
融合密度峰值与局部特征的大数据情感分析
2021-11-17 07:35孟祥光郭东伟
计算机仿真 2021年6期
孟祥光,郭东伟
(吉林大学软件学院,吉林长春市 130021)
1 引言
在互联网应用中,人们对于商品、服务、民生、事件等的讨论和评价,发挥着越来越重要的作用。企业可以根据用户评价优化商品和经营服务;政府可以根据民众评论快速掌握民生需求,防止发生舆情事件;用户可以根据网络讨论和评价确定目标商品及购买意愿。总之,充分利用讨论与评价数据,获取其中隐含的价值信息对于互联网良性发展具有推动作用,于是情感分析技术应运而生。该技术就是基于互联网中的主观文本,由计算机自动提取出其中所要表达的情感信息[1]。但是对于一些具有隐含意义的自然语言,准确可靠的情感提取并非易事[2-3]。当前使用较多的方法是机器学习,结合语法、语义特征完成分类。文献[4]提出了一种多神经网络融合的方式实现情感分析;文献[5]利用ELMO转换词汇向量,并采用MSCNN训练词汇向量并提取特征;文献[6]引入self-attention优化机器学习,改善特征分类性能;文献[7]基于self-attention机制设计了Tree-LSTM训练模型,同时引入Maxout神经元,进一步改善了情感分类的准确率;文献[8]融合了self-attention与Bi-LSTM,实现了双语情感分析。基于这些研究,本文也采用机器学习进行特征提取,同时考虑到机器学习参数较多,学习效率较低的问题,难以应付大数据应用场景,于是先对原始数据进行粗粒度聚类。这里设计了一种密度峰值聚类(DPC),DPC具有调节参量少,执行效率高的优点[9],另外本文针对原始数据集采取区域划分,独立聚类,使聚类效率进一步提高,最终通过各子区域输出合并得到全局结果。在粗粒度聚类后的本文数据上,再融合LSTM-CNN进行局部特征提取,大幅缩减了待处理数据规模及参量个数,从而可以高效可靠的实现大数据情感分析。
2 DPC优化聚类
DPC优化算法的核心是对全部数据求解局部密度ρ与相对距离δ[10],构造(ρ,δ)关系,进而确定聚类中心。对于任意数据i,其局部密度ρi可以利用与其它数据的欧氏距离dij(j≠i)来计算,公式如下

(1)


(2)
根据dij与ρi,计算相对距离,公式如下

(3)

在对数据集合进行子区域分割时,采用网格策略。此时,算法主要求解每个子区域内的数据密度与距离,以及邻近子区域的相关参数,这样的处理过程在优化数据计算复杂度的同时,有利于改善分布式计算的负载均衡性。对于一些数据点,所属簇可能与所属子区域并不是一个,这种边界数据可以将其同时归属于不同子区域。于是提出子区域扩展定义,假定si为任意子区域,边界数据所属簇的截距为d,则扩展后的子区域为si+d。当数据包含多维度时,子区域对应为空间区域。为尽可能降低数据划分对ρi的影响,本文引入高斯核优化ρi,计算公式为

(4)
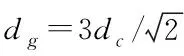

(5)
这里的n表示网格划分的子区域数量。对于任何一个子区域而言,只有ρi与δi的乘积超过门限值,才能将其确定为聚类中心。在采用局部DPC聚类时,通过扩展可能会使一些相邻区域产生数据交集。当需要对子区域结果进行合并处理时,可以利用边界数据特征搜索出相应的簇。假定c1、c2依次为交集区域A1与A2中的局部簇,它们之间满足c1⊆A1,c2⊆A2,A1∩A2≠∅。当某数据d位于c1与c2簇的交集内,且该数据同时属于c1与c2的核心元素,考虑到子区域交集数据一定是边界数据,合并点一定落在边界数据内,则此时应该将c1与c2采取合并,并将d作为合并点。从合并点能够知道c1与c2存在的联系,进而能够确定它们的全局特征。
3 文本大数据情感分析
3.1 局部优化文本特征提取
文本中的词性能够反映出人物的情感特征,假定某文本的词汇集描述为T={t1,t2,…tn},经过Word2Vec可以变换得到相应的词汇向量V(ti)。向外推广可以得到句子矩阵的词汇向量集Sij={V(t1),V(t2),…V(tn)},且Sij∈Rn×k,k表示V(ti)的维度。为了在CNN训练时重点突出词汇特征,对句子包含的诸如情绪、程度、肯定和否定等词汇采取标注。这里引入多头注意力,它可以描述为拼接矩阵与加权形式
MH(X,K,V)=HW
(6)
左侧项的X表示搜索的目标向量;K、V是X对应的键值对;右侧项W表示加权矩阵;H表示拼接矩阵。在标注过程中,文本词汇特征对应多头拼接矩阵H,任意词汇对应不同的向量值tri,且tri∈Rk。于是,一个包含n个词汇的句子,对应的词汇特征描述如下
tr1:n=tr1⊕tr2⊕…⊕trn
(7)
其中,⊕表示拼接操作。根据Sij求解出多头注意力的X、K、V参量,公式如下
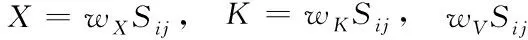
(8)
其中,wX、wK与wV均表示加权矩阵。于是,利用注意力得到词汇特征输出为

(9)
把输出结果Otr采取如下前馈加权,从而求解出额外特征

(10)
wm表示前馈加权矩阵;etr表示偏移量。至此,通过前述计算可以得到文本句子内的情感词汇特征。考虑到词汇特征与句子表达可能存在差异,这里将词汇与句子各自对应的特征进行融合。采取门控加权融合,公式如下
R=activate(wt⊙Ce+(1-activate(wt⊙))⊙Cs)
(11)
activate(-)表示激活函数;wt表示门控加权;Cs表示句子特征,提取公式如下
Cs=softmax(0,w1Otr+e1)w2+e2
(12)
w1与w2均表示加权;e1与e2均表示偏移量。再利用如下公式计算出句子的情感极性
p=softmax(wlinkCs+elink)
(13)
wlink与elink分别表示连接层加权和偏移量。CNN网络在训练情感极性p的过程中,采取交叉熵进行评估
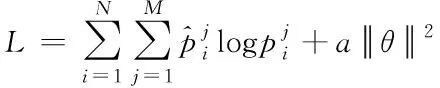
(14)

cij=f(F·V(t(i:i+l-1))+e)
(15)
cij是包含词汇i的句子j对应的局部特征;l是要提取的词汇向量行数;V(t(i:i+l-1))是获取i至i+l-1行词汇向量;F是卷积滤波;e是偏移量;f(-)是ReLU变换。
3.2 文本特征提取流程
基于局部特征优化的文本大数据情感分析流程如下:
1)文本大数据初始化操作,一方面去除文本内没有语义的非词汇;另一方面利用分词器对文本内词汇采取分割处理。在去除非词汇的同时,为防止噪声干扰,还会对停用词进行删除。将分割后的词汇采取Word2Vec变换,构造向量字典。
2)在CNN的嵌入层完成向量拼接,并利用式(7)得到句子整体的词汇特征。
3)将Sij输入至BiLSTM层,同时给定Sigmoid激活函数。在BiLSTM层的输入端,采取双向策略,利用隐层分别得到词汇与句子特征。在BiLSTM层的输出端,采取Bijt=BiLSTM(Sijt)方式完成结果拼接,Bijt即为时间点t,BiLSTM层的最终结果;Sijt表示在时间点t,包含词汇i的句子j对应矩阵。
4)在CNN中计算局部特征,采用Cijt=CNN(Bijt)纠正BiLSTM层结果,Cijt即为时间点t,CNN输出结果。对词汇与句子特征采取融合,并使全连接层介入。
5)利用softmax得到大数据情感分类。
4 仿真与结果分析
4.1 实验环境与衡量指标
仿真操作系统为Windows10,软件实现语言为Python,实验数据集选择COAE2014,该数据集具有40000条数据。在COAE2014内部,有5000条对应的情感极性为已知的,可以用于网络或深度学习。词汇截取选择jieba,向量变换选择Word2Vec,经过处理后最终得到的向量模型配置如表1。

表1 向量模型配置
在衡量密度峰值聚类性能时选择ARI指标。ARI能够描述聚类输出和实际的吻合性,它的变化区间是[-1,1],计算公式为

(16)
式中,RI表示兰德系数;E(RI)表示RI期望。ARI的值越接近1,说明聚类效果越好,越接近-1,说明聚类效果越差。RI的计算公式为

(17)
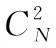
在衡量数据情感分类时选择Precision、Recall和Fl-measure三项指标。其中Precision用于衡量数据分类的查准率,计算公式为

(18)
这里的TP表示积极情感数据被正确分类成积极情感的数量。FP表示错误标记成正的数量,即非积极情感数据被错误分类成积极情感的数量。Recall用于衡量数据分类的查全率,计算公式为

(19)
这里的FN表示积极情感数据被错误分类成积极情感的数量。Fl-measure是对Precision和Recall的综合评价,计算公式为

(20)
4.2 实验结果分析
为了衡量局部DPC优化算法的聚类性能,引入AE-MDPC[9]和DPPOD[10]方法作为比较。实验过程中,依次增加数据规模,得到不同数据规模下各方法的ARI指标,结果如图1所示。根据结果对比,当数据规模增加时,各聚类方法的ARI值均有所增加。其中本文方法的ARI值始终最高,表明聚类效果与实际类别最吻合。这得益于本文设计的区域划分与局部聚类策略,针对划分区域使用高斯核优化密度计算,并根据密度与距离乘积实时调整筛选门限,使聚类中心实现自适应选择,从而获得更准确的聚类性能。

图1 实验结果
为了衡量本文方法在大数据情感分类方面的整体性能,本文引入文献[6]、文献[7]和文献[8]中方法作为比较,分别得出不同方法在COAE2014数据集下的Precision、Recall和Fl-measure指标,结果如图2所示。根据指标数据,本文方法相比于文献[6]、文献[7]和文献[8],在Precision指标上依次提高了0.035、0.026和0.054;在Recall指标上依次提高了0.04、0.023和0.051;在F1-measure综合指标上依次提高了0.037、0.025和0.053。表明本文方法在查准率与查全率方面都有显著提升,能够更加准确的对数据情感进行分类,并且具有更高的搜索全面性。究其原因,是由于本文在密度峰值聚类的基础上,利用BiLSTM-CNN提取了文本词汇与句子特征,并采取融合处理,同时采用了局部特征纠正结果,从而保证了本文方法在上下文与局部特征方面的处理都更为合理准确。
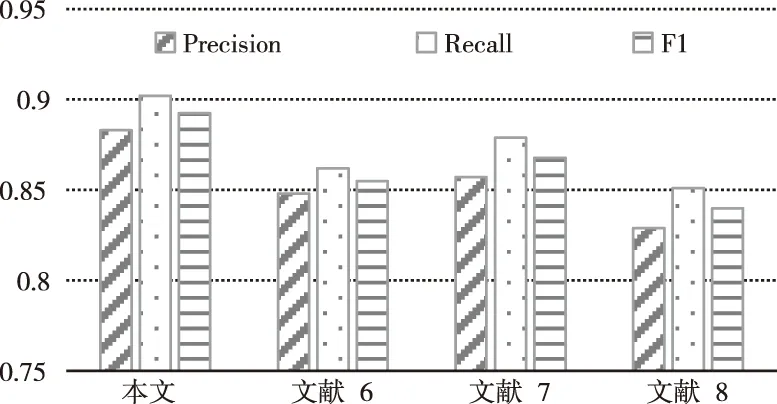
图2 性能指标对比
为验证本文方法在大数据情感分类方面的实时性,实验过程中依次增加数据规模,统计得到不同数据规模下方法的分析时间,结果如图3所示。根据曲线可知,在数据规模增长过程中,分析时间的增长速度比较缓慢且线性。表明本文方法的处理效率较高,适用于大数据场景的情感分析。这是由于本文方法在前期的聚类阶段采用了区域划分策略,便于大数据任务的拆分并发处理,同时前期聚类能够大大降低后期特征分类操作的复杂度。
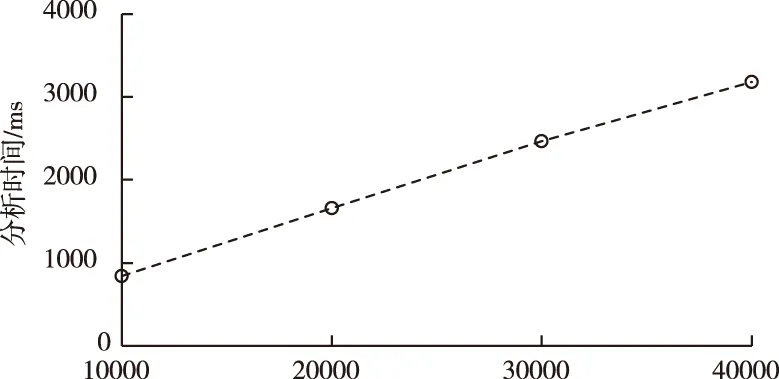
图3 大数据情感分析时间
5 结束语
为了改善文本大数据情感分析性能,本文采用了分层处理策略。首先在底层设计了改进DPC算法,使其能够通过区域划分更快更准确的达到聚类要求,对文本大数据进行粗粒度的分类,降低后期处理的数据规模和难度。然后在上层设计了局部优化文本特征提取方法,通过词汇与句子特征融合,以及局部特征修正,完成情感分类。仿真结果表明,密度峰值优化算法具有更好的聚类效果,融合密度峰值与局部特征的大数据情感分析方法具有更好的准确度与实时性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
