
基于分布式集群的语料库防篡改检索方法
2021-11-17 12:04安玉香
计算机仿真 2021年9期
安玉香,李 檀
(1.沈阳建筑大学国际学院,辽宁沈阳 110168;2.沈阳建筑大学,辽宁沈阳 110168)
1 引言
分布式集群是通过分布式搜索引擎,形成的一种完成大规模分布式资源信息数据的检索方法。其通过高速网络环境,搭建分布式搜索引擎集群系统,进行分布式并行资源数据信息检索[1]。分布式搜索引擎根据设计模式可划分为分布式元搜索引擎、散列式分布搜索引擎、P2P分布式搜索引擎等。分布式搜索引擎集群可安全、高效的完成海量资源数据的存储、索引、检索[2]。随着网络资源的不断增加,检索系统受到索引文件和索引库的数据量的增加,使自身维护成本大幅度增加,导致检索响应的时间提升,并且响应速度降低。以语料库为例,其中存放海量的、语言实际使用中真实出现过的语言材料,而电子计算机是承载语料库语言知识基础资源的载体,并且真实语料需要经过分析和处理后,才可以成为有用的资源[3]。由于语料库的类型较多,涵盖的语料内容广泛,并作为语言学研究的基础资源,其在使用过程中,容易受到人为篡改,导致资源破坏和受损。
因此针对语料库防篡改检索进行研究,文献[4]根据设计区块链数据库系统框架,将区块链技术应用于分布式数据管理,然后提出了一种基于哈希指针的不可篡改索引,根据该索引快速检索区块内数据,以此实现区块链的查询,最后通过实验测试数据库的读写性能。但是该方法的检索开销时间较长;文献[5]提出了一种基于PKEKS的关键字安全的可检索加密方法,通过在系统中添加可信赖的安全中心生成可信参数,并将生成的可信参数一起加入到加密过程的方法中,完成加密检索。但是该方法的检索误差相对较高。针对上述方法存在的问题,本文提出基于分布式集群的语料库防篡改方法,该方法采用分布式检索引擎集群完成检索,可减少检索开销时间,提高检索准确率。
2 基于分布式集群的语料库防篡改检索
2.1 分布式集群运行结构
一个完整的分布式集群,以分布式引擎为核心,设计一个高效、安全的分布式检索引擎集群。其具备高效的集群检索功能以外,还要具备负载均衡、容易扩充和防篡改的功能[6]。分布式搜索引擎集群,采用分布式的设计结构和集群协调,完成在每个部分的实现和完成相应的运行,主要包含爬虫集群、存储集群、索引节点集群、联合索引服务集群和前段服务器集群。其具体结构如图1所示。

图1 分布式集群运行结构
1)爬虫集群:将抓取和挖掘到的语料库资源数据存储到存储集群中,是爬虫集群的主要工作。
2)存储集群:其主要作用是将爬虫爬取或者挖掘的资源数据进行存储。
3)索引节点集群:该集群通过在索引服务器上建立索引,实现存储集群中的资源数据实行解析以及防篡改。
4)联合索引服务集群:将索引节点集群解析后的资源数据实行存储以及向用户提供查询服务[7]。
5)前段服务器集群:该集群为避免单点失效和提高自身的可用性和处理能力,采用负载均衡和故障转移设计,使每个成员都可通过相同的访问接口,直接获取web应用服务。
2.2 爬虫集群的语料库浏览行为数据挖掘
通过分布式集群运行结构中的爬虫集群,采用决策树算法准确挖掘语料库浏览行为数据,决策树算法可有效完成语料库海量数据中易解析形式的挖掘。信息增益的属性决定决策树ID3算法分析节点的检测属性,决策树分支根据语料库浏览行为检测属性的已知值构建,每个子集都可用根节点属性的各值表示,在每一个子树中规划递归的实行上述步骤,当子集内元素为同类时,规划停止,则语料库浏览行为决策树构建完成[8]。
设置不同的语料库浏览数据为{w1,w2,…,wr},其数量为r,浏览行为的检测属性为W,则r个语料库浏览行为{g1,g2,…,gr},利用属性W实行总体浏览过程G规划,并且G内样本在子集Gy中体现,其在W上存在dy值。如果G节点的分支相对应的是子集,Gy中类px的样本数用Gx,y表示。则可体现W规划的语料库浏览行为的子集熵公式为

(1)
式中,第y个子集权用(gx,y,…,gn,y)/g表示,其等于子集内样本数量除以G内总样本数,W值为w,F(W)和子集规划纯度呈负相关性。则选定的子集Gy的计算公式为

(2)
式中,Qx,y表示Gy内样本属于px的几率,且Qx,y=Gx,y/|Gy|。
采用决策树ID3算法通过上式,构建语料库行为样本判定数,完成语料库浏览行为的准确挖掘[9]
H(W)=Gy-F(W)
(3)
2.3 数据关键特征防篡改检索
为防止语料库资源数据的篡改,采用数据关键特征防篡改检索方法将监控代码植入语料库浏览行为数据中,防篡改检索是利用变更后的语料库资源数据特征、软件程序等实现,该变更是改变控制流完成[10]。为获取语料库中分布式大数据实时关键特征状态,并且不会对语料库的资源数据整体结构造成改变,在数据的合理部位植入监控代码。语料库资源数据特征的正常状态可采用函数级控制流图描述,通过检验后的资源数据特征判断其是否存在篡改行为,该检验利用函数运行信息实现。
为提高防篡改检索的攻击性,对语料库资源数据各特征函数实行加密处理,想要对资源数据特征实行篡改,则需要采用每一个函数的解密钥进行函数解密,并且分别采取传输和存储对各函数实行处理[11]。
如果[0,1]内的特征函数用f(x)表示,则多项式函数Ts(x)为

(4)


(5)
依据式(4)和式(5)可得

(6)
语料库防篡改检索密钥的选取,以每个部分加密方式的区别为参考,并且需满足下述条件
K2i=Fi(Ui,Ri,Hi(CF))Ts(x)
(7)
式中,第i个特征的解密密钥用K2i描述;第i个特征的密钥生成函数Fi描述;分解用户码的第i个值和分解注册码的第i个值分别用Ui和Ri表示;第i个特征函数运行信息生成的散列值用Hi(CF)表示,其中数组为CF。防篡改架构如图2所示。
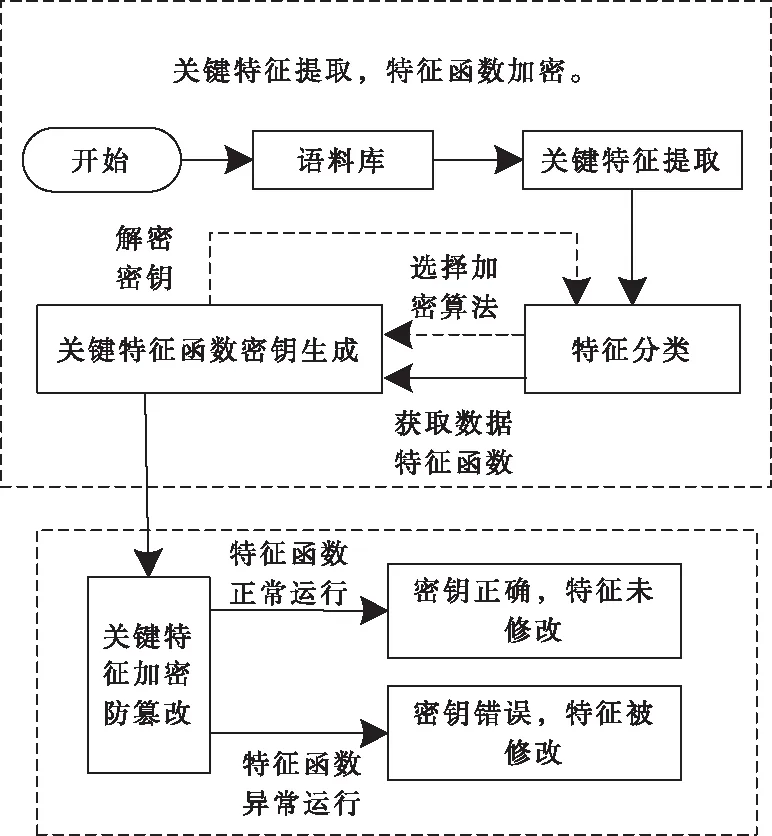
图2 数据关键特征防篡改架构
采用密钥生成函数运算获取各元素的解密密钥,该生成函数隐藏在资源数据特征内,由数个加密代码元素组成密钥。按照每一个特征的顺序完成资源数据特征函数运行,后一个特征函数的解密需要保证前一个特征函数的正常运行[12]。如果解密密钥生成结果错误,无法正常解密,是因为其中任意一个资源数据关键特征被改动,导致特征函数无法正常运行或运行异常。为增加密钥的破解难度,需利用多种加密方式构建多个差异化密钥生成函数,以此可使语料库资源数据库中分布式数据特征函数防篡改检索的保护程度大幅度提升。
3 仿真分析
选取国内某语料库为测试对象,测试本文方法的防篡改性能。设置该测试对象资源数据信息量大小为35GB,其中共有7800个被篡改的资源信息数据,并且共植入100个监控代码,密钥长度分别为512bit和1024bit。
分布式搜索引擎集群配置为:操作系统为Windows XP Professional,CPU为Intel酷睿2.4GHz,硬盘160GB,负载均衡mod_jk-apache-2.0.55.so,集群监控MC4J 1.2 Beta 9。
在上述实验环境下将文献[4]方法和文献[5]方法作为本文方法的对比方法,完成相关对比试验。
3.1 浏览行为挖掘效率测试结果
topWeb和topApp两个请求为主要用户行为特征分析请求,为分析本文方法浏览行为的挖掘效率,统计三种方法在两种请求类型下,随着并发用户数量的增加,对用户行为挖掘的效率,结果如表1所示。

表1 用户浏览行为挖掘效率对比结果/s
分析表1可知:在两种请求类型下,随着并发用户数量的增加,三种方法的用户浏览行为挖掘时间也成小幅度上升,其中,本文方法的分析时间最短,较大程度低于两种对比方法的挖掘时间。说明本文方法的用户浏览行为挖掘效率较高,可快速完成用户浏览行为挖掘。
3.2 防篡改检索性能测试
为测试本文方法的防篡改检索性能,设置篡改信息数量为3000个,在相同密钥长度条件下,采用三种方法对3000个篡改信息进行检索,统计三种方法的防篡改检索结果,如图3所示。


图3 三种方法的防篡改检索对比结果
分析图3可知:在相同密钥长度条件下,本文方法篡改检出数量与实际数量最接近,当密钥长度达到1000bit时,本文方法的篡改检出数量达到3000个,可以将篡改信息全部检索出来,检错数量均明显低于两种对比方法,并且错误率均在0.15%以下;且文献[4]方法和文献[5]方法的防篡改检出数量与实际数量差距较大,检错数量和检错率明显高于本文方法。说明本文方法的防篡改性能最佳,能够准确的完成语料库防篡改。
3.3 时间开销测试
在监控代码植入并加密和发送解密函数运行信息并解密条件下,对比三种方法的时间开销,测试结果如表2所示。

表2 三种方法的时间开销对比结果
分析表2可知,发送解密函数运行信息并解密的开销时间高于监控代码植入并加密的开销时间,但是,本文方法的监控代码植入并加密和发送解密函数运行信息并解密的开销时间相差不大,并且低于两种对比方法,说明本文方法的防篡改检索性能优于两种对比方法,可在较小的开销时间范围内,完成语料库的代码植入加密和解密。
3.4 弹性测试
弹性测试,是指将安全代码去除一定数量后,防篡改性能的变化情况。测试三种方法分别在去除一定数量的监控代码后,防篡改程度,测试结果如图4所示。

图4 三种方法弹性对比结果
分析图4可知:本文方法在去除一定数量的监控代码后,防篡改性能的影响不大,将监控代码去除80个后,防篡改程度依旧在85%以上,只有监控代码全部去除后,防篡改程度为0;两种对比方法则随着监控代码的去除数量增加后,防篡改程度明显下降。说明本文方法只有在监控代码全部去除后才会失去防篡改能力,弹性较高。
3.5 应用效果测试
测试在不同的攻击次数下,应用本文方法前、后的语料库的安全程度,测试结果如图5所示。
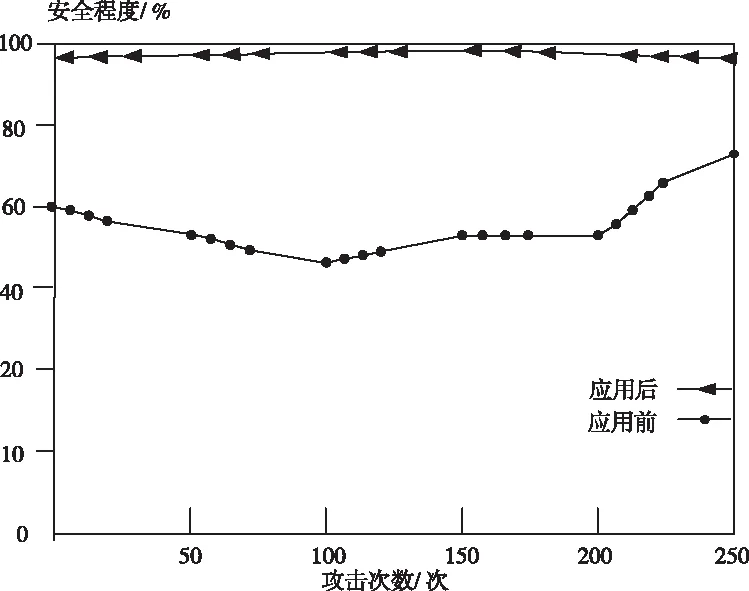
图5 应用前后的安全程度
分析图5可知:本文方法应用前,随着攻击次数的增加,语料库的安全程度明显下降,应用本文方法后,随着攻击次数的增加,预料库的安全程度几乎没有受到任何影响,均在95%以上,是因为本文方法将监控代码植入在资源数据中,并且函数的多点分布极大程度增加攻击者的代码定位难度,使攻击者无法准确判断监控代码的存在位置,因此可较大程度提高语料库的安全性。
4 结论
本文提出基于分布式集群的语料库防篡改方法,用于完成语料库的防篡改检索,经实验测试:
1)本文方法用户浏览行为挖掘效率较高,可快速完成用户浏览行为挖掘。
2)本文方法的防篡改检索错误率较低。
3)本文方法应用后,能够增加攻击者的篡改难度,可较大程度提高语料库的安全性。
下一步的研究内容是如何通过本文方法与其它方法的结合完成防篡改检索的同时,可以实现篡改预警以及篡改修复。
猜你喜欢
当代陕西(2022年5期)2022-04-19
故事作文·低年级(2022年2期)2022-02-23
故事作文·低年级(2022年1期)2022-02-03
外语学刊(2021年1期)2021-11-04
阅读(快乐英语高年级)(2021年4期)2021-07-11
阅读(快乐英语高年级)(2020年8期)2020-01-08
阅读(快乐英语高年级)(2020年10期)2020-01-08
计算机与网络(2018年2期)2018-09-10
师道·教研(2017年11期)2017-12-10
改革与开放(2010年6期)2010-06-04
