
共享单车短时需求量预测的机器学习方法比较
2021-11-18 05:06曹旦旦范书瑞夏克文
计算机仿真 2021年1期
曹旦旦,范书瑞,夏克文
(1. 河北工业大学电子信息工程学院, 天津 300401;2. 河北工业大学大数据重点实验室, 天津 300401)
1 引言
在如今这个大数据时代,通过对大数据进行分析来快速精确预测某一时间某一地点的共享单车短时需求量,从而合理地确定单车的投放数量和调度安排,是个亟待解决的问题。现阶段对共享单车需求量预测的研究主要有如下方法。在影响共享单车短时需求量的各种因素方面,Campbell等(2016)[1]通过对北京共享单车项目的调查指出,影响共享单车需求因素主要有距离、气温、降水、空气质量等;Matton 和 Godavarthy(2017)[2]指出气温、风力、降水等气候条件是影响共享单车需求的主要因素;Faghih-Imani 等(2014)[3]提出,时点因素也是影响共享单车需求的重要变量,包括每天的时间段、是否周末、高峰时间等;Zhang等[4]和Li等[5]还发现车站的位置、大小、服务范围是否重叠也会对车辆的需求量产生影响。在共享单车需求预测方法方面,文献[6]对共享单车需求的预测采用的方法集中在传统线性OLS模型、二分类和多分类Logit模型等,这些经验模型需要大量观测数据,且具有明显的局域性,回归关系不能很好符合实际情况。Kaltenbrunner等人[7]对里昂和巴塞罗那的公共自行车系统采用时间序列分析来预测其每小时的需求情况。Bacciu 等(2017)[8]采用机器学习中的支持向量机和随机森林模型预测了共享单车站点是否会在短时间内有单车归还,但没有系统讨论单车使用的短期需求等问题。
目前国内外对在短时间内的共享单车需求量预测的研究较少。而机器学习由于其预算速度高效,预测精度高且应用范围广等优点,已经广泛应用于各种算法和计算机等交叉学科。为了避免上述算法的缺陷,本文提出了当前最为主流的五种机器学习模型:随机森林,极端随机树,人工神经网络,支持向量机和XGBoost。将这几种模型分别应用于美国共享单车系统,并在bike-sharing数据集上对各学习方法进行了仿真。通过性能比较发现,极端随机树和随机森林方法在实验中效果比较好,可以用来对单车短时需求量进行预测。
和之前的预测方法相比较,本文所使用的需求量预测方法的创新之处在于:①上述已做的相关工作中,对单车需求量的预测主要使用一个方法,而本文则使用了多个机器学习方法,实现对需求量的预测,并对不同方法的预测效果以及相关指标进行了对比。②和其它相关工作相比较,本文将大数据机器学习方法引入共享单车行业的“小时级”短期需求预测,提升行业对即时性需求的预测效率,从而辅助企业的实时调度,提高单车资源的整体利用水平。
2 基于机器学习的单车需求量预测方法工作原理
2.1 支持向量回归机
SVM是一种有监督学习模型,通常用来解决线性和非线性问题。本次研究中需构建非线性的单车需求量预测回归模型。SVM利用非线性映射算法将影响单车需求量的的低维特征空间非线性转化到另一个高维空间使其线性可分,从而在高维特征空间采用线性方法对影响单车需求量样本的非线性特征进行线性分析。在搭建模型的过程中,采用核函数RBF来预测每小时的单车需求量,因为RBF核函数不仅可以处理线性可分和不可分问题,且参数少,构建的模型的复杂度低,预测效率高。
2.2 人工神经网络
神经网络构建网络拓扑结构,通过确定学习规则、模拟人体神经元的工作过程。其结构由输入层、隐藏层和输出层构成。本文的网络结构为:输入层由10个神经元组成,代表影响单车需求量的10个特征变量,隐层设置为4个神经元,输出层由1个神经元组成,不同的层次之间具有不同的网络权值,神经网络的学习问题就是网络权值的调整问题。网络权值确定后,对于给定的输入,通过整个网络的处理,得到最终的输出结果。
2.3 随机森林
随机森林是利用多棵CART树对训练集样本进行训练,然后对测试集样本进行回归预测的模型。它由多个决策树构成,且这些决策树之间无关联性。在用随机森林模型预测共享单车需求量的过程中,每当输入一个新的样本时,随机森林中的每一棵决策树分别对这个样本进行一次回归预测,最后将得到的所有的回归结果进行算术平均得到的值为最终的模型输出。
2.4 极端随机树
Gourt P等人[9]提出了极端随机树算法,它是一种集成算法。在用极端随机树模型预测共享单车需求量的过程中,按照决策树里的CART算法来生成基回归器,且在形成决策树的过程中随机性强,每个基回归器使用全部的影响单车需求量的特征样本进行训练;这样重复迭代K次,生成K颗决策树,直至生成极端随机树;最后用该极端随机树对单车数据集的测试样本进行预测,得出每小时的单车需求总量,然后统计一下所有的基回归器的预测结果,通过投票决策的方法来产生最终的回归预测结果。
2.5 XGBoost
XGBoost算法的基本思想是把多棵预测准确率较低的树模型组合起来,构建一个准确率较高的模型。该模型不断地迭代提升,每次迭代生成一棵树来拟合上一棵树的残差。最后训练完成得到K棵树,来预测一个样本的分数,最后将每棵树对应的分数加起来后就得到了该样本的预测值。
3 实验分析
3.1 实验环境与数据集
3.1.1 实验环境
本次实验环境在Windows7系统中使用Anaconda Navigator3(Jupyter notebook),Python3.6为实验平台进行仿真。
3.1.2 实验数据说明
针对本次研究选用 UCI(University of California Irvine)的Bike Sharing Dataset 中的每小时自行车使用量部分。相应的,由于自行车骑行情况同天气有明显的关系,所以数据中的特征变量主要由相关气候指数组成,比如温度,湿度,是否下雨,所处季节等,同时还包括假日以及周末等特征。该自行车使用数据来自于美国华盛顿特区2011到2012年两年的首都共享单车租用记录和对应时间的天气和季节信息,该数据集包含17370个样本点。使用的数据字段包括16个变量,其具体名称和含义见表1。其中具体的时间因素影响特征又包括24个时段变量、7个星期变量、是否周末、是否其它法定假日以及工作日等多个维度。
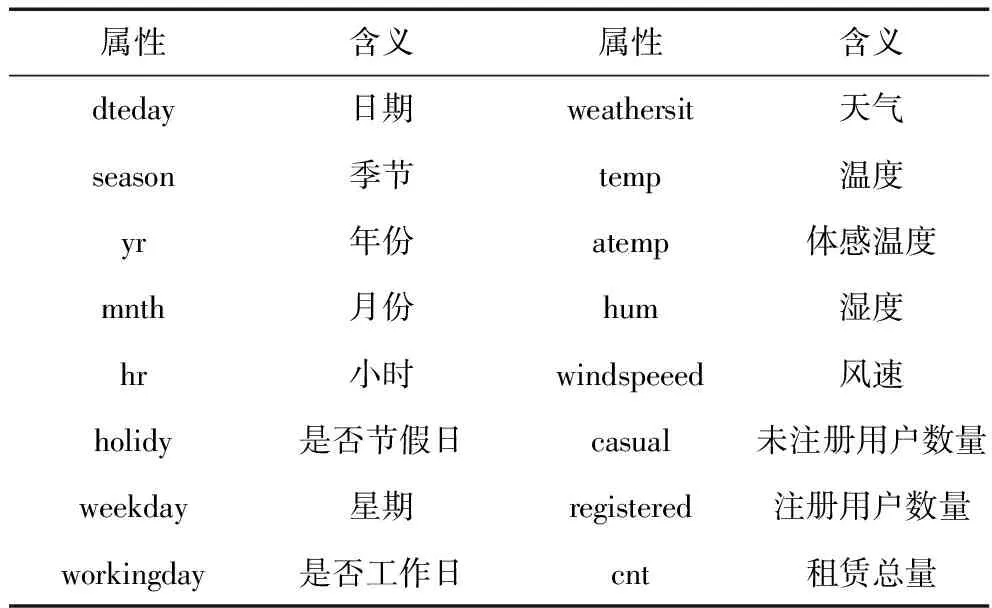
表1 实验中使用的UCI数据集
3.2 影响因子分析
3.2.1 气象因子的影响
自行车是一种受气象影响显著的交通工具,图3所示为2011-2012年华盛顿地区共享单车租借总量与五种气象因子的相关性热力分布图。
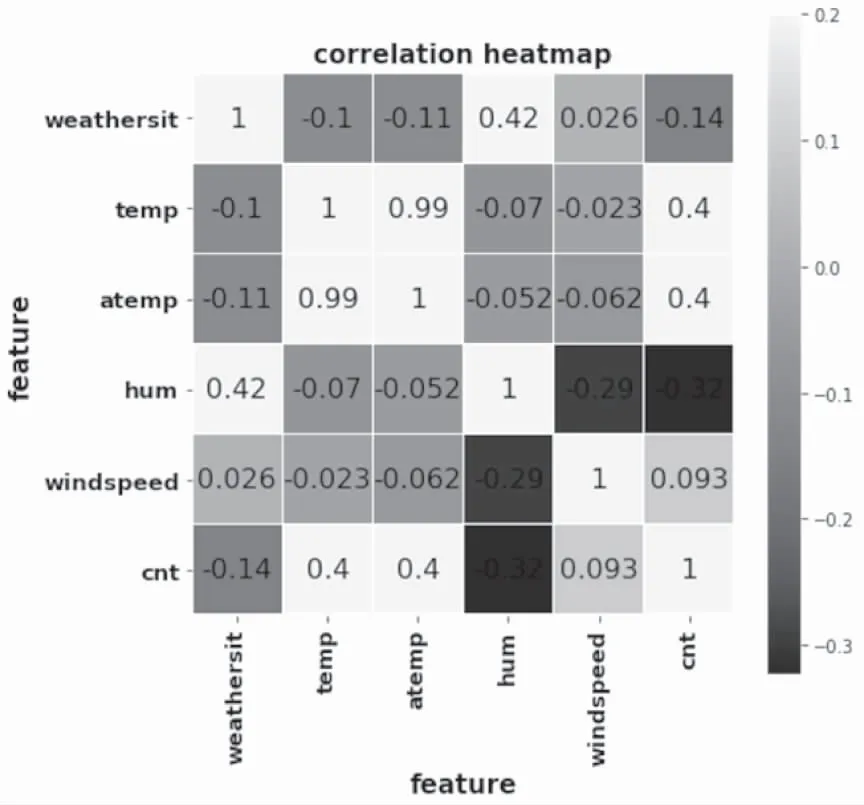
图1 气象因子与共享单车需求量的热力图
由图可得,共享单车需求量与五种气象因子之间都存在相关性,温度、体感温度与租车人数成正相关-寒冷抑制租车需求,其中temp和atemp的意义及其与count的相关系数十分接近,均为0.4,因此可以只取temp作为温度的特征;湿度与租车人数负相关-雨雪天气抑制租车需求;单车需求量与温度和湿度的相关性最高,分别为0.4和-0.32。
3.2.2 时间因子的影响
1)共享单车使用量受时间影响,利用2011-2012年美国华盛顿地区共享单车项目数据进行时序变化规律分析,结果如图2所示。
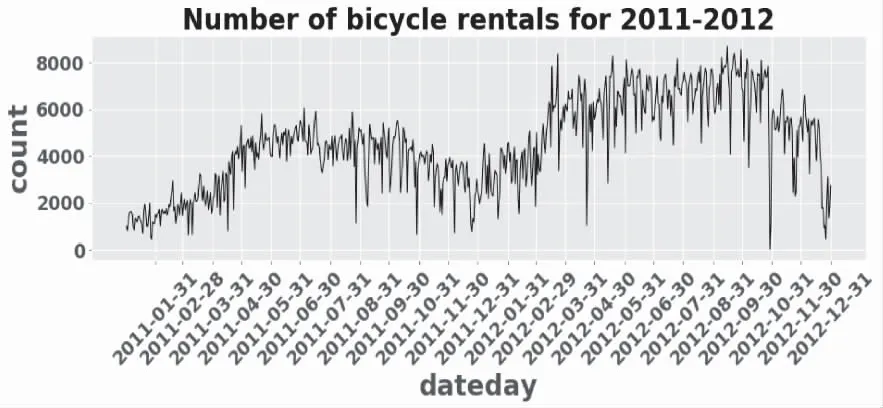
图2 日期与共享单车需求量的折线图
2012年的租借数明显比2011年高,说明随着时间的推移,共享单车逐渐被更多的人熟悉和认可,使用者越来越多。月份对租借数影响显著,从1月份开始每月的租借数快速增加,到6月份达到顶峰,随后至10月缓慢降低,10月后急剧减少。这明显与季节有关。
季节对租借数的影响符合预期:寒冷季节(1,2,12月),工作日租车人数高于非工作日,寒冷季节租车以通勤为主;温暖、凉爽季节(5-11月),非工作日租车人数高于工作日。春季骑车人少,随着天气转暖,骑车人逐渐增多,并在秋季(天气最适宜时)达到顶峰;随后进入冬季,天气变冷,骑车人减少。由此得出yr、mnth等时间因素对count也存在明显影响,因为月份和季节对租借数的影响重合,且月份更加详细,因此在随后的建模过程中可以选取月份特征,删除季节特征。
2)图3进一步考察了以每天的不同时间段为单位,各星期对租借数的影响,并绘制折线图。

图3 星期与共享单车需求量的折线图
上图中的1-6代表周一到周六,0代表周日。从图中可以看出,周一到周五租车人数相对较多,说明非周末情况下上班族需要用车,周一到周五,每天有两个高峰期,分别是早上8点左右和下午17点左右用车人较多,正好是工作日的上下班高峰期;而介于两者之间的白天时间变化规律不明显,可能与节假日有关,因此需要考虑这些法定节假日的影响;而周六日的整体租车人数比较少,其中周六日的上午9点到下午5点用车人数较多。进一步体现了时间段尤其是上下班高峰时间是影响单车需求的重要因素,也体现了节假日与周末两个日期特征对需求的影响。
3.3 实验数据处理
1)特征筛选:通过以上对影响因子的分析,在接下来建模时要删除“注册用户数量”、“未注册用户数量”、atemp和季节这四个对预测结果影响较小的特征。
2)虚拟变量:通过pandas库中的get_dummies()函数对季节,月份和天气等分类变量创建二进制虚拟变量;
3)调整目标变量:为了更轻松地训练模型,需要将温度、湿度和风速等连续变量标准化,使它们的均值为0,标准差为1;同时保存换算因子,在后续进行预测时可以还原数据。
4)数据集划分:本文将总的样本集划分为训练集样本(2011年1月1日0时至2012年12月10日17时样本) 和测试集样本(剩余观测值),并对5种典型的机器学习模型采用5折交叉验证来设定。
3.4 实验方法
基于多种机器学习方法实现,以及华盛顿地区共享单车项目数据集,完成该地区每小时的单车需求量的预测。具体实验方法如下:①首先,对原始单车项目数据进行处理,构建复合要求的数据集;②通过调用训练集完成对机器学习模型的训练,使模型不断提高预测能力;③通过调用验证集对训练出来的模型进行验证评估;④对预测效果进行统计分析,判断预测的精确度,并统计均方误差、平均绝对误差和R平方得分等各项指标来选出最佳的预测模型;⑤调用测试集,用最优模型对单车需求量进行预测,并与实际的骑行人数进行对比。
3.5 实验结果
3.5.1 实验结果说明
评价回归模型性能的主要的几个指标是平均绝对误差(MAE)、均方误差(RMSE)、分数以及CV曲线图等几个指标,具体定义如下
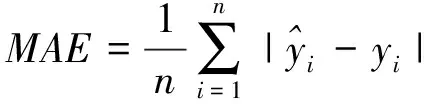
(1)
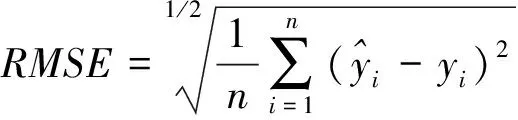
(2)

(3)

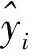
3.5.2 各模型均方误差比较结果
均方误差是用来衡量模型预测值与真实值之间的偏差的物理量,当有一个预测值和真实值之间相差特别大时,那么RMSE就会很大,说明该模型的预测效果很差。图4给出了五种方法的均方误差结果比较。均方误差越低,证明该模型的预测准备率越高。
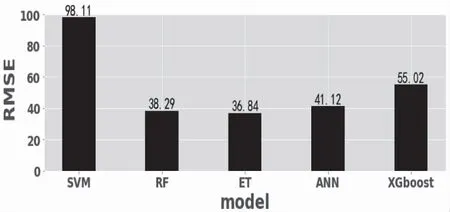
图4 均方误差结果比较
3.5.3 平均绝对误差比较结果
平均绝对误差是衡量模型的预测值与真实值之间平均相差多大的物理量,也就是预测值的无偏性。其值越低,就意味着该模型的预测效果越好。图5给出了五种模型的平均绝对误差的比较结果。

图5 平均绝对误差结果比较
各个模型在该数据集上的均方误差及平均绝对误差比较结果如图4和图5所示。可以得出,无论是RMSE还是MAE,从训练集的预测结果来看极端随机树算法的预测精度最高,其单车需求量预测结果的均方误差和平均绝对误差分别仅为36.84和22.93,其次是随机森林算法,其单车需求量预测结果的均方误差和平均绝对误差分别为38.29和23.52,其它模型在训练集上的回归预测精度大小依次为人工神经网络(RMSE=41.12,MAE=27.31)>XGboost(RMSE=55.02,MAE=38.25)>支持向量机回归(RMSE=98.11,MAE=59.65)。由此可以得出极端随机树的预测精度最高。
3.5.4 R平方得分比较结果
R平方得分是通过数据的变化来表征一个模型拟合的好坏,通过该值可以精确地得出每个模型在该数据集上的的预测精确度。其值越接近1,表明方程的变量对y的解释能力越强,这个模型对数据的拟合效果较好,其值越接近0,表明模型拟合的越差。通过对数据集进行5折交叉验证后的训练集得分和验证集的R得分如图6和图7所示。

图6 训练集上的R得分结果比较
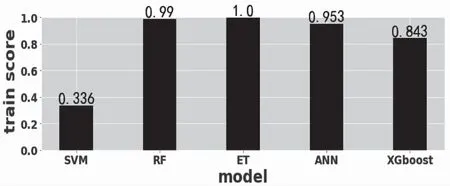
图7 验证集上的R得分结果比较
由上图可以看出,训练集得分最高的依旧是极端随机树,R得分已经达到了1.00,说明在训练集上的预测精度相当高,完全不存在预测误差,其次是随机森林,预测精度达到0.99,仅次于极端随机树。接着是人工神经网络(score=0.953)>XGboost(score=0.843),最差的是支持向量机回归,得分仅为0.336,预测精度极低。从验证集预测精度来看,仍然是极端随机树得分最高为0.941,其次是人工神经网络,再次是随进森林,得分为0.932,XGboost得分0.837,预测误差大,而支持向量机回归对验证集的预测精度极低,仅为0.33,说明该模型不适合在该数据集上的进行预测。由此得出极端随机树的预测精度最高。
3.5.5 CV曲线比较结果
CV学习曲线是样本个数和经验损失函数之间的曲线,是监督学习算法中诊断模型偏差和方差的很好的工具,不仅可以用来判断模型是否过拟合或欠拟合,还可以判断是否为了提高算法的性能需要收集更多的数据。为了验证不同模型在该数据集上的拟合能力和预测准确率,将训练数据集的大小看成自变量,将模型在训练集上的准确率和验证集上的准确率作为因变量来绘制CV曲线图如图8-图12所示。通过不同模型的CV曲线图能够很直观地看出模型的拟合问题和增加训练数据集的大小是否能解决模型的过拟合问题。
由图8和图9两种单一机器学习模型的CV曲线图可得,支持向量机模型是高偏差模型,模型在训练集上的准确率和验证集上的准确率都很低,在0.4-0.5之间,模型不能很好地拟合数据;通过增加训练数据集的个数,支持向量机模型的准确率有所提升,但是还是处于严重的高偏差状态。和该模型相比,人工神经网络模型则表现的比较好,随着训练数据集的增加,两条曲线逐渐收敛,说明不存在过拟合现象;模型在训练集上的准确率和验证集上的准确率也得到了大幅度提升,此时增加训练数据集的个数能够改善模型的性能。

图8 支持向量机模型学习曲线图

图9 人工神经网络模型学习曲线图
图10,图11和图12所示的3个图为典型的集成学习模型的CV曲线图。由图可得,XGboost模型在训练集和验证集上的准确率都很低,处于高偏差状态,且随着训练数据集的增加,效果不但没有改善,反而变得更差;随机森林模型和极端随机树模型则表现的比较好,模型在训练集上和验证集上的得分都很高,训练集上的得分分别达到了0.98和1.00左右,验证集上的得分达到了0.93和0.94左右,说明模型能够很好地拟合数据。随着样本的增加,训练集代价函数一直都很大,验证集的损失函数也逐渐增大,具有很小的偏差和方差,误差逐渐减小。但是,训练准确率和验证准确率还是存在较小的差距,说明这两个模型还是存在轻微的过拟合。这两个模型都很优,但是相比与随机森林模型,极端随机树模型更优。
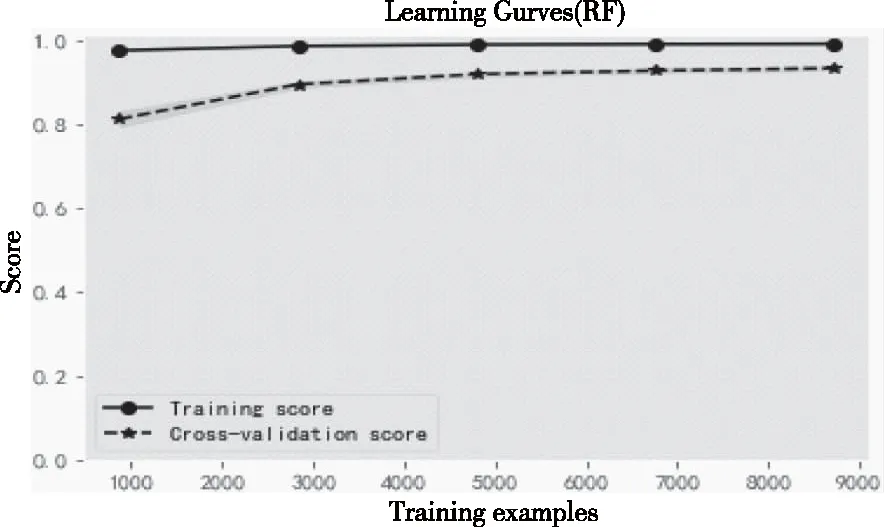
图10 随机森林模型学习曲线图

图11 XGboost模型学习曲线图

图12 极端随机树模型学习曲线图
3.5.6 预测结果分析
用以上得到的最优网络模型对经过预处理和转换后的测试集数据进行预测,预测的结果和实际的结果如图13所示。从图中可以得出,极端树模型能够很好地预测数据,除了最后10天,因为这10天是节假日,自行车需求量和平时不一样。预测的每小时使用量曲线和实际车辆使用量曲线趋势相吻合,满足回归预测过程中的经验误差要求。因此,极端随机树预测模型在共享单车短期需求预测中是可行的。
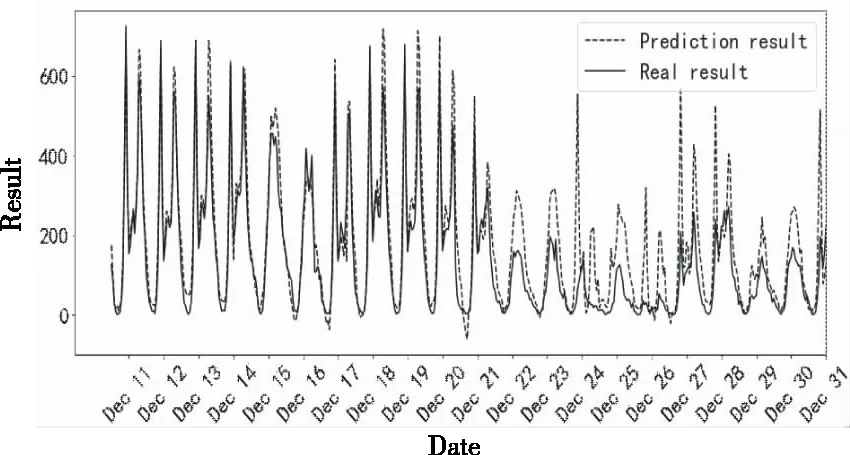
图13 预测结果与真实结果对比曲线
4 结束语
本文把几种典型的机器学习方法应用在美国共享单车数据集上实现单车的短时需求量预测,并通过仿真比较了各个模型的性能。仿真的结果为:极端随机树方法在所选城市的数据集上的具有很高的预测精度,其次是随机森林和人工神经网络,都具有较好的回归预测能力。不仅具有很好的泛化能力,切拟合效果好。相比而言,XGboost模型预测效果偏差,支持向量回归机最不适合应用在该数据集上,预测精度低,拟合效果差。因此极端随机树适合于城市共享单车短时需求量预测系统,可以用来对单车短时需求量进行预测。
猜你喜欢
计算机研究与发展(2022年1期)2022-01-19
数学大王·中高年级(2021年6期)2021-09-27
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
中学数学研究(2008年3期)2008-12-09
