
基于邻域密度的异构数据局部离群点挖掘算法
2021-11-17 07:35王晓辉宋学坤王晓川
计算机仿真 2021年7期
王晓辉,宋学坤*,王晓川
(1. 河南中医药大学,河南 郑州 450046;2. 郑州大学,河南 郑州 450001)
1 引言
离群点挖掘就是搜索出数据集内的异常数据,这些异常数据通常表现出一定的应用价值[1]。最初对于离群点的理解比较偏向无益信息[2],认为一部分离群数据可能是采集过程中的偏差导致,对其深入挖掘会影响数据分析的整体质量。随着数据采集工具的性能提升,以及离群点理解的加深,认识到离群点含有特定的分布特征,可以通过分析获取其潜在的价值信息,是一种有益信息。离群点挖掘是数据分析领域的关键技术,有着广泛的应用场景。尤其是伴随着网络和大数据的发展,在信息攻击和金融诈骗相关检测,以及气象预报等方面[3],离群点挖掘都有着不可或缺的地位。
在实际应用的驱动下,离群点挖掘引发了很多相关研究。目前对于离群点的挖掘,较为常见的基础算法有距离、聚类,以及密度等[4]。文献[5]通过近邻的相互密度与γ密度对数据采取聚类处理,并利用聚类边缘判断出离群点。算法结合了聚类与密度两种方式,无需人工介入参数,但是算法没有对聚类时密度进行评判,从而无法准确判定离群点是否被有效挖掘。文献[6]在分层次划分基础上采用了距离方式来判断离群点,文献[7]利用邻域粒距离和粗糙集来判断离群点。这类基于距离的算法在数据稠密的区域很容易产生误判,且优化难度也较大。文献[8]通过邻域密度的比较,判断数据是否为离群点。该算法较LOF具有更好的高维性能,但是挖掘精度仍然需要合适的参数支持。
针对高维异构数据,结合现有算法存在的挖掘精度差、参数敏感等缺陷,提出了一种基于邻域密度的局部挖掘算法。通过对数据集合理分割,提高对大规模数据和高维数据的处理能力。并通过核函数改进邻域密度计算,降低算法对异构数据的敏感度。为防止离群点的误判,采用离群分数检查离群点挖掘结果。本文算法的设计过程综合考虑了离群点挖掘的准确度、效率和覆盖率,总体性能更加均衡。
2 异构数据离群点挖掘原理
假定str为一组高维异构数据,则对于str中任意的两个数据点di和dj,其距离可以描述如下
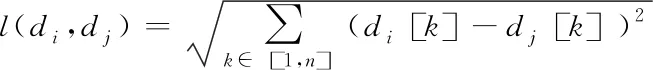
(1)
其中,n代表str的属性维度;di[k]、dj[k]分别代表di、dj对应k维的度量值。设存在非确定数据集为D,数据点di在D中的近邻可以描述为
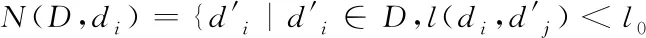
(2)
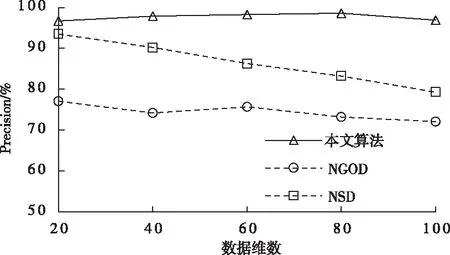
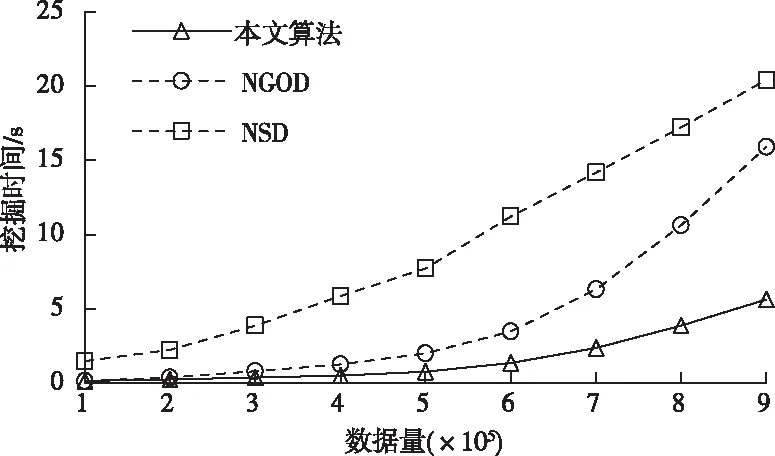
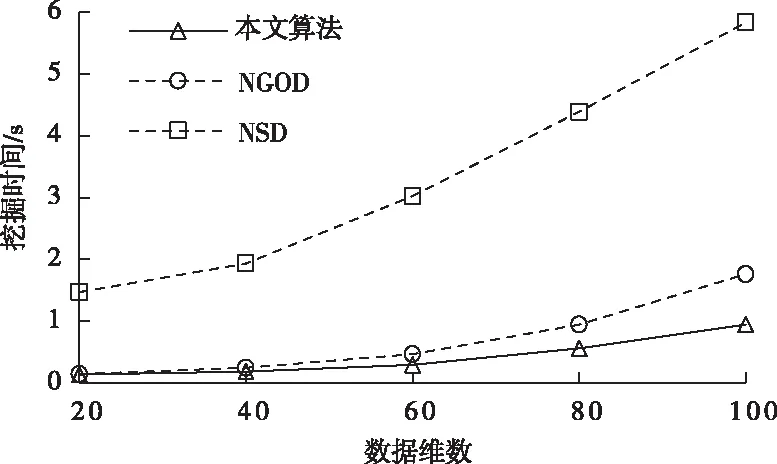
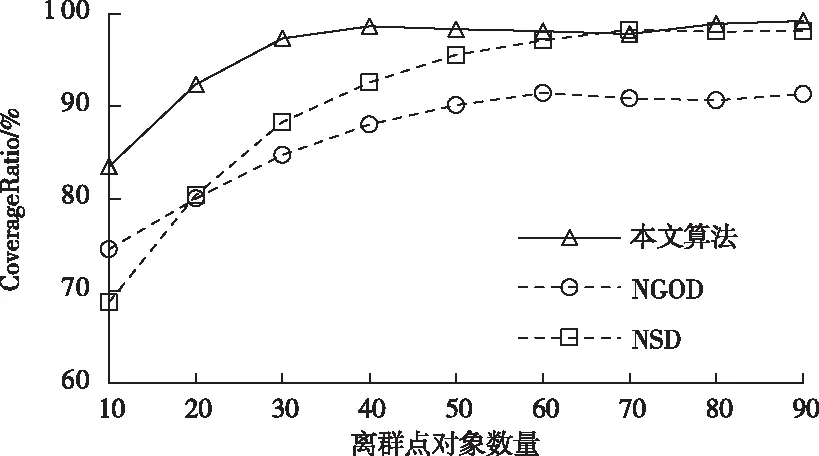
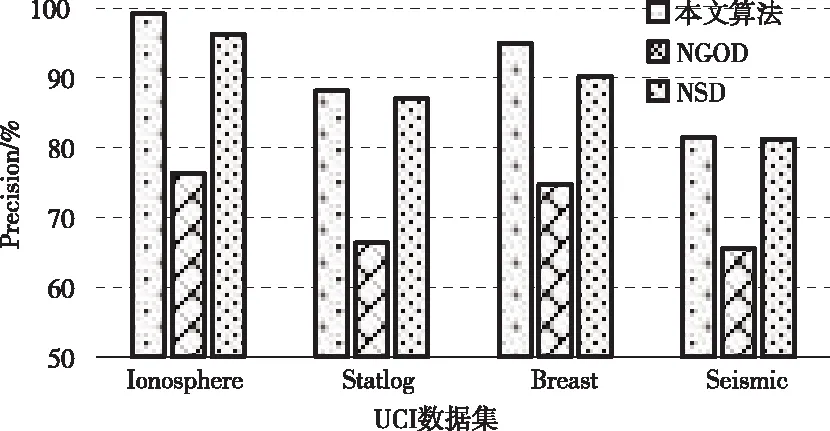
其中,l0表示搜索范围。如果搜索的邻域数据量为m,那么当|N(D,di)| (3) 随着数据规模的增加,对于高维异构数据而言,直接采取整体的离群点挖掘无法达到预期效果。而采取区域分割的局部离群点挖掘,则很容易使分割子区域过多或者过少,从而影响离群点挖掘效果。于是,本文根据节点计算性能进行区域分割。假定网络中包含n台处理机,则任意维度数据被分割的段数计算如下 (4) comp(pri)是处理机pri的计算性能。考虑到区域分割的合理性,通过各个维度的数据分布来评价区域分割的效果,公式如下 (5) 为保证区域分割在多维度间的分布均衡,在计算得到一维分布情况后,利用相邻维度构建二维分布,公式如下 (6) dis(i,j)描述了i与j构成的二维数据分布情况。与式(5)不同的是,Nm为i与j构成的二维空间区域m中的数据量。根据一维与二维的数据分布完成异构数据的区域分割,在dis(j)和dis(i,j)值最小处进行分割,同时满足分割段数,从而使高维异构数据分割得到数据分布均衡的子区域。 在分割完成的任意子区域中,数据集合描述为X={x1,x2,…,xn}。若该子区域存在h个属性,则X内的数据i可描述为xi=〈xi1,xi2,…,xih〉。其中,xih为数据i对应的h属性值。对于X内的数据xi和xj,它们的距离计算公式如下 (7) 计算得到X内l(xi,xj)的最大与最小值,分别记做max(l)、min(l)。根据式(1)将此时的邻域定义如下 N(xi)={xi|xj∈X,l(xi,xj) (8) 其中,R∈(min(l),max(l))代表搜索半径;xi的邻域数据范围为[0,n-1]。由N(xi)可以计算得到邻域密度如下 (9) 对于异构数据的非确定性,采用平均邻域密度计算缺乏稳定性和鲁棒性。考虑到核密度在非平稳数据处理方面的有效性,这里采取核密度来描述局部密度。由于它可以根据高斯分布得到数据出现次数,因此与数据的异构特性无关。 对于分割子区域中数据集合X内的任意数据xi,假定其密度是de(xi),则引入xi核函数可得 (10) Rg(xi)=R(xi/g)/g,R(xi)代表xi核函数。de(xi|g)代表xi+g密度,g的平均值是0。如果g足够小,那么de(xi|g)近似等于de(xi)。利用de(xi|g)计算得到g的后验密度,公式如下 (11) pde(g)是对g求解先验密度。采用贝叶斯对pde(g)进行估算,可得 (12) a代表超参数向量。通过任意xi的样本便能够得到de(xi|g) (13) 将de(xi|g)作为数据邻域密度,能够更好的接近真实数据密度。此时,由邻域及密度关系计算得到各数据离群度,公式描述如下 NSD(xi)= (14) NSD(xi)的值描述了xi在局部数据中的邻域状态。当NSD(xi)=0时,说明在搜索半径内xi不存在近邻,即xi严重偏离。当NSD(xi)值与1较为接近时,说明邻域密度较为接近,即xi和其它数据属性接近。当NSD(xi)∈(0,1)范围,且NSD(xi)值远离1时,说明xi比近邻数据具有更高的属性依赖,即xi属于正常数据。当NSD(xi)>1,且NSD(xi)值远离1时,说明xi的邻域密度较小,即和近邻存在偏离。基于以上分析,在NSD(xi)=0的情况下,判断数据xi一定为离群点;在NSD(xi)>1的情况下,判断数据xi有可能是离群点。 (15) 得到数据集X={x1,x2,…,xn}对应的权重集合为W={wx1,wx2,…,wxn}。当wxi值小于1,说明xi和近邻的距离较近,离群的可能性较小。此时,则可对xi采取剪枝,有利于降低数据处理量,改善数据挖掘效率。当wxi值不小于1,说明xi和近邻的距离较远,存在离群的可能。此时,则将xi保留,并利用如下公式计算加权分数 S=wxi/(N(xi)+1) (16) 为了防止近邻系统存在误差,引入逆k近邻结合加权分数,得到数据的离群分数如下 (17) k代表xi的近邻数量;代表逆k近邻数量。结合离群分数,可以在邻域密度基础上对数据的邻域状态和离群状态采取进一步确定,提高离群点挖掘的准确性。 邻域密度离群点挖掘算法基于Eclipse开发,采用Java语言编程,并通过MATLAB完成实验数据的展示分析。为了有效验证算法对异构数据离群点的挖掘效果,引入人工与UCI数据集,并与NGOD[7]和NSD[8]算法进行对比实验。 在对异构数据离群点挖掘算法评价时,采用准确度(Precision)与覆盖率(CoverageRatio)两个衡量指标。Precision的计算公式为 (18) TP是挖掘出的实际离群点个数;FP是离群点被错误挖掘的个数。Precision值越大,说明离群点挖掘越准确。CoverageRatio的计算公式为 (19) OStrue(D)是数据集合D内实际的离群点集;OS(D)是算法挖掘出离群点集。CoverageRatio值越大,说明离群点挖掘效果越好。 人工数据集能够灵活模拟不同规模和维数情况下的异构数据。本文通过随机方式产生n个数据,并以它们为中心,根据高斯规则产生聚簇数据。关于人工数据集的具体描述如表1所示。 表1 人工数据集描述 改变人工数据集的参数,分别得到数据量和数据维数对离群点挖掘准确度的影响,结果如图1、图2所示。根据结果对比可得,由于本文算法采用了核函数计算邻域密度,对于非确定异构数据具有更好的鲁棒性,所以在数据量或者数据维数改变的情况下,离群点挖掘准确度几乎不受影响,明显优于NGOD和NSD算法的性能。 图1 Precision与数据量的关系 图2 Precision与数据维数的关系 分别得到不同数据量和数据维数对离群点挖掘效率的影响,结果如图3、图4所示。根据结果分析可得,由于本文算法采用了数据分割和剪枝策略,可以有效降低待处理的数据量,所以算法的挖掘效率受数据量和维数的影响相对较小,即便是在数据量达到9×105,离群点的挖掘时间也仅为5.64s;数据维数达到100,挖掘时间也仅为0.94s。 图3 效率与数据量的关系 图4 效率与数据维数的关系 图5描述了覆盖率与异构数据中离群点对象数量变化的关系。由结果可以看出,在离群点对象为40时,本文方法的CoverageRatio指标已经达到98.63%,而此时NGOD和NSD算法仅为88.04%、92.56%。表明本文方法对于异构数据具有更好的挖掘效果,能够有效利用有限数据对象,分析检测出其中包含的离群点。 图5 覆盖率结果对比 UCI数据集能够反映实际应用场景,本文选择UCI中的Ionosphere、Statlog、Breast和Seismic四种数据集,关于它们的具体描述如表2所示。针对Ionosphere、Statlog、Breast和Seismic,将离群点确定为类型较小的数据。 表2 数据集描述 得到各数据集下离群点挖掘的准确度和效率,结果如图6和图7所示。根据结果可知,数据集的差异会对离群点的挖掘准确度产生一定的影响,但是本文算法无论在哪一种数据集下,都能获得良好的准确度,同时保持良好的挖掘效率。表明本文算法对于异构数据离群点的挖掘具有良好的普适性。 图6 不同数据集下Precision对比 图7 不同数据集下效率对比 关于高维异构数据,提出了基于邻域密度的局部离群点挖掘算法。利用区域分割将高维数据拆分成合理的子区域,降低大量高维数据的处理难度。采用核邻域密度替代平均邻域密度,使密度计算与数据异构无关。最后在邻域密度基础上对数据的邻域状态和离群状态采取进一步确定,提高离群点挖掘的准确性。通过仿真结果,说明数据量和数据维数都是影响数据离群点挖掘的主要因素,但是本文所提算法的离群点挖掘准确度、覆盖率,以及效率均明显优于对比算法,且对于不同类型数据集具有更好的适应性。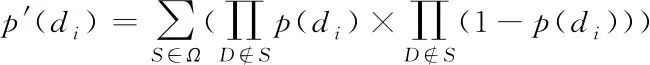
3 数据集区域分割
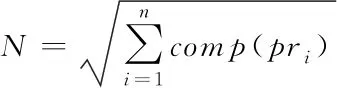
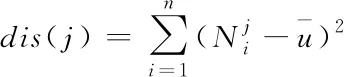
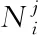
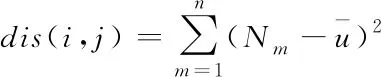
4 离群点挖掘算法
4.1 基于核邻域密度的离群点检测

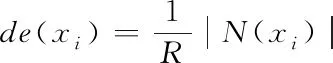
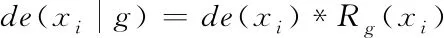
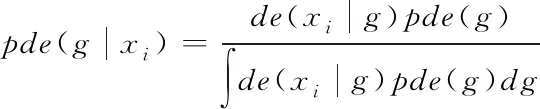
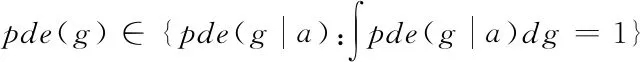
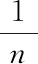
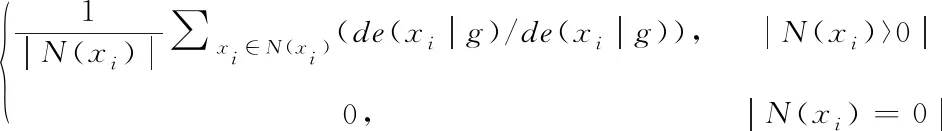
4.2 离群分数
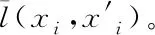
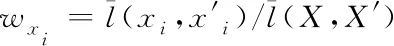

5 仿真与结果分析
5.1 实验环境与评价指标

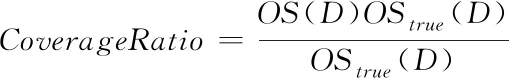
5.2 人工数据集


5.3 UCI数据集

6 结束语
猜你喜欢
农业工程学报(2022年7期)2022-07-09计算技术与自动化(2022年1期)2022-04-15河南科技(2021年26期)2021-03-22科学导报(2020年85期)2020-01-13电子技术与软件工程(2019年8期)2019-07-16意林(2019年11期)2019-06-30诗选刊(2018年7期)2018-07-09世界知识画报·艺术视界(2017年7期)2017-07-27阅读(中年级)(2016年4期)2016-11-19知识力量·教育理论与教学研究(2013年11期)2013-11-11
