
融合显著信息的白色污染图像自动标注算法
2021-11-17 07:34李光辉陈吹信
计算机仿真 2021年7期
汪 理,李光辉,陈吹信*
(1. 广州理工学院电气与电子工程学院,广东 广州 510540;2. 三峡大学电气与新能源学院,湖北 宜昌 443002)
1 引言
在大数据时代,用户能够访问获取的信息资源量巨大,图像能够反映出的信息更加易懂,更受人们青睐,因而被广泛应用。互联网平台中每天会产生大量的图像和视频信息,为了更加高效地对大规模图像信息资源进行提取并应用,图像检测变得尤为重要。
柯逍等人[1]提出一种基于数据集学习机的图像自动标注模型。首先,对公共图像库的训练集数据进行图像自动分割,选择分割后相应的标注词,并根据综合距离的图像特征匹配算法进行自动匹配以形成不同类别的训练集。通过蒙特卡罗数据集均衡算法使得各个标注词间的数据规模大体一致。然后引入多尺度特征融合算法,对不同标注词图像进行有效的特征提取。最后,运用鲁棒性增量极限学习,提高了判别模型的准确性。实验结果表明:该模型能够对图像实施自动标注,具有较高准确性。张鹏飞等人[2]提出一种基于集成GMM聚类的少标记样本图像分类方法,通过一定的规则给未标记数据赋予标签,将未标记数据转换成已标记数据用于模型的训练。在手写数字识别数据集上进行实验,最终获得标记图像。实验结果表明:该算法在少标记样本的情况下,结合集成GMM聚类的方法比只采用有标记样本训练得到的模型分类准确率具有较大提高。
由于白色污染图像边缘较为模糊,又容易受到外界环境影响,导致特征提取困难,上述方法需要耗费大量时间才能标注目标,并且精准度较低,很难被广泛应用。因此,提出融合显著信息的白色污染图像自动标注算法。该算法先对显著性信息进行提取并实施修正,然后对白色污染图像进行正则化处理,使白色污染图像中的显著目标一致性得到了增强,从而有效解决了传统方法不能精准获取目标信息的问题。再将FCM算法和遗传算法相结合,消除聚类中心收敛至极值的现象,从而改善传统方法标注结果不精准的问题。依据SimMSVM代入损失函数进行优化,从而实现图像的自动标注。实验结果表明:所提算法具有更好的标注效果,更加节省时间。
2 融合显著信息检测
2.1 全局显著性信息提取
为了使计算机自动分析出图像中区域的显著性和重要性,根据RC算法提取到显著性信息,显著图作为输入图像内像素显著值高低的灰度图,灰度值越大说明相对应像素的显著性越高[3,4]。
采用RC算法对图像进行分割,然后对各个区域实施特征提取并运算出显著值。任意区域ri的显著性是根据整体区域加权距离总和进行判断的,其表达式如下

(1)
式中,ω(rj)为区域rj的权重值,其是根据区域rj的像素数取决的,Dr(ri,rj)为ri和rj两者间的间距。
2.2 物体级别先验信息的融合
在融合显著性信息的过程中,由于图像具有复杂性,单一级别的检测方法很难获得明确的显著图,需要运用分层分割对图像具体信息进行识别[5]。
运用谱聚类算法将中级别超像素聚类成物体级别的区域分割,即O={O1,O2,…,Om}。依据K个特征向量,形成K个系列,运用聚类算法对图像进行分割。
根据分层分割定理,运用物体级别信息先验方法,当背景区域被合理划分为多个部分,那么中级别背景先验将很难对显著物体进行区分,当目标与物体两者间的流形间距较短,需要调节原始显著图,设定出一个边界先验[6]。将物体级别划分的四周与图像边界设置为L0与Lb。依据两者间的相交比例,描绘物体背景区域的概率,其表达式为

(2)
式中,LOi为边界集合内像素的个数。若中级碎片R处于相同物体级别O内含有同样的先验值,故Pp(Ri)=Pp(Oi),则物体级先验信息能够有效地增强显著性目标的一致性。
运用物体级的先验信息对超像素级别下的显著性实施进一步修正,得出公式为
M(Ri)=(Ri)Pp(Oi)
(3)
融合显著信息能够有效地抑制噪声对显著信息的影响。
3 白色污染图像自动标注算法
3.1 白色污染图像正则化约束
大多数图像的退化是通过线性退化系统K进行的,输入图像经过系统对应输出图像,得出图像退化的连续线性系统表达式为
y=x·h+n·M(Ri)
(4)
式中,y为模糊噪声图像,h为不确定的点扩散函数,x为原始图像。
充分考虑图像的特性,合理运用边缘检测滤波器组dθ获得图像边缘的具体信息,其表达式为
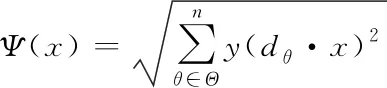
(5)
式中,Θ为滤波器整体方向集合;dθ作为滤波器组中一项权重的差分手段,合理运用大量相近点之间的细节信息,能够获得大量的边缘具体信息[7]。为了能够更好地保持图像边缘的具体信息,采用权重全变差范数对图像进行正则化约束,得出公式如下
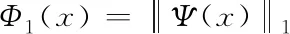
(6)

针对连续平滑性,需要确保支持域的连续性与平滑性,从而使正则化约束时的连续平滑性得到保障,模糊退化函数的表达式为

(7)

将Φ2(h)转变成高斯模糊正则化约束性,然后把参数λ2与λ3进行适当调节,能够获取模糊退化函数的稀疏性与连续平滑性;两者间的平衡可对后续图像的自动标注作铺垫,在迭代的过程中,运用函数对原始图像实施正则化约束处理[8]。
3.2 基于遗传算法和FCM的图像自动标注
为了能够对图像自动标注,更快速地实现聚类,需要采取具有较高性能的图像底层视觉特征信息,分别为HSV非均匀量化直方图具有16维,RGB颜色矩具有72维,以及SIFT特征具有128维。
FCM聚类算法主要是把图像特征数据X=(x1,x2,…,xn)分割成c个模糊组,再通过合理运算获得各组的聚类中心V=(υ1,υ2,…,υc),从而使所得准则函数呈现出最小化,故J的表达式为
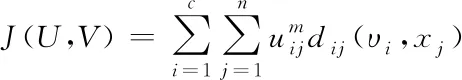
(8)
式中,i,j为图像x内像素点的坐标;υi为模糊组i的聚类中心;dij(υi,xj)为i个聚类中心υi至j个数据点xj的欧式距离;m为常数,其取值为2。通过式(8)可得出U的取值范围为
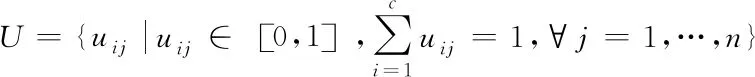
(9)
通过Lagrange乘数法,使准则函数J(U,υ1,…,υc)的值达至最小化,其表达式为

(10)
通过上述公式能够得出,FCM聚类算法作为局部动态优化算法,拥有简单的迭代过程,并且对初始值选择要求较高[9]。若初始值选取时存在误差,那么很容易导致所得聚类正确率较低的情况发生,因此,运用遗传算法对提取的特征向量进一步实施聚类分析。
遗传算法是通过模拟进化进行运算的方法,具有广泛的应用性。将遗传算法与FCM算法两者相结合,利用遗传算法的全局优化性能,在很大程度上改善FCM算法收敛性能较差的问题。两种算法结合主要是通过FCM算法快速将数据集X内c个模糊组导向其极值点,然后根据遗传算子去除聚类中心收敛过度的现象,进一步实施反复搜索,最终获得最优解的过程。算法的具体流程如图1所示。
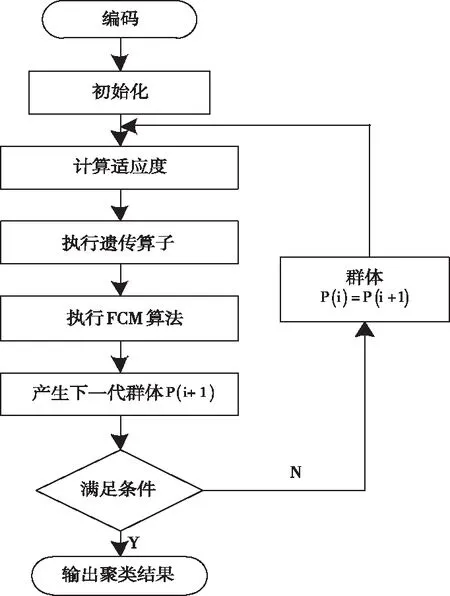
图1 算法流程图
按照c个ω维聚类中心的取值区间,将其实施二进制编码成基因串B={β1,β2,…,βn}(n=c×ω)。设置D代表聚类中心任意维数的十进制数,即D∈(-B,B),那么把D编码成16位的二进制数,其表达式为
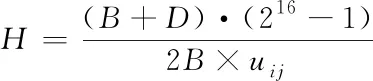
(11)
然后运用生成随机数的机制,随机生成chr个个体代表初始群体P(0)。
再运算出c类内每个个体的适应度,表达式如下
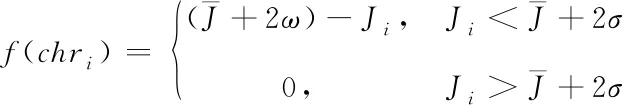
(12)

实施选择算子,运用蒙特卡罗方法,获取选择概率Pi,其表达式为
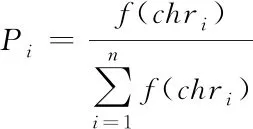
(13)
实施交叉算子,当交叉概率Pc的值较大,会导致新个体生产速度变得较快,且过大容易破坏染色体结构,过小会造成搜索缓慢。因此,交叉算子根据自适应选择,则交叉概率Pc的表达式为
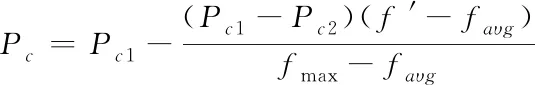
(14)
式中,Pc1为最大交叉概率,其取值为0.9。Pc2为最小交叉概率,其取值为0.6。faυg为平均适应度,fmax为最大适应度。
实施变异算子,当变异概率Pm的值较大,会呈现出随机搜索现象。当变异概率Pm较小,则很难生成新的染色体结构。因此,变异算子需根据自适应选择,变异概率Pm的表达式如下
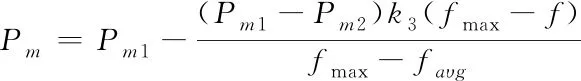
(15)
式中,Pm1为最大变异概率,其取值为0.1。Pm2为最小变异概率,其取值为0.001。faυg为群体平均适应度,fmax为群体最大适应度。
3.3 图像自动标注
在结合FCM算法与遗传算子的基础上,获得了各个模糊组的聚类中心,并消除了聚类中心收敛至极值的现象,从而得到了最优解。以此为基础,通过SimMSVM建立多类支持向量机,引入损失函数实施优化,经过逐步运算,实现白色污染图像的自动标注。
SimMSVM作为能够达到多类支持向量机的分类模型,被广泛地适用于图像处理当中。其具体定义如下:
首先,代入新的损失函数,其表达式为

(16)
然后,通过损失函数,对SimMSVM实施优化

(17)
再运用Lagrange算子运算出二次优化式,获得对偶形式的表达式为
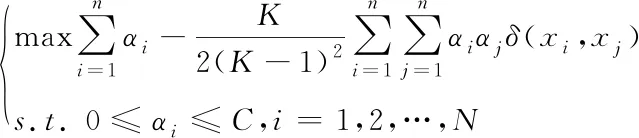
(18)
最后,获得SimMSVM的类判别函数,其公式如下
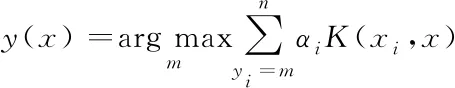
(19)
通过上述公式的推理运算,能够快速获得白色污染图像自动标注。
4 实验结果分析
为了验证所提方法的高效性,在多维网络平台上进行研究分析。通过为Windows10的操作系统运用Matlab2010软件进行实验,选用Corel图像库内300组不同形态的图像,每幅图像与1~5个标准词相关联。将所提算法与文献[1]和文献[2]方法的性能进行比较分析,结果如表1所示。

表1 图像自动标注性能对比
分析表1中数据可以得出,相比之下,所提算法具有更高的标注精度。这是由于所提算法通过具有较高性能的图像底层视觉特征信息实现快速聚类,从而实现了对图像的自动标注,提高了标注效果。
由于图像生成概率等于区域生成概率的面积,而且每一幅图像中所包含的区域个数是固定的,因此,需要将所提算法与其它两种方法进行对比分析,进一步验证所提算法的效率。具体对比内容如图2所示。
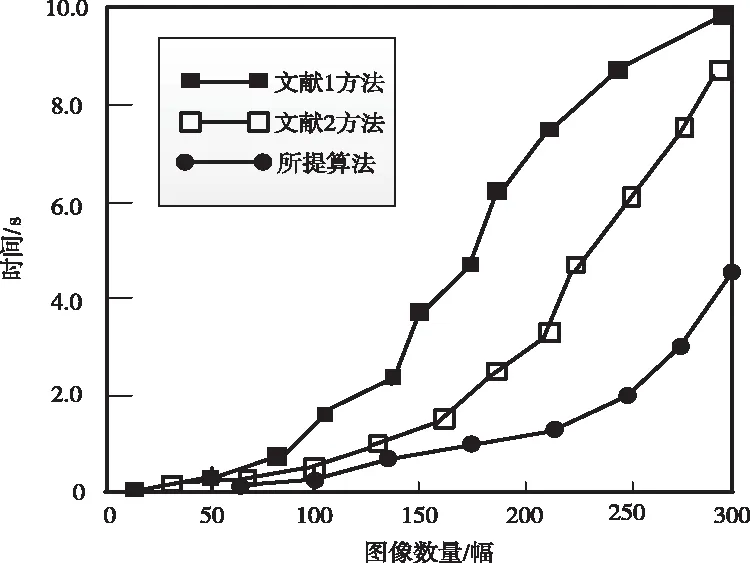
图2 标注时间对比图
从图2中可知,采用所提算法进行图像自动标注的运算时间更短,其最长运算时间为4.8s,而文献1方法的最长运算时间为10.0s,文献1方法的最长运算时间为8.7s。相比其它两种方法,所提算法更加节省时间和成本,具有显著优越性。
为了验证所提算法的图像标注效果,对比所提算法与文献[1]方法的对比结果,如图3所示。

图3 图像标注效果对比
分析图3(c)可知,所提算法能够标注出原始图像中的牛、房子、树木、绳子等物体,而文献[1]方法仅能标注出牛、树木与部分房子,标注的物体不够全面。通过对比结果可知,所提算法能够有效识别出图像中的目标信息。由于白色污染图像特征较为浅显、边缘具有模糊性,所提算法通过RC算法提取出了图像中的显著性信息,并增强了显著性的目标一致性,从而精准获取到了目标信息,提升了标注结果的精准性。
5 结论
为了解决传统方法对白色污染图像标注效果不佳的问题,提出一种融合显著信息的白色污染图像自动标注算法,本文的主要研究内容如下:
1)通过RC算法提取显著性信息,对物体先验信息进行融合,增强显著性。
2)对白色污染图像进行正则化处理,为自动标注打下基础。
3)通过遗传算法和FCM算法的结合,实现消除聚类中心收敛至极值现象的目的。
4)在SimMSVM自动标注中引入损失函数,进行合理运算,实现对白色污染图像的快速标注。
5)分析实验结果可知,所提算法在进行图像标注时,最长运算时间仅为4.8s,远低于传统方法,并且该方法的标注效果优于传统方法,说明所提算法具有较高的准确性,并且标注效果较好。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
黑龙江大学自然科学学报(2022年1期)2022-03-29
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
初中生世界·九年级(2020年12期)2020-03-10
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
大东方(2019年1期)2019-09-10
中国知识产权(2018年12期)2018-12-29
中国知识产权(2017年5期)2017-05-25
初中生之友·中旬刊(2015年4期)2015-06-10
