
基于DTFS的PACS存储系统设计
2021-11-10 05:27朱彦霞陈益洲华南罗刘敏
电子设计工程 2021年21期
朱彦霞,陈益洲,华南,罗刘敏
(1.河南省职工医院,河南郑州450002;2.河南省卫健委统计信息中心,河南郑州450000;3.中国广电河南网络有限公司,河南郑州450000;4.洛阳职业技术学院,河南洛阳471000)
目前,医疗信息数据的存储主要采取传统的中心化SAN 存储方式,平均每个患者医疗影像(PACS)存储数据在500 MB 以上[1],以三级医院为例,根据国家卫生统计中心相关数据2019年全国三级医院平均出院人数约为3~3.5 万人,仅单向存储PACS 数据空间至少占约14 TB,由此面临极大的存储、备份、存储扩容压力以及随着数据量增加而带来的数据库访问压力;尤其当医院进行存储硬件更换、软件系统升级时将面临具大的数据迁移压力以及数据完整性、一致性、迁移效率低下等问题。在日常的诊疗业务中,医院局域网内存在服务器及终端分时段存储、网络资源闲置或利用率不高的问题。如何在确保数据安全的前提下,提高医院硬件存储、网络资源的利用率是医院信息化管理极为关注的话题。
区块链具有去中心化、可追溯、安全可靠等优点[2-3],网络中各节点遵守特定的共识机制实现相互间的信息及权益的获取。文中提出并设计了一种基于分布式传输文件系统(Distributed Transmission File System,DTFS)的PACS 存储系统,充分利用现有各网络节点时段性闲置资源及私有区块链、加密算法等技术,实现分节点数据的存储、传输与备份,在PACS 业务数据传输方面可有效提高文件网络存取速度、降低数据坍塌式损毁风险。
1 国内外研究现状
近年来,国内外许多研究人员和机构运用区块链技术在医疗领域积极探索并取得了一定进展。目前,区块链技术主要应用[4-9]于电子健康病例存储与共享、医疗欺诈与理赔、药品溯源与防伪、DNA 钱包、比特币支付、药品防伪、蛋白质折叠等方面。2015年,飞利浦与Tierion 合作,实现将医疗数据记录到区块链中[10],同年,Guardtime 实现了基于Hash 计算的密码学无钥签名基础设施的区块链技术[11];2016年4月,飞利浦与区块链技术公司Gem 共同推出了Gem Health[12]项目以推动医疗领域间的合作,同年,PokitDok 公司与因特尔公司合作,提出“Dokchain”医疗区块链计划,拟构建医疗领域临床与财务数据的分布式网络解决方案[13];2017年,Patientory 发布区块链医疗应用平台[14],为患者与医护人员之间搭建安全数据存储点,实现患者对个人医疗健康历史数据的访问;2018年,沃尔玛获得三项有关区块链专利,其基于区块链的医疗记录系统将患者数据存储在分布式账本中[15],当病人遇到无意识的昏迷情况等紧急情况时,相关医疗记录可被授权访问;2019年,文献[16]将区块链与非对称加密技术结合,有效利用非对称加密安全性高、多方协作简单等特点,实现医疗记录跨域分享的数据追踪、防篡改及身份验证的简化。文献[17]针对单管理节点易遭受攻击和威胁,通过设计双区块链结构分别实现医疗记录存储与共享。在文中,充分利用现有网络资源时段冗余特点、通过软技术实现基于DTFS 的PACS 存储优化,可节省投入成本,提升系统安全、运行性能。
2 系统背景技术
2.1 分布式哈希表
分布式哈希表(Distributed Hash Table,DHT)是分布式存储与传输的关键技术,广泛应用于P2P 网络中。网络中各节点共同维护一个形如<key,value>的文件索引Hash 表,通常将文件的Hash 值存入key中、将IP 地址存入value 中;这个Hash 表会按照一定的规则算法分割成若干份存储于网络的各节点中,每个节点仅维护一小部分Hash 表;当查找时,仅需查找相应报文路由到相应节点即可[18]。
2.2 区块链
2008年11月中本聪提出“比特币”概念,2009年初实践化区块链正式诞生,全球掀起区块链热潮。目前已经从以“比特币”为代表的1.0 时代发展到3.0 时代。区块链(blockchain)利用P2P 协议、数字加密、时间戳、分布式数据存储等技术实现数据的去中心化链式存储,各节点间通过共识机制(主要包括工作量证明PoW、权益证明PoS、权威证明PoA、DPos股份授权证明机制、交易量证明机制EPos)确保链上数据的一致性。
3 平台设计
3.1 PACS系统存储应用现状
现在各医院PACS 多采用SAN 结构的单一存储,存储构架如图1所示。
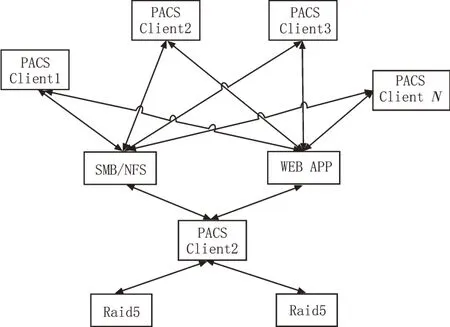
图1 基于SAN的单一存储构架
以一个省级三甲医院为例,一年至少能产生15 TB的数据,如果每份数据文件以20 kB~10 MB 颗粒度计算,将至少存储150 万个左右小文件。在此背景下,基于SAN 存储面临的主要问题如下:
1)一般要求SAN 主备镜像,主备镜像日常数据同步需消耗较大的存储及I/O 压力。
2)当发生主备镜像中的某数据存在异常错误,主备镜像数据全部恢复耗时较大,同时恢复期间设备I/O 占用率为100%,有造成服务停止的风险。
3)当存储的小文件达到一定量时,无论是NTFS还是EXT4 等常见分区格式,对文件的检索和查询性能均会降低。
4)一般采用SMBNFS 等方式与第三方系统进行数据共享,如果遇到操作系统漏洞,可能导致数据被破坏或者泄露。
5)所有的数据通信都需要通过PACS 服务器,如果业务量大则压力无法平衡。
3.2 DTFS整体解决方案
该文基于DTFS 的PACS 存储系统方案如图2所示,其整体设计思路如下:

图2 基于DTFS的PACS存储系统
1)采用HTTP、HTTPS 和WebDev 协议。
2)客户端支持Windows/Linux 操作系统。
3)数据采用中心加分布式存储并统一采用版本控制模式。
4)DTFS Server 服务端为全量存储并以块文件方式存储物理文件,小文件打包存储,大文件以切片形式存储于核心数据库。
5)DTFS Node 客户端后台运行不会打扰桌面用户,可通过Server 设置分布式存储和内存使用的大小,无需全量存储数据,但需保持数据索引与服务端数据库版本同步;当使用DTFS 的程序提取数据时,首先判断是否在本地存储,若是,则直接读取本地区块,若否,则通过DTFS Server 的API 直接取得网内区块;DTFS Node 需定期上报本地资源使用情况,保证某个节点的I/O、CPU 和剩余空间压力不至于过大(设置临界点)。
3.3 DTFS 节点存储分层设计
DTFS Node 的存储方式采用三层设计架构,各层设计功能如下。
1)冷数据层
用于存储长期保留的数据。在新建DTFS Node时,一般采用后台多线程方式从同节点设备进行数据块同步,当DTFS Node IO 或CPU 占用率较高时降低写指令频率。
2)温数据层
从当前DTFS Node 的PC 产生的数据,优先写入本地,并将结果上报中心服务器完成同步;根据主服务发布的广播指令进行数据同步,以类CNS 方式减少或缓解客户端对服务器端请求压力。
3)热数据层
除中心服务器外,所有的DTFS Node 均有本地数据库,只存储DTFS Server 下发的指令和需要上报的指令和数据区块。
3.4 算法设计
3.4.1 DTFS node 审核
每个DTFS Node 安装后会产生一个GUID 并提示用户选择服务器或输入服务器IP;链接成功后并对本地资源进行上报,上报后DTFS Server 会审核此Node;DTFS Node 通过审核后,服务端根据DTFS Node 的硬件水平设置磁盘和内存的策略,然后DTFS Node 转入后台运行;在使用DTFS 的APP 或者WebAPP 通过认证机制访问DTFS API 接口操作数据时,在设备硬件性能不足时可设置禁用本地缓存直接从服务器推荐的DTFS 节点读取数据。
3.4.2 新建文件过程
新建文件过程也即导入DTFS 系统的过程,具体流程如下:
1)首先根据用户ID(UID) 获取用户角色(UserRole),同时调用本地DTFS API 接口对文件进行二进制流化处理并根据设定切片包大小(Buffer_len)进行数据流切片;与服务器进行握手,用<Public key, Private key>进行数据加密并获取Hash、Did、Gid、Version 等相关信息后打包上报;上报后数据分别存储于DTFS Server 及当前DTFS Node。
2)服务器获取并签入数据后,广播指令给1/5 的在网资源较富余的Node 并分批下发同步指令,Node按DTFS-Tree 结构根据资源状态进行同步,服务端可在后台查看目前Node 节点和数据的运行状态。
3)Node 节点的策略分为Full 模式及Auto 模式。通常可选取服务器集群中业务原资源消耗率较低的节点标识为Full Node,用于DTFS 数据优先资源同步;其他终端节点标识为Auto Node,并根据日常监控资源使用情况进行Auto 分发同步;Auto 模式设置两种状态,即CDN 状态和镜像状态(镜像状态包含CDN功能),如果所有节点达不到DTFS镜像模式的最低标准,则仅启动CDN功能,DTFS将失去灾备恢复能力。
3.4.3 读取文件过程
文件读取过程中主要采用NO-SQL 技术完成内存数据操作等,具体流程如下:
1)调用请求DTFS API 接口并传送<Gid, Did,Hash>,接口可选择获取对应的Version信息及与之相关的存储路径信息等,并根据路径信息自动从本地或路径导航指示Node 数据块中获取相应文件数据。
2)获取文件数据后,DTFS API 调用Server 上存储的对应密钥对数据进行解密;解密后的文件数据存储于Node 节点上的内存数据库中。
3)读取文件过程结束后,DTFS API 对内存数据进行释放。
3.4.4 修改文件过程
文件修改过程支持版本控制功能,主要分为版本覆盖、版本升级两种模式,具体流程如下:
1)版本覆盖模式
Gid 不变Version+1;Did 和Hash 会被刷新与修改后的切片一同上传,同时服务端下发指令,将Gid下原有版本的数据在所有节点上声明清除已节省空间;此时所有Node 节点获取数据时只能请求Server端或已经同步过的Node 节点来获取数据。
2)版本升级模式
Gid 不变Version+1;Did 和Hash 产生新的与修改后的切片一同上传,同时服务端下发指令,将Gid下原有版本的数据在所有节点上声明Version 升级。
3.4.5 删除文件过程
文件删除过程也采用了版本控制机制,分为彻底删除和当前版本删除两种模式,具体流程如下:
1)彻底删除模式
根据Gid 直接删除所有历史版本,所有Server和Node 节点启动就会执行,服务端只会保留删除历史。
2)版本删除模式
根据Gid 的获取版本号并将相应版本标记删除;删除后客户端将不再获取该版本数据,但其他数据节点会暂存该节点信息直至同步数据资源不足时释放。
3.4.6 核心过程实现
基于DTFS 平台的PCAS 文件存储核心过程实现详见算法1,算法涉及文件导入、权限判断、加密、DTFS Node 间数据传送、异步处理等过程。算法1 展示如下:

3.5 系统安全机制
3.5.1 DTFS 标记约束
每个软件应用DTFS 的时候,需通过平台申请账号并获取系统为软件应用分配唯一标识及会话认证key;软件应用调用DTFS API 时,会根据机制获取会话令牌用于文件操作流程。
3.5.2 文件命名约束
文件命名根据路径轨迹以冒号分隔,以软件应用APP1 创建及查询PACS 文件过程为例:创建过程,创建形如App1:眼科:张某:2020-04-22:眼部扫描.zip的文件;查询过程根据命名约束进行路径拆解扫描,并根据接口调用及传参情况获取相应资源。
3.5.3 数据访问原理
本地软件由DTFS API 调用平台会串行化一个http/https 地址用于数据本地软件的获取;DTFS API还支持WebDev 模式,可实现类Windows 操作文件方式,但不支持彻底删除和选择版本读取。
3.5.4 数据同步镜像原则
镜像服务需要通过节点实时备份且至少保证在线设备空间与主服务器可用空间比例为1∶1,以下对理想状态与非理想状态下存储网络状态进行了分析,分析假设:服务器端需同步数据大小为20 TB,客户端数量为100 台。
1)理想状态
理想状态下所有节点设备的可存储空间在全量数据的5 倍左右,此基础配置下可以保证极端情况下至少有33%的设备在线以支撑系统正常运行要求;按照每台PC 终端可划出1 TB 的存储空间用于DTFS 存储,根据员工昼夜轮休情况,全院2/3 的电脑在非工作时间处于关机状态,则剩余的1/3 的电脑已可满足服务器端的镜像同步需求。
2)非理想状态
节点不满足DTFS 的基础需求,则DTFS 工作采用热CDN 模式。该模式下,对近期有访问的数据进行缓存,容量超限之后,自动删除访问率较低的数据,当核心服务器数据丢失后,不可全量恢复、仅可支持恢复所有节点当前版本数据。
3)成本对比分析
以下将PACS 存储分别在SAN 模式及DTFS 模式下的存储服务器硬件成本及运营恢复成本进行了分析对比,分析结果表明:基于DTFS的存储模式无论在硬件成本及运营恢复成本上均优于传统PACS模式。
①存储、服务器等硬件成本分析
传统SAN 模式服务器采用Raid5,有效存储20 TB,服务器、硬盘及配套硬件总成本约6 万;采用DTFS 模式,以100 台PC 客户端构建DTFS 子节点同时考虑服务器冗余资源利用。根据市场调查目前PC 客户端硬盘存储不小于2 TB,空闲存储不小于1 TB 可用于DTFS,平台整体硬件成本将小于3 万元,当客户端在线率及冗余率增高时,其DTFS 扩容成本随之降低。
②运营成本分析
客户端请求服务器读取数据时服务器端会产生大量网络和I/O 压力,对服务器及网络扩容需求增高带来相应运营成本不断增高;采用DTFS 按照局域网是1 000 M 计算,通过瀑布式传输可分步实现数据同步传输,常规数据的读写不直接再请求核心服务器,充分缓解了核心服务器和核心交换机的压力,延缓了IT 扩容的周期,相应运营成本增幅较慢。
3.5.5 数据灾难恢复
系统设计充分考虑数据灾难恢复方案:当遭遇中心服务器宕机数据彻底丢失时,首先重新部署服务器;部署完成后,各Node 端自动链接Server(如果服务端IP 域名变更则需Node 端相应重新配置),Server 端审核后,审核通过的Node 会自动上传本地版本库的数据和版本日志,只要本地分节点的数据覆盖能达到100%则数据可以完美恢复;在恢复过程中,Node 的数据可能会发生篡改或损坏,则Node 节点之间需要进行批量数据块校验比对,通过服务端仲裁策略决定服务端的最终恢复相应版本数据;当冗余备份不足时,仅恢复当前节点版本数据。
4 结 论
数据储存备份压力、数据并发传输效率、数据迁移风险是PACS 信息化平台中面临的重要问题。文中在医院PACS 平台之上设计了一个基于DTFS 的存储分发容灾平台,可有效延缓系统升级时间以实现资源高效利用并降低成本投入,同时通过存储及安全机制策略设计可有效提高系统的数据传输速度、提升系统安全性能并降低灾难性数据丢失风险。
猜你喜欢
科学(2020年5期)2020-11-26
科学(2020年6期)2020-02-06
铁道通信信号(2019年9期)2019-11-25
传媒评论(2018年4期)2018-06-27
现代企业文化(2018年13期)2018-06-09
消费导刊(2018年8期)2018-05-25
网络安全和信息化(2017年9期)2017-11-07
网络安全和信息化(2017年10期)2017-03-08
知识产权(2016年8期)2016-12-01
网络空间安全(2016年3期)2016-06-15
