
电力用户侧异常数据分析
2021-11-10 10:55马俊鹏邬英光柏航
科学与生活 2021年12期
关键词:智能电网
马俊鹏 邬英光 柏航
摘 要:随着电网智能化的不断深入和电网结构、运行方式的日渐复杂,电力系统产生的数据逐渐呈现海量化、高维化的趋势。此时,电网运行的安全性和经济性变得愈发重要,其中电力用户侧数据的异常、冗余与遗漏对电网运行安全和调度的影响绝不容忽视。目前电力系统异常数据检测主要分为基于状态估计和基于数据挖掘两大类,绝大多数的方法都只是在理论研究层面进行异常电力数据的辨别研究,而对实时数据的即时辨别能力不足。针对传统方法实时辨别能力的不足,本文引入K- 距离因子算法进行电力用户侧电量数据即时辨别。
关键词:智能电网;异常数据;K- 距离因子;特征量
0 引言
随着科学技术的不断发展进步,电网结构和运行方式的复杂度不断提升,电网的安全性和经济性也变得比以前更加重要,其中电力用户侧信息的正确性和实时性尤为关键,一旦出现误判将对电网运行安全和调度产生不可估量的影响[1-4]。本文通过典型家庭用电负荷分析,提出基于K-距离因子的电力用户侧异常数据辨析方法,可作为电力系统安全、经济研究参考依据。
1 数据处理
1.1用户用电数据分析
本文所研究的用电量分为两种:良好数据和异常数据。异常数据又分为两种类型,一是无效数据。即该测量点的用电量小于等于前一时刻的用电量,即 。其中, 为当天当前时刻用电量数据,即第t天的第n个数据点, 为当天前一时刻的用电量数据。因为用电信息采集系统采集到的用电量是累加值,必定是一个递增的过程,所以一旦出现此类情况则判定此数据为无效数据,直接存入错误集,不参与算法辨析过程。二是错误数据。虽然 ,但该数据明显过大或过小,不符合常规的用电规律。
通過对家庭用电行为分析可知,当用户外出时,用电设备情况较为单一,主要是冰箱等持续运行电气设备,所以用电负荷长期维持在一个较低的水平,明显异于正常用电规律,因此,必须排除此种情况干扰。此时,可以根据用户近几周内每天最小的用电量差值变化情况,可以得知用户外出时间段的典型用电量差值,参考时刻可以为凌晨00:00-06:00时段(除夏天)、早上10:00-11:00及下午15:00-17:00等时段。而由图2可以明显看出,凌晨时洗衣机的使用频率明显降低,使用时间也明显减少较短;而热水器的使用时间大多集中在常在晚上睡觉前或这早上起床后;电脑和电视机的使用时间则通常都是在晚上而且连续时间较长。为排除空调、暖气等季节性用电的干扰,本文选取上一年度春秋季00:00-06:00时段的数据组成p(0),即家庭用电最低负荷集。待确定这一典型用电量差值,识别方法就可以根据相邻时刻的用电量差值,从而判断用户可能是外出或家中进行无需用电的活动,如阅读、休息等。
1.2用户用电信息采集
用电信息采集系统主要是用来实时收集家庭用户的用电信息并及时分析处理。通过异常电量、电能质量等相关数据的检测来达到对整个电力用户需求侧状态的实时在线监控目的。传统家庭用电量采集频率多为每天一次,且集中在23:00至次日1:00之间,因为传统采集系统面对采集的数据,缺乏有效的方法进行判定,且错误和缺失的数据无法补缺,只能通过采集频率的降低和选取用电负荷较小区间进行数据采集,以降低数据的错误率。但是,过低的采集频率无法实现对家庭用电信息的时时监控,从而无法准确的掌握家庭用电状态。本文将一天24小时分为48个用电区间,并设置48个采集点(采集点设置详见表1)。在解决传统信息采集频率过低问题的同时,通过对采集数据的辨别分析,从而有效分辨出数据的真实、有效性,并针对缺失、错误数据,通过负荷预测的方法进行补全。
1.3历史特征量的选取
普通家庭的不同月份的用电情况变化较大,用电峰时段为冬(12 ~ 2 月) 夏(6、7、8),其余月份的谷用电量差别不大,要是选取家庭全年的用电信息进行离群点分析,则容易产生误判。因此,本文引入相似日的概念,通过相似日的选取从而得到更接近预测时段的电力负荷数据,减少了历史数据的量却提高了预测精度。根据“远小近大”的原则,日期越接近,它们的电力负荷也会更加相近。因此通过利用具有特征量相似的历史用电量数据作为依据,判断当前时刻用电量数据是良好或者异常更加合理科学。本文依据普通家庭用电负荷季节性变化的特点选取近往前29天的同一用电区间电量数据作为特征量与新采集的数据组成一个集合p(t), p(t)内共有30个数据,而新的采集数据默认为p(30)。
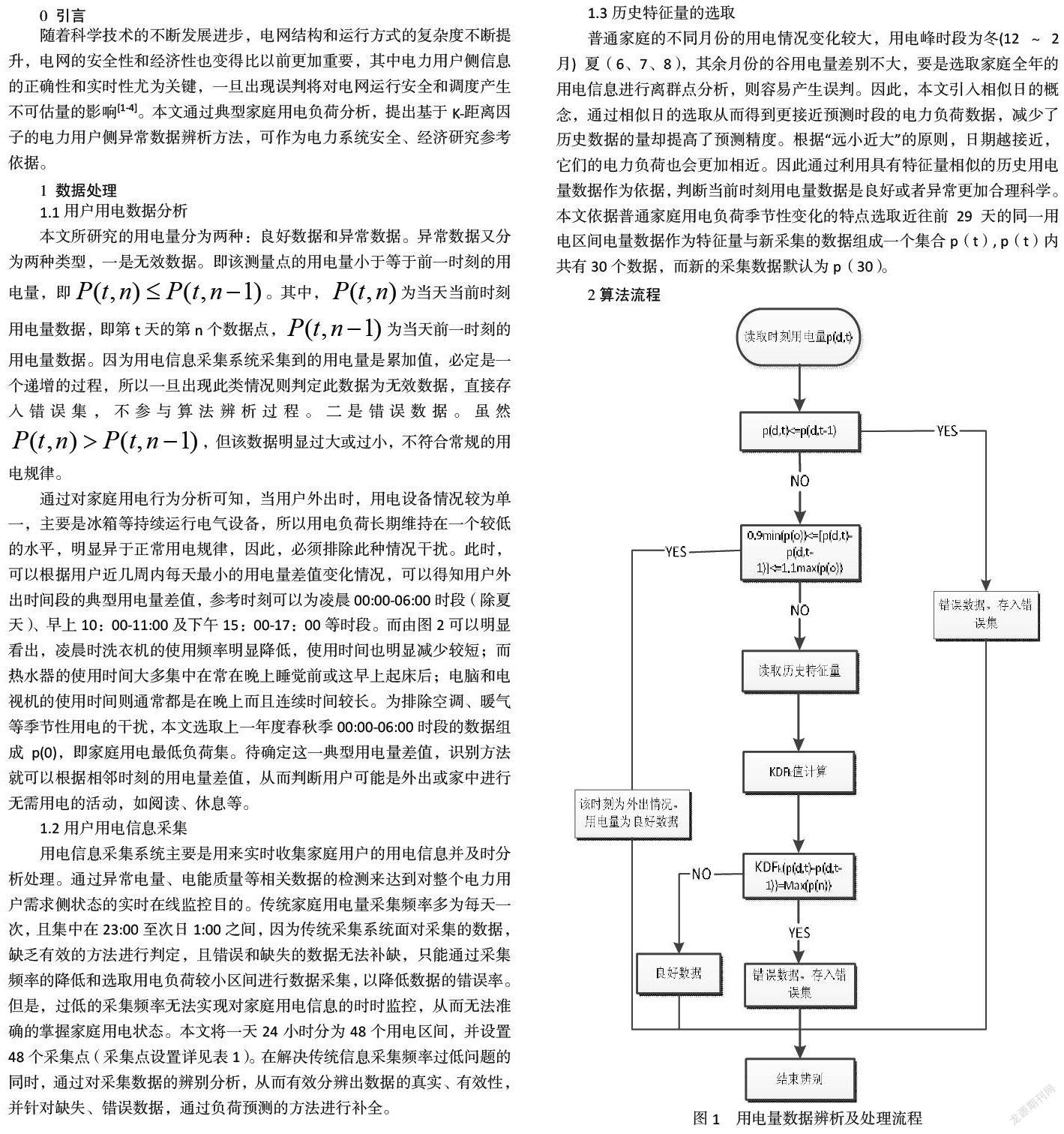
2算法流程
本算法的流程主要分为一次提取,三次判断。一次提取就是提取实时用电数据p(d,t)。第一次判断是判断该实时数据p(d,t)是否为有效数据。因为用电数据是一个累计递增的变量,所以如果实时电表读书p(d,t)小于等于上一采集时刻的电量读数p(d,t-1),便能判定此数据为无效数据。一旦被判定为无效数据,便直接将其存入错误数据集。如果经判断p(d,t)是有效的,则进行第二次判断,即排除家庭外出状况。考虑到用电负荷的突变性,首先将p(0)的上下限上下浮动10%,然后再将实时区间用电量数据p(d,t)- p(d,t-1)与0.9min(p(0))和1.1max(p(0))对比,如果p(d,t)的数值在0.9min(p(0))和1.1max(p(0))之间,便判定该家庭为外出情况,该数据有效直接存入数据库。如果经判定,该家庭不属于外出情况则进行第三次判断,首先将每次读取到新的数据与选取的历史特征量组合成新的待辨别数据集p(t),其中新采集到的数据默认为p(30),然后通过K-距离因子算法进行辨析。
3总结
本文首先提出了运用k-距离因子进行电力用户侧用电量数据辨别的思路,并对数据、参数和辨别条件做出了改进。由于电力系统对电力数据的准确度和实时性要求越来越高,正常的数据突变偶有发生,这也对异常数据辨析结果产生影响,因此还需进一步研究改进。
参考文献
[1] 王兴志,严正,沈沉,等.基于在线核学习的电网不良数据检测与辨识方法[J].电力系统保护与控制,2012,40(1):50-55.
[2] 王宝石,段志强,翟登辉.基于有效指数k-means算法在电力系统不良数据辨识中应用[J]. 东北电力技术, 2010, 31(3):16-18.
[3] 揭财明.基于密度的局部离群点检测算法分析与研究[D].重庆大学,2012.
[4] 闫少华,张巍,滕少华. 基于密度的离群点挖掘在入侵检测中的应用[J]. 计算机工程, 2011, 37(18):240-242.
作者简介:
马俊鹏,男,硕士研究生,工程师,主要进行新技术在装备保障体系中的应用研究。
柏 航,男,本科,高级工程师,主要从事装备保障体系。
邬英光,男,本科,高级工程师,主要从事装备保障工作。
猜你喜欢
科学与财富(2016年26期)2016-12-01
科学与财富(2016年15期)2016-11-24
企业技术开发·中旬刊(2016年10期)2016-11-12
企业技术开发·中旬刊(2016年10期)2016-11-12
数字技术与应用(2016年9期)2016-11-09
科学与财富(2016年28期)2016-10-14
科学与财富(2016年28期)2016-10-14
