
基于Python爬虫技术的虚假数据溯源与过滤
2021-11-17 03:12周力臻
计算机仿真 2021年3期
陈 丛,周力臻
(福建师范大学协和学院,福建 福州 350117)
1 引言
随着嵌入式计算与传感器技术的不断发展,推动了无线传感网络的迅速崛起,并广泛应用于军事、医疗、建筑等领域[1]。与传感网络不同,无线传感网络将海量廉价小型传感器节点随机布置在不同区域,利用自组织形式生成网络,同时采用多跳方式将信息传输给用户,每个节点都具有数据采集、处理、定位与连接等功能。但无线传感网络属于开放式网络,其计算性能、储存空间较为有限,抗捕获能力较弱,攻击者可通过捕获节点获得其中敏感信息,并对其注入虚假数据,如果不能及时过滤掉这些虚假数据,则会导致网络瘫痪,引发错误报警,影响用户决策[2]。为此,该领域研究者对该问题进行了很多研究,并取得了一定成果。
文献[3]提出基于能量感知路由和节点过滤的虚假数据过滤方法。该方法将距离与能量相结合,提出能量感知和节点过滤方法。与传统密码交换机制不同,该方法在会话构建前有策略的将重点密钥传输到部分节点中,而不是全部节点;在选择过滤节点时不但参考距离,且综合分析节点剩余能量与密钥传播信息,有效过滤虚假数据,更好的均衡网络能耗。该方法可有效根据部分节点进行过滤,但该方法过滤的数据覆盖范围存在一定局限。文献[4]提出多路虚假数据分层过滤方法。该方法在完成网络布置后,对每个节点分配相应密钥,利用密集认证方式建立封闭区域,并通过密钥明确簇内节点和验证节点之间的关系,转发需要检测的数据包,判定其包括的节点码、哈希值等信息是否正确;根据sink节点对数据包进行对比与丢弃,以此实现多路虚假数据分层过滤。该方法可以准确过滤掉虚假数据,但对网络虚假数据出现的溯源追踪与定位考虑甚少。
基于上述方法存在的不足,本文利用Python爬虫技术进行虚假数据溯源与途中过滤。爬虫技术通过一定规则自动抓取网页信息的一种程序。其目的是将目标数据下载到本地,便于后续分析。Python语言是一种较为简洁的开源编程式语言,具有标准库与第三方库,用户可结合自己喜好选取最适合的编辑工具来编写爬虫程序。本文设计了Python爬虫系统,利用该系统生成数据包,实现虚假数据溯源与途中过滤。与传统方法相比可以有效追踪虚假数据的溯源,且过滤的数据范围较大,具有一定优势。
2 虚假数据覆盖的网络划分
为了实现网络虚假数据的溯源与途中过滤,本文首先对虚假数据所处的网络环境进行划分。将虚假数据网络覆盖部分分割为同样大小的网格,任意一个节点均有固定监测范围,在此范围内发生的全部状况都能被节点感知。其中,网格便是监测网格。此外节点根据设置的概率,随机挑选多个不在自身监测范围内的网络,将其作为认证网格,节点对认证网格发生的状况进行验证。网络划分情况如图1 所示。

图1 虚假数据覆盖的网络划分
图1 中,存在L个主密钥组,节点必须加入其中一个密钥组,并利用此组中的密钥生成监测和认证网格相对的密钥。若某事件发生时,由该事件节点形成数据报告;然后,节点使用其掌握的事件发生地点密钥为词条数据增添消息认证码MAC(Message Authentication Code)。
每条合法的数据报告需包含T个MAC,且形成这T个消息认证码节点必须出自不同密钥组。当途中节点接收数据报告后,需明确事件发生地址,结合掌握的密钥断定是否对数据报告进行检测与认证。如果不对其认证,则根据一定概率对数据包进行标记[5],并转发此数据报告;如果认证失败,直接丢弃此数据报告。通过对虚假数据覆盖的网络划分,明确其存在的位置以及设置相关密钥,降低算法复杂度。
3 基于Python爬虫的虚假数据溯源与途中过滤
3.1 Python爬虫系统设计
3.1.1 爬虫抓取过程分析
网络爬虫是开发者编写的计算机程序或脚本[6],利用设置的规则,在上述构建的网格中向蜘蛛网一样对网页不停扩张,从中获取目标数据的过程,其抓取过程如图2所示。

图2 网络爬虫抓取过程
由图2可知,抓取过程是一个循环执行过程,经过不停循环获得新的网页信息。以链接构成的集合作为种子源,将其放入待爬取队列中,按照设置的规则从中选取某个链接,并将请求发送到远程服务器,等待服务器返回内容;爬虫得到网页信息后,对内容进行解析,提取重要数据储存在数据库中。此外,获取新的超链接,经过去重处理,进入新一轮数据提取。
3.1.2 系统需求分析
利用Python语言设计的爬虫系统能够为不同领域用户提供数据采集服务的通用型系统。为达到一定效果,系统需具备下述功能:
1)适用较多采集场景:系统设计需适用于不同场景,为不同用户提供服务。
2)界面可视化:结合使用场景,设计图形化界面,确保用户在浏览信息同时,记载用户操作的相关信息,生成爬虫任务脚本。
3)执行爬虫任务:将脚本信息变为能够识别的内容,结合指令驱动[7],完成数据提取。
4)负载均衡:需针对不同性能机器分配适当任务量。
3.1.3 Python爬虫系统设计
Python爬虫系统硬件结构分为客户模块、服务模块、爬取模块与储存模块,如图3所示。
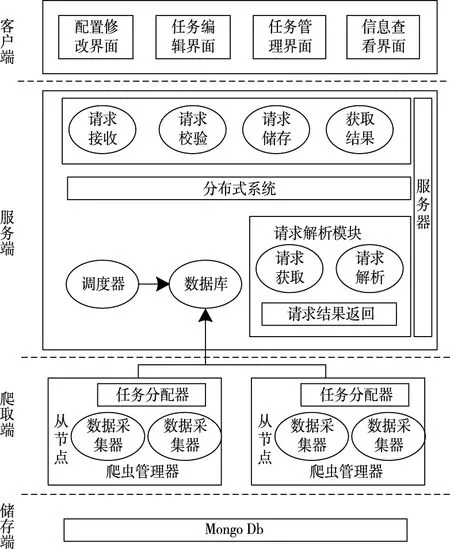
图3 爬虫系统整体架构
其中,客户端是系统交互的入口,提供编辑、任务管理、信息查看等界面。服务端对客户请求及时处理,执行爬虫任务的分配与调度工作。
为追溯虚假数据,降低不同模块之间耦合度,对该系统的硬件部分进行设计。
1)爬虫管理器:该管理器对物理节点启动提供适当虚拟节点。结合节点负载状况,对虚拟节点数量进行调整,确保节点以最佳状态执行爬取任务,简化系统负载程度。
2)爬虫采集器:主要任务为数据采集。包含任务解析与数据管理子模块。
3)内嵌浏览器:利用QT(Qualification Test)框架作为内嵌浏览器,采用Qpush Button部件设置访问按钮,确保信息链接和网页相互对应。
在上述硬件设置后,对系统软件运行机制进行设置。从系统爬取数据角度描述系统软件各模块如何协作,如图4 所示。
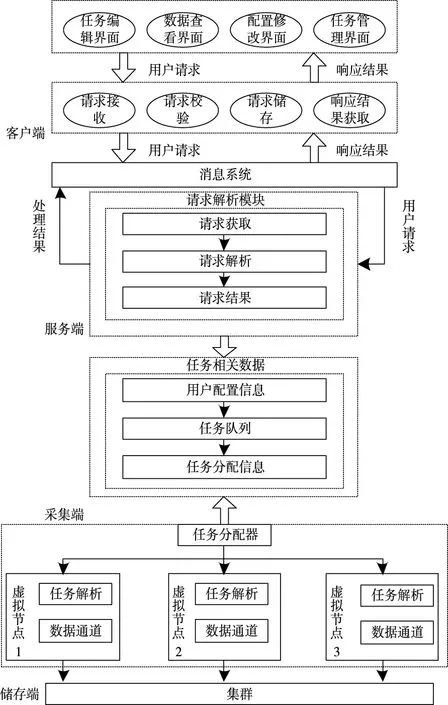
图4 软件运行机制
3.2 关联建立与密钥分配
根据上述构建爬虫系统,通过密钥分配生成数据包,分析密钥验证的合法性,实现虚假数据溯源与途中过滤。
假设存在大小未是N的全局密钥池G,将其等分为n个不重合的分区{Ui,0≤i≤n-1},任意一个分区密钥数量表示为m(N=n×m)。在部署区域将节点任意挑选一个分区进行保存,将此种密钥设为R型密钥。
在完成节点部署后,若某节点的ID最小,将此节点当作簇头CH。由于感知半径大于传输半径,因此,设簇内全部节点可以同时感知发生事件。CH采集簇内数据生成hello包:{y,CH,S1,S2,…,Sy},y表示计数器,原始值是簇内节点数量,S1,S2,…,Sy为簇中节点。
CH将hello向sink方向传输,传输跳数取决于y。首个中转节点Si接收包后,删除节点数最后一位,记录Sy。Si与Sy是一对协作节点,Si处于上游,而Sy为下游。Si将自身节点号插入节点数组首位,并转发数据包,继续执行爬虫过程,此时计数器y减去1。
hello数据包传输y跳后停止操作,位于最后的中转节点Sj形成一个仅包括其本身节点的ACK包:{Sj},且将其按照hello数据包的方向进行传输。中转阶段顺次将自身节点引入到数据包末位,簇内节点从包中ACK记载协作节点序号[8-9]。
协作节点间利用消息共享一对密钥,密钥类型表示为A′。簇内节点随机挑选一个R型密钥对A‘密钥进行加密,同时传输给簇头,簇头将这些信息压缩再传输到sink节点。构建协作关系的区域可以对数据进行认证,将其称作封锁区。
3.3 虚假数据包的生成
在建立关联后,如果检测到突发事件,簇头将感知值传输给每个簇中的节点。获得信息的节点S将感知数值与设定的阈值e比较,如果低于设定阈值,认为两个数据相同,并任意选出一个R型密钥与其A型密钥生成签名:MR,MA,将其传输给簇头,当簇头采集t个节点签名信息后形成数据报告
R0={C;e;R1,R2,…,Rt;MR1,MR2,…,MRt
A1,A2,…,At;MA1,MA2,…,MAt}
(1)
式中,C表示跳数计数器,其原始值表示为y;R1,…,Rt属于R型密钥,MR1为密钥R1生成的MAC;A1…At描述节点号,MA1是A1节点利用对偶密钥生成的MAC。利用布隆过滤器[10]将两种MAC映射为d比特字符串,即
F=b0,b1…bd-1
(2)
则生成的虚假数据包为
R={C;e;R1,R2,…,Rt;A1,A2,…,At;F1;F2}
(3)
式中,t的取值是过滤性能与能耗情况的折中。
3.4 虚假数据溯源过程
当sink节点获得数据包后,使用共享密钥证明MAC是否合法,如果不合法,启动溯源过程。
当检测到存在虚假数据时,选择新的虚假数据包,向上一跳传输一个查找请求信息Q,当节点A1收到消息后,查询缓冲区域,并对信息Q进行广播,其邻居节点获取查询信息后,检查缓冲区日志,若没有查询到有关内容,则不发送应答信息ACK;若查找到有关内容u.a[i].SrcID==Q.SrcID,则利用sink节点共享密钥生成Mu,即

(4)
并将应答信息传输到A1,传输过程描述为

(5)

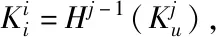
当节点A1获得全部应答信息后,断定各信息中A1的前一跳节点是否一致,根据缓冲区查询结果,挑选与前一跳节点相同的查询结果,并将回复信息传输到sink节点。A1传输到sink节点的回复消息形式为
A1→sink=IDu1,…,IDut,IDd1,IDd2,Q.SrcID
Q.Seqno,Mu1,…,Mut
(6)
当sink节点获得上游节点回复的信息后,必须断定信息中是否包括节点认证,再结合共享密钥验证信息的合法性,经过验证后,获取IDd1与IDd2值。当获得全部回复信息后,可以重构路径,溯源到虚假数据。
3.5 虚假数据的途中过滤
在Python爬虫系统中,虚假数据途中过滤详细步骤为:
1)核对数据包内是否存在t对{Rk,MRk};{Ak,MAk}元组,如果不存在则将数据包删除;
2)核对数据包内t个R型密钥是否出自t个不同区域,若不存在,则删除数据包;
3)如果节点具有数据包内一个R型密钥,则使用此密钥重新获得R型MAC,且与数据包内原有MAC进行比较,若不同则删除数据包;
4)如果节点中不具有任何一个密钥,则将数据包直接过滤,实现虚假数据的过滤。
4 仿真分析
4.1 仿真环境及参数
本文使用C++语言构建模拟仿真平台,在一个半径为100 m区域内,随机布置1000个传感器节点,主密钥数量设置为6个,在圆形监测区域内,源节点与sink节点分别布置在圆心与圆的四周。具体仿真参数如表1所示。

表1 仿真参数
4.2 仿真方案
在上述仿真环境下,通过对比所提方法、基于能量感知路由和节点过滤以及传感器网络多路虚假数据分层过滤方法,以虚假数据途中过滤效果、虚假数据过滤的覆盖性以及虚假数据追踪定位准确性为指标,验证所提方法的科学有效性。
4.3 实验结果
4.3.1 虚假数据途中过滤效果
在虚假数据途中过滤效果分析中,通过分析虚假数据途中过滤比例与传输跳数之间的关系,反映方法的过滤效果。实验对比了所提方法、基于能量感知路由和节点过滤方法以及传感器网络多路虚假数据分层过滤方法的过滤效果,如图5 所示。
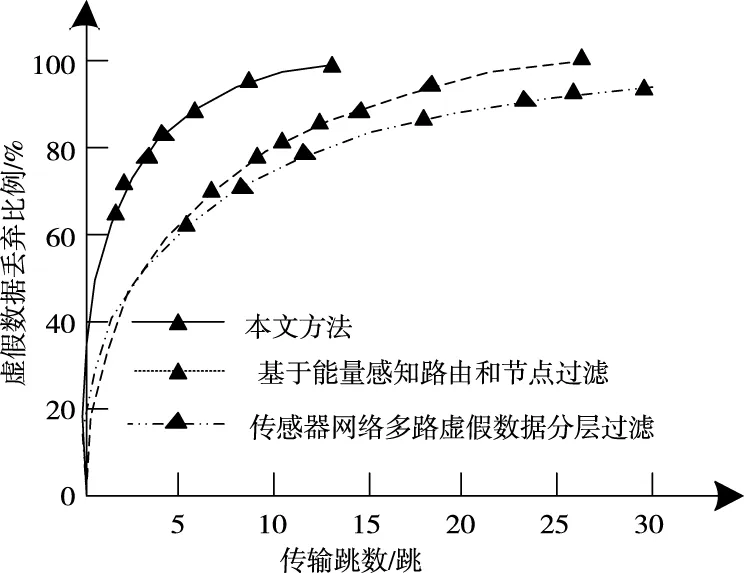
图5 虚假数据途中过滤效果分析
分析图5中可以看出,利用本文方法时,虚假数据的大部分在前5跳即可被过滤,而其它数据也在前15跳全部过滤完成,而其它两种方法在前5跳基本无法过滤虚假数据,在15跳后仍有数据没有被过滤。相比之下所提方法途中过滤性能明显优于其它两种方法。
4.3.2 虚假数据过滤范围覆盖性能分析
实验分析了所提方法、基于能量感知路由和节点过滤方法以及传感器网络多路虚假数据分层过滤方法在过滤时的覆盖性能,将部署区域的网络节点数量分别设置为1000、2000和3000个,在每种情况下分别进行100次实验。实验结果如表2 所示。

表2 不同过滤方法覆盖性能对比
由表2可知,随着节点数量的不断增长,本文方法的覆盖性能始终保持较高水平,而其它方法覆盖性下降较快,导致虚假数据过滤效果不理想,验证了所提方法的有效性。
4.3.3 虚假数据追溯跟踪定位精度分析
实验采用三种方法对虚假数据进行溯源定位,比较虚假数据成功定位的概率,实验结果如图6 所示。
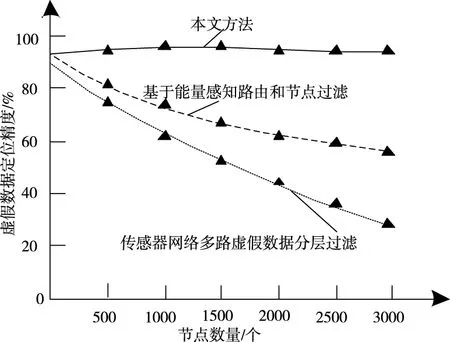
图6 不同方法追溯跟踪性能对比
从图6中可以看出,所提方法对虚假数据定位的精度更高,始终高于90 %,而其它两种方法定位精度呈现下降趋势,且始终低于所提方法,这是由于所提方法利用Python爬虫系统对虚假数据进行溯源,收集更多数据报告,提高成功定位的精度。
5 结论
针对传感器虚假数据的注入,利用Python爬虫技术设计爬虫系统,建立封锁区域、生成数据包以及判断数据是否合法启动溯源程序,并对虚假数据进行途中过滤。与传统方法相比具有以下优势:
1)采用所提方法对虚假数据中途过滤的效果较好,且过滤的覆盖性能具有一定优势。
2)采用所提方法对虚假数据溯源的定位精度始终高于90 %,具有一定可信度。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
计算机与数字工程(2022年3期)2022-04-07
故事作文·低年级(2022年2期)2022-02-23
故事作文·低年级(2022年1期)2022-02-03
现代信息科技(2021年21期)2021-05-07
物联网技术(2018年8期)2018-12-06
智能计算机与应用(2018年5期)2018-10-20
计算机与网络(2018年2期)2018-09-10
电脑知识与技术·经验技巧(2018年1期)2018-05-30
中国新通信(2016年2期)2016-03-11
