
基于VSM的海量医学资源特定信息优化聚类模型
2021-11-17 07:36宁鹏飞
计算机仿真 2021年6期
刘 鹏,宁鹏飞
(内蒙古医科大学,内蒙古 呼和浩特 010000)
1 引言
信息技术的发展不但打破了用户获得医学信息的时空限制,并且使可供利用的医学资源特性信息更加丰富[1]。科学和技术的发展在信息数据全球化的背景下,信息聚类在很多领域都有广泛的应用,但是,当前方法在去噪过程中无法保存有效信息,细节信息流失现象较为严重,导致Jaccard系数与F1系数偏低,即聚类效果并不理想[2-3]。医学信息用户需要熟悉网络学术信息资源的分布特征与价值,并且要掌握这些资源的聚类技巧,才能通过医学资源特定信息的聚类实现自己的研究工作,因此对海量医学资源特定信息进行聚类处理具有重要意义[4]。
文献[5]提出基于信息共识的医学资源特定信息聚类方法,该方法利用CDIM方法获得初始聚集,通过参数方法初始化处理初始聚集,在簇标签信息间关系的基础上构建信息共识,利用文本分类器将簇标签分配给构建的共识,通过训练文本分类器实现医学资源特性信息的聚类,该方法没有对医学资源特定信息进行去噪处理,导致Jaccard系数较低。文献[6]提出基于需求功能语义的医学资源特定信息聚类方法,该方法在服务需求中利用自然语言处理技术提取有用功能信息集,根据获取的信息集对服务功能语义对应的相似度进行计算,在相似度计算结果的基础上通过k-means算法实现海量医学资源特定信息的聚类,该方法在去噪过程中无法保留细节信息,导致Jaccard系数较低。文献[7]提出基于分量属性近邻传播的医学资源特定信息聚类方法,该方法首先运用动态时间弯曲法计算多变量时间序列的总距离,将获得多种数据时间的整体距离通过近邻传播的方式进行分类,并结合多种序列数据下存在的联系及初始时间数据的显示关系实现医学资源特定信息的聚类,该方法在分类过程中无法保留有效信息,导致F1系数较低。
为了解决存在的问题,提出基于VSM的海量医学资源特定信息优化聚类模型,通过对医学资源信息进行信息预处理及特征提取,在VSM的基础上建立医学资源特定信息优化聚类模型,以帮助用户提高对海量医学资源特定信息的聚类与应用能力。
2 海量医学资源特定信息预处理
2.1 医学资源特定信息降维处理
现实生活中每个数据集的结构都较为复杂,降维处理后的低维数据和原高维数据都尽量满足相同的流形结构时,建立基于VSM的海量医学资源特定信息降维目标函数。降维目标函数利用半监督医学资源特定信息与无标记数据中隐含的医学资源信息来维持全局流形和局部流形[8]。通过CSDDR算法分别定义全局和局部流形,标量Qg主要用于表示医学资源中全部的样本全局流形结构,通过正负约束对设定的目标函数进行调整,标量Qg的计算公式如下

(1)


(2)
式中,nc为正约束对的数量。正负约束的贡献值分别用α与β来调整。在计算投影距离时,为了降低不同医疗资源之间的差距,首先需要降低相同类型医疗资源的距离,增加不同类型医疗资源的距离。结合先验知识可知,通常情况下,负约束的样本距离更加接近期望值[9]。因此一般会取α=1与β>1,当α的值过大时,数据样本距离聚类越来越近,数据样本特征性质产生负面影响,此时聚类中心存在明显偏移或者错误识别噪声点的现象等。
利用先验信息中所包含的全局流形信息与未标记的信息样本中隐含的局部结构流形信息,来获得详细流形信息。因此,刻画样本局部结构流形时,用Ql来定义标量。对各个样本点xi分别求其k-最近邻点集合(KNi)和k-最远邻点集合(KFi),并根据其余样本点xj∈KNi或xj∈KFi对目标函数进行调整。

(3)
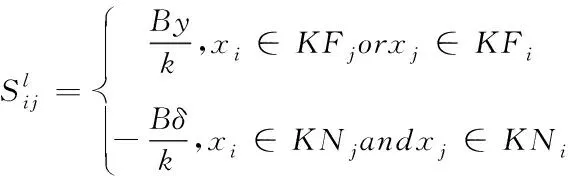
(4)
式中,y与δ的取值主要用于调整医学资源特定信息的贡献值,一般δ的取值距离更加接近期望值,因此,定义y=1与δ>1。对于数量k值可通过不同的数据集与不同的先验约束进行具体调整:k取值偏小时,1/k值变大,增加了Ql在降维目标函数中的影响度;k取值偏大时,医学资源信息的选取准确度会降低。
未标记医学信息样本中除了局部结构流形信息以外,其它隐含的医学特定信息也可以为目标函数所用[10],将全部未标记样本用标量Qu来定义
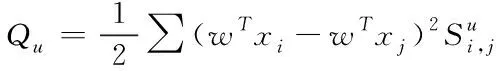
(5)

结合上述数据,具体医学资源特定信息降维目标函数的表达式如下
J(w)=Qu+AQg+BQi
(6)
式中,通过参数A可以对Qg在整个医学特定信息目标函数中的贡献作出调整,Qi在目标函数中的贡献度可通过参数B进行调整。通过上述分析可知,可以利用普通矩阵特征值求解问题代替降维目标函数的求解问题,上式中,L为一个对称矩阵,其表达式如下
L=Lu+ALg+BLl
(7)
矩阵L的主要作用是降低信息特征值与对应特征向量出现虚数的几率。通过矩阵L减少了医疗资源特定低维信息Y中存在的虚数
Y=WTX
(8)
所提方法利用标记医学资源信息与无标记医学资源信息样本中所包含的信息,设置降维目标函数的参数值,建立降维矩阵,利用降维矩阵实现海量医学资源特定信息的降维处理,获得原医疗资源特定信息的最佳低维表示。
2.2 医学资源特定信息去噪处理
基于VSM的海量医学资源特定信息优化聚类模型通过基于小波变换模极大值与阈值决策相融合的去噪方法对医学资源特定信息进行去噪处理,具体步骤如下:
使用小波变换或者小波包变换对含医学信息含噪信号进行离散,获取不同尺度的系数,即医学特定信息信号通过小波分解后,获得不同尺度中的高通分量。
1)在小波变换过程中,计算小波在不同尺度中的模极大值。将各个尺度上的小波变换模极大值进行计算。
2)对各个尺度上小波模极大值系数的功率进行计算。
3)设Pj(x)代表的是小波模极大值系数在不同尺度中对应的功率,其计算公式如下

(9)
式中,j=1,2,…。低尺度下,功率Pj(x)主要由噪声控制,随尺度的变大,噪声变换模极大值逐渐变小,而信号变换模极大值逐渐变大,所以功率会因为噪声的影响快速降低,将最小时对应的尺度jm作为尺度取舍的一个阈点。基于VSM的海量医学资源特定信息优化聚类模型为了提高小波系数阈值处理结果,将尺度jm作为分界点处理小波系数。
4)对于最大尺度的细节信号,由于信噪比高,有用信号的能量增加,其占主要部分,为了避免除去过多的有用信号,阈值的选取不能太大。结合以上分析,通过下式确定阈值tJ

(10)
式中,σJ为信号在最大尺度上的方差,N为信号的距离。
5)对于尺度j=jm+1,jm+2,…,J-1,信噪比越高,阈值也应该提高,通过下式确定阈值tj

(11)
式中:σ为信号在最大尺度上的方差。由于尺度j的变大,tj的值逐渐变小,可知噪声在小波变换的各个尺度上有着相同的传播特性。
6)对尺度j=1,2,…,jm,噪声的能量越高,信噪比越低,因此选用Donoho广义阈值,计算方式如下

(12)
3 海量医学资源特定信息聚类方法
3.1 特征提取
医学资源信息中通常含有大量的数据,每个信息对数据分类都有着不同的作用,如果将整体的数据都进行计算,那么计算量会大幅度增加,所以将通过特征提取实现信息聚类。通过选择对医学数据区分度大的项作为数据的特征进行分类,可以降低计算量的同时优化聚类效果。基于VSM的海量医学资源特定信息优化聚类模型采用改进互信息的特征提取方法,选取数据条和类别互信息较大的前部分数据作为医学资源特定信息的特征。
设RMI(T,Ci)代表的是数据条和类别的互信息,计算方法如下
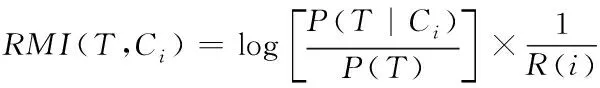
(13)
式中:P(T|Ci)表示此数据条在Ci类别中出现的概率;P(T)为类别Ci中出现词条T的概率;R(i)为特征提取修正因子,该值计算方式如下

(14)
式中:N(i)表示Ci类别中出现的总数据条数,R(i)表示Ci类别的数据量在全部数据集中所占的比值。
3.2 聚类模型
在医学资源信息分类中,向量空间模型(VSM)是常用的信息表示形式,每种医学资源信息都属于一个特定领域,该领域可以通过该类别的医学资源信息进行描述,上述领域通常由一些核心概念构成,在该类医学资源信息中上述核心概念中存在的词将会反复出现。所有的核心概念与分类的影响都是相辅相成的,如果一项数据中出现一种数据类别的多种核心概念,那么这些数据之间将出现相互证明的情况,从而该数据属于该类别的可能性会增加。
用CoreWord(Ci)来表示类别Ci的核心概念,即CoreWord(Ci)由两部分组成:
1)训练样本中段落首尾句和标题中存在的名词,计算名词对应的权值Rt。
2)当名词在训练样本中出现的频率大于设定的阈值时,该词即为权值。
海量医学资源特定信息的标题和段落的首尾句相比于资源的其它部分更能体现资源的主题,对于这些部分出现的概念在信息处理中应赋予更高的权重。对信息Ti进行分类,首先对医学资源信息标题和文本中的段首和段尾句进行分词得到一组词WORDSn=[w1,w2,…wm],同类的文档是通过一组概念来体现的,此部分词是互相交叉的并不是相对独立的,如果一个类A的核心概念词是由词a来体现的,那么a∈CoreWord(A);如果词a、词b都是属于A的核心概念词,并出现在信息Ti中,则在信息Ti中a∈Ti,b∈Ti,此时属于信息A的得分分别为Sa,Sb;如果在信息Ti中词a、词b同时出现,则该信息属于A的得分Sab>Sa+Sb,此时a、b的激励效应可以用Sab-Sa-Sb对应的部分进行表示。
通常情况下数据条的权值偏小,多于两种数据之间的激励效应可以忽略。
所提方法运用文本向量与类特征向量在VSM的基础上构建医学资源特定信息优化聚类模型
Score(TiCj)=s×V(Ti,Cj)+k×Cos(Ti,Ci)
(15)
式中:s,k代表权重,s+k=1。共有m种医学信息类别。通过上述聚类模型实现海量医学资源特定信息的聚类。
4 实验结果与分析
为了验证基于VSM的海量医学资源特定信息优化聚类模型的整体有效性,需要对基于VSM的海量医学资源特定信息优化聚类模型进行相关实验。本次测试的实验环境为:开发环境:VS2010;开发语言:C#(.NETFramework3.5);分词系统:NLPIR/ICTCLAS2014;数据库:SQL Server2005。
将分类实验中的已知分类与聚类算法运行后的结果相似度进行比较,通过参数计算两者之间的相似程度,本次实验通过Jaccard系数与F1系数进行测试。当Jaccard系数与F1系数的值越大时,表明聚类结果越接近数据集合原有的类别系统,即聚类结果的质量越好。Jaccard系数与F1系数公式分别如下

(16)

(17)
采用基于VSM的海量医学资源特定信息优化聚类模型(方法1)、基于需求功能语义的医学资源特定信息聚类方法(方法2)和基于分量属性近邻传播的医学资源特定信息聚类方法(方法3)进行测试,Jaccard系数测试结果如图1所示。
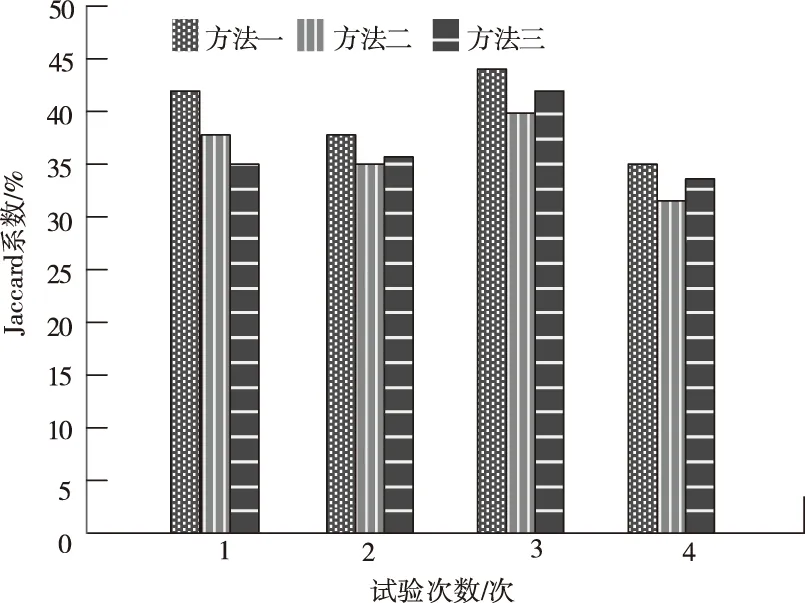
图1 Jaccard系数测试结果
由图1可知,在多次实验中方法1的Jaccard系数较大,证明此方法的聚类运行结果更接近数据集合原有的类别系统,即聚类结果的质量更好。方法2与方法3的Jaccard系数偏小,即聚类结果的质量较低。因为方法1融合小波变换模极大值与阈值决策方法对医学资源特定信息进行去噪处理,经过去噪处理的优化获得干净与真实的数据,提高了Jaccard系数。
分别采用方法1、方法2、方法3通过F1系数进行测试,测试结果如2所示。
分析图2中数据可知,在多次测试中方法1的F1值均高于方法2与方法3的数据,因为方法1在去噪过程中通过选取合适的阈值,保留医学资源特定信息的有效信息和细节信息,根据保留的信息提取海量资源特定信息的特征,提高F1系数,进而实现资源的高质量聚类。
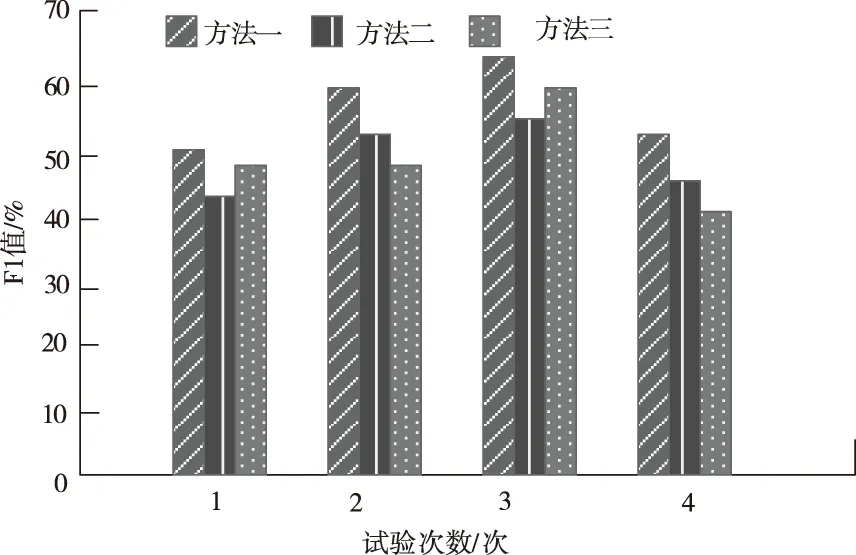
图2 F1系数测试结果
5 结束语
网络医学资源特定信息分类组织的无序性和信息聚类的差异性,对医学信息用户的聚类能力和技术提出了更新的要求。对此问题提出了基于VSM的海量医学资源特定信息优化聚类模型方法,对海量医学资源特定信息进行预处理,提取信息特征,根据信息特征构建信息聚类模型,完成医学资源特定信息的聚类,该方法有效地解决了当前方法中存在的问题,为海量医学资源特定信息处理工作提供了相关依据。在未来的研究中,可以对海量医学资源特定信息优化聚类模型做更加深入的研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
社会科学战线(2022年7期)2022-08-26
导航定位学报(2022年2期)2022-04-11
汽车实用技术(2022年4期)2022-03-07
海峡姐妹(2019年12期)2020-01-14
当代陕西(2019年14期)2019-08-26
中学数学杂志(初中版)(2016年5期)2016-11-01
科技视界(2016年16期)2016-06-29
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
