
改进自训练模型在业务质差用户识别中的应用
2021-11-11 06:04余立李哲高飞袁向阳杨永
电信科学 2021年10期
余立,李哲,高飞,袁向阳,杨永
(1. 中国移动通信有限公司研究院,北京 100053; 2. 中国移动通信集团公司,北京 100033)
1 引言
随着移动互联网发展,我国移动互联网用户突破13亿户,占全球网民规模的32.17%[1],随着新型技术(如5G、云计算等)的发展,用户对上网速度、稳定性等要求越来越高。
质差用户指在使用移动通信网络服务时,由于网络质量问题或其他因素对服务体验不满的用户。网络质量问题导致的质差用户,对网络服务的满意度会降低,且可能存在投诉、转网等行为。
质差用户群体流失概率较高,他们是各大网络运营商重点关注与关怀对象。传统质差用户识别通过数据采集系统对用户上网过程中产生的行为单据XDR(X data record)进行分析,即可过滤潜在的质差用户。但各用户感知无法统一,不满意原因及不满意的业务也并不一致,传统分析方法可识别的投诉用户比例较低,无法满足现网投诉处理要求。故通过将已存在的满意度低或投诉行为的质差用户与XDR进行关联标注后,利用机器学习算法,实现对质差用户进行分类识别与预测。
通过现网收集的XDR数据中存在以下问题。
• 不同省份网络基础设备存在一定差异,数据中特征字段并不完全相同,且部分字段填充率较低,无法直接利用。
• 数据进行标签化标注时,不同省份字段计算方法可能存在差异,且数据量巨大,导致标注成本高昂。
• 已投诉用户单据中投诉原因众多,部分原因来自于非网络问题,存在大量对抗样本,导致样本本身含有较大噪声,训练时会影响模型性能。
2 半监督学习
有监督学习需大量的有标签数据训练模型,在质差用户识别模型中,一条有标签数据包含两部分:用户XDR数据和是否为质差用户。前部分数据通过数据采集系统获得,后部分标签信息需丰富的专家知识,往往判定成本较高,造成整体训练成本的增加[2]。
现网每日会产生海量的用户XDR数据,通过标注再进行训练,模型时效性较差,无法准确描述现网实时运行状况。半监督学习与有监督学习相比可以利用现网实时海量无标签数据,效率较高;与无监督学习相比可以保证模型准确率。
质差用户识别为分类问题,已知的半监督分类问题主要分为5类,具体优劣势见表1。

表1 半监督分类方法优劣势
• 基于图的半监督模型将标签数据和未标签数据构建为图,图中节点为数据点,边为节点权重,通过寻找图的最小分割,然后计算反向传播权重,其可应用于图片、中文文本、数据分类等各类场景,但是当新样本加入时,需要重新训练得到图模型,计算开销较大[3-4]。
• 基于分歧的半监督模型通过选择差异化基模型,进行组合降低“错误”分类样本对模型的不良影响,提升模型预测准确率,但是其对基模型选择设定要求较高,并且运算效率也较低[5-6]。
• 半监督支持向量机是将支持向量机应用到半监督模型中,将样本空间映射到高维空间,并选择合适平面将样本集划分,但是模型受参数影响,最终模型准确率较低[7]。
• 协同训练(co-training)用有标签样本的两个视图分别训练两个弱分类器,再利用分类器对未标注样本预测中高置信度样本训练另一个分类器;即用一个视图中获得的知识来训练另一个视图。缺点是对样本要求高,要求具有两个充分冗余且满足条件独立性的视图,实际情况下较难满足[8-9]。
• 自训练(self-training)需要一个基分类器和少量样本数据可以实现,核心思想是先学习有标签数据,然后计算无标签样本置信度,并将置信度高的样本加入训练集,缺点是如果无标签样本预测错误,则随着训练的深入,会造成错误的累计[10-12]。
基于对以上半监督方法的研究,本文选取一种改进自训练模型,通过设置基模型参数以及较高的置信度阈值,引入多个基模型学习器,降低传统自训练中出现的误差累计现象,提高模型训练精度。
3 改进自训练应用
3.1 改进自训练模型
自训练模型是一种增量模型,首先建立基分类器模型,通过有标签数据进行训练,然后利用训练好的基模型不断预测数据集中无标签数据,从中选择置信度高样本,将其加入有标签数据中进行基模型循环训练。在满足设定停止迭代条件后,得到具有最高分类精度和最强的泛化性能的最终分类器。模型在迭代过程中不可避免会产生误分样本,基模型学习误分样本会产生错误累计,最终影响模型效果。为降低错误累计,本文做出以下改进:设置模型性质不同、性能相同的3种基模型,分别进行预测后,通过投票初步选定伪标签样本,随后计算其置信度,将置信度高的伪样本加入模型训练集中进行循环迭代。改进自训练模型示意图如图1所示。
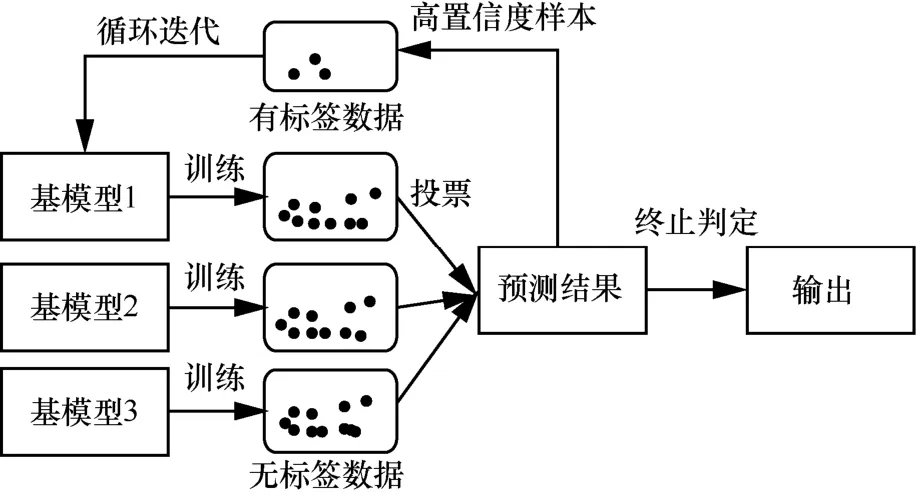
图1 改进自训练模型示意图
其基本流程如下:
(1)根据有标签数据集训练3种基模型;
(2)利用训练得到的基模型预测无标签数据;
(3)选择置信度高的样本,将其加入有标签数据集;
(4)循环训练模型;
(5)判断是否满足迭代条件,重复(1)~(3)。
改进自训练模型算法见算法1。
算法1
输入有标记样本集:
每i轮基学习器为 K1i、 K2i、 K3i;
每i轮预测得到样例数为pi;
流程
(1)初始化设置 K10、 K20、 K30;
(2)i=1;
(3)利 用 K10、 K20、 K30拟 合Dl得 到 K11、 K21、 K31;
(4)利用 K11、 K21、 K31训练Du,得到pi例样本不同分类情况下置信度;
(5)进行选择,将pi例预测样本加入Dl;
(6)利用新样本集Dl训练,得到 K12、 K22;
(7)循环(4)~(6),直到满足迭代终止条件。
3.2 基模型选取
质差用户识别是一种分类问题,最终评价标签为质差用户和非质差用户两种。当前主流机器学习分类模型有贝叶斯分类器(NB)、Logistic模型、支持向量机、树模型(如随机森林(RF)和极限梯度提升(XGBoost)等[13])。本模型选择朴素贝叶斯分类器、XGBoost、随机森林为基模型进行训练。
(1)朴素贝叶斯分类器
该模型描述如下:设训练集中包含m个类H=(H1,H2,… ,Hm),n个条件属性X=(X1,X2, …,Xn),并且假设所有条件属性X为类变量H的子节点,并相互独立,则当待分类样本x=(x1,x2,…,xn)分配到类Hm时,根据贝叶斯定理可得:
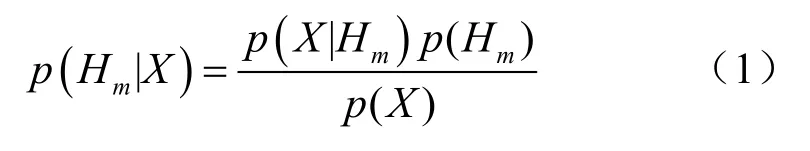
由于在本监督学习中需要使用大量的无标签数据进行模型训练,式(1)修改为:
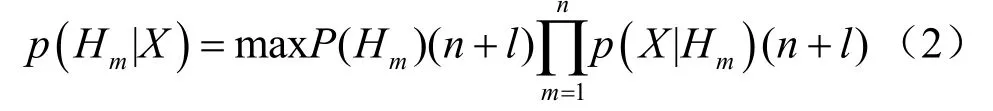
其中,(n+l) 表示迭代后有标签样本集与增加标记后的无标签样本集的合集,该合集增加了无标签数据中预测得到的高置信度数据。
(2)极限梯度提升和随机森林
XGBoost和RF都是基于树模型的集成模型,但是两者有所区别。XGBoost为并行化Boosting处理,RF为串行化Bagging处理[14]。
给定数据集D=(Xi,yi),输入Xi并通过线性叠加模式预测iy。并设学习使用k棵树,模型如式(3)、式(4)所示。
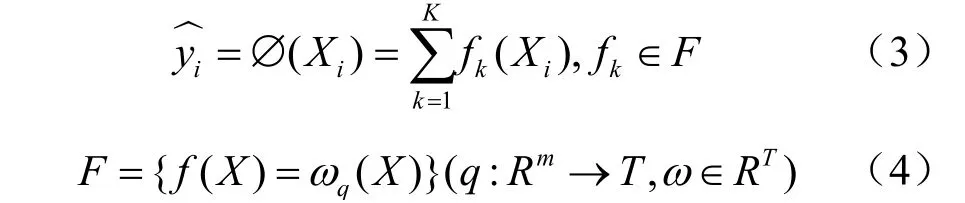
其中,()fX代表回归树,F代表回归集合,()qX表示将X分到了某个叶子节点上,T为叶子节点的数量,ω为叶子节点分数,ωq(X)代表f(X)对样本的预测。
通过二阶泰勒展开式和正则项调整得到目标函数如式(5)所示。
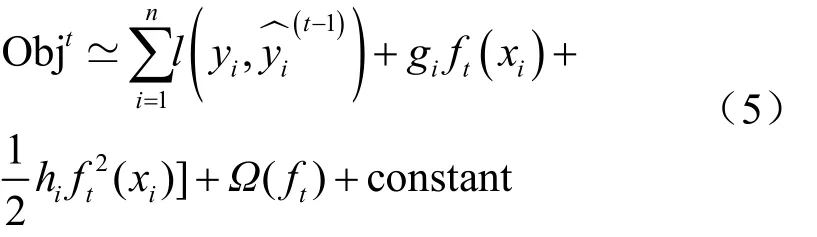
4 实验与分析
4.1 数据预处理
(1)数据收集
本次仿真实验使用数据采集系统中的正常XDR数据和现网投诉XDR数据。其中包含199 998条、46项字段的正常XDR数据以及3 355条、125项字段的投诉XDR数据。
(2)字段选取
正常XDR数据的46项字段中,包含较多非结构化离散字段(如小区ID、所属城市、IPV类型等),并且部分字段缺失值比重较大,通过处理最终得到连续型字段15项。
(3)标准化处理
部分机器学习模型需要数据处于同一量纲,所以进行数值量纲转化、标准化处理。处理后数据变化到均值为0、方差为1范围内。
(4)样本均衡
因为质差用户识别为二分类问题,所以需要保证原始训练数据样本集分布相同。使用随机采样方法,最终案例数据集组成见表2。

表2 数据集组成
(5)关键参数
TCP建链成功到第一条事务请求的时延(tcp_ack_srv_dur):在终端和服务器完成TCP建链请求后,到终端发出业务请求前的时间间隔。
第一个HTTP响应包时延(fisrt_http_ response_ time):在业务请求过程中,第一次业务请求发出后到接收第一次业务请求响应的时间间隔。
TCP建链确认时延(fisrt_http_response_ time):在TCP建链过程中,第二次握手SYNACK报文发出后到收到第三次握手ACK报文的时间间隔。
4.2 分类器评价标准
对于每个待检测的用户数据,分类器最终可能产生4种不同的结果,本实验中对不同情况解释如下。
• TP(true positive):质差用户,且模型预测结果为质差用户。
• TN(true negative):非质差用户,且模型预测结果为非质差用户。
• FP(false positive):非质差用户,但模型预测结果为质差用户。
• FN(false negative):质差用户,但模型预测结果为非质差用户。
基于以上4种情况,引入精准度、F1值和AUC3项指标进行评判。精准度和F1主要判断分类器预测结果的准确性,AUC主要判断分类器对质差用户区分能力的强弱。
精准度即精确率,在本实验中表示正确判断为质差用户的样本占全部质差样本的比例:
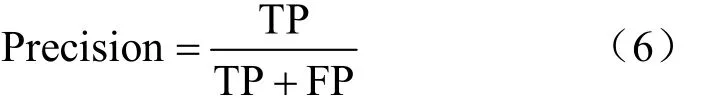
F1值是由Precision和Recall的调和平均数,在本实验中表示在保持一定精确率同时,尽可能保证所有质差用户可以被模型识别即保证召回率,两者相互平衡。
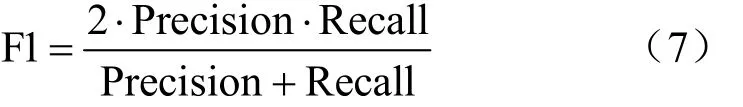
AUC值是ROC曲线下方的面积。ROC曲线绘制的横坐标是FPR,而纵坐标是TPR。当无法直接衡量学习性能时,AUC值越大,表明模型效果越好。

4.3 实验结果与对比分析
针对实验数据,分别使用全监督方法、半监督方法、无监督方法进行拟合。其中全监督方法选用XGBoost模型,半监督方法使用本文提出的改进自训练模型,无监督方法选用图传播label spreading模型。结果对比见表3。
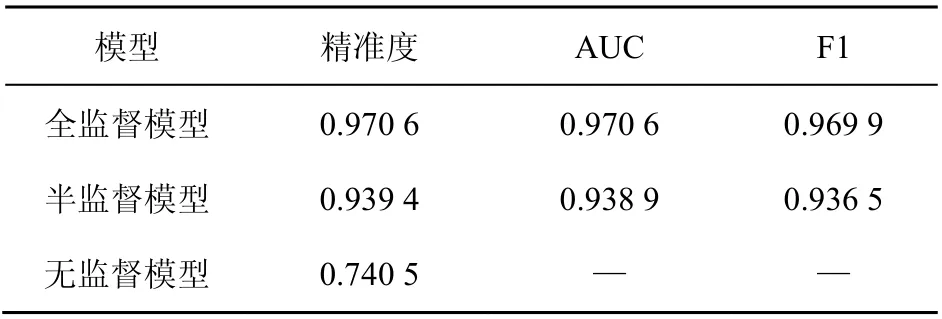
表3 3种模型运行结果
对比3类模型精准度可得到如下结论:全监督模型效果最好,各项评价指标数值最高;无监督模型效果最差,因为在模型训练过程中不可避免会学习到数据中噪声,影响模型评价指标;而半监督模型介于两者之间,可以充分利用大量无标签数据,此外还可以保证较高精准度。
为了进一步验证半监督模型优越性,将以上3类模型进行对比。其中在半监督和无监督模型中,横轴设置为样本标签缺失值比率。在全监督模型中,横轴设置为训练集划分比率。不同缺失值比率下模型精准度变化如图2所示。
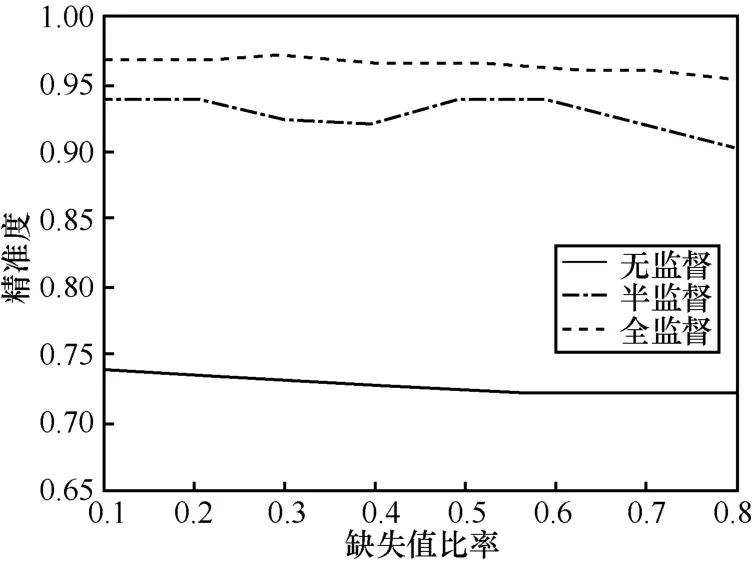
图2 3类模型精准度对比
通过图2可知,随着缺失值比率增加,3类模型精准度都在下降,半监督模型仍然处于一定精准度变化区间内,可以满足模型识别精准度要求。
在半监督改进自训练模型中,使用迭代训练对无标签数据进行标注,当缺失值比率相比于上次训练变化幅度低于0.1%时,模型迭代停止。具体数值和曲线变化如图3和表4所示。

图3 半监督模型评价指标变化趋势
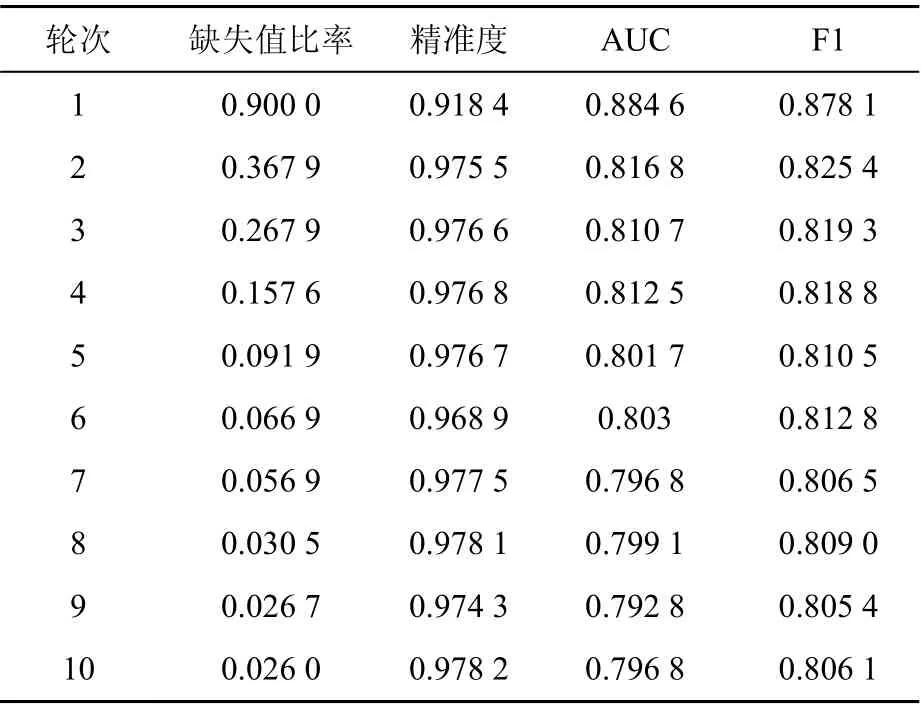
表4 半监督模型变化趋势
如表4所示,设置默认参数和初始样本缺失值比率(Ratio)后,模型开始训练。通过10轮迭代计算后,Ratio变化幅度0.07%符合迭代终止条件,迭代停止。观察表4中数据可知,缺失值比率列数值下降明显,精准度、AUC、F1 3项评价指标有一定波动,且浮动下降。这是因为模型在自训练过程中不可避免会学习到样本集中的噪声,最终模型性能受到一定影响。为进一步提升模型识别精准度,在之后的模型训练过程中,需改进基模型选择设计方案,并通过提高阈值、增加样本预测可靠性水平等方法,降低训练过程的误分类样本噪声。
5 结束语
本文针对质差用户识别问题,设计一种改进自训练的半监督模型,采用无标签样本占90%的训练集时,最终模型精准度维持在90%左右。相比于全监督模型和无监督模型,该模型在保证一定性能指标前提下,能够充分利用无标签样本数据,在现网应用中可有效降低数据标注成本,同时避免了人为主观因素对于质差规则设定的影响,可以有效实现质差用户识别。未来的工作重点为进一步提高该模型性能,降低在循环迭代中噪声对于模型性能的影响。
猜你喜欢
当代陕西(2020年24期)2020-02-01
安阳工学院学报(2018年6期)2018-11-28
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
网络安全和信息化(2018年3期)2018-03-03
自然资源情报(2017年4期)2017-11-26
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
公民与法治(2016年10期)2016-05-17
少儿科学周刊·少年版(2015年2期)2015-07-07
