
一种基于精英选择和反向学习的分布估计算法
2021-11-18 05:04孟磊,张婷,董泽
计算机仿真 2021年1期
孟 磊,张 婷,董 泽
(1.大唐环境产业集团股份有限公司,北京100048;2.国电新能源技术研究院有限公司,北京 102209;3.华北电力大学河北省发电过程仿真与优化控制工程技术研究中心,河北 保定 071003)
1 引言
分布估计算法(Estimation of Distribution Algorithm,EDA)是一种结合统计学知识和进化原理的群体优化算法,其概念最早由德国学者H. Mühlenbein和G. Paaß提出[1]。它基于统计学原理,通过对搜索空间内优秀个体的概率分布进行估计和采样,产生新一代群体,如此不断进化,完成寻优。
1996年分布估计算法的概念被提出,自此之后,对该算法的研究层出不穷,总结主要有三类:一是研究算法在解决不同问题上的应用,诸如多目标优化问题[2,3]、调度问题[4,5]、生物信息学问题[6,7]以及工程应用问题[8,9]等;二是对算法本身的理论研究,例如Rastegar分析了cGA(compact Genetic Algorithm)和PBIL(Population-based Incremental Learning)算法收敛到其最优解的概率,并得到了这两种算法的收敛条件[10];Chen 等分析了EDA算法的运算时间与所求优化问题规模的关系[11];Lima等研究了利用贝叶斯优化方法建立的概率模型与问题结构之间关系[12]等;三是对算法的改进。在EDA算法的改进方面,大体有三种:以概率模型为改进主体[13,14]、着重保持种群的多样性[15,16]以及融合算法,其中,融合算法指的是与其他算法的融合[4,17,18]。
以概率模型为主体的改进算法中,一些算法选择了复杂度更高的概率模型。此种改进措施在提高算法性能的同时,带来了一些其他问题,例如,内存消耗的加剧以及计算复杂性的增加。EDA算法产生新个体的方式是通过对优秀个体概率分布的拟合,进而采样随机产生。过拟合在保持种群多样性方面是不利因素,容易使算法陷入早熟风险。对于EDA算法来说,种群多样性的保持是一个很重要的问题。
本文提出一种基于精英选择和反向学习的改进分布估计算法,采用最基本的高斯分布作为概率模型,通过引入精英选择策略和反向学习机制改善算法性能。在提高算法收敛速度方面,精英选择贡献了很大力量,面对精英选择带来的种群多样性减少问题,通过二次反向反射搜索来弥补。二者结合,加速算法收敛到全局最优解。算法性能的验证通过对经典Benchmark测试函数的仿真来实现,与之对比的算法选择性能比较好的EE-EDA算法和基本经典的EDA算法。
2 基本分布估计算法
分布估计算法主要采用统计方法构建优秀个体的概率模型,该概率模型能够反映变量之间的关系,对该概率模型采样以此产生新种群,不断迭代进化,最终实现搜索空间内的寻优。其中的关键步骤主要如下[25]:
1) 初始化
设置种群规模PS,最大进化代数Gmax,搜索空间维数D。初始种群通过在搜索空间范围内通过均匀分布随机产生
pop(xi)0=ai+(bi-ai)×rand(1,PS)
(1)
其中:ai和bi分别是第i维变量xi的下限和上限,rand(1,PS)代表在[0,1]区间上依据均匀分布的方式随机产生PS个个体。
2) 选择
对种群中每个个体计算其适应值,然后按照适应值大小进行排序,选择适应值较优越的个体,构成规模为m=λ×PS的优势群体。
3) 构建概率模型
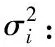

(2)
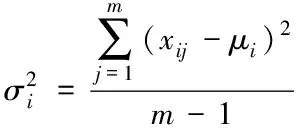
(3)
其中:xij是优势群体中第j个个体第i维的值,i=1,2,…,D,j=1,2,…,m。
第i维高斯概率密度函数为
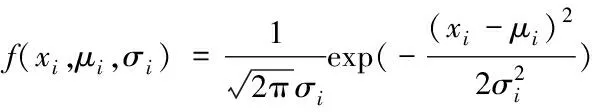
(4)
4) 采样
在搜索空间范围内依据式(4)所表示的概率分布模型随机采样生成规模为PS个个体的种群,这就是下一代种群。
3 改进的分布估计算法
3.1 精英选择
基本分布估计算法产生下一代种群的方式是通过对优势群体的概率分布模型进行采样生成,而优势群体的选择是直接将种群中每个个体按照适应值的大小排序,以截断的方式选择适应值比较优的前m个个体。这种经典的截断选择,操作简单,并且在这m个个体中,无论适应值大小,每个个体所起的作用均等(均为1/m)。在粒子群算法(Particle Swarm Optimization,PSO)的种群更新策略中,通过个体最优和种群最优共同来对迭代速度进行更新,寻优速度非常快,但其弊端亦非常明显:易导致收敛到局部最优。受此启发,提出一种精英选择策略,对适应值比较优的个体的作用进行强化,同时需要对种群的多样性进行兼顾,尽量减小陷入局部最优的风险,提高算法的寻优性能。
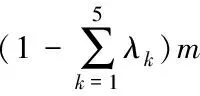
popb(1:λ1m)=xb1;
popb((λ1+1)m:(λ1+λ2)m)=xb2;

该算法打破优势群体中每个个体比重相同的状况,使得适应值最好的5个个体在优势群体中占的比例增加,然而,受启发于PSO算法易陷入局部最优的特点,优势群体并不单单只由这5个个体构成,兼顾收敛速度和种群多样性,从而提高算法性能。
3.2 二次反向反射搜索
2005年,Tizhoosh提出反向学习(Opposition-based learning, OBL)的概念[19],随之机器学习领域整合采用了该机制,使得算法性能得到明显改善。二次反向点的概念由Rahnamayan等提出,并用之于差分进化(Differential Evolution, DE)算法中[20]。2009年,Ergezer提出二次反向反射的概念,并将其用于BBO(Biogeography-based Optimization)算法中[21]。他通过数学分析和仿真证明了其在所有反向学习算法中的优势,说明了其在优化算法收敛速度和全局搜索能力提高方面的强大作用。
这些算法的描述和概念简介如下:
定义1(反向点)
设区间[lb,ub]上存在任意实数y,它的反向点yo为
yo=lb+ub-y
(5)
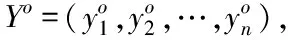
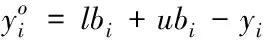
(6)
定义2(二次反向点)
设区间[lb,ub]上存在任意实数y,它的反向点为yo,那么,它的二次反向点yqo为
yqo=rand[ym,yo]
(7)
其中:ym=(lb+ub)/2,rand[ym,yo]为ym和yo之间随机生成的数。

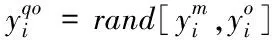
(8)
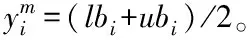
定义3(二次反向反射点)
设区间[lb,ub]上存在任意实数y,yo为它的反向点,yqo为它的二次反向点,那么,它的二次反向反射点yqro为
yqro=rand[y,ym]
(9)
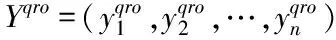
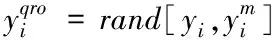
(10)
基于二次反向反射搜索的优化算法:
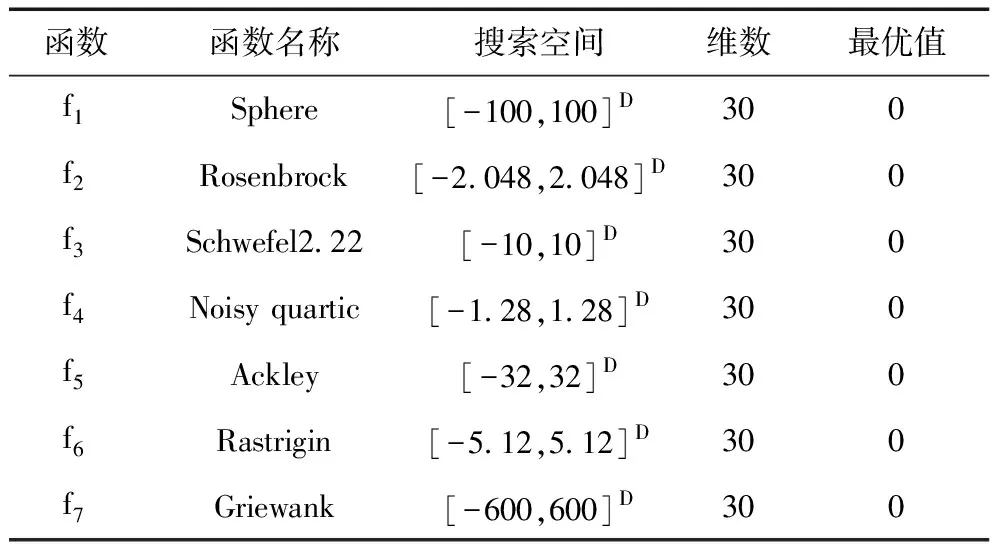
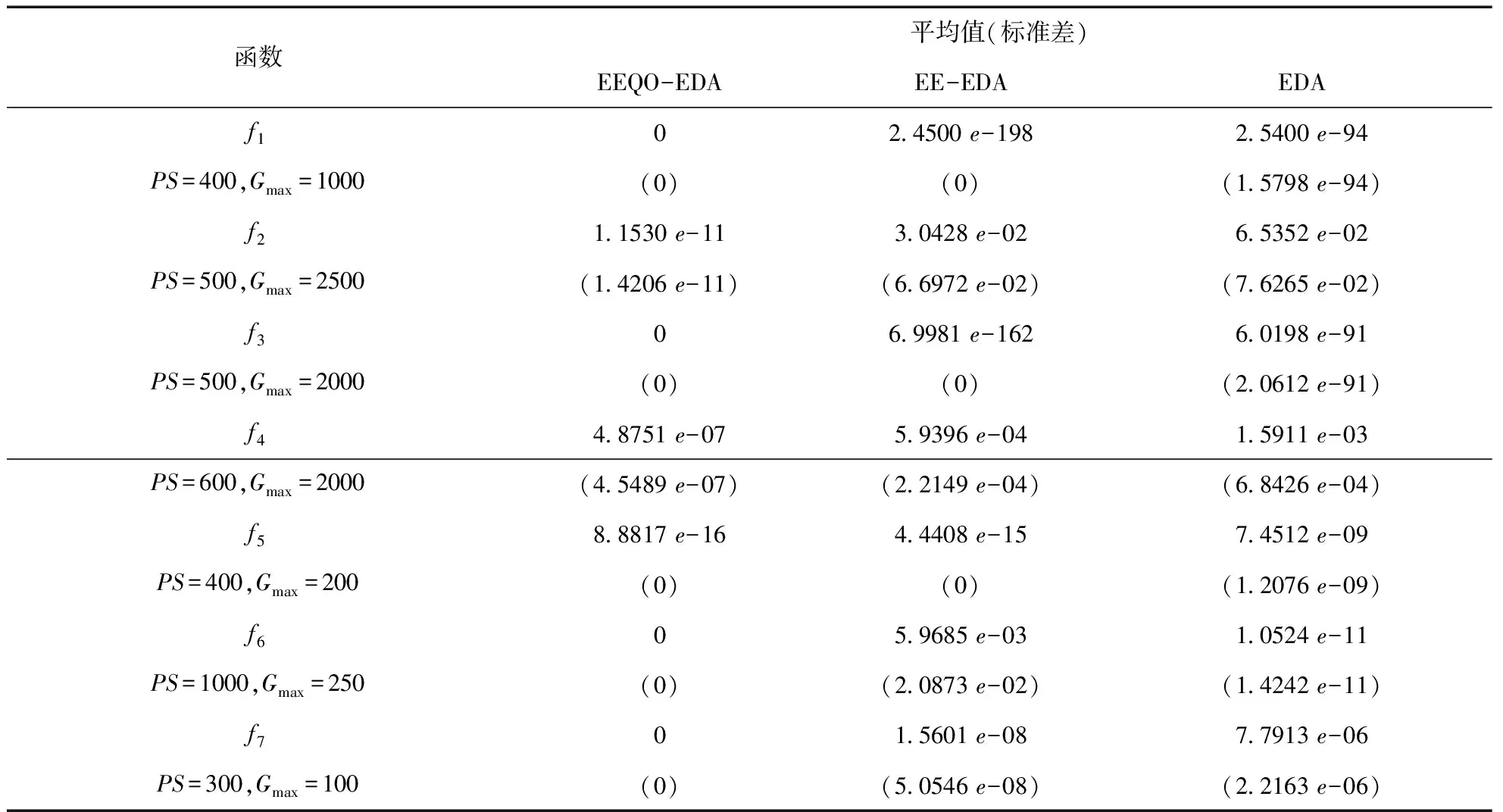
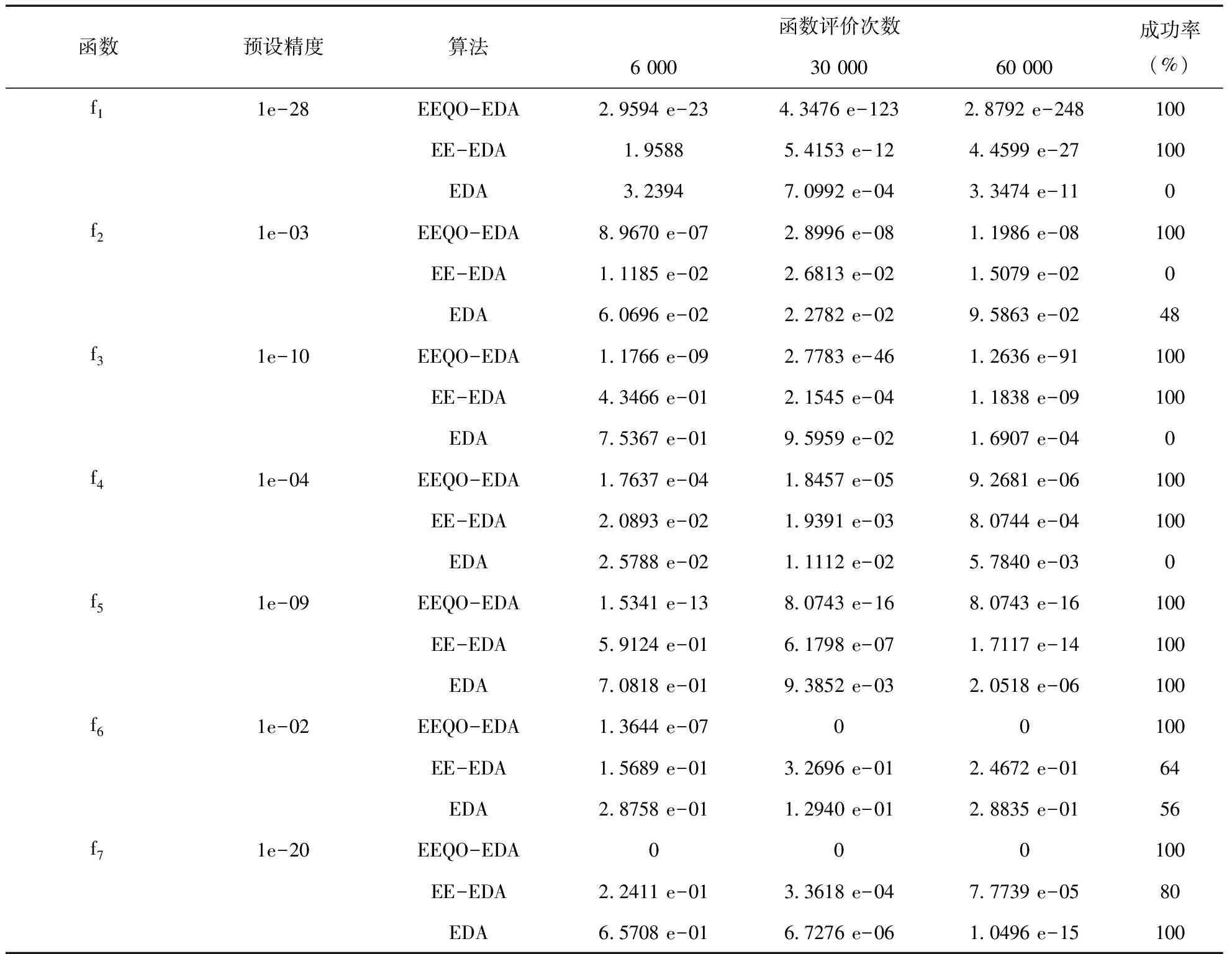
在优化算法中使用二次反向反射搜索算子时,假设Y=(y1,y2,…,yn)为n维搜索空间其中的一个可能解,Yqro是它的二次反向反射解,f(·)是该优化算法的适应度函数,当f(Yqro) 改进后的算法称之为EEQO-EDA,算法的伪代码如下: g=0;∥g代表进化代数 repeatg=g+1; 对两个种群的适应值进行计算f(X),f(Xqro); forj=1:PS iffj(Xqro) X=Xqro; fj=fj(Xqro); else X=X; fj=fj(X); end end 依照从小到大的规则对fj进行排序; 依据精英选择策略来生成优势群体popb; 依照式式(2)~(4)来建立概率模型; 采用随机采样的方式对概率模型采样来生成下一代种群pop(xi); until 满足算法终止条件; output 优化结果及最优个体值。 为了验证本文改进算法的性能,选择了7个标准函数进行仿真测试,并选择标准EDA和已发表的性能很好的EE-EDA[22](EDA with extreme elitism selection)进行对比。运行环境是Windows 7系统,处理器是Inter(R) Core(TM)2 Duo CPU T6570,仿真软件是MATLAB R2015a。 本文所采用的测试函数为标准测试函数,取自文献[23],函数特性如表1。 表1中,这些测试函数大体上分为两种:1)f1~f4是单极值的函数,这类函数不存在收敛到其他局部最优值的情况,可以用来对算法的寻优速度进行测试;2)f5~f7是多极值函数,这类函数存在多个局部最优值,寻优结果可能为某个局部最优值,而非全局最优,这类函数可以用来对算法的全局搜索能力进行测试,测试算法逃离或者避免陷入局部最优值的能力。 在仿真实验中,当采用某个测试函数进行测试时,所有算法的概率模型是相同的,种群规模PS以及最大迭代次数Gmax,对于所有算法是相同的;但是,不同的测试函数之间,算法的PS和Gmax可能不同。这是由算法本身所具有的特性来决定的:有些测试函数的形状整体形如深谷,但是,谷底却比较平缓,对于此类函数来说,寻优算法的最大迭代次数可以设置的大些;有些测试函数的形状起伏较多,即存在多个局部极值点,对于此类函数,寻优算法的种群规模可以设置的大些,一定程度上增加种群的多样性。最后,对于所有算法而言,优势群体的选择比例设置为λ=0.5,也就是说优势群体的数量m=λ×PS=0.5PS 表1 测试函数 算法的参数设置:1) 标准EDA和EE-EDA根据式(1)采用均匀分布的方式随机生成初始种群;2) EEQO-EDA初始种群的生成根据式(1)和二次反向反射搜索相结合;3) 优势群体的产生,标准EDA利用截断选择生成;4) EE-EDA利用精英选择来生成优势群体,并且依据文献[22]的分析,适应值比较优越的5个个体在优势群体中所占据的个数分别为25,20,15,10,5,也就是说,λ1m=25,λ2m=20,λ3m=15,λ4m=10,λ5m=5;5) EEQO-EDA利用精英选择和二次反向反射搜索相结合的方法来对种群进行更新,而其中精英选择部分的参数设置则采用与EE-EDA一致的方式。 为了评价各个对比算法的性能,本文中选择了以下指标[24]: 1) 收敛精度:当算法的迭代过程达到某一评价次数时,各个寻优算法在测试函数上所能得到的最优解的精度; 2) 收敛速度:在不同的终止评价次数下,对于同一个测试函数,各个优化算法所能获得的最优解的精度。假如对于不同的评价次数,某个优化算法所能获得的最优解的精度都比较高,那么,可认为对于该测试函数,该优化算法的收敛速度是更快的; 3) 稳定性:对于某个固定的评价次数,算法独立运行多次,统计多次运行所得到的最优解的精度,得到其方差(或者标准差)作为稳定性的评价依据; 4)鲁棒性:对于某个固定的评价次数,算法独立运行多次,能够获得不低于预设的最优解精度的概率。 4.2.1 收敛精度和稳定性评价 针对每一个单独的测试函数,种群规模和最大迭代次数一定时,对所有优化算法每次寻优所得到的全局最优解进行统计,获得其平均值和标准差。每一个测试函数在每一个优化算法下独立运行25次,对这25次的运行结果进行统计,获得如表2所示结果。 实验结果中,认为均值反映了优化算法的收敛精度,认为标准差是稳定性的反映。表2可以看出,在与之对比的EE-EDA和标准EDA算法中,本文所提出的EEQO-EDA在对所选择的7个测试函数寻优的过程中全部都取得了最好的优化结果。其中,对于体现收敛速度的单极值测试函数f1和f3,体现全局寻优能力的多极值测试函数f6和f7,利用本文所提算法,均收敛到其理论最优解。对于测试函数f2和f4,本文所提的算法虽然没有获得其理论最优值,然而,与EE-EDA和EDA相比,本文所提EEQO-EDA算法在收敛精度和稳定性上的优势依然非常明显。对于多极值测试函数f5,EEQO-EDA算法所得到的最优解在收敛精度上依然优于其他两种算法。而对于EE-EDA和标准EDA来说,除去测试函数f6,在其余测试函数上,EE-EDA在收敛精度和稳定性方面具有明显优势。可以得出以下结论:1)与EE-EDA和标准EDA算法相比,本文所提出的算法具有最优越的收敛精度和稳定性;2)对于多数测试函数而言,将精英选择融合之后的EDA算法(EE-EDA)在收敛精度和稳定性方面具有明显的提高;3)对于融合精英选择的EE-EDA算法,本文所提出的算法在弥补EE-EDA算法不足的同时,使得算法的收敛精度和稳定性显现出明显的提高。 表2 固定迭代次数下,三种算法的收敛精度及标准差对比 4.2.2 收敛速度和鲁棒性评价 为了定量评价算法的收敛速度,对评价次数在6000、30000和60000时算法在函数上所能获得的最优解的精度进行统计对比;为了定量评价算法的鲁棒性,对于各个测试函数,预设一个收敛精度,设置最大评价次数为90000,当达到最大评价次数时,对各个算法达到预设精度的概率进行对比。对于各项试验,令三种优化算法在每个测试函数上独立运行25次,然后对运行结果进行统计,如表3所示。 表3 三种算法的收敛速度及成功率对比 从表3可以得出:1)在收敛速度方面,与EE-EDA和标准EDA算法相比,本文所提出的算法对于不同的测试函数,在不同的评价次数下,所得到的最优值的精度为最高,并且优势明显,这在一定程度上,可以认为本文所提出的算法在收敛速度上是优于EE-EDA和标准EDA算法的;对于EE-EDA和标准EDA算法之间的对比,可以看出,除去测试函数f7,对于相同的评价次数,在不同的测试函数下,EE-EDA所能得到的最优解的精度优于标准EDA算法,或者与标准EDA算法持平,这在一定程度上,我们可以认为EE-EDA算法在收敛速度上是优于标准EDA算法的。2)在鲁棒性方面,当算法达到最大评价次数时,本文所提出的算法在所有测试函数上每次都能达到预设精度,成功率为100%;而对于EE-EDA而言,对于测试函数f5和f6,当达到最大评价次数时,收敛到其预设精度的概率分别为64%和80%,对于测试函数f2,在达到最大评价次数时,均不能收敛到其预设精度,对于其余测试函数,均能在最大评价次数之内收敛到其预设精度;对于标准EDA而言,对于测试函数f2和f6,当达到最大评价次数时,收敛到其预设精度的概率分别为48%和56%,对于测试函数f1、f3和f4,在达到最大评价次数时,均不能收敛到其预设精度,对于其余测试函数,均能在最大评价次数之内收敛到其预设精度。通过对比实验发现,在一定程度上,可以认为本文所提出的算法在鲁棒性上优于EE-EDA和标准EDA。 本文在基本EDA算法的基础上,提出EEQO-EDA算法,将精英选择和二次反向反射搜索引入到EDA算法。精英选择机制可大大提高算法的收敛速度,二次反向反射搜索在增加种群多样性的同时,减弱了算法收敛速度加快带来的陷入局部最优的风险,二者配合,兼顾收敛速度和全局寻优,使得算法性能得到提高。通过对Benchmark测试函数进行仿真实验,验证了其在收敛速度、收敛精度、稳定性以及鲁棒性上的优势。3.3 改进算法
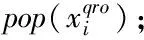
4 仿真分析
4.1 测试函数及算法参数设置
4.2 实验结果及分析
5 结论
猜你喜欢
今日农业(2022年15期)2022-09-20商用汽车(2021年4期)2021-10-13作文周刊·小学一年级版(2021年36期)2021-01-14阅读与作文(小学高年级版)(2020年8期)2020-09-1221世纪商业评论(2019年10期)2019-10-28中学生物学(2018年8期)2018-03-01世界汽车(2016年8期)2016-09-28中国经济周刊(2016年34期)2016-09-02幸福·悦读(2009年11期)2009-01-29中学生物学(2008年6期)2008-08-29
