
基于网络爬虫的网页大数据抓取方法仿真
2021-11-17 08:37谢蓉蓉郑帅位
计算机仿真 2021年6期
谢蓉蓉,徐 慧,郑帅位,马 刚
(1. 西安石油大学计算机学院,陕西 西安 710065;2. 西安石油大学石油工程学院,陕西 西安 710065;3. 西安石油大学信息中心,陕西 西安 710065)
1 引言
伴随互联网行业迅速发展以及计算机的广泛应用,以数字作为主要标志的数据内容、将网络作为主要载体的文化信息,逐渐成为现阶段信息传播的主要方式之一。由于网络自身具有全球性以及开放性的特点,在一定程度上为恶意信息的传播提供了机会,因此,面对该问题,如何采用网络数据[1]信息实行有效地控制及监督,并快速截取有害信息、防止不良数据信息的扩散,已成为当前网络研究的主要对象。经研究发现,网络大数据的搜索与挖掘是解决上述问题的一种重要途径,也是数据信息查找最有效的方法之一。
针对上述问题,文献[2]提出了基于Spark下遥感遥感大数据特征提取的加速策略。首先,采用Landsat8作为数据来源;其次,利用归一化计算方式计算植被指数(NDVI)、差值植被指数(DVI)、比值植被指数(RVI)值;最终通过仿真数据结果表明:在统一硬件环境条件下,执行相同的处理任务以及数据量,利用所提方法处理遥感大数据的速度提高了将近2倍,与基于Hadoop分布式文件系统(HDFS)方式相比,所提方法的处理速度提升了将近1.2倍,与基于HDFS方法相比,所提方法在栅格切分上处理速度提高了将近1.5倍,充分证明Spark方法的提取效率优秀。文献[3]针对民航飞机在飞行过程中需使用快速存取记录仪(QAR),同时QAR数据也是飞行安全评估的重要依据。为了解决QAR数据样本数量大、高维度的特点,提出了一种有效的飞行数据特征提取的高效算法——DBN算法。DBN优势在于其能够摆脱对大量数据处理技术与专家经验的依赖,而对飞行数据进行有效特征提取。在不同类别飞行数据集上进行仿真,结果显示与主成分分析法(PCA)相比,通过DBN提取的特征进行分类识别准确率更高。文献[4]提出了一种多代表性再融合近似数据采集方法,即多个具有相似读数的节点组成一个数据覆盖集。其读取值由R节点表示。靠近水槽的设置较小,远离水槽的设置较大,可以降低热点地区的能耗。然后提出了一种分布式数据聚合策略,该策略可以重新融合彼此相距较远但具有相似读数的R节点的值。
由于上述所提方法在进行网页大数据特征抓取时计算过程繁琐,且误差大,因此本文提出了基于网络爬虫的大数据特征抓取方法,经仿真与传统数据抓取相比,本文所提方法耗时更短、抓取效率更高,有较高的鲁棒性。
2 网络爬虫基本流程
网络爬虫中的本爬虫在对一个网络站点进行访问时,首先会检查网页中是否存在Robts协议,如果存在,爬虫会依据相关协议内容确定数据抓取范围;如果不存在,爬虫会顺着链接进行抓取。如图1所示,为网络爬虫数据抓取的基本流程。
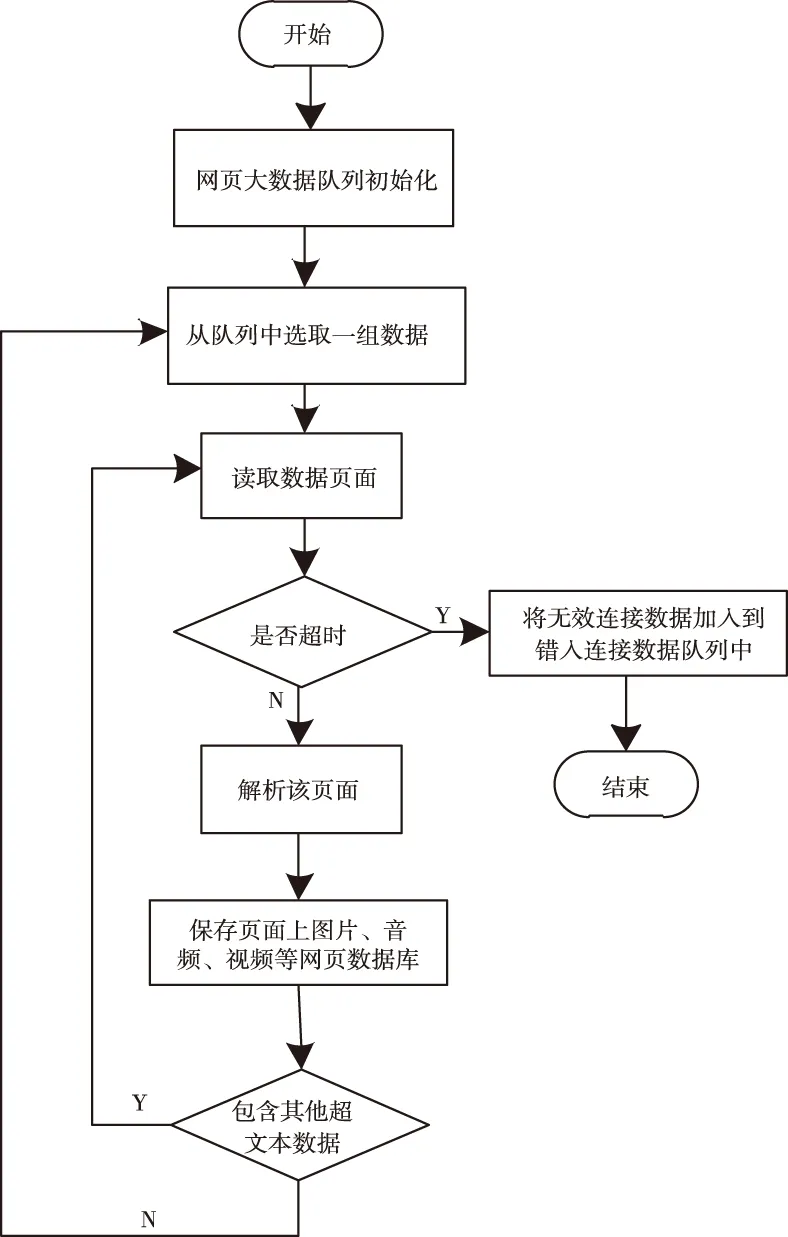
图1 网络爬虫数据抓取基本流程
在网页大数据中,将待访问的数据队列作为抓取对象,通过使用者或外部程序进行初始化处理,OA冲胫骨相关访问协议初始化数据队列中匹配的界面,解析该页面提取数据特征,根据提取出的特征,存储此时界面上全部数据信息,以此为基础,每个爬虫的循环规律都是通过解析出的数据特征中挑选一个特征进行爬行,直至所需数据抓取完毕为止。
3 基于网络爬虫的网页大数据抓取方法
3.1 大数据关键特征提取
通过局部样本特征对网页大数据集合进行分析,同时对其中蕴含的关键信息进行抓取[5]。
使用Fui形容第u个数据样本中的第i个特征,因此第u个数据样征的表现形式为
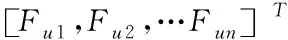
(1)
则网页大数据的关键特征抓取过程如下述:
假设网页数据样本为A∈Rn×d,使用建立的数据最短邻图为Gu=(V,E)描述样本的部分构成;其中,V表示网页中节点集合;V=A:E表示各节点间连接线的集合;Gu的权重矩阵方程为W∈Rn×n,可进行具体如下描述

(2)
其中,ε表示常数;W代表网页数据样本中的部分内在结构特。
为了更加快速准确地住抓取数据信息,首先需要确函数Yu的数值结果最小,使用Yu形容网页数据中的第u个特征,即
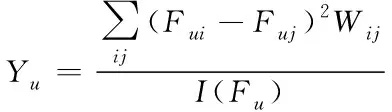
(3)
式中
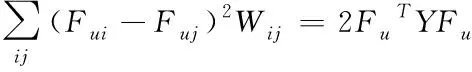
(4)
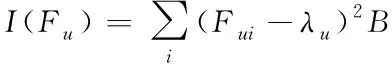
(5)
其中
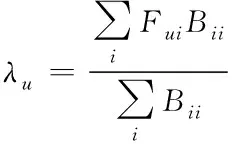
(6)
利用下式将Fu的结果更加精确
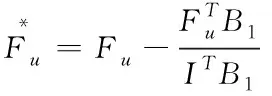
(7)
可得出第u个特征Yu,即
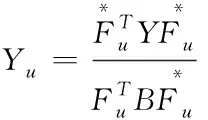
(8)
根据Yu的计算结果可抓取出Yu最小特征,即网页中数据中的主要类型。
网页大数据通常不具有明显规律性与排列顺序,具有较高的复杂性,本文提出基于网络爬虫的数据抓取方法,通过抓取主要特征,实现数据的分类与整理,提高网络搜索效率。
3.2 基于网络爬虫的数据抓取策略
现阶段,网络爬虫在进行网页大数据抓取时通常使用深度优先和广度优先策略[6]。
1)深度优先:当爬虫以顺沿的形式向节点树以纵方向分布时,网页遍历图中不存在已访问的节点。深度优先可被视作递归过程的一种,因爬虫在执行任务的过程中需占据大量系统内存,在大部分情况下,会导致爬虫工作存在一定难度,甚至电脑会出现死机的情况。除此之外,因多线程运行时一次可运行多个任务,且各任务都包含自身的堆栈,执行数据抓取任务时需使用同一堆栈,所以在网络爬虫中,递归与多线程不可同时使用。
2)广度优先:当爬虫以顺沿的形式向节点树宽度方向分布时,抓取初始网页大数据中的所有信息,随机选取一个网页地址,重复该过程。广度优先策略可提高爬虫的抓取效率。
基于上述,本文所提方法中采用广度优先策略,可进一步提高数据抓取性能,实现爬虫在访问网页过程中以并行的方式访问服务器,连接承购后对整个网页数据信息进行挖掘,以单线程对应一个数据连接,多个线程同时运行的方式实现。并结合具体实际情况,因线程数量的最佳素质与计算机的CPU性能、网络情况、宽带等因素密切相关,所以并不是线程越多爬虫效果最佳,因此需采用广度优先策略,可确保网络爬虫工作的过程中,网页数据库能够正常运行与爬虫抓取信息间找到一个平衡中心。
3.3 基于网络爬虫的构建相空间
网络爬虫程序是非递归方式完成爬行的过程,在完成数据抓取时主要通过构建等待、运行、完成、错误四个序列[7]。在该过程中,等待序列是OA冲处理网页的集合;完成序列是已完成抓取任务的数集合;错误序列是爬虫在任务过程中解析数据信息或读取数据超时的集合。在抓取网页大数据的过程中,若同一时刻下的爬虫只能存于同一序列中,可将此看作一个运行状态,具体过程如图2所示。

图2 运行变化过程
大数据的序列表现形式为非线性时间序列,根据非线性时间序列中的关键点建立相空间[8],相空间可确保数据信息的准确性,是网页大数据抓取中的核心部分。
基于网络爬虫构建相空间的一维时间序列,其表现形式为{q1,q2,…qN},则重新建立的相空间矩阵为
Q={Q1,Q2,…,QN}
(9)
也可表示为
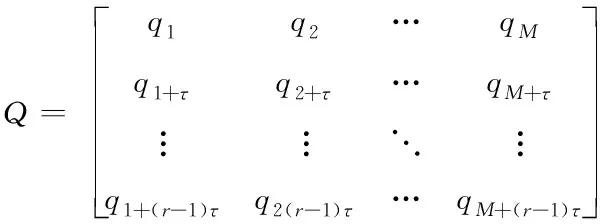
(10)
其中
M=N-(r-1)τ
(11)
上述式(9)到(11)中,τ代表时间延长;r代表嵌入维数值。若r≥2d′+1,此时网页中的大数据几何特征得知,其中d′代表网络爬虫的维度[9]。
3.4 大数据关联维特征抓取
在相空间构建完成后,获得到相空间的矢量数值[10]。按定义划分,关联维属于分维定义的一种,是数据信息在网页多维空间中密度的体现,表示数据信息的关联情况。如果建立后的相空间内存在的点数量为k,选取其中差值最大的两组矢量数值,将差值看作两点间的距离,可被描述为
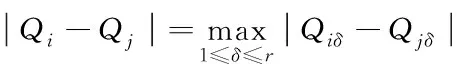
(12)
结合式(12),将间隔距离小于既定正数l的矢量称为关联矢量,假设构建的相空间中包含K个点,计算出相关联的矢量对数,可得出全部可能的K2中组合所占据的被定义为关联积分,其表达形式为
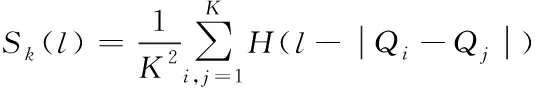
(13)
式(13)中,使用H表示爬虫函数,即
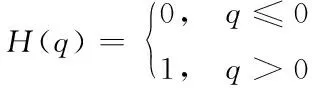
(14)
有相关研究表明,当关联积分Sk(l)处于l→0时,与l间的关系如下
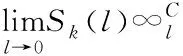
(15)
其中,C代表关联维数值,若l的数值大小选择合理,可令C代表爬虫间的相似性结构,近似值计算方程为

(16)
在实际数据抓取过程中,通常对双对数InSk(l)→Inl进行分析,不将斜率等于0以及为∞的直线考虑其中,选择其中的最佳拟合直线,并设置该条直线的最佳执行斜率为C。
标准差即网页大数据中的样本点分布形式的体现,关联则是根据数据在多维空间中的分布密度提下。据此,针对基于网络爬虫的大数据抓取,若相对差较大,则抓取到的数据样本信息与实际偏差较大,这是由于页面数据布局不集中,导致关联维数值偏低,通过抓取到的关键特征数值,对大数据的分布关系可进行如下描述
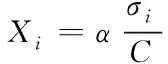
(17)
式中,α表示倍频因子,假设令α=0,σi表示在第i层分解后的相似系数的标准差值。
结合上诉分析可知,在一些数据标准差值较大的情况下,关系维数值相对偏小。通过分析式(17)可得到,当Xi的数值越大时,与之相对应的大数据布局越稀疏,关联程度越小。因此基于网络爬虫对网页大数据进行抓取,可对数据关键特征完成抓取任务。
4 仿真研究
为了验证本文所提方法对网页大数据抓取的效果,设置仿真对网页大数据抓取方法可行性进行验证。
4.1 仿真条件
选取某高校内网作为仿真环境,将网络爬虫分别配置在3台计算机中,处理器均选用奔腾频率为43.0GHz的处理器、内存为2GB的DDR 667、以及CITOS5.4的操作系统,同时3台计算机中都具备单独的网络IP地址。将计算机3个节点间的传输速度设为101MB/s,通过边界路由器连接公用宽带为5MB/s网络,具体结构如图3所示,其网络实验平台示意如图4所示。
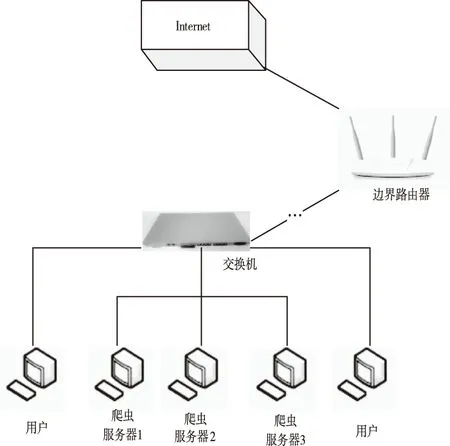
图3 仿真网络环境
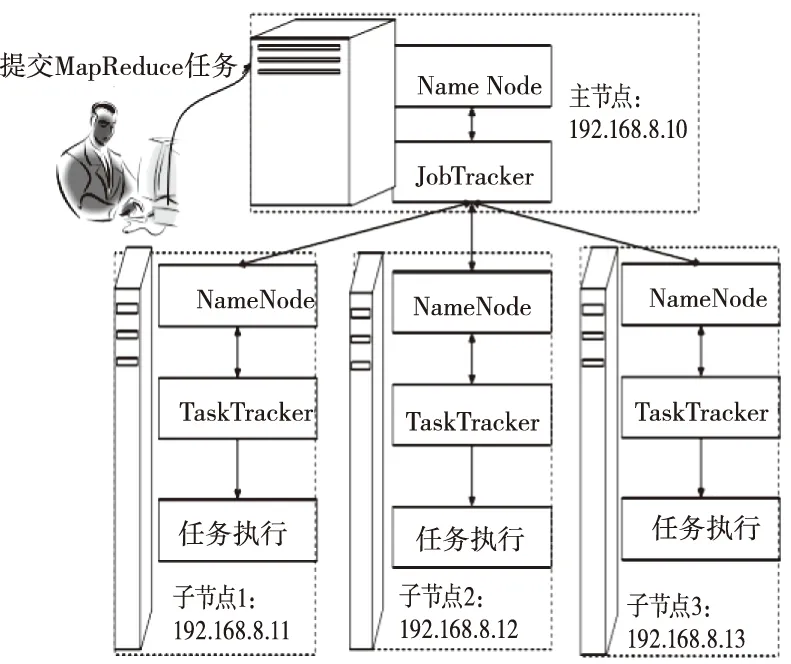
图4 网络实验平台示意图
4.2 实验结果分析
因所要抓取的网页与网络爬虫服务器件,存在网络路径质量以及网站的繁忙程度各不相同的情况,针对该问题,本次实验选择相同的20个网页,并将网络爬虫的深度设置为3进行测验,所得到的选用平均数值。针对本文所提方法对计算机系统内的参数进行了不同设置,得到的3次大数据抓取结果如表1所示。

表1 本文所提方法数据抓取结果
在上述实验中,对比文献[2]、文献[3]以及文献[4]数据抓取方法在参数不改变条件下进行的测试,结果如表2所示。

表2 其它方法抓取结果
根据表1和表2得到的数据抓取结果分析,本文所提方法的3次抓取数据中,成功抓取数据信息的数量对比文献[2]、文献[3]以及文献[4]方法较多,并且每次抓取数据所需时间比其它文献方法短。本文所提方法在其它方法的基础上,放弃了少量的网页数据抓取,大幅度提高了抓取效率,是由于基于网络爬虫提取数据的关键特征,抓取成功概率越来越符合实际情况。
分析图5和图6可知,本文方法3次测试中,大数据抓取成功率均高达90%以上,而文献[2]、文献[3]和文献[4]的抓取成功率在70%到80%之间。本文方法3次实验耗时均在14s以下,其它文献方法均高于17s。现阶段,在网页大数据的规模不断扩大的情况下,若想通过网络爬虫实现整个网页数据完整抓取是存在一定难度的,首先由于网页自身孤点的原因,其次由于网页数据信息量庞大,实时性较高且网络架范围广,会因抓取速度较慢造成一些网页被放弃,甚至由于响应时间较长导致用户不得不放弃游览的页面。对于网络爬虫抓取方法而言,在不间断抓取网页大数据的情况下,可将节约的时间用于抓取更多的数据信息,以少量的计算过程大幅度提高抓取效率,有较高的应用推广价值。
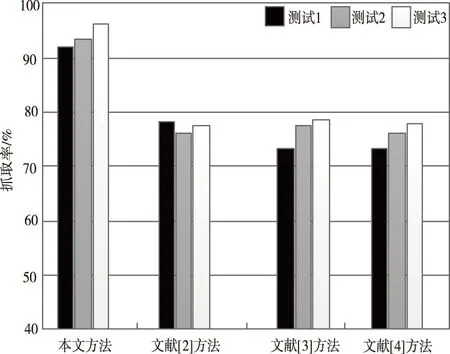
图5 大数据抓取成功率对比
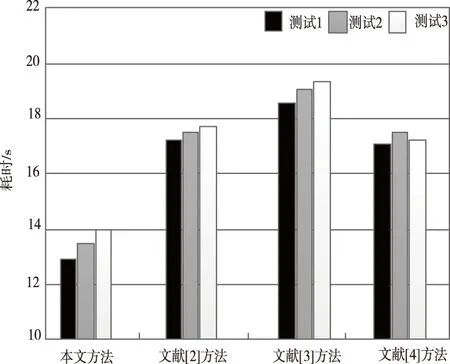
图6 大数据抓取耗时对比
5 结论
解决传统网页大数据抓取方法效率低,误差大,为此本文提出了基于网络爬虫的网页数据抓取方法,将整个网页集和看做一个大数据库,从而提供完善的数据信息内容以供监测与提取。最后通过仿真证明了所提方法的可行性以及有效性,可为今后的数据信息抓取提供可靠的有效方法。在后续的数据抓取中,可利用构建的相空间与网页数据关联维,对网页大数据的关键特征进行获取,将得到有关网页数据内容信息以及用户访问行为方式。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
速读·下旬(2021年11期)2021-10-12
现代信息科技(2021年21期)2021-05-07
大东方(2019年12期)2019-10-20
智能计算机与应用(2018年5期)2018-10-20
魅力中国(2018年5期)2018-07-30
电脑知识与技术·经验技巧(2018年1期)2018-05-30
科学与财富(2017年22期)2017-09-10
中学科技(2016年7期)2017-05-16
商情(2017年1期)2017-03-22
