
大规模集群网络疑似攻击自主检测方法仿真
2021-11-17 03:58郭倩林张翰林
计算机仿真 2021年3期
郭倩林,张翰林
(1.青岛大学智慧校园与信息化建设中心,山东 青岛 266071;2.青岛大学计算机科学技术学院,山东 青岛 266071)
1 引言
网络技术的不断更新和深入发展使人们对网络依赖程度越来越高,网络改变了人们工作和生活方式。但是网络规模的扩大使其面临的风险也随之增加[1]。
由于大规模集群网络存在开放性和匿名性等特征,一些用户出于某种竞争等目的恶意向互联网系统发起大量疑似攻击行为,导致网络能源耗尽,甚至出现崩溃现象[2]。一旦网络出现瘫痪,将会带来巨大经济、资源损失。为此,人们经常使用防火墙技术、攻击检测等方式对攻击行为进行防范。但是这些方法检测范围有限,检测到的攻击信息也较为片面。因此网络疑似攻击自主检测已经成为热点研究课题。
文献[3]提出基于两级分段模型的异构数据处理和网络攻击检测方法。整理分析异构数据并对其进行建模分析,获取在多核条件下模型分布特征,对模型做分布式训练,实现网络攻击行为检测。
文献[4]提出基于自适应免疫计算的网络攻击检测方法,利用密度聚类方法对自体训练数据做预处理,在聚类分析的基础上,去除噪声数据形成自体检测器,然后结合自我检测器构成非自我检测器,结合自适应免疫计算检测异常攻击行为。
虽然上述两种方法在一定程度上扩大了攻击检测范围,改善了检测片面性缺陷,但是不能结合攻击的动态变换做自主调整,降低了检测灵敏度。为此,本文利用模糊数据分离方法对大规模集群网络疑似攻击自主检测进行研究。通过聚类算法对疑似攻击数据做模糊数据分离,构建对检测有价值的数据集合,根据联合评分偏离度对数据集合中疑似攻击数据进行判断,进而实现对集群网络疑似攻击自主检测。
2 风险评估函数设置与攻击数据初步判断
2.1 风险评估函数
在检测疑似攻击的过程中,首先需去除攻击样本数据中的冗余信息,保留具有较大特征值的主要成分。然后假设采集到的疑似攻击样本数据特征为xij∈X(i=j=1,2,…,N),则有
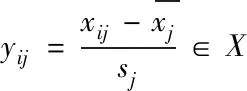
(1)
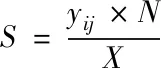
(2)
在此基础上,根据式(3)计算样本数据的主成分
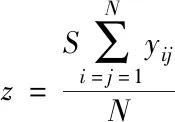
(3)
如果主成分可以表示90%以上的数据特征,就可以将其当做表示样本特征的主成分值。若将最后确定的样本特征主成分数据表示为G=(xi,di),其中xi代表数据特征向量,di表示输出期望值,对这些数据进行从高维到低维的映射,可将非线性关系变换成线性关系

(4)
式(4)中,φ表示高维空间特征值,w代表权重,b属于偏移量。为满足网络疑似攻击自主检测过程的需要,需建立风险评估函数并确保评估结果的平滑性,因此先设计一个风险函数[5-6],表达式如下

(5)
式(5)中,ε表示评估误差,C表示风险系数。为准确计算疑似攻击风险评估值,需带入正向松弛变量ξ,且必须符合下述约束条件

(6)
2.2 攻击行为初步判定
大规模集群网络节点间的连接存在择优性,从整体上看节点间具有密切的关系连接,但是这种连接并不是均匀分布。一些节点存在大量连接,属于整体网络的核心节点。因此,为提高疑似攻击检测精准度,利用混合免疫方法对所有节点进行定义[7],并选择最佳节点数、划分代码矢量,经过对矢量集合中违背排名顺序的节点进行识别,完成对疑似攻击数据初步判断。
假设s表示节点总数量,T(xt,yt)表示其中一部分节点坐标,将T(xt,yt)变换为二维矢量,L表示所有坐标二维矢量组成的一个平面,通过下述公式将L平面分割成多个互不相交的子区域
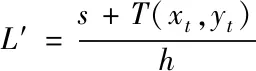
(7)
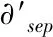
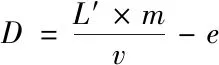
(8)
式(8)中,v表示二维矢量的种类,m表示任意两个矢量之间欧氏距离,e描述矢量误差。然后假设μ表示第j类矢量集中数目,r表示矢量集合初始聚类中心,则通过下述公式能够计获取节点在疑似攻击检测区域的位置分布状况
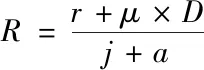
(9)
式(9)中,a表示所有节点状态种类。如果f表示一个受到疑似攻击的数据检测序列,d为受攻击数据所在子区域的距离序列,利用式(10)对大规模集群网络疑似攻击行为进行初步判断
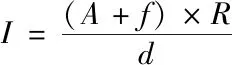
(10)
式(10)中,p表示节点次品率,A为网络节点状态种类集合。
以上分析能够表明,在对网络疑似攻击自主检测过程中,在对所有节点总数进行定义的基础上,选择合理节点数量,划分代码矢量,最终完成疑似攻击初步判断。
3 基于模糊数据分离的疑似攻击自主检测
3.1 构建检测器动力学方程
在实际的检测过程中,疑似攻击自体通常存在动态变换特征。因此,与其相对的自体耐受和检测过程(抗体)同样也是不断变化的。自体动力学表达式如下:
S(t)=Sdead(t)-Svar iation(t)+Snew(t)
(11)
式中,Svar iation(t)表示变异自体,Snew(t)代表新形成自体,Sdead(t)则为淘汰自体。
为确保检测器具有多样性特征,利用随机方法对一部分检测器选择,其余部分则采用基因自由组合方式生成[8]。这种方式可以确保网络疑似攻击检测器检测的准确度。利用下式表示网络攻击候选检测器
Inew(t)=Rrandom(Ag)+Rrandom(G(t))
(12)
式(12)中,Ag表示网络攻击检测器集合,其实质属于二进制字符串,长度表示为l。基因库动力学方程表示为
G(t)=G(t-1)-Gdead(t)+Gnew(t)
(13)
式(13)中,Gdead(t)表示在t时间点出现虚警的记忆细胞,Gnew(t)代表t时间点上发出反应的抗体克隆细胞。在检测过程中,对于不同变异攻击行为,仅需要获取克隆抗体,即可控制检测器进化方向,改善系统对疑似攻击风险检测能力[9]。在此基础上,通过下式表示获取较为成熟的网络攻击检测器

(14)
式(14)中,Tnew(t)表示t时刻成熟的检测器,Imaturation(t)则代表进化形成的检测器,Tclone(t)为经过克隆形成的检测器。
综上所述,网络疑似攻击的记忆检测器动力学表达式如下
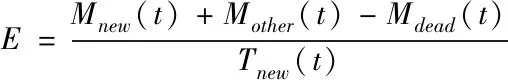
(15)
式(15)中,Mnew(t)表示新的记忆检测器,Mother(t)表示从其它系统中得到的记忆检测器,Mdead(t)表示自体记忆检测器,且
Mnew(t)=Tactive(t)+Mclone(t)
(16)
式(16)中,Mclone(t)表示克隆检测器集合。综上所述,分别研究自体与抗体动力学表达式,为疑似攻击检测提供理论依据。
3.2 分离模糊攻击数据
由于传统算法在检测过程中需要设置参数才可以检测出疑似攻击次数,检测过程较为复杂,因此本文在获取检测器动力学方程后,基于聚类的模糊数据分离方法对疑似攻击进行检测。在检测过程中,对疑似攻击的网络信息做模糊数据分离,构成疑似攻击数据集合[10],详细步骤如下:
步骤1:检测过程中,假设H={h1,h2,…,hn}表示模糊数据集合,若该集合隶属于空间Rp,因此可以表示为hn∈Rp。
步骤2:将误差平方和函数当作聚类函数,表达式如下
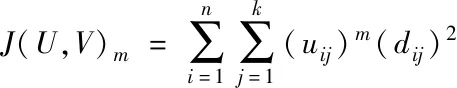
(17)
式(17)中,uij表示检测样本中与数据点对应的第j个聚类中心的隶属度,V描述聚类中心数据集合。
步骤3:利用聚类方法能够将式(17)中J转换成最小值的(U,V)。然后将全部聚类结果根据含有疑似攻击数量多少排序,将Q当作阈值,如果集合高于Q则表示为正常聚类集合;若小于Q,将其确定为疑似攻击数据集合。
上述即为通过聚类方法对疑似攻击模糊数据分离的全过程,为完成疑似攻击检测提供有力条件。
3.3 疑似攻击自主检测的实现
将联合评分偏离度作为疑似攻击判断依据实现疑似攻击自主检测[11]。假设USr表示联合评分偏离度,r表示对疑似攻击数据的评分结果,uik表示支持数据构成集合,将其定义成数据支持度[12],表达式如下:
USr=|Uik|
(18)
不同类型疑似攻击数据集合相对的攻击子集不同,在任意一个子集中,攻击数据一般会最大限度的偏离评分平均值,且存在相同偏离方向,由此准确判断出攻击子集中存在的疑似攻击数据,以此实现大规模集群网络疑似攻击自主检测。
4 仿真分析
4.1 仿真设计
为验证本研究设计的大规模集群网络疑似攻击自主检测方法的实际应用性能,将本文方法与文献[3]中的基于两级分段模型的异构数据处理和网络攻击检测方法、文献[4]中的基于自适应免疫计算的网络攻击检测方法进行仿真对比。

其它参数设置情况如下:网络最大延时为17ms,数据集合中的样本数量为2000个,链路容量为50Mb/s,节点缓存大小为300Packets,数据包共300个。
实验分别从攻击漏报率、检测灵敏度以及误检率三方面对三种不同的检测方法的应用性能进行对比。
如果η表示所有网络数据样本总数,k1表示实验总次数,k2表示正确检测到的攻击次数,n表示实际受到攻击数据,则疑似攻击检测漏报率为
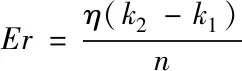
(19)
根据式(19)能够看出,Er值越小,检测精准度越高。
若φ表示数据检测平均代价,利用下式分别计算检测灵敏度Ek与误检率Ec。

(20)
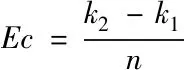
(21)
4.2 实验结果与分析
对攻击漏报率、检测灵敏度以及误检率三项指标的检测结果分别如图1、图2、图3所示。

图1 不同方法攻击漏报率对比图
从图1中可以看出,三种方法漏检率均处于10%以下,但是相对来说,本文方法的攻击漏报率最低,这主要因为本文方法对网络数据进行模糊分离,构成疑似攻击数据集合,使检测过程更加全面,因此对攻击行为的漏检率较低,充分满足疑似攻击检测对精准度的要求。
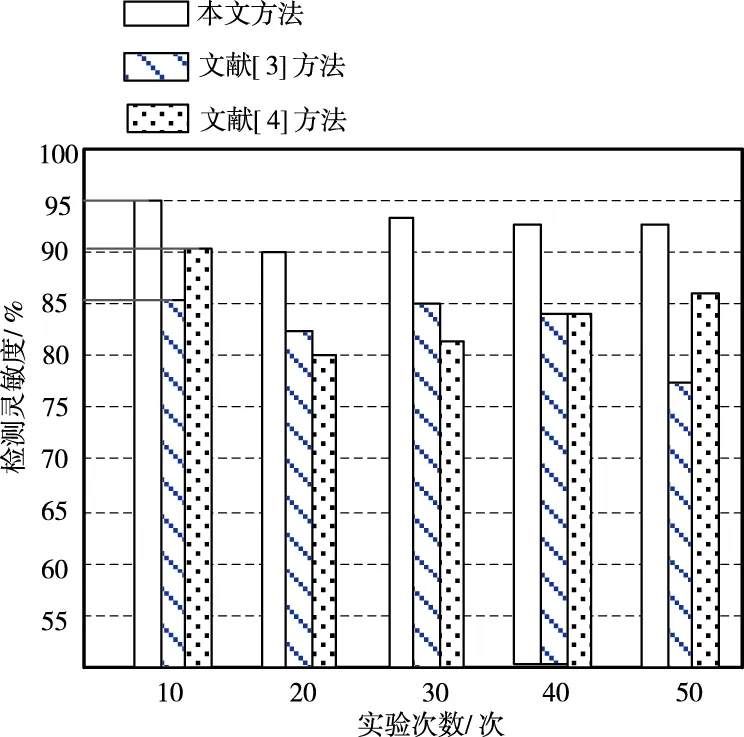
图2 不同检测方法检测灵敏度对比图
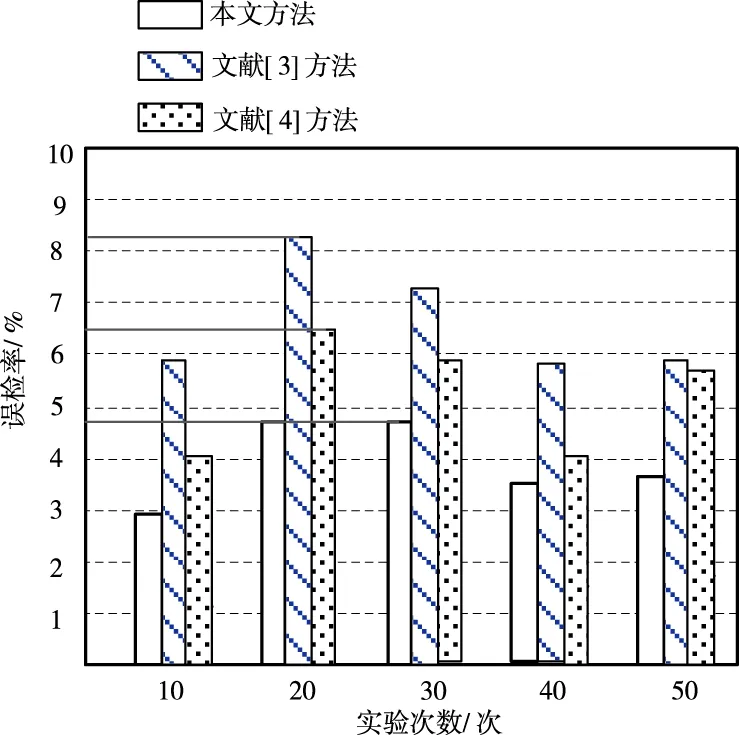
图3 不同检测方法误检率对比图
综合图2与图3可知,本文方法的检测灵敏度远远高于其它两种方法,因此,相应的误检率也较低,这是由于所提方法确定风险评估函数,对攻击行为进行初步判定,保障网络疑似攻击检测质量。相对来说,基于自适应免疫计算的攻击检测方法和基于两级分段模型的攻击检测方法的检测灵敏度不理想,相应的误检率也会有所增加。
5 结语
本研究利用模糊数据分离方法获取聚类目标函数,在确定约束条件后,根据联合评分偏离度实现大规模集群网络疑似攻击行为检测。仿真结果表明,该方法对攻击行为的漏检率低,检测灵敏度较高,可充分满足检测精度的要求。
然而,疑似攻击检测不能全面解决网络安全问题,因此,在接下来的研究中,可以将这种方式与其它安全技术以及网络结构特征相结合,使之互相融合、补充,共同在一定范围内确保网络系统安全稳定运行。
猜你喜欢
中国当代医药(2022年25期)2022-10-20
医院管理论坛(2022年7期)2022-10-14
新传奇(2022年26期)2022-07-22
现代装饰(2022年3期)2022-07-05
测控技术(2022年4期)2022-04-27
中国典型病例大全(2022年9期)2022-04-19
家庭医药(2019年9期)2019-09-23
科技风(2018年15期)2018-05-14
中国新闻周刊(2017年33期)2017-09-20
Coco薇(2015年10期)2015-10-19
