
基于Fasttext和多融合特征的文本分类模型
2021-11-17 06:53张焱博
计算机仿真 2021年7期
张焱博,郭 凯
(北京邮电大学,北京 102206)
1 引言
随着网络发展的不断推进,个性化推荐成为热门领域。在文本信息不断激增的当下,有效化的挖掘文本信息、分析处理、归纳推理变得越来越迫切。继深度学习不断在视觉领域取得成果后,对自然语言文本分类也推出各种个性化算法进行了多角度的研究。
传统文本分类任务通常利用的是单一神经网络。目前常见的神经网络有:CNN、RNN、Fasttext、LSTM[1]。CNN网络结构简单,参数少且训练速度快,但是模型只能提取到位置相近词语的特征,难以融合间隔很长的词之间的特征。Facebook设计并开源了Fasttext,一种词向量计算和文本分类工具[2],它基于浅层网络设计,通过保留文本的低层信息,可取得和深度网络相媲美的精确度,但在较复杂的文本中表现比较无力。 RNN应用于文本分类中,可有效记忆全文文本信息特征。但RNN网络长序列中较早出现的文本易被遗忘,存在梯度消失和爆炸的情况。用LSTM进行文本情感分类的研究方法是对RNN神经网络的改进,通过增加门机制,对文本前端的信息选择性的保留和遗忘,相较于CNN更适合学习时间序列。但是随着文本增长,LSTM仍易丢失文本前端的信息,且表征性不够强。
为此,本文结合卷积神经网络、循环神经网络以及词向量平均的三种模型和其特点,提出一种基于Fasttext有效融合多特征的文本分类模型。实验将网上的新闻作为数据集,将其词向量作为CNN层、双向LSTM层和Fasttext层的输入,通过CNN和Bi-LSTM提取深层特征并赋予Attention权重。有效提升了文本分类的精准性。
2 相关工作
2.1 CNN
CNN即卷积神经网络,与传统神经网络相对比,网络架构相似,仍是层级网络,层的功能和形式有区别。它主要通过卷积层和子采样层对输入数据局部进行特征提取,并逐层组合得到全局信息,获得最终输出层结果。
2.2 Bi-LSTM
RNN即循环神经网络,作为序列处理的神经网络,序列位置的隐藏状态由当前位置的输入与前序位置的输入共同决定。RNN具有循环单元,它记忆前序信息并在网络中保存,为之后的计算提供记忆。但是对于一些较长的序列,循环单元中较早的输入强度越来越低。针对RNN短期记忆问题,创建了长短期记忆网络(LSTM)。LSTM模型只能记忆序列t位置之前的信息,无法用之后的信息进行分析。Bi-LSTM[3-4]突出(Bi-directional)双向特性,包含前、后向LSTM,前向网络记录t位置之前的信息,后向网络记录t位置之后的信息,二者的输出共同决定序列当前位置的输出,能够更好地捕捉双向语义依赖。
2.3 Fasttext
Fasttext文本分类工具采用N-Gram结构,基于词向量化的浅层网络,训练与测试高效快速。具体做法是把N-gram作为词向量输入,隐藏层对词向量做叠加平均,得到文本向量,最后连接输出层,得到特征。
2.4 Attention机制
Attention机制最初被用于图像领域[5]。Attention机制是在一个序列中学习到每一个元素的重要程度,并对每一个元素分配相应的权重,从而提取出相关度更高的部分,提升模型的精确程度。Attention机制的实质是一个寻址(addressing)过程,给定一个和任务相关的Query,称作向量q,通过计算与Key的相关程度并将其附加于Value,从而得到表示相关程度的Attention Value。如图1。
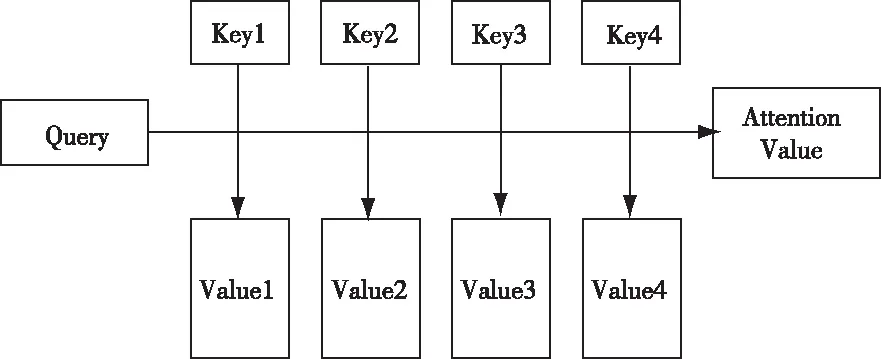
图1 Attention机制结构图
3 本文方法描述
本文提出一种AT-LSTM-CNN-FASTTEXT的混合模型文本分类。模型结构如下图2所示。主要包含6个模块:输入层、卷积神经网络层、双向LSTM层、注意力计算层、Fasttext层、预测层。
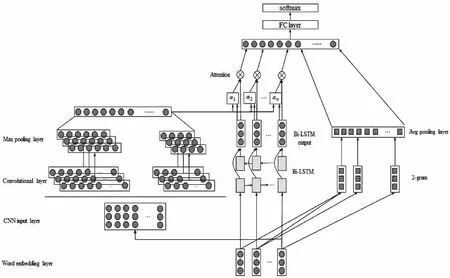
图2 AT-LSTM-CNN-FASTTEXT模型结构
1) 输入层对文本预处理,将每个词构建成词向量表示。
2) 双向LSTM层与卷积神经网络层分别将输入层的词向量作为输入,得到深层词向量的特征表示。
3) 注意力计算层将双向LSTM层与卷积神经网络层的输出特征作为输入,为双向LSTM层输出的每个深层词向量计算合适的注意力权重值。
4) Fasttext层将输入层的词向量进行2-gram处理,作为自己的输入并作叠加平均,得到词向量的浅层表示。
5) 将Fasttext层的输出与注意力计算层的输出拼接并作为预测层的输入,预测层基于该特征预测文本分类。
3.1 输入层
基于注意力机制的分类模型输入由中文词向量构成。将词序列转换为词向量W={w1,w2,w3,…,wn},wi∈Rm,其中:n表示分词后token的数量,m表示为词向量维度。
3.2 双向LSTM层
LSTM神经网络适合捕捉文本中长或短时依赖,且双向LSTM网络可以通过向前的状态与向后的状态分别捕捉到前时间步长与后时间步长。相应的,双向LSTM网络可以同时考虑到上下文的内容。本模型将W作为输入,双向LSTM的前向处理与后向处理步骤如下
(1)

(2)
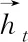
3.3 卷积神经网络层
定义一个卷积层为用大小为x×y的卷积核P对输入矩阵X进行卷积操作。每行的输出结果如下:

(3)
其中:a代表卷积网络中的第a个通道,X(i,i+r-1)是第i至第i+r-1行特征,b是偏置量,f是BatchNorm2d归一化处理,ReLu是线性整流函数,ri是通过卷积操作得到的第i行输出结果,设置滤波器纵向移动步长为1,最终得到的卷积结果为
Ra=[r1,r2,…,rn-r+1]T
(4)
对得到的局部特征进行Max Pooling处理提取的局部最大特征代替局部特征,以减小特征数量

(5)
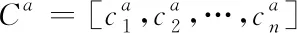
(6)
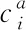
Ca=Conv(X)
(7)
对于每一个CNN模块,有
Cj=Conv_3(W)
(8)
其中Conv_3代表对输入词向量做3次Conv操作,j代表第j个CNN模块的输出。将所有CNN模块的输出进行拼接,得到卷积神经网络层的输出
U=[C1,C2,…,CJ]
(9)
其中J为卷积神经网络层中CNN模块的个数。
3.4 注意力计算层
CNN神经网络只能学习位置相近的文本特征,LSTM神经网络在长文本下容易丢失文本前端信息。因此采用Attention机制,将CNN与Bi-LSTM的高层特征融合,进而弥补Bi-LSTM丢失前端信息的问题。根据卷积神经网络的深层特征对双向LSTM网络的深层特征分配注意力权重,得到融合特征表示。经过Attention机制赋予权重,深层特征表示如下
Z=α·HT
(10)
其中,α为打分函数score函数经过softmax处理得到的结果,代表双向LSTM深层特征中第i个特征的注意力权重值,其公式为
α=softmax(score)
(11)

(12)
3.5 Fasttext层
对输入层词向量W进行2-gram处理。对于每相邻两个词向量,计算它们的平均词向量

(13)
拼接每个平均词向量得到
V=[v1,v2,…,vn-1]
(14)
在词向量的维度上,对每个词求平均得到Fasttext层的输出
(15)
3.6 预测层
因为经Attention机制计算权重的深层特征与浅层特征互补,将注意力计算层得到的输出H与Fasttext层K进行拼接得到预测层的输入I
I=[H,K]
(16)
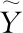

(17)
4 实验方案与仿真验证
实验开发环境是Pytorch 1.6.0,开发工具使用Jupyter notebook。计算机操作系统Windows10, CPU:Intel Core i7-8750H,显卡:GeForce GTX 1060,内存:DDR4 16G,
4.1 实验数据
本文实验以清华大学的THUCNew数据集为依托。该数据集具有财经、彩票、房产等14个类别。本文选出其中科技、时政、娱乐、体育、房产、家居、游戏、教育、财经、时尚共10个类别,每个类别的数据6500条。训练集由其中的90%构成,测试集选用剩余的10%。对每条语料进行清洗,使用jieba对语料进行分词处理操作。若语料长度超过500,取前250个字与后250个字做拼接处理。词向量采用预训练的中文维基百科词向量,每个词向量维度是300。
4.2 实验参数
本实验模型中CNN层所使用的参数见表1。对于每次卷积操作得到的结果进行BatchNorm2d操作以增强网络稳定性。

表1 CNN网络参数
Bi-LSTM层选择Adam为优化函数,所使用的参数见表2。

表2 双向LSTM网络参数
4.3 实验分析与结果
4.3.1 采用预训练词向量的完整数据集实验
将本文提出的模型(AT-LSTM-CNN-FASTTEXT)与Bi-LSTM模型、CNN模型、无FASTTEXT模块的融合模型(AT-LSTM-CNN)在完整预处理数据集上实验,对比模型的超参数与本方法中超参数相同。图3、图4分别给出了AT-LSTM-CNN-FASTTEXT模型、CNN模型、Bi-LSTM模型、无FASTTEXT模块的融合模型的准确率与损失函数变化图。
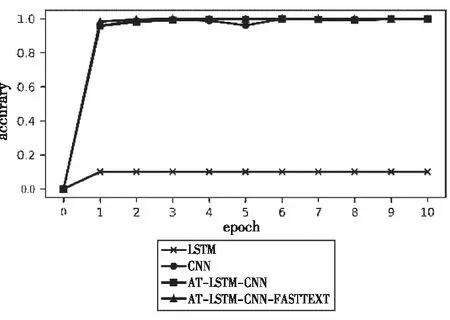
图3 各类模型实验准确率变化

图4 各类模型损失函数变化
由表3可以发现,本文模型收敛速度快且准确率均高于AT-LSTM-CNN、CNN、Bi-LSTM几种模型。在epoch为1时,本文提出的模型分类准确率比AT-LSTM-CNN模型提升2.5%,比CNN模型提升了2.4%,比Bi-LSTM模型提升88%。这是因为当epoch少时,CNN, AT-LSTM-CNN等深层网络无法较好的学习到深层特征,而本文模型中FASTTEXT模块可以较好的捕捉到浅层特征并迅速调整参数,使得本文模型有更好的收敛性。当epoch为2时,AT-LSTM-CNN模型与本文模型分类准确率相差1.6%,CNN模型与本文模型分类准确率相差0.7%。对比图4发现,除Bi-LSTM的损失函数基本保持不变外,其它模型损失函数减小到稳定值的速度慢于本文模型,但在4 epoch后均下降到一个相近的稳定值,除Bi-LSTM模型外,都有较好的收敛效果。原因为Bi-LSTM容易丢失文本前端的信息,导致信息在迭代过程中丢失。对比不同模型在各epoch下的准确率可以发现,本文模型在第1个epoch便取得最佳效果。

表3 各模型准确率(%)随epoch数的变化
4.3.2 采用预训练词向量的部分数据集实验
本文不仅在整个数据集上与其它模型进行对比,还按照不同的比例对训练集选取一定量的数据进行训练。不同百分比对应数据量见表4。在epoch为1的前提下,不同模型分类预测准确率的变化见表5。

表4 训练集数据量占比
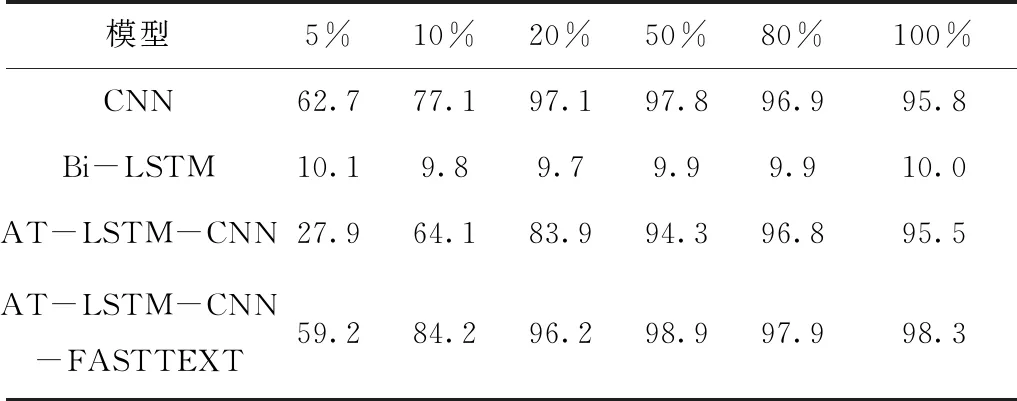
表5 1 epoch下分类预测准确率(%)随数据量的变化
训练数据量分别为5000,25000,50000时,本文模型、CNN模型、Bi-LSTM模型与去除FASTTEXT模块的融合特征模型(AT-LSTM-CNN)的分类准确率,如图5-图7所。

图5 数据量5000时各模型准确率

图6 数据量25000时各模型准确率
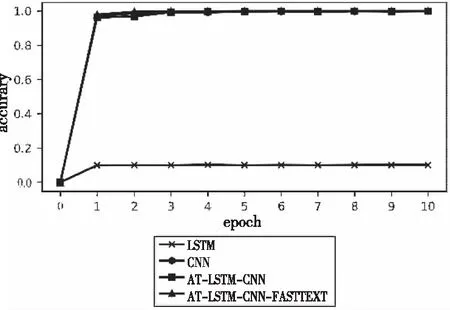
图7 数据量40000时各模型准确率
通过对比发现,本文AT-LSTM-CNN-FASTTEXT融合模型训练数据条数为5000时,在收敛速度上明显强于AT-LSTM-CNN融合特征模型。在1 epoch下,由于训练数据集较小,较复杂的AT-LSTM-CNN网络在epoch较少时难以对更多的参数有效的调整,而本文模型中的FASTTEXT模块可以较快速准确的学习文本的浅层特征,使得本文模型准确度比单CNN模型高7%,比AT-LSTM-CNN模型高出约20%。随着训练数据集的变大,本文模型在epoch为1时的准确率不断提升且在epoch增加的情况下准确率始终高于CNN、Bi-LSTM、AT-LSTM-CNN模型,当数据集为整个测试集时,本文模型在1 epoch条件下准确率在四种模型中最高,具有更快收敛速度。
4.3.3 采用未训练词向量的完整数据集实验
将AT-LSTM-CNN-FASTTEXT模型、CNN模型、Bi-LSTM模型、AT-LSTM-CNN模型在未引入预训练词向量的不同大小训练集上进行训练,数据的大小同表4,在epoch为1的前提下,随数据量的变化,准确率见表6。

表6 无预训练词向量1 epoch下分类预测准确率(%)随数据量的变化
在训练集小的时候,具有注意力机制的AT-LSTM-CNN与AT-LSTM-CNN-FASTTEXT模型在1epoch下准确度明显高于CNN模型与Bi-LSTM模型。随着训练资源增加,训练数据条数为10000时,AT-LSTM-CNN与AT-LSTM-CNN-FASTTEXT两模型分别比CNN模型准确率高出4.6%与19.1%,AT-LSTM-CNN-FASTTEXT模型效果更优。这表明通过使用LSTM与CNN特征进行交互,具有Attention机制的模型捕捉到的特征相比单纯使用CNN模型或Bi-LSTM模型更有效,具有更好的分类准确率。
5 结束语
本文提出了一种基于Fasttext和LSTM、CNN的AT-LSTM-CNN-FASTTEXT混合模型进行文本分类。该模型利用Fasttext对文本的浅层特征进行提取,同时利用CNN网络模型对文本局部特征提取,利用双向LSTM网络进行全局文本特征提取并通过Attention机制将卷积神经网络的深层特征对双向LSTM模型的特征分配注意力权重。将浅层特征与深层特征相结合对文本类别进行预测,充分考虑了局部文本与全局文本的语义信息。在实验过程中,对比本文模型、CNN模型、LSTM模型、AT-CNN-LSTM模型,结果表明,本文AT-LSTM-CNN-FASTTEXT融合特征模型能够有效提取到文本浅层和深层特征,准确率更高。本文仅依托THUCNews中的部分数据集验证了模型的有效性,后续计划针对不同分类任务进行实验,探究模型泛用性,并对模型进一步改进。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
高中生学习·高三版(2016年9期)2016-05-14
