
基于协同过滤的多节点信息资源分配推荐算法
2021-11-17 07:36佘学兵占清华邬昌兴
计算机仿真 2021年6期
佘学兵,占清华,邬昌兴
(1. 江西科技学院信息工程学院,江西 南昌330098;2. 华东交通大学软件学院,江西 南昌 330013)
1 引言
目前网络信息技术飞速发展,网络上留存着大量的信息数据[1]。由于这些数据属性不同并且较为杂乱,因此在用户进行信息搜索时,常常花费较长的时间却找不到相对有用的信息[2]。目前的信息资源分配算法只能对用户已知的信息进行推荐,而不能对未知信息进行推荐,所以急需一种新的信息资源分配推荐算法满足用户需求。
文献[3]提出基于改进物质扩散的数据信息资源分配推荐算法。采用信任机制得到目标用户最优邻居集,利用用户信任度初始资源分配信息,根据物品双向扩散能力对参数进行调优,实现信息资源的再分配,优化目标用户完成推荐。该算法能够提高推荐结果的多样性,但其信息资源分配时间较长。文献[4]提出基于受限马尔可夫决策过程的节点信息资源分配推荐算法。采用马尔可夫决策理论,构建动态优化模型,利用近似动态规划理论,定义基函数的分配行为,调整外部环境学习和资源分配策略完成推荐。该算法能够有效减少计算维度,但是其信息资源分配推荐列表覆盖率较低。为了解决上述信息资源分配算法中所存在的问题,提出了基于协同过滤的多节点信息资源分配推荐算法。
2 基于协同过滤算法的信息分类处理
2.1 构建信息数据评分模型
利用预处理技术与数据挖掘技术,对节点中的信息资源进行处理分类,构建评分数据模型。一般选择用M×N的评分矩阵R(如下式1所示)。

(1)
式(1)中,M代表矩阵中的行数,N代表矩阵中的列数,且数据i对项目j的评价值用Rij表示。数据评价值用0到5之间的整数来表示,作为数据对项目的评分,值越大表示此数据受欢迎程度越高,0则表示没有对数据进行评价[5]。也可以用整数区间来表示评价级别,级越高表示越受欢迎。
2.2 查找最近邻居集
利用构建的评分数据模型对网络信息数据进行查找,获取网络信息数据中评分信息的评分向量。根据相似度公式对评分向量进行计算,获取数据评分矩阵中数据u与数据uj的评分相似度sim(u,uj)[6]。再将取得的节点信息相似度进行降序排列,可得知sim(u,u1)>sim(u,u2),>…>sim(u,ux)。然后依据选择策略决定最近邻居值的大小。选择邻居策略有两种主要形式,第一种预先设置最近邻居数k,第二种是设置固定的相似度阈值,若目标相似度大于阈值,就可将对应的数据划分到目标的最近邻居集中。但是长时间的经验累积已经能够证明用固定值k确定最近邻居值的方法优于后者,所以一般都会采取设固定邻居数k,确认最相似的邻居数,最近邻居集可表示为KNN(u)={u1,u2,…uk},u∉KNN(u),k∈(1,m)。
假设寻找数据0的最近邻居,选K值为5,可用矢量距离代表网络信息数据之间的相似度,数据0的最近邻居便是距离它最近的五个数据1、2、3、4、5。
2.3 相似性计算
在协同过滤算法中,最近相似度的计算是查找邻居集的重要前提[7]。相似度的计算函数又分为余弦相似性、修正余弦相似性、相关相似性三种。其中,余弦相似性是计算网络节点信息与项目空间向量上的内积夹角余弦值,并用此余弦值计算数据之间的相似度,过程如下式
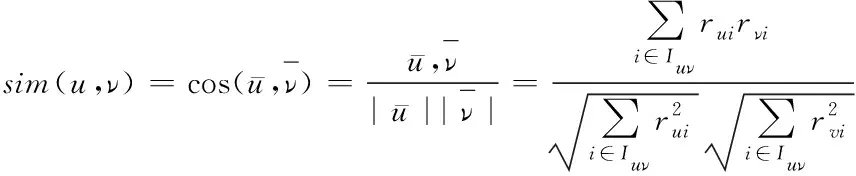
(2)
调整余弦相似度的目的在于克服网络信息数据在评价时受个体因素影响而导致的评分尺度不同的问题。在余弦相似性的公式上进行修改,主要是将获取的余弦相似性向量减去信息数据平均评分向量后,进行夹角的余弦计算。过程如下式
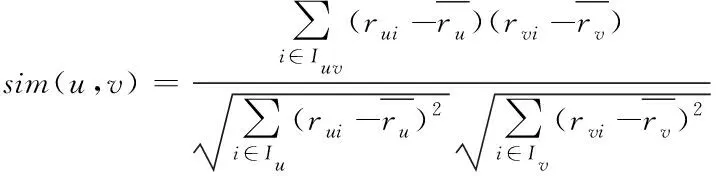
(3)
相关相似性也叫做皮尔森系数,首先找到信息数据进行过共同评分的项目集,其次在共同评分项目集中计算向量的相关系数,以此来表示不同网络信息数据的相似性,如下式所示。
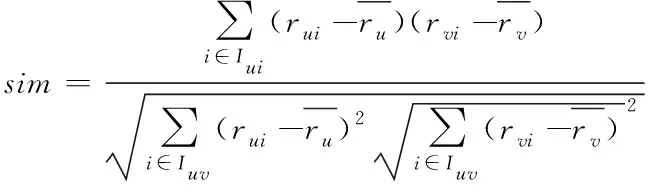
(4)

2.4 预测评分
在目标信息数据的最近邻居集KNN(u)确定后,以sim(u,v)为权重加权的平均最近邻居集对信息数据的未评价项目i进行评分[8],并引入信息数据对历史项目评分的平均水平进行调整,产生u对i的预测评分,过程如下式;
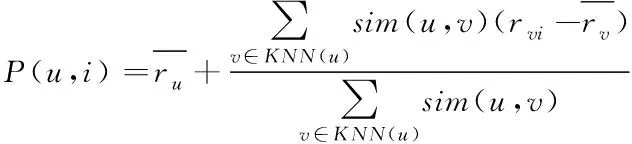
(5)
在访问网络信息数据时,根据一些历史信息,适时对未评分的数据进行评分,划入相对应的最近邻居集,利用相似度计算完成对网络信息数据的分类。
3 多节点信息资源分配推荐算法
在基于协同过滤算法将节点信息进行分类后,利用二部图网络结构对分类的节点信息进行资源分配并对信息资源进行推荐。
设二部图网络用G={V,E}表示,U表示分类信息的用户类,L表示分类信息的项目类,这样就由U类数据信息节点和L类数据信息节点以及围绕在它们之间的数据信息边集E组成了一个网络结构[9]。若假设这个网络结构中有N个用户L={l1,l2,…lN},M个项目U={u1,u2,…uM},那么在用户和项目之间便会由此形成一种选择关系,可以用一个邻接矩阵A={αul}M,N来代表这种关系。如果项目l被用户u选择了,则αu,i=1,若否αul=2。
每一个用户都有各自的爱好,所以根据用户选择的项目就可以准确了解用户在这一阶段对某些项目的喜好程度。若把这些抽象意义上各不相同的喜好进行信息提取再具象的表现出来,就可以清晰的看到,不同用户选择的不同项目能够互相连接,形成关系网。再让获取的资源值在这些关系中进行流动[10-11]。当选定目标用户将其获取的资源值通过未选定用户分配给用户未选择项目时,该目标用户便具备了推荐用户的未选择项,就此形成推荐过程。二部图网络结构的多节点信息资源推荐过程如图1所示。
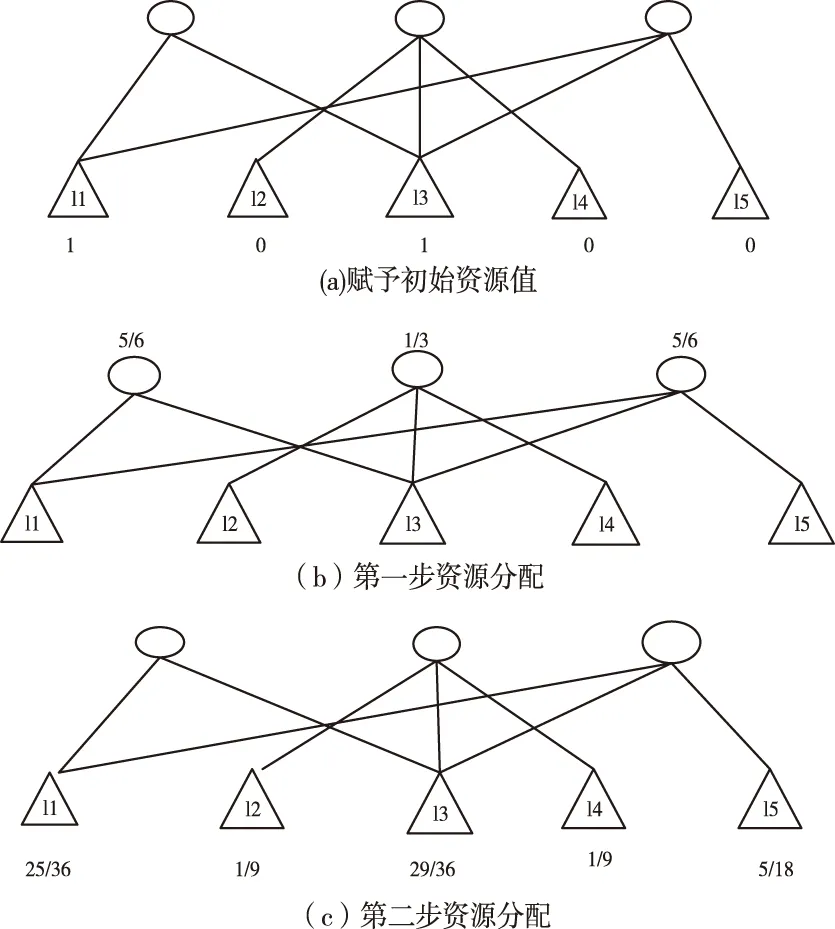
图1 二部图网络结构的多节点信息资源推荐过程
如图1所示,设目标用户为u1,二部图的多节点信息资源分配过程如下:
1)对信息数据项目设定初始资源值。设定“1”为L类节点信息中目标用户u1选定项目的初始资源值,而未被选择的项目则为2。初始资源值为1的项目集合为S={l1,l3},具体过程如图1(a)。
2)根据选定的关系,将S集合所被赋予的资源值进行整合并分配到跟其相邻的U节点里,这样用户集P={u1,u2,u3}就都能够获取资源值。而用户集P中所有用户取得的资源值实际上就是S集中所有项目节点l的资源值除以l节点中度的总和,具体如图1(a)到图1(b)所示。
3)再依据选定的关系,先把P集合中的推荐资源值进行整合,再将整合后的用户节点资源值分配到P集合所相邻的l类项目节点里,最后得到的信息项目资源值里将包含未选择的所有项目。这种情况下,所获取的l类信息节点资源值就包含了用户集P中全部用户u的信息项目资源值除去l信息节点度的总和。过程如图1(b)到图1(c)所示。
对于以二部图网络结构为基础的多节点信息资源分配算法所提出的资源扩散过程,在设定目标用户为u的情况后,具体步骤如下;
1)初始资源值确定,用下式表示
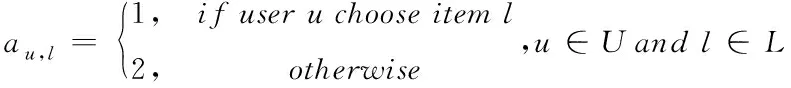
(6)
式(6)中,用户u所对应的信息项目l是所设定的初始资源值用αu,l表示。
2)从P集合中挑选任意用户v中未选择项目资源作为选定的目标用户u,过程如下式
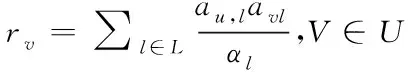
(7)
式(7)中,al代表有多少用户选择过信息项目l,即这个信息项目的维度。
3)获取P集合中的任意项目x的资源过程,用下式表示

(8)
式(8)中,rx是项目x在目标用户u推荐项目x时产生的推荐资源值。而任意用户v选择过的项目数dv则为任意用户v的度。
利用二部图网络结构为基础的多节点信息资源分配算法,将未选中的目标用户进行再次计算。在信息资源库中,设二部图中有Y个信息项目节点,这种情况下可以创建一个y行y列的W矩阵,用作表示二部图结构上所存在与项目中的一维投影[12]。W矩阵中的Wl,x则表示l行x列的资源值在项目传递时对项目x的初始加权。围绕信息资源分配过程,可以用下式表示
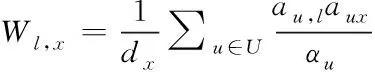
(9)
矩阵W则如下表示为

(10)
假设向目标用户u进行信息资源推荐,项目集L的最终资源值用向量fο=(i1,i2,…,in)T表示,则如下式所示;
f=Wfo
(11)
按由大到小顺序排列最终向量f按照资源值,取前k个用户u没选择过的项目形成推荐列表推荐给用户,完成信息资源的分配并推荐。
4 仿真分析
为了验证所提算法的有效性,在MATLAB软件平台上进行对比测试,采用的Java作为编程开发语言、数据库为MySQL关系数据库、平台为Eclipse、操作系统为Windows 7、内存为1G DDR、CPU为Intel Pentium。分别采用所提算法、文献[3]算法和文献[4]算法进行测试。
在网络信息数据相同的情况下,对比不同资源分配推荐算法推荐信息资源所需要时间,测试结果如图2所示。
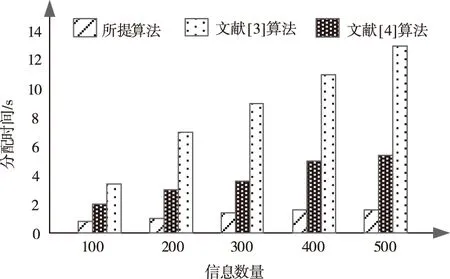
图2 不同算法的信息资源分配时间测试结果
分析图2可知,在相同的数据信息下,所提算法比文献[3]算法和文献[4]算法的测试时间短,因为所提算法在前期处理数据时对信息数据进行协同过滤处理,构建了信息数据评分模型,短时间内快速查找最近邻居集并对数据进行了预测评分,以此完成了对信息数据的分类处理。减少了信息资源分配时间,提高了分配效率。
在相同量的信息数据下,所提算法、文献[3]算法与文献[4]算法对信息资源分配的正确率进行测试,测试结果如图3所示。

图3 不同算法的信息资源分配正确率测试结果
分析图3可知,在相同量的数据信息中,与文献[3]算法和文献[4]算法相比,所提算法的信息资源分配正确率较高且检测的正确率趋于平稳,这是因为所提算法在信息资源预处理时对数据进行了协同过滤的相似性计算,提高了数据信息在资源分配时的准确性。
基于上述两种测试结果,对三种算法进行不同推荐列表数量的准确覆盖率测试,测试结果如图4所示。
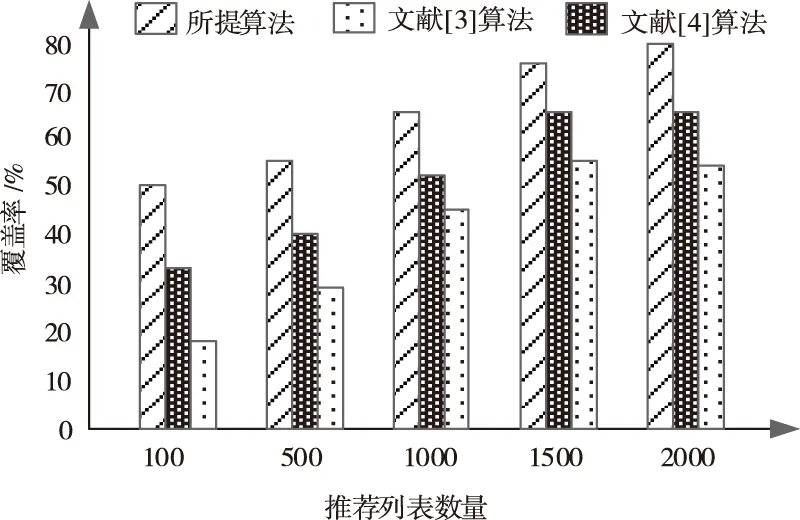
图4 不同算法的推荐列表覆盖率测试结果
分析图4可知,在不同数量的推荐列表下所提算法比文献[3]算法和文献[4]算法的覆盖率更加全面并且较为平稳,稳定性较好。这主要是由于所提算法在信息资源分配时对网络信息数据进行了协同过滤的数据分类,根据历史信息,对数据进行预测评分,再由多节点信息资源分配算法进行计算,最后生成推荐列表。所以,所提算法在不同推荐列表下的覆盖率要高于文献[3]算法和文献[4]算法。
5 结束语
为缩短目前算法多节点信息资源分配时间,提高信息资源分配正确率和推荐列表覆盖率,提出基于协同过滤的多节点信息资源分配推荐算法。基于协同过滤算法,将数据信息整合,构建信息数据评分模型,依据建好模型查找数据的最近邻居集进行评分预测,完成数据分类。由二部图网络结构的多节点信息资源分配推荐算法对分类过的数据信息进行二次计算,实现信息资源分配并对用户进行推荐。所提算法能够有效缩短多节点信息资源分配时间,提高信息资源分配正确率和推荐列表覆盖率。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
现代电子技术(2022年4期)2022-02-21
速读·下旬(2021年11期)2021-10-12
智能计算机与应用(2021年4期)2021-06-05
大东方(2019年12期)2019-10-20
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
智富时代(2018年3期)2018-06-11
智富时代(2018年3期)2018-06-11
科学与财富(2017年22期)2017-09-10
计算机应用(2016年10期)2017-05-12
