
基于改进SSD算法的学生课堂行为状态识别
2021-11-01 13:26董琪琪刘剑飞郝禄国曾文彬
计算机工程与设计 2021年10期
董琪琪,刘剑飞+,郝禄国,高 星,曾文彬
(1.河北工业大学 电子信息工程学院,天津 300401; 2.广东工业大学 信息工程学院,广东 广州 510006; 3.广州海昇计算机科技有限公司研发部,广东 广州 510663)
0 引 言
将人工智能引入教学活动,采用深度学习的方法识别学生在课堂上的行为,了解学生的上课状态,对教学改革具有积极意义。在针对行为识别的研究中,无论是使用双流CNNs[1-3]和3D卷积算法[4,5]进行人体行为识别,还是基于人体骨架的行为识别[6]都已经取得显著效果,但是这些方法基本上都需要分析一段完整的视频,识别结果即分类为单个行为标签,使得其计算时间长和训练开销大。将VGG16网络模型迁移到学生课堂行为识别任务中,具有较高的识别精度,但也是将测试图像归为某一类行为[7]。这些方法不能实时检测同一帧图像里多人行为,不适用课堂多位学生同时检测。目标检测Faster R-CNN算法通过基于ZFNet预训练网络模型的迁移学习,实现对学生课堂行为的检测识别分析,取得良好的检测识别效果,可以检测同一帧图像里多人行为,但缺乏实时性[8]。目标检测YOLO算法定位和识别行为状态,可以实时检测从监控摄像机视频数据流中捕获的帧,基于单个帧可得到行为状态标签,但其对远景小目标识别能力欠佳[9-11]。
SSD(single shot MultiBox detector)算法[12]具有检测精度高和实时性好等优势,本文对SSD算法的候选框设计及损失函数进行改进:一方面采用K-means聚类算法统计训练集真实框长宽比,重新设置SSD网络预测层候选框比例及分布,增大候选框与真实框的匹配度;另一方面融合焦点损失函数调节样本权重,解决训练时正负样本及难易分类样本不平衡问题。基于改进SSD算法对智慧教室中举手、睡觉、回答、写字、听讲5类学生课堂行为状态进行识别。
1 原理与方法
图1所示为基于改进的SSD算法的学生课堂行为状态识别的实现流程。由图可见,实现对学生课堂行为状态识别包括3个环节:数据集构建、算法模型训练和学生课堂行为识别。首先是数据集构建。本文采用LabelImg工具标注举手、睡觉、回答、写字、听讲5类学生行为状态;然后,采用基本改进的SSD算法训练学生行为数据集。训练过程中,输入的学生行为状态图片前向传播至SSD网络进行特征提取,不同预测层的候选框与真实框匹配,输出每个候选框类别置信度预测和位置偏移量预测的误差,计算损失反向传播调节对应的权重,直到损失函数降到较小的稳定值,模型训练完成;最后进行学生课堂行为状态的识别。智慧教室录播系统中待检测视频帧输入,通过训练好的参数模型在图像帧上生成一系列检测框,通过非极大值抑制消除冗余框,得到检测学生行为的最佳位置框,进行举手、睡觉、回答、写字、听讲5类学生行为状态识别。
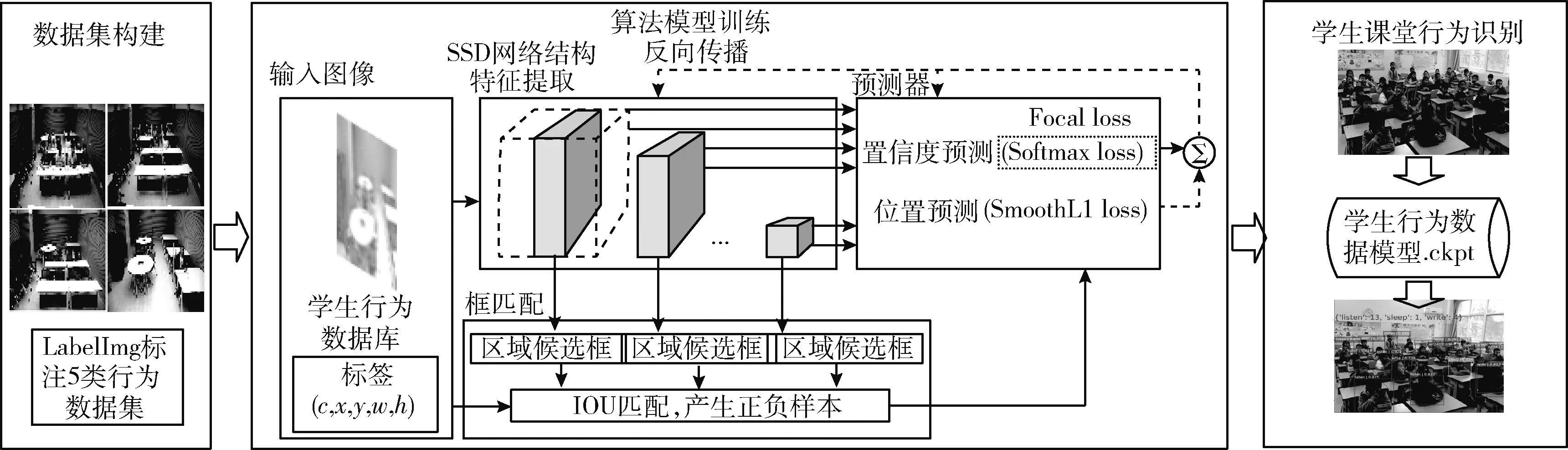
图1 基于改进SSD算法的学生课堂行为状态识别的实现流程
1.1 SSD网络
SSD网络融合不同尺度的特征图进行特征提取,网络结构分为基础网络、金字塔网络两部分。其中,基础网络是VGG-16的前4层网络,金字塔网络由特征图逐渐变小的5个简单卷积网络构成。表1所示为预测层候选框的分布。表中,SSD网络模型中将VGG-16中的Conv4_3层作为特征融合的第一个特征图,特征图大小为38×38,基础网络后新增的卷积网络中选用5个特征层(Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2)作为检测所用的特征融合图,这样共有6个特征层,特征图大小分别为38×38、19×19、10×10、5×5、3×3和1×1,而且每个特征层的特征图设置的候选框数目、大小、比例也不尽相同。

表1 预测层候选框的分布
候选框的大小遵守线性递增规则,如式(1)所示
(1)
其中,m表示特征层个数,Smin和Smax分别表示比例的最小值和最大值,Sk表示第k个候选框相对于图片的比例大小。对于长宽比,一般按式(2)选取5种长宽比
(2)
确定长宽比后,按式(3)计算候选框的宽度与高度,其中sk表示候选框实际尺度
(3)
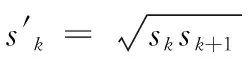
为提高计算速度,且精度不受较大影响,Conv4_3,Conv10_2和Conv11_2层在实现时仅使用4个候选框,没有长宽比为{3,1/3}的候选框。SSD网络最终预测8732个候选框,候选框的比例及分布与SSD算法的特征提取能力密切相关。为提高算法的检测准确率,在不同应用场景,候选框的比例及分布应重新设置。
1.2 学生课堂行为状态识别的候选框设计
SSD算法设置的预选框比例适用于VOC数据集。VOC数据集中20类目标大小不一、种类差异大,目标框大小差距也很大。如果按原先设置的预选框比例训练检测学生行为状态数据集,根据人体形态比例可知其中部分预选框比例并不合理。因此本文预选框的比例根据学生行为状态数据集的训练集来设置。采用K-means在训练集标签框上进行聚类产生合适的候选框使得模型的提取特征能力更强,学习能力更强[13,14]。本文利用K-means聚类算法对自制学生行为状态数据集进行聚类,得到k个聚类中心,再由聚类中心坐标进而得到真实标签框的长宽比。针对学生行为数据集及SSD算法候选框比例的分布,设置参数k=5,最终得到5个聚类中心,K-means聚类过程如下:
步骤1从标注的学生行为状态训练集获取xml文件,读取xml文件,随机选择k个初始聚类中心;
步骤2计算每个标注样本与k个中心各自的欧式距离,然后按最小距离原则被分配至最邻近聚类;
步骤3使用每个聚类中的样本均值作为新的聚类中心;
步骤4重复步骤2、步骤3到聚类中心不再变化;
步骤5最后得到k个聚类结果坐标。
由聚类中心坐标获得学生行为状态数据集标签框的长宽比后,重新设置预测层候选框的分布进行实验对比。
1.3 样本不平衡改进策略

SSD训练时对位置和目标类别进行回归预测,产生的误差损失记为损失函数L(·),可表示为位置误差(locatization loss)与置信度误差(confidence loss)的加权和,如式(4)所示
(4)
其中,N是候选框的正样本数量,即与真实框匹配的候选框数量,Lconf(x,c)为置信度误差,Lloc(x,l,g)为位置误差,x表示默认框与不同类别目标的真实框匹配结果,c表示目标类别置信度预测值,l表示候选框对应边界框的位置预测值,而g为真实框的位置参数,α为衡量位置损失和置信度损失的权重系数,通常设置为1。
位置回归采用的是L1平滑损失函数,目标函数如式(5)所示
(5)
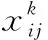
(6)
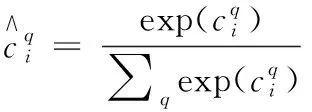
一般目标检测问题可以视为图像分类中的二分类问题,其中二进制分类(binary classification)的交叉熵(CE)损失式(7)如下
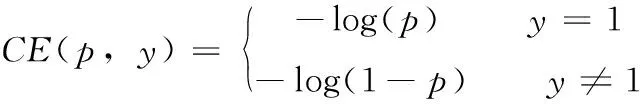
(7)
其中,p表示正样本概率。
在二分类问题中y的值为1或-1,p的范围为[0,1]。为了方便,用正样本概率pt代替概率p,如式(8)所示
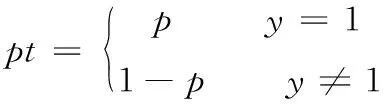
(8)
将式(8)代入式(7)得到交叉熵损失函数,如式(9)所示
CE(p,y)=CE(pt)=-log(pt)
(9)
为使损失函数在样本的迭代过程中优化至最优,引入一个加权因子αt以调整正负样本对总的损失函数的共享权重,αt的范围为[0,1],交叉熵损失函数如式(10)所示
CE(pt)=-αtlog(pt)
(10)
交叉熵损失函数可以控制正负样本的权重,但是无法控制容易分类和难分类样本的权重,于是引入了Focal loss,如式(11)所示
FL(pt)=-(1-pt)γlog(pt)
(11)
其中,γ为焦点参数,γ≥0,(1-pt)γ称为调制系数。
图2所示为Focal loss函数曲线图。由图可知,对于目标检测Focal loss,当目标对象被错误分类且pt很小时,调制系数趋于1,近似等于原来的损失函数。反之,当pt趋于1时,样本分类正确,调制系数趋于0,对总的损失函数影响很小,可忽略不计。Focal loss函数通过调制系数调节样本权重,易分类样本的权重减少,在训练时网络模型更着重于难分类的样本。当γ=0时,Focal loss即为传统的交叉熵损失,当γ增大时,调制系数也会增大。
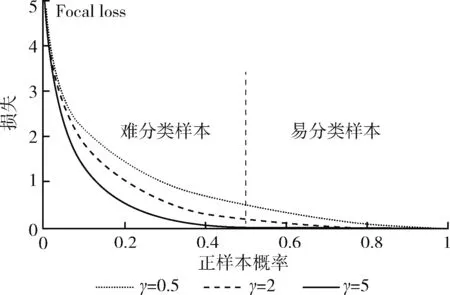
图2 Focal loss曲线
Focal loss融合交叉熵函数,损失函数如式(12)所示
L(pt)=-αt(1-pt)γlog(pt)
(12)
于是,将原SSD算法中类别回归的softmax损失函数(见式(6))代入式(12),作为SSD算法中新的置信度损失。如式(13)所示
(13)
训练时设置参数αt=0.25,γ=2。
2 实验与结果分析
2.1 课堂学生行为状态数据集制作
目前公开的数据集没有课堂学生上课动作的数据信息,针对学生课堂行为类别分析的数据库需要自行建立。根据需求将学生行为状态数据集类别分为5大类:听讲、举手、回答、睡觉及写字。数据集图片用脚本隔帧处理智慧教室录播视频,挑选学生行为特征明显的图片。为达到较好的泛化性能,具备良好的鲁棒性,数据集包括所有学生动作特征,且学生动作特征明显。数据集图片中有学生单人和多人的变化,学生穿着和发型的变化,学生目标大小和远近的变化,课桌的位置和角度变化,学生排座和动作类别的变化。剔除动作特征变化不明显、前后变化小的图片后,用LabelImg工具,通过人工标注的方式,一张图片生成一个xml文件,生成的xml文件包含标签类别(hand,write,answer,listen,sleep),真实框的坐标信息和图片的名称,一共记录了12 279张标签。自制学生行为状态数据集可为后续的智慧教室自动教学分析提供数据来源。

表2 学生行为状态数据集各类别数量
2.2 网络模型评价指标
SSD算法网络模型性能最常用的评价指标就是平均精度均值(mean average precision,mAP),如式(14)所示
(14)
其中,j是类别,共有J类,aveP(j)是网络模型对于第j类的准确率的平均值。mAP是训练模型对于测试集中每一类的平均准确率的平均值,代表了训练模型在整个数据集上的所有类别的准确率和召回率的综合评估值。图像处理中衡量算法效率的常用指标,可用FPS(frames per second)表示,即每秒处理图像帧的数量。
2.3 实验结果及分析
实验环境:服务器上硬件环境配备NVIDIA GTX1080ti显卡,显存大小11 GB,软件环境为Ubuntu16.04操作系统、深度学习开源框架TensorFlow、用于科学计算的Python发行版Anaconda3、显卡并行计算架构CUDA、针对神经网络运算的GPU加速库cu DNN等。训练时初始化学习率为0.001,每隔两个周期下降到之前的0.94倍,梯度更新采用Adam优化器,动量因子为0.9,每次迭代训练50 000次结束。
在相同的环境设置下,YOLO算法和SSD算法在自制学生行为数据集上的测试结果在表5可见,SSD算法对5类行为状态的识别的平均准确率比YOLO算法高9.8%,却也降低了检测效率。本文在保证实时检测的同时,致力于提高检测精度,接下来在候选框分布及引入Focal loss做了以下几组对比实验。
2.3.1 候选框分布实验
学生行为状态数据集中训练集通过K-means聚类后,得到样本宽高比见表3。
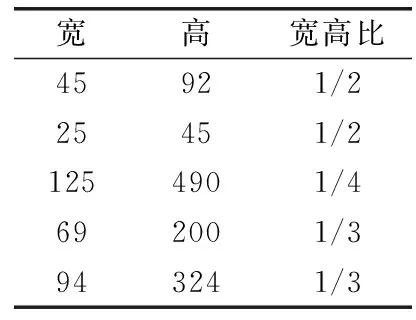
表3 聚类后的宽高比
为了研究候选框比例对及分布对实验结果的影响,根据表1中SSD算法的候选框数量分布及K-means聚类中心的结果,进行了以下两组实验对比。
表4所示为改进SSD算法各预测层候选框比例设置。表中,把SSD模型中conv4_3预测层中长宽比为1的区域候选框替换为长宽比为1/4的区域候选框,此模型记作SSD_change1。而把SSD网络模型中各个预测层中的长宽比为1的区域候选框都替换为长宽比为1/4的区域候选框,则模型记为SSD_change2。

表4 改进SSD算法各预测层候选框比例设置
表5为各模型在课堂学生行为状态数据集上的测试结果。由表可知,在相同的训练参数条件下,SSD_change1模型检测性能比原SSD模型的mAP提高了5.9%,而SSD_change2模型比原SSD模型准确率提高了7.6%,且比SSD_change1提高了1.7%。由此说明按照学生行为状态数据集聚类分析结果设置候选框长宽比及分布,增大了训练时候选框与真实框的匹配度,减小噪声,测试准确率得到提高。在实践中,根据不同的数据集设计预选框的比例及分布有重要意义。
2.3.2 平衡样本实验
在重新设置候选框分布的基础上,引入Focal loss损失函数,在课堂学生行为状态数据集上实验结果见表5。
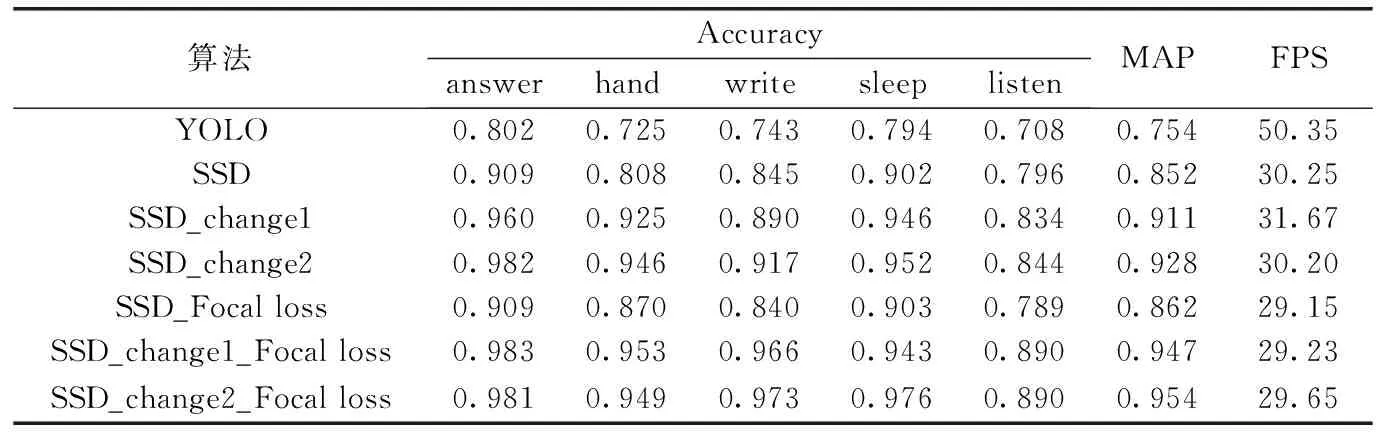
表5 各模型在课堂学生行为状态数据集上测试结果
由表5可见,SSD算法在引入Focal loss以后准确率为0.862,比原SSD提高了1%。说明通过Focal loss调制系数调节正负样本权重及难易样本权重,减小了对损失和计算的梯度产生负面影响,因此识别精度均值有提高。进一步将Focal loss引入SSD_change1和SSD_change2中,则mAP较SSD_change1和SSD_change2分别提高了3.6%和2.6%。特别是SSD_change2_Focal loss对行为状态识别的mAP达到95.4%。由此说明,在重新设置候选框分布并引入Focal loss损失函数后,网络模型的性能得到明显提升。同时,由FPS指标可知该算法每秒可以检测29帧图像,因此可以实时检测学生课堂行为状态。
由于映射数据集的不完备性和算法精度限制,在智慧教室实时检测学生行为过程中不可避免地存在误检和漏检。表6所示为SSD_change2_Focal loss在学生行为状态测试集上误检和漏检结果。由表可见,采用改进SSD算法SSD_change2_Focal loss模型对学生课堂行为状态识别,在测试集上测试的结果误检率和漏检率分别为0.45%和0.24%,这一结果对利用该数据进行教学效果分析的影响可以忽略不计。
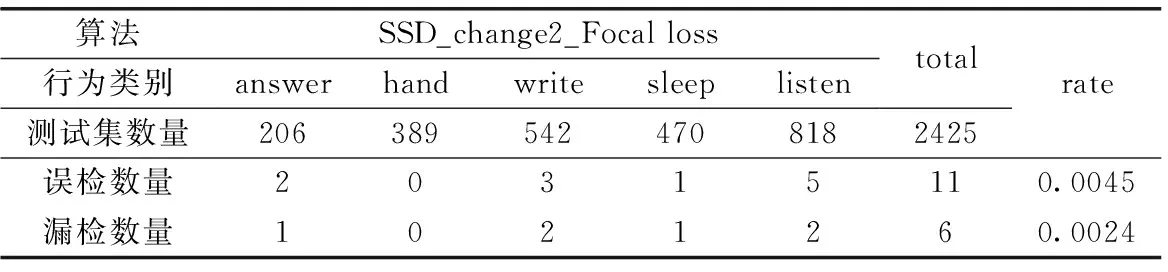
表6 SSD_change2_Focal loss在学生行为状态测试集上误检和漏检结果
2.3.3 智慧教室检测结果
用测试集检测模型性能时,仅用一块GPU时检测帧率在表5中可查。可以看出几种模型检测识别速率差别很小,而且常见的视频流一般都是每秒25帧图像,可以进行实时检测。图3所示为智慧教室实时检测效果图。采用SSD_change2_Focal loss网络模型实时检测智慧录播系统中视频数据流中的学生课堂行为,并设置程序将检测结果图像帧自动保存,由图可见该方法能够同时准确定位、识别多位学生听讲、写字、睡觉、回答、举手5类学生课堂行为状态。

图3 在智慧教室实时检测效果
3 结束语
本文基于改进的SSD目标检测算法进行智慧教室学生课堂行为状态的识别,根据自制的学生行为状态数据集重新设置候选框比例和分布,增大训练时的匹配度,并引入Focal loss调节训练时数据类别及正负样本的不平衡,以此减小训练时的误差,提高生成网络模型的准确率,实现了在不降低 SSD 检测效率的同时提高检测精度,实时并准确检测学生听讲、写字、睡觉、回答、举手5种动作,识别准确率达到95.4%。需要指出的是,尽管目前改进算法对于特征明显的行为状态识别准确率很高,但在实际应用环境中对于特征复杂或状态组合的学生行为识别准确率有待进一步研究。另外,在后续的研究中除了可以得到学生课堂动作的类别,还可以将定位的学生位置坐标信息与人脸识别结合,实现智慧教室中学生身份识别与其上课行为状态的一一对应。
猜你喜欢
光学精密工程(2022年13期)2022-08-02
计算机工程与应用(2022年1期)2022-01-22
计算机工程与科学(2021年4期)2021-05-11
中学生数理化·高一版(2021年2期)2021-03-19
铁道通信信号(2019年6期)2019-10-08
知识经济·中国直销(2018年8期)2018-08-23
火力与指挥控制(2018年3期)2018-04-19
雷达学报(2017年6期)2017-03-26
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
