
基于虚拟现实系统的声乐教学平台优化设计
2021-11-17 08:37汪浩文板俊荣
计算机仿真 2021年6期
张 进,汪浩文,板俊荣*
(1. 南京航空航天大学国家文化产业研究中心,江苏南京211106;2. 南京航空航天大学艺术学院,江苏南京211106)
1 引言
由于声乐教学实践性强,演唱过程中的情感体验与表达极为丰富,在目前的虚拟现实教育领域中应用较少。在一些为数不多的虚拟现实教学应用中存在真实性差、交互体验不够理想、教学的可视化内容相对单一,以及流畅度欠佳的情况。这些问题主要归纳如下:
首先是部分研究者通过虚拟全景视频技术(ArcSoft Panorama Maker),制作三维全景图像数据,使演唱者能够在全景范围内跟随预设的教学主线进行视听交互,获取不同风格的视听体验效果[1-4]。在感知体验上缺少深度交互信息,缺乏将演唱情绪与表情语言惟妙惟肖的进行展现,难以建立具备深度性的交互功能。
其次是部分研究者通过次世代的引擎技术(VRPlatform),制作三维场景的深度信息,能够较全面地为用户提供关于演唱交互方面的情景选择,也能够实现一定的面部表情绑定[5-6],但是在渲染及流畅性上存在真实性差、图形算法不够优化,画面实时计算极易出现卡顿。
基于对以上技术优缺点加以分析,本研究试图以虚拟现实引擎技术(Unity3D)作为主要制作工具,系统性地针对建模、面部表情、手势捕捉、多角度相机记录进行全面的优化设计,以此为声乐演唱提供更加真实、细腻、交互多元化的应用方法。
2 工作原理分析
2.1 模型嵌入系统
在虚拟现实中,模型嵌入系统是表述虚拟现实体验效果的前期重要因素,它的几何分割功能能够对场景交互体验的流畅度起着决定性作用。即将同一模型分为3个等级的LOD(levels of detail)精度规范,以此在不同的视距范围内将模型精度灵活切换[7-10]。这种切换方式应遵循的原则是能够确保前景的模型精度相对较高,中景的模型精度适中或使用简模表达,而远景的模型精度相对较低,甚至可以通过贴图遮罩或图像替代的方式进行表达,进而使虚拟现实能够根据场景的不同视角进行实时优化。
2.2 面部捕捉系统
人脸的面部捕捉主要是先确定面部的眼虹膜、鼻翼、嘴角等五官轮廓的大小、位置、距离等属性,然后计算出它们的几何特征量,使其能够形成整体描述该面部的特征向量[11]。其技术的核心原则是遵循局部人体特征分析与神经识别算法。主要目的是利用人体面部活动的特征去与几何关系多数据形成的识别数据库中所有的原始参数进行比较、判断及确认的一系列过程。
2.3 手势捕捉系统
手势捕捉系统基于Oculus quest2手部定位追踪技术,对人体手部的关节部位进行关于空间坐标的捕捉,同时实时传输到虚拟现实的动画过程中[12]。其主要原理是采集每根手指的弯曲姿态,通过数据归一算法使所有手指形成统一的单字节数据格式,以减少冗余数据,同时利用平滑处理算法将手指之间的时空参数进行处理,使手势的骨骼及肌肉形成自然、柔和的运动状态。此外,手势捕捉的过程中会形成基于明显特征的分割方法,主要包括肤色分割与手形分割。
1)肤色分割:是一种通过使用集群肤色的方式,在颜色空间中建立精准坐标下的肤色模型,并借助RGB色域对肤色进行综合确认。
2)手形分割:是一种基于多模式融合的分割方法,主要是为了克服复杂环境对手部主要结构分割条件的限制,完善手型的表观特征与运动信息。常用的策略有分割几何特征、可变形特征及空间覆盖型特征等。
2.4 相机系统
虚拟现实中的相机系统通常为第一视角输入,也是一种主动视觉标定的形式,能够有效记录人眼观察到的动态视景[13-15]。与传统虚拟相机不同的是它并不需要使用已知尺寸的标定物,通过建立标定物上的坐标点及图像点进行对应的方式,就可以及时捕捉动态的序列帧图像,但是在一定程度上缺少增稳功能,如果需要得到稳定的摄像功能,需要在虚拟现实的程序底层做好必要的程序优化工作。
3 工作流程设计
基于对以上系统原理进行分析,可以归纳出虚拟现实在声乐教学方面的制作思路应从三维建模、面部捕捉、手势捕捉、相机处理等若干方面进行应用研究:首先,需要借助3ds Max作为模型建立的初始工具,分别完成场景及演唱角色的建模工作,同时在所有模型完善后应将场景模型与角色模型全部导入Unity3D虚拟现实制作平台,利用平台中的模型嵌入系统对模型进行适当的几何分割,确定好不同层级的LOD与场景的应对关系。其次,配合面部捕捉系统对演唱角色的面部进行识别及绑定,精准处理好面部主要肌肉结构的定位点。再次,通过手势捕捉系统完成手部骨骼节点的确认,将相应的数据与虚拟现实引擎接口进行联立计算。最后,通过对相机系统进行程序优化的方式,实时记录好演唱者在演唱过程中的具体表现,便于后续能够借助一定的途径直观地分析、评价演唱者应用虚拟现实前后的变化。总体而言,上述流程设计是以一种高效、简洁的制作思路为主,如图1。
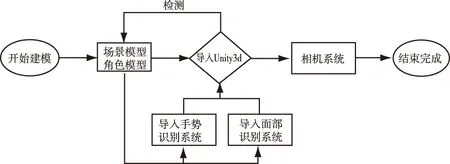
图1 工作流程设计
4 虚拟现实优化应用方法
4.1 模型的创建方法
模型在虚拟现实的制作及体验过程中至关重要。模型的结构准确性、面片分配状况、精度等问题将直接影响虚拟现实的仿真程度与交互程度。
4.1.1 场景模型
以某T型舞台场景为例,其主要制作方法为以下3个步骤:
1)首先,利用3ds Max中样条线编辑创建3000cm(长)×2200cm(宽)×1000cm(高)的T型舞台,将其转换为多边形编辑,将各个顶点焊接为整体,以便于后续对各个边界布线连接;
2)其次,利用网格布线对整体模型的细节进行处理,配合连接、挤出、倒角、插入等功能细化舞台模型的局部结构,对于舞台中心地面、背景、延长台上的造型可以通过独立建模后再对其进行整体的桥接处理;
3)最后,利用几何放样配合多边形编辑,对舞台周边的观众席、顶部灯架等辅助模型进行创建,建模过程中可以利用镜像、复制简模的手段为主,逐渐丰富好整体场景,如图2。

图2 舞台场景模型
4.1.2 角色模型
角色模型应在盒体元素下创建,利用多边形编辑对角色面部、肢体进行整体布线,以四边形布线为主,尽量确保在面部五官、肢体关节等需要虚拟现实动画运动的区域重点布线,细化结构关系,在一些不参与动画运动的区域可以通过塌陷、面片合并等手段对模型面数进行有效控制,如图3。将模型中无法避免的三角形布线放置在角色不参与动画计算的隐蔽区域,避免模型在虚拟现实的动画过程中出现面片褶皱等不利现象。

图3 角色模型
4.2 模型的优化方法
将模型整体导入Unity3D中,设置预览虚拟现实的帧率FPS帧率为70~90,在引擎中检测好模型面片的法线、顶点闭合情况,并在蓝图接口处,通过代码植入的方式对场景的细微局部进行二次优化,以满足模型的几何分割、空间坐标、面片处理、渲染烘焙等几个方面的优化工作,其程序设计如下:
int main(int,char**){
osgProducer::Viewer viewer;∥创建一个场景
viewer.setUPViewer():
∥加载osga地形模型到节点变量中
osg::Node* node=osgDB::readNodefile(“Wutai.osga”):
viewer.setSceneData(node);∥加载模型到场景中
∥进入渲染循环
viewer.realize();
while(!viewer.done()){
viewer.sync();∥等待所有cull和draw线程的完成
viewer.update();∥通过遍历节点更新场景
viewer.frame();∥渲染更新结果
}
viewer.sync();∥退出程序前等待所有cull和draw线程的完成
return;
}
4.3 面部捕捉的方法
由于系统采用的结构光原理,需要通过向面部方向投射光线,再利用读取物体表面光照信息数据来确定人脸形状。为此,在选择面部采集设备时,除了需要配置距离传感器、话筒、前置摄像头外,还需要满足具备依序排列的红外镜头、泛光照明灯、泛光感应元件及点阵投影器。通常情况下,点阵投影器可以向人脸投射3万多个肉眼不可见的光点所组成的点阵,需要通过红外镜头读取点阵图案,并与前置摄像头拍摄到的人脸进行联立计算,进而获得面部表情的深度信息,即真实的面部三维模型,联立计算需要搭建的4个数据接口分别为:
IFTFaceTracker:人脸追踪主要接口。
IFTResult:人脸追踪运算结果。
IFTImage:图像缓冲区。
IFTModel:三维人脸模型。
联立计算需要重点获取的数据信息分别为:
FT_CAMERA_CONFIG:彩色或深度传感器数据。
FT_VECTOR2D:二维向量数据。
FT_VECTOR3D:三维向量数据。
FT_Translate(X Y Z):所有用于人脸追踪所需的输入数据。
FT_Rotate(X Y Z):三维模型人脸角度数据。
FT_Scale(X Y Z):权重矩阵数据,如图4。
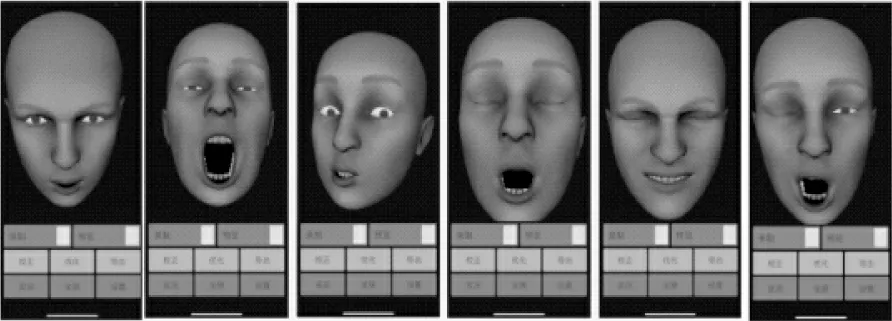
图4 面部捕捉后的效果
与通过二维图像进行面部捕捉的方法相比。Tj的人脸识别精度在0.1mm,能够超过图像2、视频1及平面0。当光线条件Ri不够理想时,由点阵投影器发射出来的光线-σ、接收光线σ这种主动获取面部信息的方法,也不会影响Tj的识别效率,其面部捕捉系统的优化方法可以改变如下
4.4 手势捕捉的方法
手势捕捉是虚拟现实中的技术难点,需要通过演唱者戴着虚拟头显设备Oculus quest2,以及手部定位追踪器与电脑进行相连。之后,在头显设备的前端再安装深度感应相机,且向下倾斜13.4°,以此使演唱者可以从虚拟现实的体验过程中实时观测到自己的双手,及时跟踪自己的指尖的变化,其手势从左到右依次为:向后、停止、向前。若指尖位置在零坐标静止区域区(zc)内,则无法产生运动;当指尖向前伸出至静止区域以外时,则被试运动速度的红色进度条会随指尖距离产生线性增加,当手指关节朝向另一个方向移动,且朝向掌心向下时,移动到静止区以外,红色进度条会向后产生微妙的运动。具体表现为一种手掌的自然伸缩变化的过程,该过程是以演唱者右手食指远端到手掌中心的距离以mm为单位,根据每人手掌尺寸按比例扩大2.74倍,以此减少在手指弯曲时所带来的噪波,其设置参数如下:
1)β--beta coefficient,β表示斜率系数=速度/γ(表示食指指尖到静止区边界的距离),向前运动γ=(position×2.74)-(zc+dzw),向后运动γ=(zc-dzw)-(position×2.74)。
2)静止区--dead zone,在实验开始时,当测试者把他们的手放在一个放松的、轻轻弯曲的,当手指处于舒适的位置时,就可以确定手势的零静止位置,如图5。

图5 手势的零静止
3)α--exponent-velocity=(β×γ)^α,当一个参数发生改变时,其它参数固定在它们的中间值。例如,β=21 m/s, dzw=25mm,α=1.0.三个参数的测试顺序依次为系数、静止区宽度、指数α。每个测试者在一个参数内测试三个水平的顺序是随机的。对于每个参数水平,测试者完成一个大目标(2m)的实验(30个目标)和一个小目标(1m)的实验(30个目标)。这三个参数之间的测试顺序不是随机的。
该实验时间至少需要完成30个指标中的最后24个指标的时间,使用重复测量方差分析不同水平时间的差异,以此对小目标及大目标进行细节分层,其参数设置可见表1、表2。
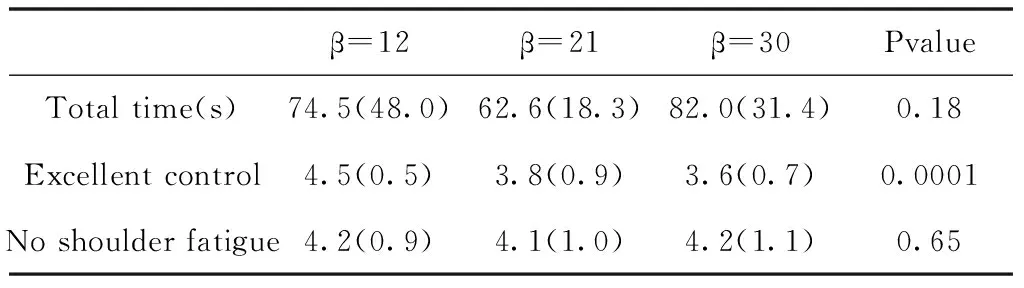
表1 Beta coefficient (small target)(m/s)
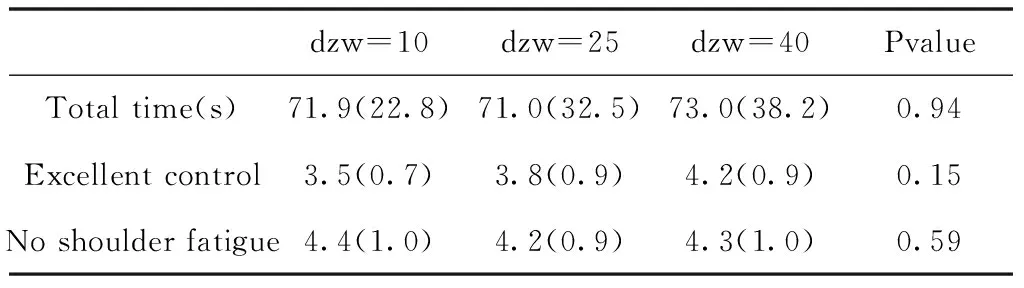
表2 Dead zone width (small target)(mm)
4.5 多视角相机建立的方法
为了更好地提高虚拟现实相机的稳定性,也为了使使演唱者能够从多个摄像机角度审视自己在虚拟空间中的动作与面部表情的综合表现,需要对虚拟现实的程序底层进行必要的优化,其代码修改如下:
Camera _camera;
∥ Use this for initialization
void Start ()
{
_camera=Camera.main;
}
∥unity前3个锁定,由低到高分别是nothing/everything/default/transparentFX/ignore raycast/waterUI
从第1个到第3个可以自己设置
∥第1个为cube层;第2个为sphere层;第3个为capsule层
void Update ()
{
if (Input.GetKeyDown(KeyCode.A))
{
_camera.cullingMask=1<<1; ∥cube 只渲染第1个
}
if (Input.GetKeyDown(KeyCode.B))
{
_camera.cullingMask=1<<2; ∥sphere 只渲染第2个
}
if (Input.GetKeyDown(KeyCode.S))
{
_camera.cullingMask=1<<3; ∥capsule 只渲染第3个
}
通过上述方法,可以观察出多视角相机的稳定性非常理想,便于后续对演唱者的表现进行定量分析,如图6.

图6 多视角相机效果
5 实验效果评估
被测人员:声乐表演专业 20名学生,男、女各10人,5人/次,根据高、低年级组及性别分为共4组。
虚拟内容:将自定义制作的360°虚拟声乐视频的内容根据情绪分类划分为正性(激动)、中性(舒适)、负性(悲伤)共6首歌曲,分别为:正性情绪歌曲《我和我的祖国》《在希望的田野上》,负性情绪歌曲《时间都去哪了》《烛光里的妈妈》,中性情绪歌曲《贝加尔湖畔》《牧歌》。
实验结果:以问卷形式与SAM量表来进行数据收集及分析测试结果良好,如表3。
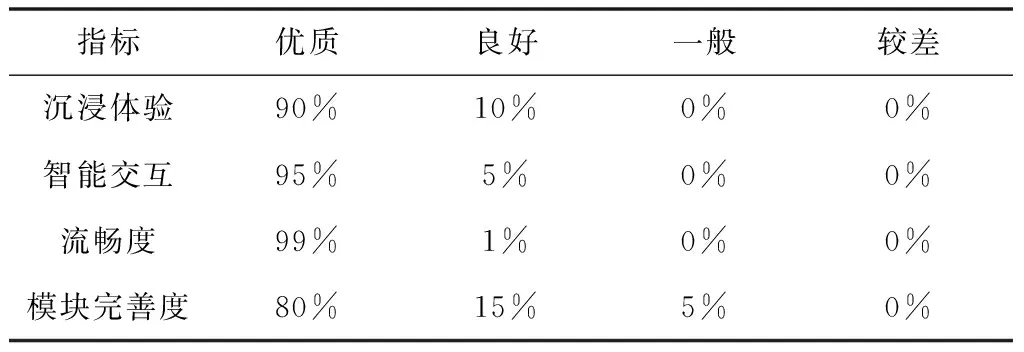
表3 声乐交互虚拟系统使用体验数据分析
通过SAM情绪自陈量表获取高仿真度声乐交互内容,对虚拟现实介入前后进行相应的分析,如图7。

图7 虚拟现实介入前后的对比
从量表数据分析可知,使用高仿真度声乐交互虚拟系统产生的情绪变化要远高于传统声乐教学课程表现,这主要得益于虚拟现实技术带来的沉浸性和高仿真度。
6 结束语
与传统声乐教学方法相比,基于虚拟现实的声乐教学平台能够给演唱者更广泛的空间选择,也能够对演唱水平起到积极促进作用,其优势如下:
1)能够不受现实物理时空、费用等条件限制,有效节约硬件成本,也是一种以高仿真度环境为基础的智能交互性体验过程。
2)能够构建不同的虚拟内容元素,能够较好地实现大众参与,且能够有效刺激演唱者的各项感知器官。
3)能够为声乐交互的虚拟现实体验带来更加精确、细腻、多元化的沉浸感及临场感。
猜你喜欢
艺术家(2022年7期)2022-11-22
戏剧之家(2022年27期)2022-10-31
天津音乐学院学报(2022年2期)2022-07-28
歌剧(2017年11期)2018-01-23
歌剧(2017年12期)2018-01-23
歌剧(2017年7期)2017-09-08
中小学信息技术教育(2017年3期)2017-03-28
声屏世界(2015年7期)2015-02-28
