
基于深度学习算法的机器自动翻译质量评估模型
2021-11-10 05:27胡仁青
电子设计工程 2021年21期
胡仁青
(西安交通工程学院公共课部,陕西西安710300)
目前,翻译产品开发人员需要评估翻译产品的机器自动翻译质量,分析翻译产品的使用效果;用户需要了解哪个翻译产品的机器自动翻译质量优秀,以此决定自己需要使用哪个翻译产品[1-2]。所以,评估机器自动翻译质量具有十分显著的意义。
目前,所有翻译产品的评估都围绕着某个固定标准来评价产品的某种属性,评价机器自动翻译质量的优劣不存在固定的评估标准,所以,高精度评估机器自动翻译质量存在一定难度。目前,诸多学者对评估机器自动翻译质量进行了一定研究,例如,吉奕卫[3]为解决机器翻译处理汉语被动语态的问题,以谷歌翻译和有道翻译译文为例,评估了汉语被动语态的机器翻译译文质量;孙逸群[4]为对翻译软件进行全面评估并比较其各项指标的具体差异,研究了基于问卷与数据分析的机器翻译质量评价方法;贺文照等人[5]以谷歌机器翻译为例对英语关系从句机译汉语进行了评价。尽管以上学者对评估机器自动翻译质量进行了一定研究,但仍可以发现,目前的部分评估机器自动翻译质量方法存在精度较低的问题,为了有效解决这一问题,文中引入了BP 神经网络算法这一深度学习算法。
深度学习算法中的BP 神经网络算法能够以学习训练机器自动化翻译译文中双语词的形式,完成对机器翻译译文语言向量特征的高精度提取,且能够实现机器自动翻译译文语义质量的高精度评价。为此,文中利用BP 神经网络算法构建一种基于深度学习算法的机器自动翻译质量评估模型,在特征提取、质量评估两个步骤中均使用深度学习算法,实现机器自动翻译后语言特征的高精度提取、译文质量的高精度评估。
1 机器自动翻译质量评估模型
1.1 自动翻译语言信息提取
设置机器自动翻译质量为超参数,并以两种语言为例,使用基于深度学习的机器自动翻译语言信息提取方法,将两类语言信息相融。在基于深度学习的机器自动翻译语言信息提取方法中,学习训练阶段由无监督学习阶段与有监督学习阶段构成。无监督学习阶段主要通过降噪自动编码机同时对双语词进行学习训练,得到翻译前后两种自然语言的双语语义特征。有监督学习阶段把自然语言语料的标准信息导进双语词中,实现两种自然语言的双语语义特征微调,优化语言向量特征提取效果[6]。
1.1.1 无监督学习阶段
无监督学习阶段中的学习对象为需翻译自然语言A 的训练语料、自然语言翻译结果B,自然语言翻译结果B 属于和自然语言A 存在差异的自然语言。无监督学习阶段的学习示意图如图1所示。训练机器自动翻译样例y的A 向量YE与B 向量YC,能够获取机器自动翻译样例y中双语对齐的样例对(YE,YC),其表示双语词。使用降噪自动编码机对双语词实施无监督学习,重构获取样例y中的A 向量、B 向量。针对样例y中的B 向量而言,需要重构此样例的自然语言A 向量、自然语言B 向量,获取机器自动翻译样例中的语言向量特征[7-9]。
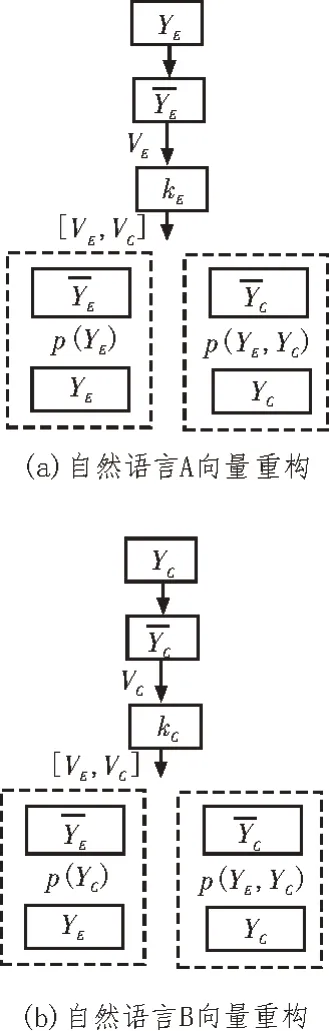
图1 无监督学习阶段的学习示意图
为了优化无监督学习的可靠性,使用降噪自动编码机对双语词实施无监督学习,在重构样例y中的A 向量、B 向量之前,向样例对(YE,YC)导入一定程度的噪声。样例对(YE,YC)导进噪声后的向量为降噪自动编码机作为两种语言的编码器,可通过sigmoid 激活函数编码获取自然语言A 与自然语言翻译结果B 的隐式表达kE、kC,为:

其中,gθ与r分别是编码函数和sigmoid 激活函数;A 与B 互相变换的翻译矩阵参数分别为VE、VC,VE、VC是具有各自语言特征的双语词;因为kE、kC的维度不存在差异,所以自然语言A 与自然语言B 的编码器共享一种偏移值β。
得到kE、kC后,使用降噪自动编码机依次对两类语言的隐式表达进行解码[10-12]。针对自然语言A 的隐式表达kE而言,文中对自然语言A 与自然语言翻译结果B 的两种解码器实施解码:将kE依次解码成自然语言A 的重构向量与自然语言翻译结果B 的重构向量:
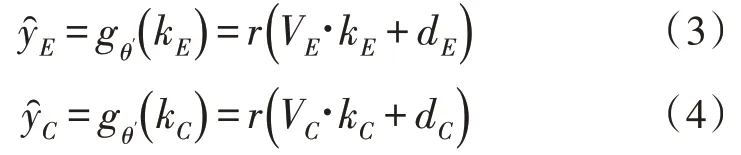
其中,gθ′是解码函数;dE、dC为两种自然语言的解码器偏移量。
隐式表达kC的解码步骤和隐式表达kE的解码方法不存在显著差异,解码kC可获取,解码kE可获取。
此类编码、解码的形式能够让一种语言的输入向量重构至自己原始语言的向量,也能够将其重构成其他语言的向量[13]。但是两种自然语言间的信息并不相同,重构时具有重构误差。针对设置的输入样例对(YE,YC),文中将重构误差设成交叉熵的模式,将下述5 类重构误差的和设成无监督学习阶段的损失函数:
1)YE重构成翻译前的语言向量间误差是p(YE)。
2)YC重构成原向量的误差是p(YC)。
3)YE重构成翻译前的语言向量YC的误差是p(YE,YC)。
4)YC重构成翻译前的语言向量YE的误差是p(YC,YE)。
5)两种自然语言向量对(YE,YC)重构成原始(翻译前)向量对的误差是损失函数O为:

在无监督阶段中,设定无监督学习的解码函数为gθ′={VE,VC,dE,dC},使用梯度下降算法更新解码函数gθ′,使损失函数O达到最小值,训练得到VE、VC。
1.1.2 有监督学习阶段
有监督学习阶段可降低自然语言重构误差。两种自然语言向量对(YE,YC)在y中具有两类语言的全部信息,所以文中将自然语言A、自然语言B 的向量对(YE,YC)使用翻译变换矩阵(VE,VC)进行实时编码,获取隐式表达kβ,kβ中存在此样例的双语信息。

其中,β是编码器的偏移值。
通过kβ运算样例的正例、负例概率为:

其中,ϕ表示权重;Q1、Q2依次是正例、负例概率。
通过有监督学习,能够获取嵌入翻译信息的变换翻译矩阵VE、VC,它们均有属于语言特征的双语词,从而优化自然语言向量特征提取的效果。
1.2 基于深度学习的译文质量评估模型
基于深度学习的译文质量评估模型由1 个可视层、3 个隐藏层、1 个回归层构成,可视层的输入是1.1.1 节中获取的VE、VC。隐藏层的节点数目都是100,3 个隐藏层依次描述为t1、t2、t3。回归层即为输出层,节点数是1。可视层与隐藏层的联合概率分布是:

其中,Q(t1)、Q(t2)、Q(t3)分别是3 个隐藏层的语言变量分别满足翻译需求的概率。
基于深度学习的译文质量评估模型的评估步骤是:
1)在深度学习网络中,从上到下实施无监督训练,将各层均设成一个限制玻尔兹曼机,使用贪婪学习法训练各层权重,从下往上分层训练。首层与其他层分别建模成高斯-二进制的限制玻尔兹曼机、二进制-二进制的限制玻尔兹曼机[14]。在限制玻尔兹曼机中,各个可视节点与隐藏节点间不具有连接性,其条件概率分布θ1与联合概率分布θ2为:

式中,M()、logistic()分别是高斯密度函数与逻辑函数;可视层uj的偏置是fj;t1表示隐藏层节点数是1;j=1,2,3;ε表示标准差。
2)有监督的微调。输出层按照所输入的具有各自语言特征的有监督双语词VE、VC实行整体微调。
3)回归。通过无监督训练与有监督学习能够获取每层的权值与偏置,构建输出译文特征的回归模型,使用该模型对机器自动翻译指令实施评估[15]。模型为:

其中,Ω为机器自动翻译质量评估结果。
2 仿真实验
2.1 模型有效性分析
该模型的数据集为某新闻网站的语句,且以中国翻译协会制定的《翻译服务规范第1 部分:笔译》(GB/T 19363. 1-2003)为评价指标标准[16]。使用提出模型对训练某新闻网站的语句实施翻译质量评估,该新闻语句详情如图2所示。

图2 新闻语句详情
如图2所示,新闻语句经机器自动翻译完毕后,使用提出模型进行译文质量评估,评估过程中多种语言的训练集及测试集的翻译语句都是5 000 个。语句类型都为从属复合句。各种译文类型的翻译详情如图3所示。

图3 译文翻译详情
测试提出模型对机器自动翻译质量评估有效性时,测试指标设成评估结果与实际情况的差值。提出模型的评估结果如图4所示。对比图3与图4可知,在提出模型评估下,机器自动翻译正确语句的数量与实际数量间的差值都是1 个,原因是每种语言都具有各自独特的语法结构,在此前提下,提出模型评估结果符合现实使用需求,可有效评估机器自动翻译的质量。

图4 提出模型评估结果
2.2 翻译句型对提出模型评估性能的影响
设置机器自动翻译的语句类型分别是陈述句、特殊用法句、疑问句、并列复合句,以测试提出模型评估机器自动翻译的翻译质量,结果如图5、图6所示。分析图5、图6可知,在不同语言与不同翻译句型下,提出模型的评估结果和实际情况的差异较小,仅特殊用法句翻译质量的评估结果存在差值,但差值较小,为1 个。陈述句、疑问句、并列复合句对提出模型的评估效果无影响,评估结果和实际情况一致。

图5 陈述句与特殊用法句的翻译质量

图6 疑问句与并列复合句的翻译质量
2.3 语句数量对提出模型评估性能的影响
双语评估候补(Bilingual Evaluation Understudy,BLEU)分数:对于一个给定的句子,有实际翻译质量信息A1,还有一个提出模型评估的结果A2,对于A2而言,判断提出模型评估结果A2 中具有多少正确评估结果出现在A1 中,此比率即为BLEU 分数。BLEU分数可对测试集中的单个句子翻译错误进行求和,判断提出模型的评估性能,结果如图7所示。分析图7可知,语句数量对提出模型评估性能不存在显著影响,语句数量由1 000 个增加至6 000 个时,提出模型的BLEU 分数由96 分增加至98 分,结果表明提出模型的使用性能较好。
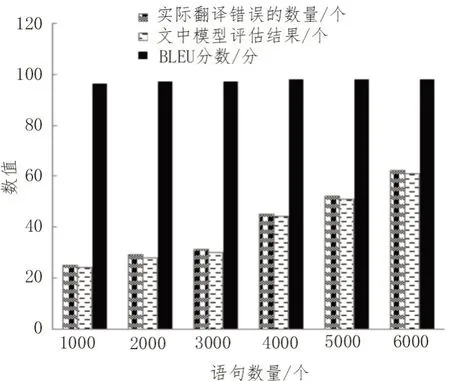
图7 语句数量对该文模型评估性能影响
为了进一步分析提出模型的有效性,将其与文献[3]、文献[4]方法进行对比,得到3 种模型的精度对比,如图8所示。

图8 不同语句数量下3种方法的精度对比
从图8可以看出,无论语句数量为1 000、2 000、3 000、4 000、5 000 还是6 000 个,提出模型的机器自动翻译质量评估精度远高于另外两种方法,精度最高可达97%,且更加稳定,具有一定的应用价值。
为了更好地分析提出模型的应用价值,再次对3种模型的质量评价效率进行对比,可得结果如图9所示。
从图9可以看出,无论语句数量为1 000、2 000、3 000、4 000、5 000 还是6 000 个,在保证质量评估精度的同时,提出模型的机器自动翻译质量评估效率远高于另外两种方法,质量评价效率最高在95%以上,在一定程度上可以证明提出模型的可行性。

图9 不同语句数量下3种方法的质量评价效率
3 结 论
文中构建了基于深度学习算法的机器自动翻译质量评估模型,并通过实验测试了该模型,可知:
1)提出模型认为机器自动翻译正确语句的数量与实际数量间的差值都是1 个,评估结果准确性较高。
2)在不同语言与不同翻译句型下,提出模型的评估结果和实际情况差异较小,仅对特殊用法句翻译质量的评估结果存在差值。
3)随着语句数量的增多,提出模型的BLEU 分数小幅度增大,最高分为98 分。
综上所述,提出模型适用于机器自动翻译质量评估工作中。
猜你喜欢
环球时报(2022-07-13)2022-07-13
心理学探新(2022年1期)2022-06-07
环球时报(2022-03-14)2022-03-14
新世纪智能(语文备考)(2020年4期)2020-07-25
广东教学报·教育综合(2020年15期)2020-03-23
电影(2018年8期)2018-09-21
社会心理科学(2015年6期)2015-02-07
中学教学参考·文综版(2014年1期)2014-03-11
语文知识(2014年4期)2014-02-28
小雪花·初中高分作文(2009年8期)2009-11-16
