
基于随机失活的循环神经网络交通事件预测
2021-11-17 08:37张晓蕾孙士保赵鹏程
计算机仿真 2021年6期
刘 伟,张晓蕾,孙士保,赵鹏程
(1. 河南科技大学信息工程学院,河南 洛阳 471023;2. 北京信息职业技术学院软件工程系,北京 100018)
1 引言
交通事件管理是智能交通系统(ITS)的一个研究热点,由于城市街道的不断增多和繁忙时段交通需求日益增大,一旦发生交通事件,如果不能及时处理就容易造成交通拥堵,交通事件管理面临着巨大挑战。
针对交通事件不确定性较强和规律性较弱等特点,国内外研究学者提出两类预测模型:一类属于数学模型的方法,Luis Leon ojeda等人[1]提出的基于自适应卡尔曼滤波的多跳预测方法。成云等人[2]提出的基于差分自回归滑动平均和小波神经网络组合模型的预测方法。柳立春[3]提出的改进卡尔曼算法。虽然数学模型方法预测精度高、稳定性较好,但方法在构建和求解交通模型过程中难度较大,不适合于短时交通事件预测的要求。另一类是基于非数学模型的方法,Bingduo Yang[4]提出一种针对本地当日交通流估计和变量选择的回归方法,采用平滑绝对差分算法同时完成选择变量和估计回归系数,该算法在标准数据集中测试获得较好性能。Ricardo等[5]提出一种交通模式的动态分类方法,分为离线和在线两个阶段,实现了对日常交通模式的有效识别。邵俊倩[6]提出了基于小波模糊神经网络的交通流预测方法,通过分析神经网络、模糊逻辑和小波基函数的特点,得到了收敛性预测精度明显优于常规BP网络的模型。吴琛,程琳[7]构建了适合于交通事件检测的BP小波神经网络算法,与其它事件检测算法相比适合实时检测,具有平均检测时间短的优点。非数学模型预测方法相对来说实现要更简便,只要向模型里面输入足够的历史数据,不需要去构建庞大冗余的预测模型,最终得到的结果也可以满足在智能交通系统中的需要。
上述方法大多在离线或是平稳时间序列情况下的效果比较好,但实时交通事件数据因本身设备限制或外部因素干扰的不确定性,交通时序数据预测会出现预测结果精度不理想,模型曲线过拟合等问题。针对交通流数据预测中的问题,综合参数模型、非参数模型优缺点,在本文采用循环神经网络模型配合随机失活方法,处理交通事件序列数据并去除数据模型的过拟合,得到一个稳定的改进预测模型。
2 循环神经网络模型
循环神经网络(Recurrent Neural Network, RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接形成闭合回路的递归神经网络,可用于交通流量预测等各个方面[8-9]。RNN模型有很多,这里介绍最主流的RNN模型结构如图1所示。
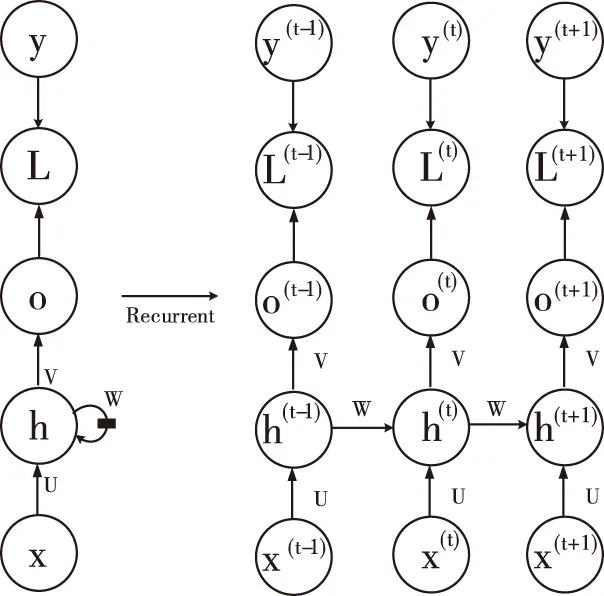
图1 RNN模型结构图
1)x(t)代表在序列索引号t时训练样本的输入
2)h(t)代表在序列索引号t时模型的隐藏状态,由x(t)和h(t-1)共同决定
3)o(t)代表在序列索引号t时模型的输出,只由模型当前隐藏状态h(t)决定
4)L(t)代表在序列索引号t时模型的损失函数
5)y(t)代表在序列索引号t时训练样本序列的真实输出
6)U,W,V这三个矩阵是模型的线性关系参数,它在整个RNN网络中是共享的,体现了RNN的模型的“循环反馈”的思想
7) 对于任意一个序列索引号t,隐藏状态h(t)由x(t)和h(t-1)得到
h(t)=σ(z(t))=σ(Ux(t)+Wh(t-1)+b)
(1)
其中σ为RNN的激活函数,b为线性关系的偏倚。序列索引号t时模型的输出o(t)的表达式比较简单
o(t)=Vh(t)+c
(2)
在最终在序列索引号t时预测输出为
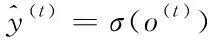
(3)
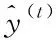
3 结合随机失活的预测模型的构建
交通事件特点是具有随机性,而随机失活方法处理这类事件的优点在于可以将复杂的外界输入简单化,降低它们之间的相关性、随机性。这种特性使得随机失活方法正好适合处理交通事件。
3.1 随机失活方法
随机失活(dropout)是对具有深度结构的人工神经网络进行优化的方法,在学习过程中通过将隐含层的部分权重或输出随机归零,降低节点间的相互依赖性(co-dependence)从而实现神经网络的正则化(regularization),降低其结构风险。
训练阶段神经网络会随机按概率p将部分隐含层节点的权重归零(如图2(b)),由于每次迭代受归零影响的节点不同,因此各节点的“重要性”会被平衡。引入随机失活后,神经网络的每个节点都会贡献内容,不会出现少数高权重节点完全控制输出结果的情况,因此降低了网络的结构风险,以缓解神经元之间隐形的协同适应,从而达到降低模型复杂度的目的。

图2 随机失活方法
从数学上来说,神经网络层训练过程中使用的标准 Dropout 的行为可以被写作
y=f(Wx)·m
(4)
其中f(Wx)为激活函数,x是该层的输入,W是该层的权值矩阵,y为该层的输出,而m则为该层的 Dropout 掩膜(mask),mask 中每个元素为 1 的概率为p。在测试阶段,该层的输出可以被写作
y=pf(Wx)
(5)
结合随机失活方法及主要代码如下所示。
Input: 样本数据并归一化
DropoutFraction的值
Output:预测和拟合值
BEGIN
Step1:load mnist_uint8;
train_x=double(train_x(1:2000,:)) / 255;
test_x =double(test_x(1:1000,:))/ 255;
train_y=double(train_y(1:2000,:));
test_y =double(test_y(1:1000,:));
Step2:初步构造了一个输入-隐含-输出层网络
权值初始化
Step3:设置学习率,momentum,激发函数类型,惩罚系数
Step4:每一次样本数据输入训练时,随机扔掉50%的隐含层节点
nn=nnsetup([861 100 10]);
nn.dropoutFraction=0.5;
opts.numepochs=20;
opts.batchsize=100;
[nn, L]=nntrain(nn, train_x, train_y, opts);
[er, bad]=nntest(nn, test_x, test_y);
END
3.2 算法描述与分析
本文将使用循环神经网络模型方法对输入的交通事件数据进行训练,并将训练出来的模型使用随机失活方法去除数据的过拟合,构建基于改进循环神经网络的交通流拥堵事件预测模型。其预测流程如图3所示。
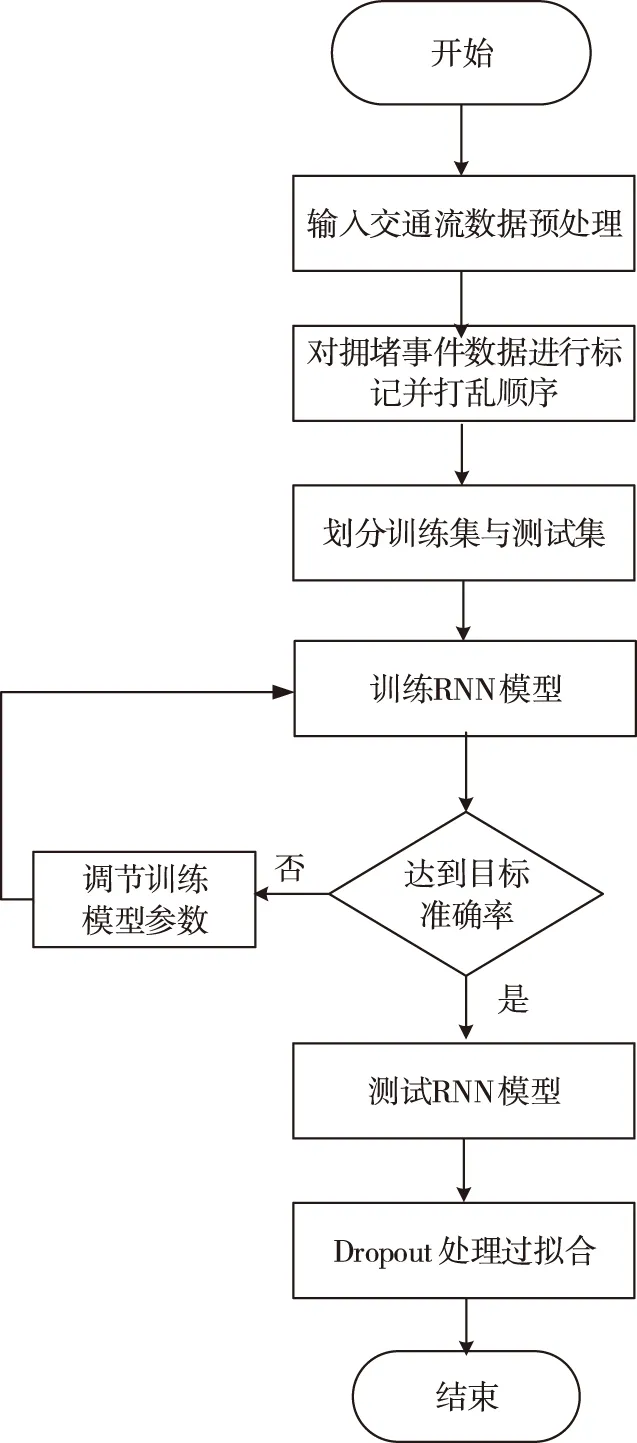
图3 基于RNN的改进交通流拥堵事件预测流程图
其中具体方法步骤如下:
1) 通过政府开放数据渠道,获取达拉斯区域2018年十一月整月的交通事件开放数据,原始数据的每条事件信息都包含了提交时刻路段的经纬度以及时间,把整个数据集里面的事件类型都变成事件编号,将问题转换成利用事件序列进行分类预测,对采集到的原始数据进行修复和归一化预处理。
2) 把交通堵塞事件数据中最严重的“大型交通拥堵”(large traffic jam)和“超大型交通拥堵”(huge traffic jam)合并成一个严重交通拥堵事件集合,对于每一个严重拥堵事件,追溯到前30分钟,把之前同一条道路上发生的事件,按照顺序存成一个列表。对没有任何其它事件先兆的空列表进行了清除。同样,从剩余事件集合中,随机找出了相同数量的非空有效序列,这些序列的后续紧随事件都不是严重拥堵。对严重拥堵的之前30分钟的事件序列标记为1;对于非严重拥堵之前30分钟的事件序列标记为0。打乱数据集中数据的顺序,但是保持序列和对应标记之间一致性。
3) 划分训练集和测试集。取其中80%的数据作为训练集数据,另外20%的数据作为验证集数据。利用事件类型数量和事件向量长度,构造一个初始嵌入矩阵,搭建循环神经网络模型,开始训练时,把刚才随机生成的初始嵌入矩阵挪进来,并且不改变嵌入层的参数。最后,开始训练搭建好的模型,并把模型的运行结果保存起来。
4) 训练好循环神经网络模型后,准确率曲线没有剧烈波动且后半程稳定在80%以上,但是损失值曲线发生了分叉。这是典型的过拟合。这是因为相对于复杂的模型,训练数据不够用。解决方法是增加训练数据,或者降低模型复杂度。立即增加数据不太现实,但是降低模型复杂度,可以利用在LSTM层上加入随机失活的方法调参来去除过拟合。
5) 将最终训练模型结果与传统BP神经网络预测模型对比分析得出结论。
4 实验验证部分
为了验证本文方法的有效性,设计实验进行验证。
4.1 实验数据集描述
用于论文研究的数据,是达拉斯政府的2018年整个十一月的Waze交通事件的开放数据。通过使用本文改进的循环神经网络来构建序列数据分类模型,利用序列模型找到规律进行分类预测。
4.2 实验评价指标
现在普遍使用的模型评价指标是平均绝对误差(MAE),均方根误差(RMSE)和平均绝对百分误差(MAPE)。如下,式(6)为 MAE 的计算公式,式(7)为 RMSE的计算公式,式(8)为 MAPE 的计算公式。
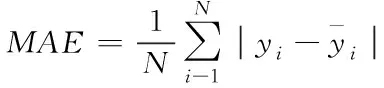
(6)
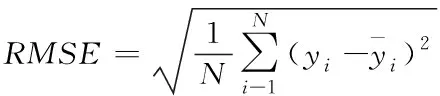
(7)
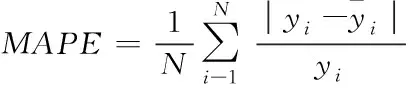
(8)
4.3 实验过程与结果分析
在Python中导入交通流事件数据,把交通堵塞事件数据中,对交通影响最大的“大型交通拥堵”数据收集起来,作为一个交通拥堵事件集合,其它剩余事件作为另一个集合。对每一个交通拥堵事件,找到事件发生前的10分钟,按照时间顺序将本条道路上发生的事件存为一个列表,然后去除其中毫无征兆发生的交通拥堵事件,这样的有效序列共有583个。再同样从剩余事件集合中随机找到583个后续紧随事件都不是严重拥堵非空有效序列,作为对照组来进行试验对比。然后将问题转换成利用事件序列分类预测严重拥堵的发生。标记交通拥堵发生前的事件序列为“1”;标记非交通拥堵之前10分钟的事件序列为“0”。
将实验样本分别代入第3节确定循环神经网络模型进行训练与测试实验,并与广泛应用的BP模型进行对比。通过数据分析,训练过程结束之后,利用matplotlib绘图功能来看一下训练的准确率和损失值变化,如图4、图5所示。
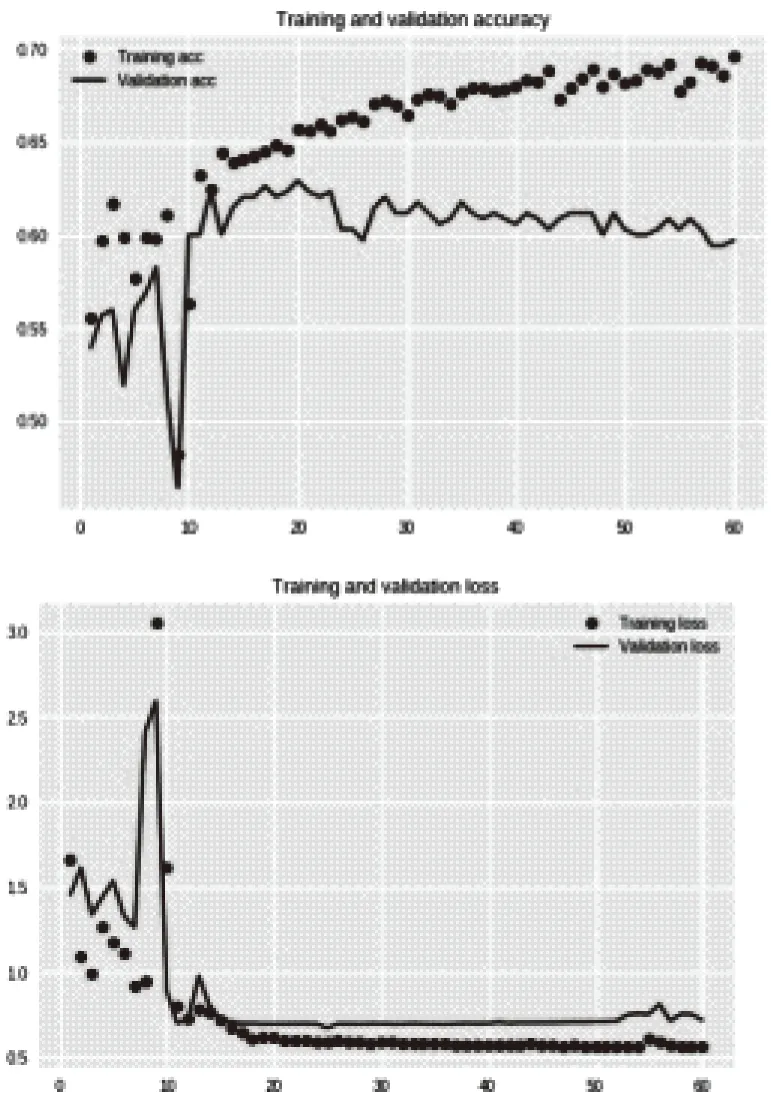
图4 BP神经网络预测值准确率与损失值曲线
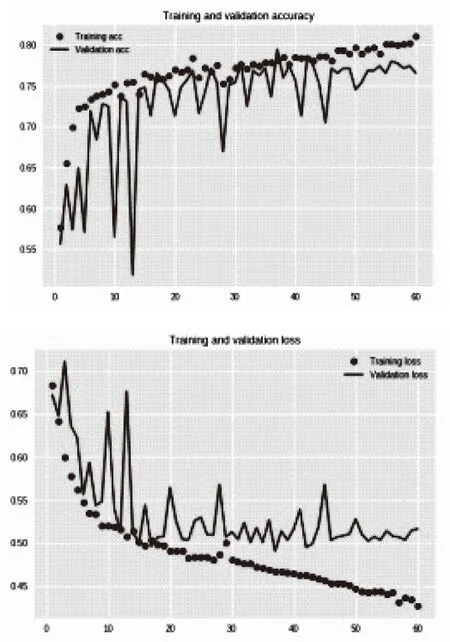
图5 循环神经网络预测值准确率与损失值曲线
从预测精度曲线或是损失值曲线来看,循环神经网络模型的精度和稳定性均明显高于BP神经网络模型,且循环神经网络模型的预测精度可达到80%,损失值保持在0.45以下。只不过曲线抖动比较厉害,稳定性差。但是检测集的预测精度就不是那么理想了,从半程之后,训练集和验证集的损失值变化发生了分叉,这是典型的过拟合现象。发生过拟合,主要原因就是相对于复杂的模型,训练数据不够用。这时候,要么增加训练数据,要么处理数据使其降维,或者降低模型复杂度。立即增加数据,不太现实。因为目前只有一个月里积攒的数据。所以我尝试利用随机失活的方法来去除过拟合。对其中LSTM 层上添加两个参数dropout和recurrent_dropout来改进循环神经网络模型,经过多次试验交叉验证,其值分别为0.15和 0.25时效果最优。试验结果如图6所示。
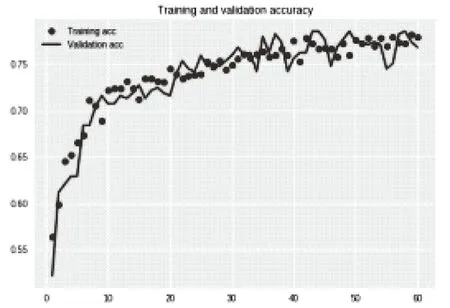
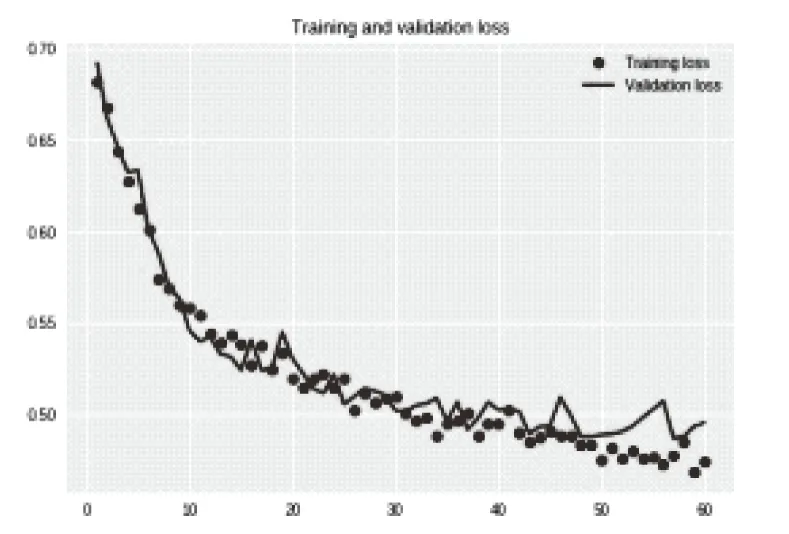
图6 改进后循环神经网络预测值准确率与损失值曲线
这次的准确率曲线,可以感受到训练集和验证集达到的准确率更加贴近,曲线更加平滑。看下面损失值曲线的变化就可以看出来过拟合的去除效果更为明显,可以看到训练集和验证集两条曲线的波动基本保持了一致。
将传统BP神经网络预测结果、改进BP小波神经网络预测结果与改进循环神经网络结果用评价指标进行对比,对比结果如表2所示。
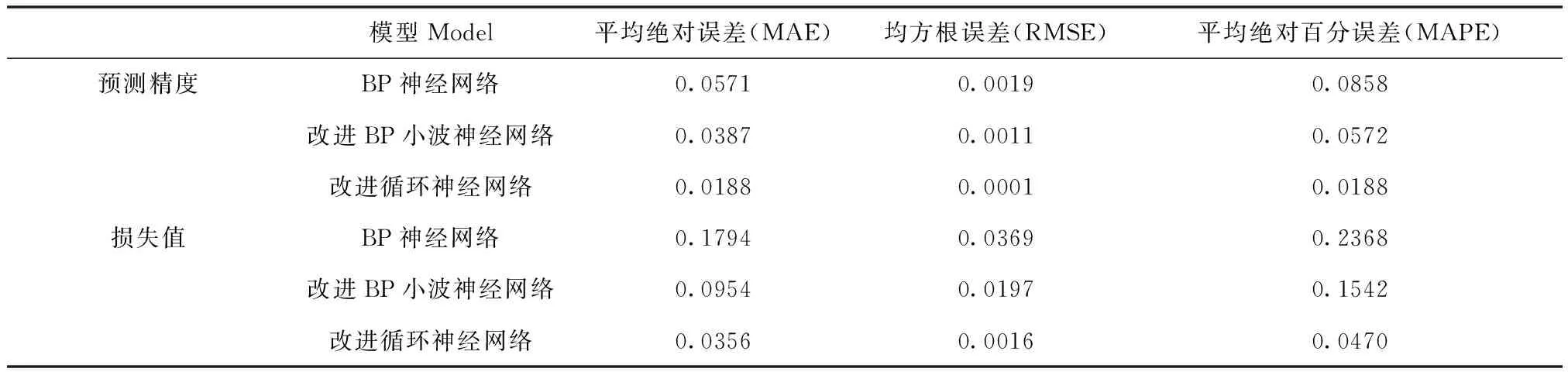
表2 预测模型精度与损失值分析
由表2可知,改进循环神经网络模型比传统的BP神经网络和改进BP小波神经网络模型预测精度高、损失值小,改进循环神经网络模型的MAE、RMSE和MAPE(保留4位有效数字)分别为 0.0188、0.0001和0.0188,与传统的BP神经网络和改进BP小波神经网络模型相比,MAE、RMSE和MAPE分别提高了3.8%、0.18%、6.7%和1.9%、0.1%、3.84%,由此得知在实时交通事件预测这类问题上,有预测精度高,损失值小等的优点,改进循环神经网络模型能够取得较好的预测结果。
5 结束语
本文将循环神经网络与随机失活算法进行结合组成改进循环神经网络模型,通过Python输入实时交通流时间数据,并在matplotlib中实现了对达拉斯数据的实例数据分析。通过实验分析和验证了基于随机失活的循环神经网络交通事件拥堵预测方法处理具有时效性和多维度的交通事件数据效果显著,在模型预测精度和损失值都得到了验证。今后的研究工作将主要集中在继续训练预测模型稳定性和如何分析国内主要路段高峰期交通事件,使交管部门可以未雨绸缪,提前做出干预。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中国教育信息化·高教职教(2022年4期)2022-05-13
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
煤气与热力(2022年2期)2022-03-09
软件(2017年6期)2017-09-23
人民交通(2009年9期)2009-10-29
小朋友·快乐手工(2009年4期)2009-04-28
