
多价值链视角下基于深度学习算法的制造企业产品需求预测
2021-11-23 13:00吴庚奇牛东晓耿世平张焕粉
科学技术与工程 2021年31期
吴庚奇, 牛东晓*, 耿世平, 张焕粉
(1.华北电力大学经济与管理学院, 北京 102206; 2.新能源电力与低碳发展北京市重点实验室, 北京 102206; 3.北京清畅电力技术股份有限公司, 北京 100089)
随着市场竞争的不断加剧,制造企业面临的生产、库存、物流等业务成本风险增加。企业想要在竞争脱颖而出,获得更多的利润,首先要做好产品需求预测。准确的需求预测是制造企业扩大市场份额、提高利润的重要支撑。首先,产品需求预测对制造企业合理安排生产计划和物料采购计划具有导向作用,能够有效降低产品供应不足风险和库存成本。其次,制造企业合理的生产计划能够满足下游分销商的产品销售需求,保证其销售利润。同时,良好的物料采购计划保证供应商充足的物料准备时间,有利于供应商有序安排企业整体的供应计划。从而有利于维护制造企业同上下游企业长期战略合作的关系,形成企业间的协同性发展,提高市场竞争力,实现多赢。因此,准确的产品需求预测能够帮助制造企业更好的管理决策,这对制造企业及其上下游关联企业都具有重要意义。传统的产品需求预测往往根据下游计划订单或人工经验,运用统计学等方法进行预测。随着计算机技术和工业互联网的发展,计算机算力和数据支持都有了长足的进步,基于此构建合理的算法模型能够有效提高产品需求预测的准确度。
目前,用于产品需求预测的方法主要有统计学方法,如自回归滑动平均模型(autoregressive moving average model, ARMA)[1],灰色预测模型(grey mo-del, GM)[2]等;智能算法,如人工神经网络(artificial neural network, ANN)[3],支持向量机(support vector machine, SVM)[4]等。李成港等[5]用差分整合移动平均自回归模型(autoregressive integrated moving average model, ARIMA)对物流公司销售数据进行分析预测,结果表明该模型在短期预测上置信度高,能为仓储优化提供辅助决策依据,解决企业仓储不合理等问题。赵军等[6]应用数据挖掘技术建立灵活、准确的预测数据库,将基于指数平滑模型的库存需求预测模型应用于第三方物流中心库存需求预测中,预测效果良好。但当时间序列波动或不稳定时,ARMA、ARIMA、指数平滑等方法的预测效果不够理想。高豪杰[7]利用反向传播(back propagation,BP)神经网络模型对阀门制造企业库存需求进行预测,结果表明该方法能够有效降低误差。但BP神经网络训练时可能会陷入局部最优,需要反复进行参数调优,才能取得较好的预测效果。汪娅等[8]提出一种新的基于约束需求预测的消耗性航材备件需求预测方法,通过遗传算法对其进行求解,获取最优需求预测结果。但遗传算法的局部搜索能力较差,导致单纯的遗传算法比较费时,在进化后期搜索效率较低。综上,单一预测模型或多或少存在一些不足,为了优化预测模型,组合预测模型应运而生。靖可等[9]提出改进BP-ARIMA组合模型用于预测智能制造模式下产品的不确定性需求,结果表明组合模型的预测精度较ARIMA模型有显著提高。贾琦等[10]利用灰色模型构建方便、计算简单、善于挖掘影响因素内部联系的优点,以及LS-SVM在非线性映射分析和稳定性高的优点,设计了一种灰色LS-SVM预测模型,用于解决小样本数据的装备器材需求预测问题。采用组合预测能够结合不同模型的优点,有效应对时间序列不平稳问题,提高预测速度、降低预测误差和风险,保证良好的预测效果。然而,目前用于制造企业产品需求预测的深度学习算法较少。
近些年深度学习的应用掀起热潮,深度学习是一种利用复杂结构的多个处理层来实现对数据进行高层次抽象的算法,以海量的数据和计算机算力作为支撑,普遍能够取得优于神经网络的训练效果[11]。随着工业互联网的发展推动了移动互联网、云计算、大数据、物联网等与现代制造业结合,制造企业也因此有能力提供深度学习足够的数据支持,深度学习算法初步应用于制造企业的产品需求预测方面。任春华等[12]首先提出一种优势矩阵结合轻梯度提升机(light gradient boosting machine, lightGBM)、门控循环神经网络(gated recurrent unit,GRU)的组合预测模型用于汽车配件需求预测,该组合模型能够发挥2种模型的优势,不仅训练效率高效且模型结构简单。Weng等[13]提出了一种基于lightGBM和长短期记忆神经网络(long short-term memory, LSTM)的供应链销售预测模型,实验结果表明该模型能够对供应链销售进行准确、高效、可解释的预测。李琼等[14]在考虑多产品相互制约的条件下,通过GRU-BP组合神经网络预测模型对模型分析求解后证明预测结果的可行性。基于此,考虑引入当前较为火热的深度学习算法构建预测模型,丰富深度学习算法在制造企业产品需求预测等方面的应用,提高预测精度。
近年来,制造企业在注重供应价值链建设,强化自身竞争优势的同时,也开始重视多价值链协同,通过与产品生产销售中的服务价值链、营销价值链等协同性管理提高整体的运作效率。其中,多价值链协同对于制造企业产品需求预测意义重大。相比单一供应链,多价值链协同能够获取更为全面的相关数据,帮助制造企业进行供准确的产品需求预测。
通过上述分析,提出一种基于一维卷积神经网络(one-dimensional convolutional neural networks, 1D-CNN)-长短期记忆神经网络的组合预测方法,将其应用于制造企业的产品需求预测,通过供应链、服务链、营销链等获取足够的多链数据用于模型训练,构建出拟合度高的1D-CNN-LSTM模型,从而精准预测产品需求。模型首先采用1D-CNN自动提取历史产品需求数据的深层次特征,接着利用LSTM对数据的深层次特征进行处理学习,构建时间序列模型实现产品需求的预测。最后基于某制造企业产品需求的历史相关数据进行预测,并将模型预测结果同传统神经网络模型的预测进行比较,分析本文构建模型的有效性。
1 多价值链视角下影响因素的选择
1.1 构建多价值链协同的数据空间
传统的制造企业产品需求预测通常只考虑了单一供应链的物料需求、销售数据等情况,没有考虑到下游代理商的产品售后相关数据、产品营销策略等其他价值链中相关因素的影响,预测结果不够精确。尤其是现在市场环境复杂,制造企业的代理商、供应商众多,供应和销售渠道增多,企业间关系愈发复杂和紧密,产品需求的影响因素越发复杂,仅单一价值链内的数据难以准确预测。因此,应该从多价值链协同入手,协同利益相关企业,在大数据时代数据多且杂的背景下构建数据空间,避免大量无用数据的干扰,从海量数据中收集与产品相关的多链数据集,用于产品需求预测等相关活动。数据空间是以对象为主体,其全生命周期内围绕业务产生的关联数据的集合,充分地考虑了如何在最大程度上利用和展现数据的有效性及可行性,使得其在打破“数据孤岛”,推动多源异构数据快速融合方面快速确立了领先优势[15]。构建数据空间有利于积累信息资源,用于客户挖掘,物料需求预测、产品需求预测、优化物流调度等方面。例如,本文进行产品需求预测,从产品数据空间中获取多链数据集,通过全面的数据助力预测精度的提高。多价值链协同视角下产品的数据空间及数据获取如图1所示。
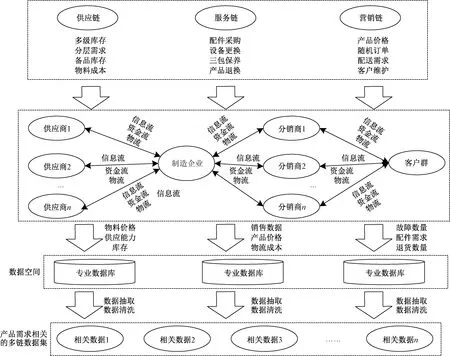
图1 多价值链协同视角下产品的数据空间及数据获取
1.2 产品需求影响因素分析
多价值链数据是由产品需求相关影响因素的相应数据构成,主要包括产品全生命周期过程中供应商、制造商、分销商等链上企业在日常业务中产生的采购、库存、销售、售后等相关信息数据[16]。构建预测模型进行产品需求预测,首先需要选取关键影响因素作为预测模型的输入。产品需求变化的驱动因素众多,全面选择影响程度大的因素对预测结果的准确性有显著影响。
在供应链环节上,供应商、制造商和客户是产品需求的主要影响主体,分析其中的主要影响因素包括产品零部件的供应量、零部件采购总成本、采购提前期、产品订单数量、市场占有率等[17]。在服务链环节上,产品售后服务过程中的产品退换、三包保养、零部件更换等因素对产品需求也会产生一定的影响。在营销环节上,产品价格、营销折扣、节假日和新增客户数量也等与产品的销售情况紧密相关。
2 1D-CNN-LSTM模型构建
2.1 1D-CNN模型
CNN是一种包含卷积计算且具有深度结构的前馈神经网络,其基本结构由输入层、卷积层、池化层、全连接层及输出层构成[18]。相比传统神经网络模型,CNN引入感受野机制,具有局部感受野、权值共享和池化的特点,减少了神经元连接数目和训练参数,从而降低网络模型复杂度,减少过拟合,获得较好的泛化能力[19]。CNN模型具有强大的特征识别和提取能力,可以应用于在时间序列数据分类上,有效的预测时间序列数据的走势[20]。时间序列预测一般使用1D-CNN模型,其卷积和池化仅在一维尺度上进行,卷积核在时间序列数据上进行窗口平移,提取局部序列段与权重进行点乘得到卷积层,进而进行池化下采样得到池化层,多次反复卷积和池化,提取出时间序列数据的关键特征,使得预测性能得到优化。1D-CNN模型的基本结构如图2所示。

图2 1D-CNN的基本结构图
2.1.1 卷积层
卷积层通过卷积核与输入数据的卷积运算获取数据潜在的特征。其中,卷积核即为滤波器,过滤不重要的信息,抓取数据中潜在的重要特征。卷积运算实现了人体的感受野机制,通过局部连接的方式克服了传统神经网络中全连接方式导致的维度灾难,减少了计算量,大幅降低了神经网络模型的训练难度[21]。卷积运算公式为
(1)
2.1.2 池化层
除了卷积层,CNN也经常使用池化层来缩减输入特征的大小。池化主要通过减少网络的参数来减小计算量,提高计算速度,同时提高所提取特征的鲁棒性,防止过拟合。池化操作方法一般包括最大池化、平均池化[23],计算公式分别为
(2)
(3)

2.2 LSTM模型
循环神经网络(recurrent neural networks,RNN)主要用来处理序列数据,在预测领域得到了大量的应用。但随着时间序列长度的增加,由于梯度消失或梯度爆炸问题的存在,传统的RNN会产生长跨度依赖问题,难以保持长期记忆[24]。LSTM是RNN的一种改进模型,其神经单元由输入门、遗忘门和输出门构成,通过门决定以往信息和即时信息的记忆程度,解决了长期依赖问题[25]。遗忘门用于决定遗弃多少细胞状态中的过去信息和当前信息;输入门的作用是将有用的新信息加入到细胞状态;输出门的作用是从当前状态中选择重要的信息作为细胞状态的输出[26]。LSTM模型的基本结构如图3所示。

σ为Sigmoid激活函数;xt-1、xt、xt+1为输入,ht-1、ht、ht+1为输出;ft为遗忘门,it为输入门,ot为输出门;Ct表示当前细胞状态,表示当前候选细胞状态;⊗和⊕表示运算方式
遗忘门、输入门和输出门的计算公式为
ft=σ(Wf[ht-1,xt]+bf)
(4)
it=σ(Wi[ht-1,xt]+bi)
(5)
(6)
(7)
ot=σ(Wo[ht-1,xt]+bo)
(8)
ht=ot×tanhCt
(9)
式中:Wf、Wi和Wo分别为遗忘门、输入门和输出门的权重矩阵;WC为细胞状态的权重矩阵;bf、bi和bo分别为遗忘门、输入门和输出门的偏置项;bC为细胞状态的偏置项。
2.3 1D-CNN-LSTM组合模型
1D-CNN可以快速挖掘时间序列数据中隐藏的特征,但无法学习到时间序列数据中的长依赖特性;LSTM具有较好的长期记忆能力,但对时间序列数据隐藏信息的挖掘不如1D-CNN。因此,本文中结合1D-CNN和LSTM两种模型,首先更好地挖掘出时间序列数据深层次的隐藏特征,再进行时间序列预测,聚合两种模型的优势以提高预测精度。本文构建的1D-CNN-LSTM组合模型的预测流程如图4所示。
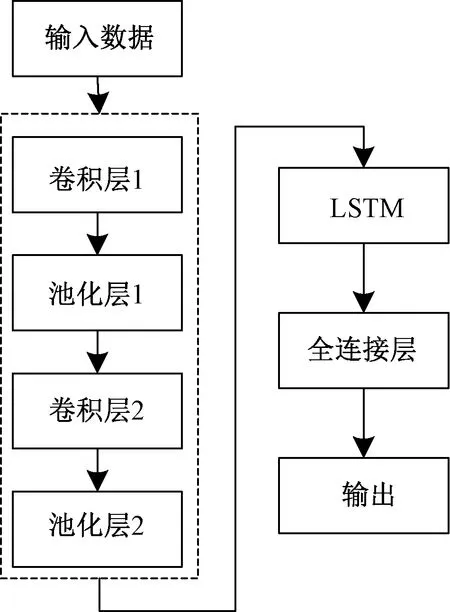
图4 1D-CNN-LSTM组合模型的预测流程图
如图4所示,1D-CNN-LSTM组合模型的及具体实现步骤如下。
步骤1获取原始数据,将数据预处理后输入1D-CNN模型;
步骤2输入数据在1D-CNN模型中进行两次卷积和池化操作,提取数据特征;
步骤3将1D-CNN模型处理后得到的特征数据集输入LSTM模型中,进行时间序列预测;
步骤4利用全连接层对将LSTM模型的输出数据进一步处理,最后输出预测结果。
3 实例分析
3.1 数据与实验环境
3.1.1 数据获取
以某电气设备制造企业为研究对象,对生产销售的环网柜需求进行算例分析。综合考虑制造企业供应链、服务链、营销链对产品需求的影响以及相关数据的可获取性,选取产品价格折扣、产品不合格数量、节假日(节假日及周末为1,正常上班日期为0)、新增客户数量作为产品需求预测模型的输入变量,以销售数量作为产品需求量,构建多价值链数据集,用于产品需求预测。获取的数据为2020年7月6日—2021年7月30日之间的每日数据。其中,随机抽取80%的数据集作为训练集,进行预测模型训练;以剩下的20%数据集作为测试集,对训练好的模型的预测精度进行检验。环网柜需求相关的部分多链数据集如表1所示。
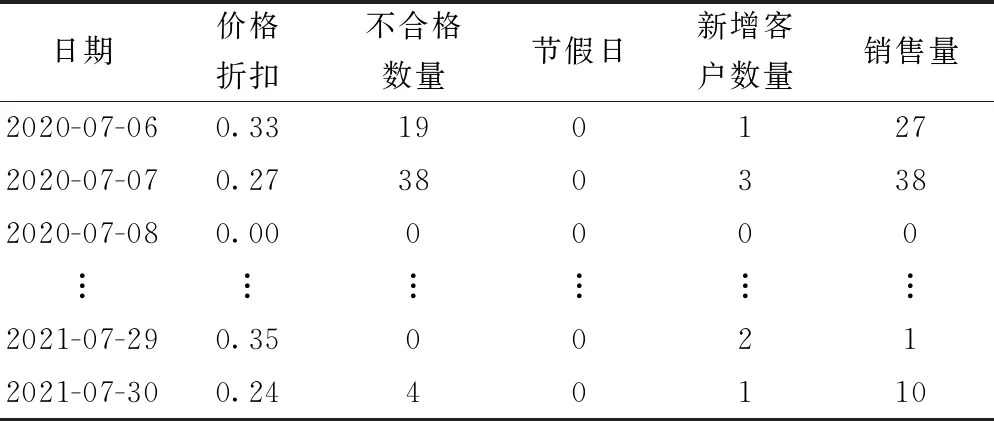
表1 环网柜需求相关的部分多链数据集
3.1.2 数据预处理
从数据空间中获取的多链数据集需要进行预处理,防止数据不规范、异常等因素对预测结果产生影响,主要处理方式包括缺失值处理、归一化处理。
(1)缺失值处理。部分数据有可能在数据空间记录过程中出现某条数据样本丢失或不全的情况。这些缺失值取前后时刻该特征值的平均数。
(2)归一化处理。为了消除数据之间的相互影响,让1D-CNN-LSTM组合预测模型收敛更快更稳定,采用min-max法进行归一化处理,将数据映射到[0,1]区间内。归一化公式为
(10)
式(10)中:xnorm为归一化处理后的数值;x为当前的观测值;xmin和xmax分别为样本数据的最小值和最大值。
3.1.3 实验环境
实验平台为AMD Ryzen 5 4600U with Radeon Graphics,主频2.1 GHz,16 G RAM以及Windows 10 64位操作系统。本文中采用Python 3.7构建实验模型,基于Python的深度学习库Keras2.0实现,Keras以TensorFlow或Theano作为后端,是一个非常方便的深度学习框架。1D-CNN-LSTM模型的超参数设置在一定程度上会影响预测性能,经过反复试验,确定了相对较优的超参数如表2所示,模型组件的参数设置如表3所示。

表2 1D-CNN-LSTM模型超参数设置
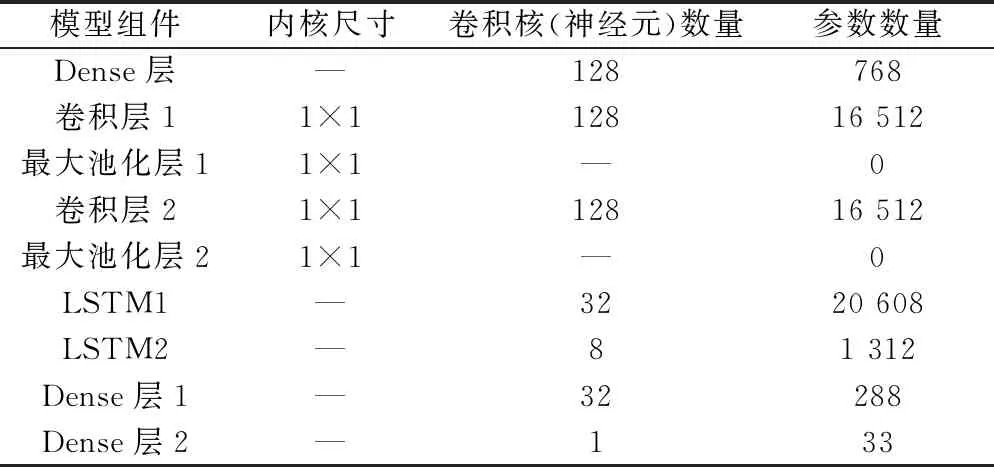
表3 1D-CNN-LSTM模型的模型组件参数设置
3.2 预测结果
对比训练集和验证集的损失值和误差值可以反映模型的拟合能力,因此从训练集中随机选取20%的数据集作为验证集对模型进行验证。本文训练模型的训练集和验证集的损失曲线如图5所示,训练集和验证集的误差曲线如图6所示。从图5和图6可以看出,随着训练次数的增加,训练集和验证集的损失值和误差值先是快速下降,而后收敛,趋于平稳,并且损失值和误差值都收敛于较小的值,反映了本文训练的CNN-LSTM模型泛化能力较好,拟合程度较高。

图5 训练集和验证集的损失对比
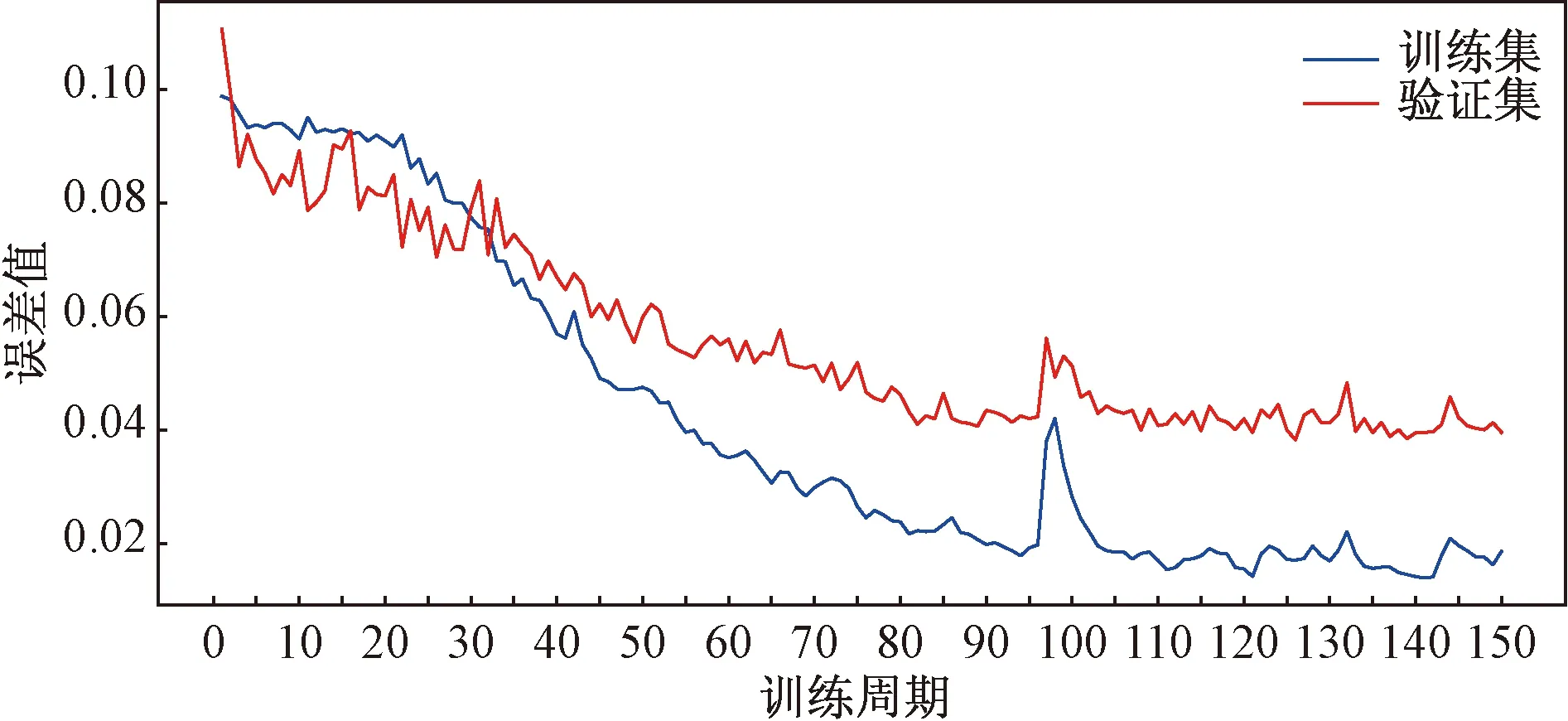
图6 训练集和验证集的误差对比
利用测试集对训练好的模型进一步进行性能验证,图7为测试集的预测结果。对比预测值和实际值的曲线可以看出,预测值和实际值十分接近,预测精度较高,说明CNN-LSTM模型具有较好的预测能力。
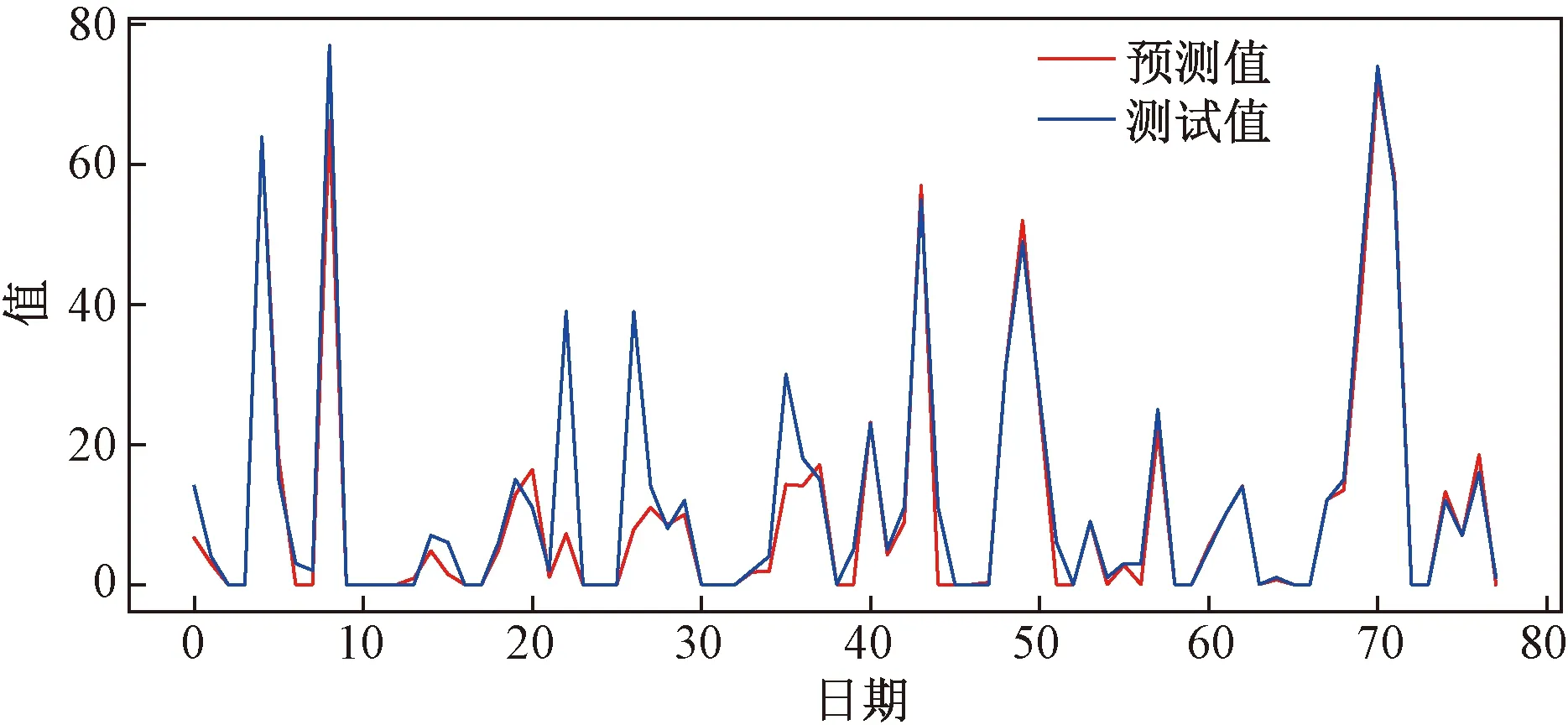
图7 预测结果对比
3.3 与其他模型对比
选取均方根误差(root mean square error, RMSE)、平均绝对误差(mean absolute error, MAE)两种评价指标来检验模型的预测效果,其计算公式为
(11)
(12)
进一步验证本文构建模型的有效性,分别与LSTM模型、BP模型以及PSO-BP模型进行实验对比。选取这些模型基于以下几点考虑:①与LSTM模型进行对比,验证利用CNN改进的LSTM模型是否能够通过抓取深层次数据特征而提高模型的预测精度;②与BP模型、PSO-BP模型进行对比,验证深度学习模型的学习能力是否优于传统神经网络模型,能够训练出拟合能力更强的预测模型。其中,LSTM模型的参数设置为:LSTM1神经元数量为128,LSTM1神经元数量为64,Dropout比率取0.2,Dense层1参数为32,Dense层2参数为1。BP模型的参数设置为:隐藏层节点数为4,训练次数为1 000次,学习率为0.01,最小误差为0.000 01。PSO-BP模型的参数设置为:初始种群数为50,粒子更新位置最大速度为0.9,粒子更新位置最大速度为0.1,隐藏层节点数为4。如表4所示为不同模型预测结果的误差值。

表4 不同模型预测结果的误差对比
从表4可以看出,LSTM模型的误差小于BP模型和PSO-BP模型。这说明了相比传统的神经网络,深度学习网络在足够数据量的支持下进行深层次的学习拟合,能够搭建出预测精度更高的预测模型。另外考虑到了数据潜在特征的1D-CNN-LSTM模型,则在LSTM模型的基础上进一步提升了预测精度。
4 结论
基于多价值链协同视角下制造企业的产品预测需求,首先提出数据空间的概念,构建产品数据空间能够有效整合产品需求变化的所有相关数据。当企业需要进行产品需求预测、物料需求预测等相关活动时,可以简单高效地从数据空间中获取预测所需的历史数据。其次,引入深度学习算法,提出了1D-CNN-LSTM的预测模型,该模型既能快速挖掘数据隐藏的深层次特征,又能长时间记忆历史数据中的信息,能够有效保证预测精度。最后,利用某电力设备制造企业的环网柜销售相关数据对提出的模型进行算例分析,并与其他预测模型进行误差对比,验证本文提出模型的预测效果。主要结论如下。
(1)整合企业生产经营活动中产生的所有相关数据构建数据空间,可以用于产品需求预测、优化物流调度等方面,为企业的经营决策提供依据。
(2)多价值链协作背景下,综合考虑多链对产品需求的影响进行预测,其预测效果优于仅考虑单一供应链上的影响因素。
(3)本文构建的1D-CNN-LSTM模型有效,预测精度高、误差小。其预测效果不仅好于传统的神经网络模型,也优于单一的LSTM预测模型。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
大众投资指南(2021年35期)2021-02-16
消费导刊(2020年41期)2021-01-27
现代经济信息(2020年34期)2020-06-08
软件(2020年3期)2020-04-20
上海节能(2020年3期)2020-04-13
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
消费导刊(2017年24期)2018-01-31
