上,选取了两个全卷积网络作为备选项:多尺寸融合网络与U-Net[18]。之前的如降噪[19],图像超分辨率[20]等工作利用到了近些年在图像识别中被广泛使用的残差网络(ResNet)[21],但是在前期的实验中发现它并不适用于本文的架构,究其原因,可能是输入与输出位于不同的颜色空间中。另一个影响我们选择的是内存消耗问题,因此避免选取带有全连接层的神经网络。综上,选取U-Net作为本文方法的主干网络。
1.2 U-Net
通常卷积神经网络(Convolutional Neural Network, CNN)用于图像分类任务当中,在这类任务当中图像的输出通常为一个简单的类标签。但是在一些其他的视觉任务当中(如图像分割,图像重建等),期望输出还应包括局部信息,也就是说需将图像标签分配给每一个像素,此时全卷积神经网络(Ful Convolutional Neural Network, FCN)[22]应运而生。FCN通过将常规CNN中的全连接层皆替换为卷积层,将通常的池化操作替换为上采样操作,以增加输出的分辨率来获得二维的特征图,同时为了更好地进行局部化(Localization),将来自主干网络的高分辨率特征与上采样相结合。U-Net便是FCN的变体,如图5所示。

图5 本文的主干网络U-Net
2 实验结果及分析
2.1 消融实验
为了证明提出方法的有效性,我们指定了不同的图像模式,并演示了不同损失函数对于结果的影响。消融实验的结果如表1所示。
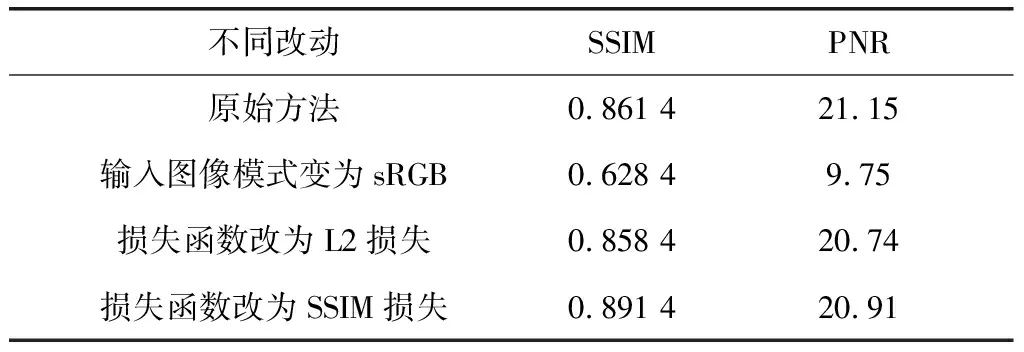
表1 变动不同参数时的性能对比
由表1可以得出以下结论。
(1) 由于大多数现有的传统图像增强方法都是在已经处理过的sRGB图像上进行的。但我们发现,在极端低光条件下,直接对原始传感器获得的RAW数据进行操作更为有效。原因可能是,相对于RGB图像,RAW图保留了原始图像更多的信息。
(2) 本文原始的工作是基于L1损失函数展开的,由表1可以看出,L1优于L2损失函数,同时与SSIM损失函数差别不大,原因可能在于基于像素差值层面的L1损失函数对异常点较为敏感,而SSIM由于其同时考虑了亮度,对比度与结构指标,因此在细节上可能略胜一筹,所以两者各有千秋。
2.2 对比实验
为了进一步验证方法的有效性,将所得结果与其他低照度图像增强方法进行对比。其结果如表2和图6所示。

表2 与其他方法的性能对比


表2列举了本文方法与其他一些图像增强方法关于SSIM与PNR的性能对比。关于表中方法的详细介绍可参见引言部分。可以看到,本文的基于深度学习的低照度图像处理方法在两项指标中皆处于最优。多帧方法虽然在性能上与我们的方法较为接近,但是其缺点是消耗过多内存,因此空间复杂度较高。
图6列举了3L法,多帧合并法与本文方法(从左至右以此排列)的处理结果直观比对(由于代码的不可获取性,因此其他方法的处理结果不能进行展示)。注意3L法重构后得到的图像,其亮度提升的并不明显,图像的椒盐噪声没有得到改善并且整体观感很模糊。相比于前者,多帧合并法处理的结果略胜一筹,但是观感上存在过曝的现象,原因可能在于AEC自动曝光控制的处理阈值设定不过关,另外噪声现象仍然存在。我们的方法可以看到的是整体已重构至相当接近于白天场景下的照片,对细节如毛刺,噪声的处理已相当到位。
3 总结
本文提出了一种基于深度学习的微光条件下图像处理算法以改善传统算法在弱光处理方面的不足。具体来讲,利用LTSITD这一目前已知的最大开源的弱光数据集,通过使用端到端的全卷积神经网络进行训练。实验结果证明了本文方法在噪声抑制和颜色转换等方面的有效性。
猜你喜欢
社会科学动态(2022年2期)2022-02-12
燃气涡轮试验与研究(2021年6期)2021-08-01
海洋信息技术与应用(2020年4期)2021-01-18
绿色建筑(2020年3期)2020-11-23
小资CHIC!ELEGANCE(2019年29期)2019-09-12
中国生物医学工程学报(2019年5期)2019-07-16
小资CHIC!ELEGANCE(2019年14期)2019-05-20
天津诗人(2017年2期)2017-11-29
北京航空航天大学学报(2017年3期)2017-11-23
照明工程学报(2017年3期)2017-07-10
