
改进残差神经网络在遥感图像分类中的应用
2021-11-23 13:00刘春容雷印杰陈炳才
科学技术与工程 2021年31期
刘春容, 宁 芊,2*, 雷印杰, 陈炳才
(1.四川大学电子信息学院, 成都 610065; 2.新疆师范大学物理与电子工程学院, 乌鲁木齐 830054; 3.大连理工大学计算机科学与技术学院, 大连 116024)
随着遥感技术的飞速发展,获取大量高分辨率的遥感图像越来越容易,这些高质量的遥感图像在实际生产生活中有着广泛的应用,如精细农业、森林火灾检测、城市规划[1]等。高分辨率遥感图像包含了非常丰富的地物纹理信息和空间语义信息,如何将大量的遥感图像进行准确分类是遥感图像解析的重要研究内容。
遥感图像场景分类方法根据特征提取的层次可分为低层特征处理和中层特征处理两大类方法。低层特征通常采用场景图像的颜色[2]、方向梯度[3]、密度特征[4]、特征点[5]、变换域的纹理[6]等进行描述。这些低层特征不能很好地对中层语义进行描述,难以跨越低层到高层语义的鸿沟,泛化能力差。目前遥感图像分类算法主要集中于中层语义特征建模,如视觉词袋(bag of visual words,BoVW)模型[7]、空间金字塔匹配(spatial pyramid matching,SPM)模型[8]、概率潜在语义分析(probabilistic latent sementic analysis,pLSA)模型[9]等方法,虽然这些方法能一定程度地缩小低层到高层语义的鸿沟,但其对图像深层特征的提取和场景的尺度变化缺乏有效的处理措施,难以在复杂场景分类中取得较高精度。
近年来随着深度学习的快速发展,以卷积神经网络为代表的深度神经网络[10]在图像识别、自然语言处理等领域中取得了较好的结果,也有不少研究人员将其应用到遥感图像场景分类任务中[11]。经典卷积神经网络模型有VGG[12](visual geometry group)、AlexNet[13]、GoogleNet[14]、ResNet[15]等。Tianshun Z[16]等对AlexNet模型进行了改进,将改进后的模型与迁移学习结合进行遥感图像分类实验,在不增加训练时间的同时提升了分类精度。Muhammad[17]等选择预训练的VGGNet作为深度特征提取器,采用典型相关分析对不同层的特征进行融合,该方法在遥感图像场景分类任务中取得了较好的结果。Li等[18]提出了一种自适应多尺度深度融合残差网络,自适应特征融合模块通过学习权值来突出有用信息,有效地抑制了无用信息。王改华等[19]提出了一种基于多分辨率和残差注意力机制相结合的图像分类模型,通过在DenseNet网络稠密块中添加多分辨率因子来控制瓶颈层层数,此外还在模型中引入了残差注意力机制,能有效地从大量信息中筛选出少量重要的信息。张桐等[20]提出了一种深度多分支特征融合网络的方法进行遥感图像场景分类,利用多分支网络结构提取中、高、低三个层次的特征信息,将三个层次的特征进行基于拆分-融合-聚合的分组融合,提升了模型的表征能力。王雨滢[21]等提出一种深度学习和支持向量机相结合的图像分类模型,基于实际图像改进卷积神经网络,并提取训练集的图像特征,通过使用训练集的深度特征来训练支持向量机(support vector machine, SVM)分类器。史文旭[22]等提出了一种基于卷积神经网络(convolutional neural network, CNN)的多尺度方法结合反卷积网络的特征提取算法并对腺癌病理图像进行分类,利用反卷积操作实现不同尺度特征的融合,然后利用Inception结构不同尺度卷积核提取多尺度特征,最后通过Softmax方法对图像进行分类。蓝洁等[23]提出一种基于跨层精简双线性池化的深度卷积神经网络模型,首先根据Tensor Sketch算法计算出多组来自不同卷积层的精简双线性特征向量,然后将归一化后的特征向量级联送至softmax分类器,最后引入成对混淆对交叉熵损失函数进行正则化以优化网络。
正如上述所言,越来越多的深度学习方法被运用到遥感图像分类任务中,这些方法与传统机器学习方法相比有了很大提升,但针对遥感图像空间信息复杂,图像中关键物体小并且尺度变化大等问题,这些方法还不能够对遥感图像信息进行很好的描述。同时随着神经网络的加深,网络变得更加复杂和难以训练,导致分类准确率饱和甚至下降。
针对上述问题,提出一种改进的ResNet50网络模型,在残差块中引入分组卷积和可分离卷积,以减少网络的参数量和计算量,加速模型的收敛。同时在每一个大的卷积组后嵌入多尺度缩聚与激发模块(squeeze and excitation block, SE block),将不同尺度的特征进行融合,提高通道间的依赖性,并以此进行模型训练,以验证本文方法对遥感图像的分类有效性。
1 相关工作
1.1 残差神经网络
随着深度神经网络层数的不断增加,网络的学习能力越来越强,但相对的网络的收敛速度会减慢,梯度在传播过程中会消失,导致无法对前面网络层的权重进行有效调整。传统卷积神经网络,网络中除了第一层外,每一层的输入都来源于上一层的输出,而残差神经网络采用跳跃式结构,使得深度残差网络可以越过中间几层直接将参数传递给后面的层,降低了网络的复杂度,解决了深层次网络的退化问题,促进了网络性能的提升。
残差神经网络的网络结构如图1所示,该网络借鉴了高速网络的跨层连接思想。在图1所示的残差单元结构中,x为网络的输入,H(x)为最优解映射,F(x)代表残差项,直接把输入x传到输出作为初始结果,输出H(x)=F(x)+x,当F(x)=0时,H(x)=x,即恒等于映射。残差神经网络的训练目标就是要使得残差项F(x)=H(x)-x的结果逼近于0。让网络学习F(x)=0相比于更新该网络的参数来学习H(x)=x更简单,该层学习F(x)=0的更新参数能够更快收敛。该种结构的残差网络与没有采用跳跃式结构的网络模型相比,其输入的数据更加清晰,能最大程度的保留数据的准确性。
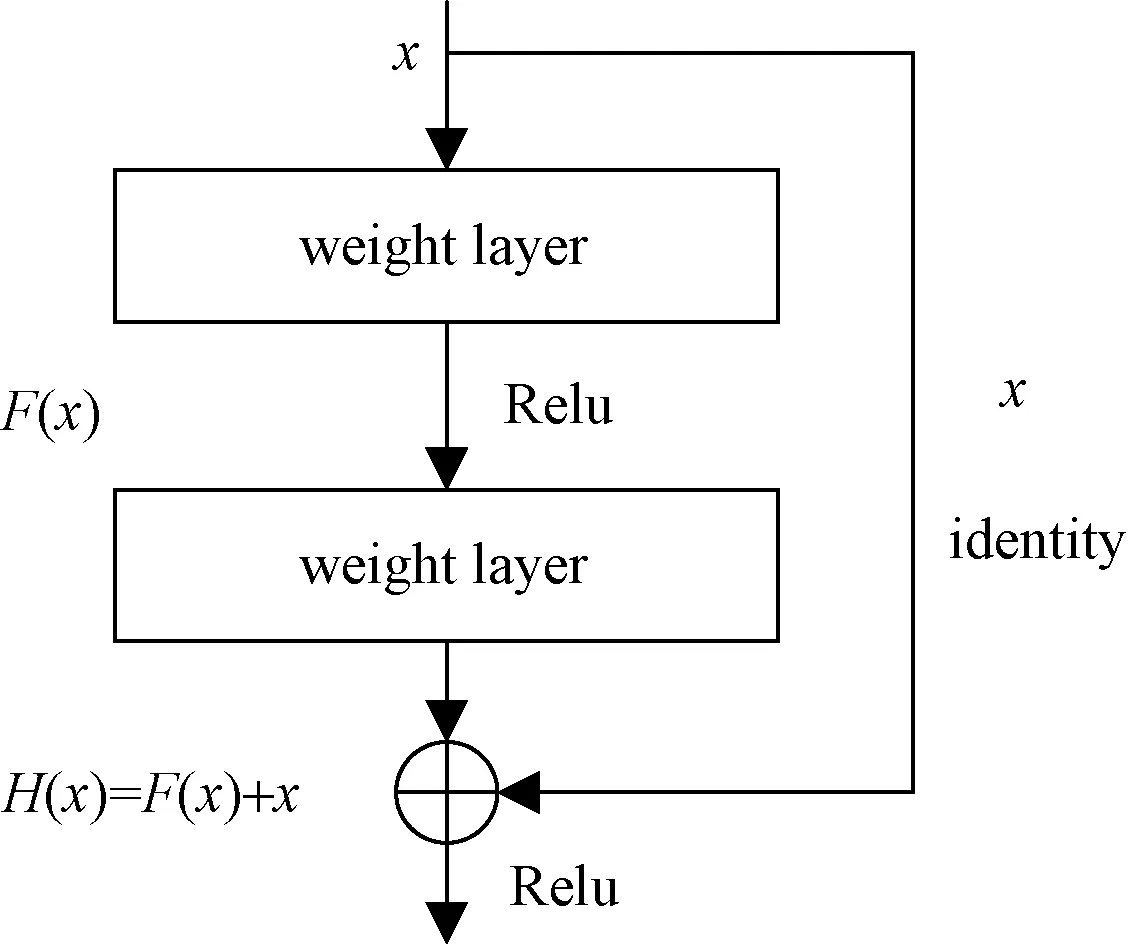
图1 残差网络单元示意图
1.2 分组卷积
分组卷积最早在AlexNet中出现,由于计算资源有限,通常将卷积操作分配给多个图形处理器(graphics processing unit,GPU)分别进行处理,最后将多个GPU的结果进行融合。分组卷积的原理如图2所示,假设输入尺寸为H×W×C,卷积核的个数为N,大小为k×k,将输入特征图分为G个组,在图2中G=2,则每一组的输入特征图数量为C/G,每组的卷积核个数为N/G,每组卷积核只与其所对应组的输入进行卷积。

图2 分组卷积
对于普通卷积来说,卷积核的总参数量为
p1=k×k×N×C
(1)
分组卷积所对应的卷积核参数总量为
p2=k×k×(N/G)×(C/G)×G
(2)
从计算结果可以看出,经过分组卷积可将总参数量降为原来的1/G,其用少量的参数量和计算量就能产生大量的特征图。
1.3 深度可分离卷积
深度可分离卷积分为深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)两个过程,在进行卷积操作时将通道和空间区域分开考虑,对于不同的输入通道采取不同的卷积核进行卷积。深度卷积过程如图3所示,假设输入大小为H×W×C,C为通道数,在图3中C=3。假设卷积核个数为m,大小为k×k×1。则在深度卷积中,将输入分为了C组,每一组做k×k×1的卷积,每一个卷积核只提取其所在通道的空间特征。
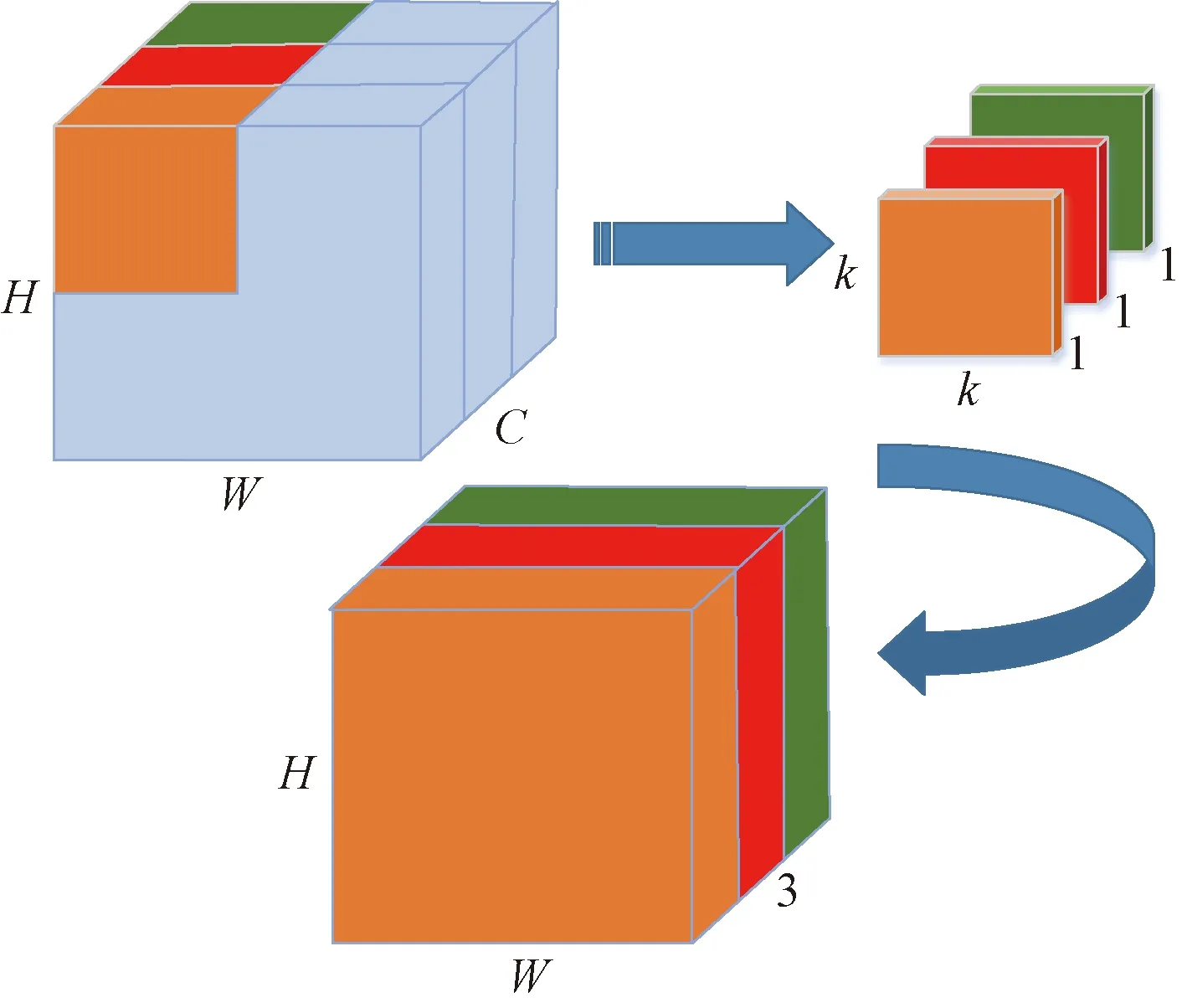
图3 深度卷积
逐点卷积的原理如图4所示,其将经过逐通道卷积后的特征做m个普通的1×1卷积,经过逐通道卷积核逐点卷积后的输出为H×W×m。
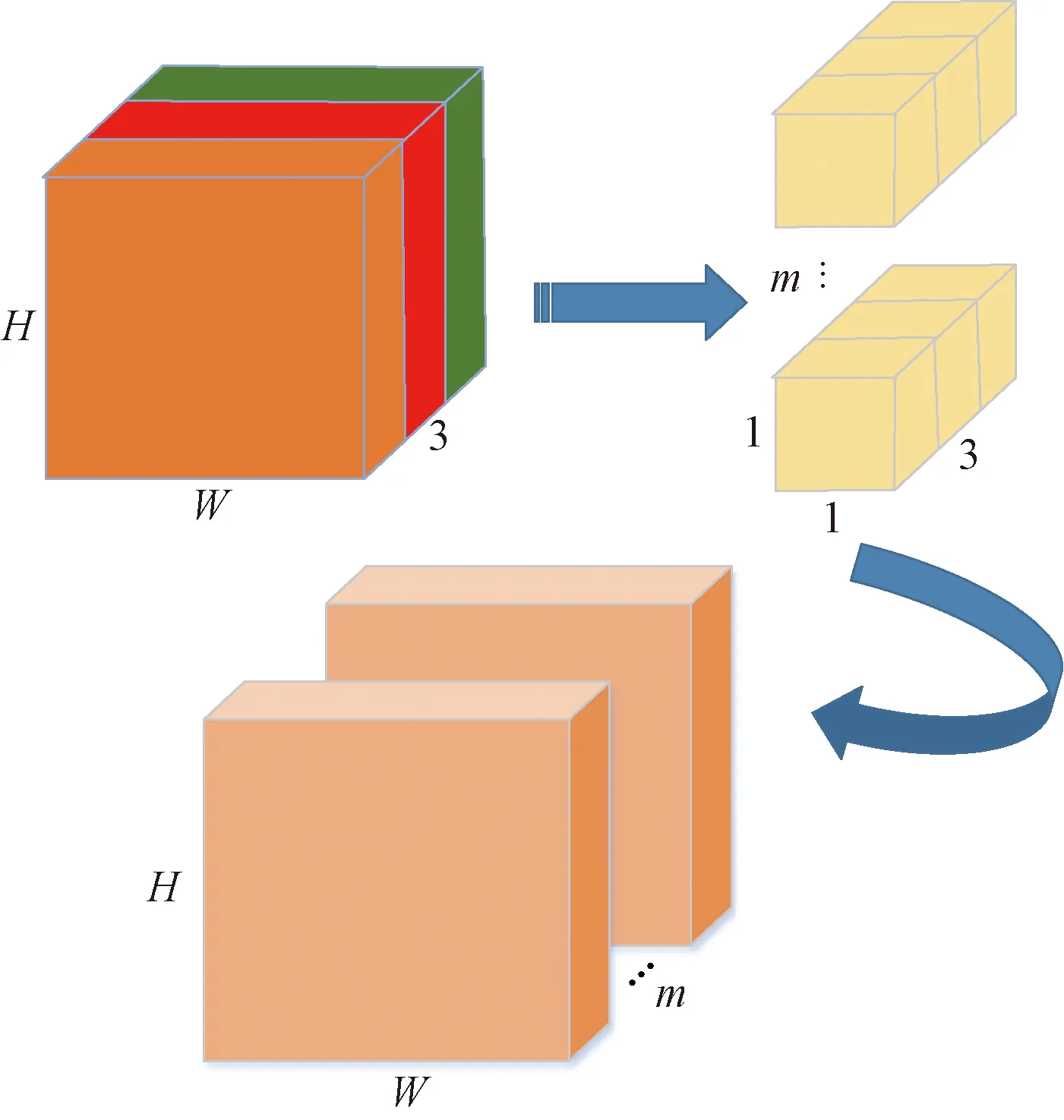
图4 逐点卷积
对于普通卷积来说,在相同参数设置的情况下输出为H×W×C,其计算量为
p=H×W×C×m×k×k
(3)
深度卷积的计算量为
p1=H×W×C×k×k
(4)
逐点卷积的计算量为
p2=H×W×C×m
(5)
则深度可分离卷积相当于将普通卷积的计算量压缩为

(6)
从上述计算结果可以看出,深度可分离卷积相比于普通卷积,在深度一样的情况下大大减少了模型的计算量。
1.4 SENet网络结构
SENet(squeeze and excitation networks)是一种轻量级的网络结构,它通过对特征通道间的依赖关系进行建模来获取每个特征通道的重要程度,然后依照这个重要程度提升有用的特征通道并抑制对当前任务不重要的特征。SENet对输入特征进行Squeeze和Excitation两个重要的操作,通过Squeeze操作对输入的每个通道进行全局平均池化得到通道描述子,Excitation操作利用两层全连层为每个通道生成权重,最后将Excitation的输出权重与先前特征进行重新加权,完成在通道维度上对原始特征的校准。
2 网络结构设计
2.1 改进残差神经单元
残差神经网络由多个bottleneck block残差块和convolution block残差块堆叠构成。bottleneck残差块的主路径包含三个卷积层,第一部分1×1的卷积核用于减少特征通道的数量;第二部分3×3的卷积核用于进行特征的提取,同时减少了参数的数量;第三部分的1×1卷积核可以保证输出通道数等于输入通道数,在保证数据可靠性的同时增加了网络的深度,可以对数据进行充分的提取,进而提高模型的性能。同时残差块中引入了BN(batch normalization)算法,加快了网络的收敛。convlution残差块结构与bottleneck残差块结构相似,区别之处在于其分支上增加了一个1×1的卷积层,用于调整输入特征的尺寸。
对残差神经单元进行了改进,改进后的bottleneck block和convolution block结构分别如图5、图6所示。

图5 改进后bottleneck block结构(SGBB)

图6 改进后convolution block结构(SGCB)
bottleneck block中第一部分和第二部分的普通卷积替换为深度可分离卷积,第三部分普通卷积替换为分组数为2的分组卷积。convolution block中的第一部分保持不变,第二部分卷积采用深度可分离卷积,第三部分卷积采用分组数为2的分组卷积,分支上的卷积保持不变。改进后的残差块大大减少了整个网络的参数量和计算量,加快了网络的收敛,在通道数不变的情况下加强了模型的特征提取能力。
2.2 多尺度SE block
在常规SE block中的全局平均池化前先对输入分别做1×1和3×3的卷积,将两组卷积结果相连接,再进行Squeeze和Excitation操作。其结构如图7所示。多尺度SE block有效地将不同尺度的特征进行融合, 通过全连层和非线性激活层得到多尺度特征图的权重,然后将学习得到的权重与输入特征图相乘,通过对通道特征的重校准提升了有效特征的权重,增强了网络的特征表达能力,使得遥感图像场景分类精度得到提升。

图7 多尺度SE block(MSEB)
2.3 改进ResNet50网络结构
采用ResNet50作为基础模型,其bottleneck block和convolution block分别使用上文所对应的改进结构,即SGBB和SGCB,本文中对网络的层数进行了调整,在conv3_x和conv4_x上分别去掉了1个和3个bottleneck block残差块,由于分组卷积和深度可分离卷积的引入,大大减少了网络的参数量和计算量,有利于加快模型的收敛。同时在每一个大的卷积组后嵌入多尺度SE模块(MSEB),自动获取每个遥感图像特征通道的重要程度,有效增强有用特征,抑制用处不大的特征,进一步提升了网络的性能和泛化能力。改进后的网络结构如图8所示。

图8 本文网络结构
3 实验与分析
3.1 实验数据集
实验数据集1为航空图像数据集(aerial image dataset, AID[24]),该数据集由华中科技大学与武汉大学联合制作并于2017年发布,其中包含机场、森林、学校等30类遥感场景图像,每类遥感图像的样本数量为200~420张不等,尺寸均为600×600像素,该数据集共计10 000张图像。各类图像部分示例如图9所示。

图9 AID数据集部分场景图像
实验数据集2为UCMerced_Land Use(UCMLU)[25]数据集,选自美国地质调查局国家城市地图航空遥感图像,包含建筑、飞机、棒球场、海滩等21类遥感场景图像,每类包含100张大小为256×256像素的图像,该数据集共计2 100副图像,空间分辨率为0.3 m,各类图像部分示例如图10所示。

图10 UCMLU数据集部分场景图像
在以上两个数据集中,分别从每类遥感场景图像中随机选取80%的图像作为训练数据集,剩余20%的图像作为测试数据集。同时为了达到更好的测试效果,对两个数据集都采用在线数据增强的方式进行数据集扩充,增强方式包括随机旋转、随机缩放、随机裁剪、垂直变换等操作,并将所有图像尺寸统一为256×256像素大小。
3.2 实验环境及参数设置
本文中采用Adam优化器对模型进行优化训练,初始学习率设置为0.001,当测试集的损失值持续5个epoch不再下降时,将学习率调整为原来的0.1倍,学习率的最小值设置为0.000 01。更小的batch_size有助于增强模型的泛化能力,将batch_size设置为20,网络一共经过100个epoch进行充分训练,损失函数采用交叉熵。
本文中实验的环境为:Windows10操作系统,2.90 GHz Intel(R) Core(TM) i7-10700 CPU,内存为16 GB,GPU使用NVIDIA GeForce RTX 2070,显存为8 GB。神经网络训练使用keras框架。
3.3 评价标准
本文中采用总体分类精度(overall accuracy)、混淆矩阵(confusion matrix)和每秒浮点运算次数(floating-point operations per second,FLOPS)这三种评价指标对所提出方法的分类性能进行分析评估。总体分类精度指被正确分类的样本个数占总样本数的比值,能够很好地表征分类精度。混淆矩阵能更直观地展现每一类场景图像的分类准确率以及该类被错分为其他类的情况。计算量指浮点运算数,可以用来衡量模型的复杂度,精度越高,计算量越小,则网络的性能越好。本文中所有分类准确率值均为5次独立重复实验结果的平均值。
3.4 实验结果分析
3.4.1 网络分组数对比实验
为了更合理地选择分组卷积的分组数,本文将网络分组数分别设置为2、4、8组进行对比实验,在AID和UCMLU两个数据集上的实验结果分别如表1所示。
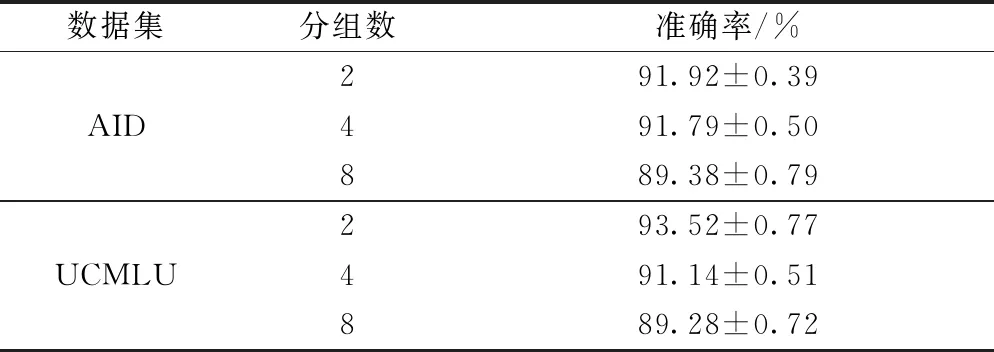
表1 分组数对AID、UCMLU数据集分类精度的影响
从实验结果可以看出,分组数为2相比分组数为4和8在两个数据集上都能取得更高的分类精度,因此本文中将分组数设置为2。
3.4.2 AID数据集结果分析
为了分析本文改进残差神经单元和引入多尺度SE block对分类精度的影响,分别对传统CNN(ResNet50)、在残差结构引入分组卷积和可分离卷积的方法(SG_ResNet50)以及在SG_ResNet50基础上嵌入多尺度SE block的方法在AID数据集上进行了实验。三种方法平均分类精度随迭代次数的变化关系如图11所示。从图11中可以看出,使用未做任何改进的ResNet50做全训练的分类精度最低;对残差单元结构进行改进后,由于引进了分组卷积和可分离卷积,减少了网络的参数和计算量,改进后的模型SG_ResNet50比ResNet50准确率增长速度更快,模型更快收敛,并且分类准确率达到了90.42%,高于ResNet50准确率1.88%;最后在SG_ResNet50的基础上嵌入多尺度SE block,分类精度有了进一步提升,达到了91.92%,说明多尺度SE block的引入有效地提升了模型性能。
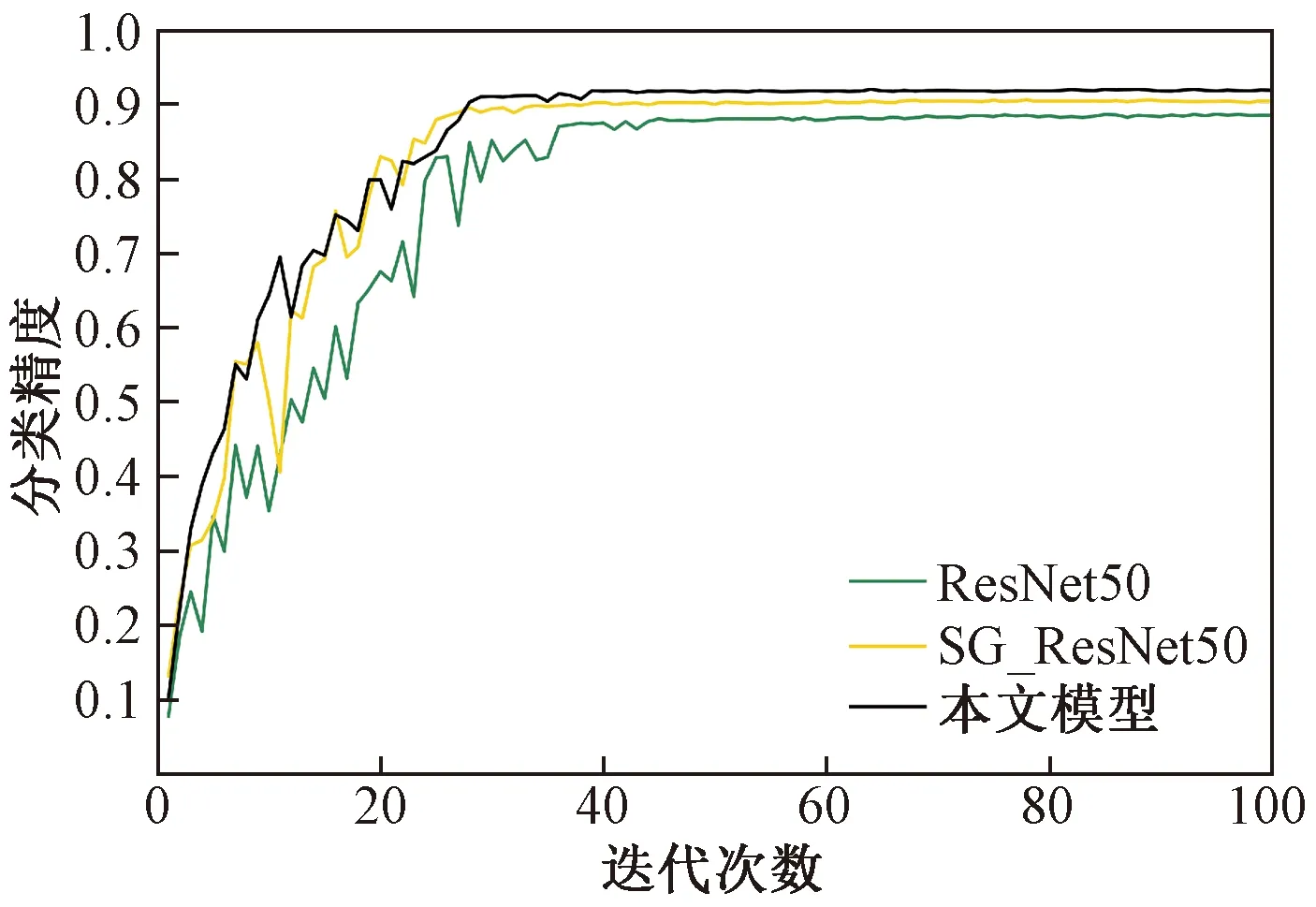
图11 ResNet50、SG_ResNet50、本文模型分类精度对比
表2中给出了ResNet50、SG_ResNet50、SG_ResNet50_SE和本文模型四种网络结构的性能对比,从结果可以看出,SG_ResNet50相比于ResNet50的计算量降低了60%,平均精度提升了1.88%,表明在残差结构中引入分组卷积和深度可分离卷积大大降低了网络的计算量,同时分类准确率有了较大的提升。在SG_ResNet50的基础上引入多尺度SE block,在计算量几乎不变的情况下分类精度有了进一步提升(提升了1.5%)。同时本文模型的平均精度比SG_ResNet50_SE提高了0.6%,表明引入多尺度SE的模型效果优于标准SE模型。
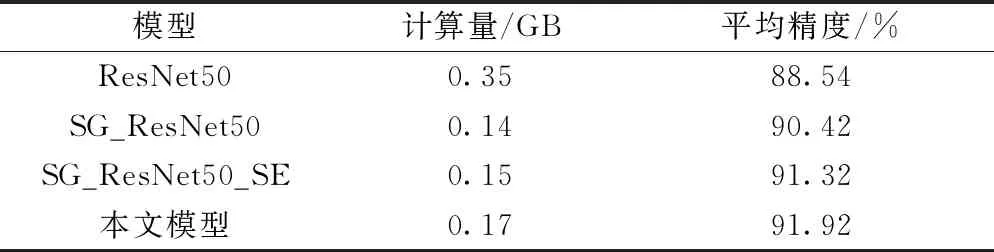
表2 AID数据集上不同模型性能对比
在测试集上进行5次独立重复试验平均分类准确率的混淆矩阵如图12所示,总体平均分类准确率为91.92%。由图12可以看出,30类场景图像中有22类的分类精度均高于90%,说明本文提出的方法对复杂场景图像具有较好的分类性能。同时从实验结果可以看出学校和广场的分类精度最低,分别只有78%和67%,其中学校容易被划分为工业区和密集住宅区,广场容易被划分为中心区域和公园,说明本文所提出的方法对存在二义性的场景图像分类性能还有待进一步提高。
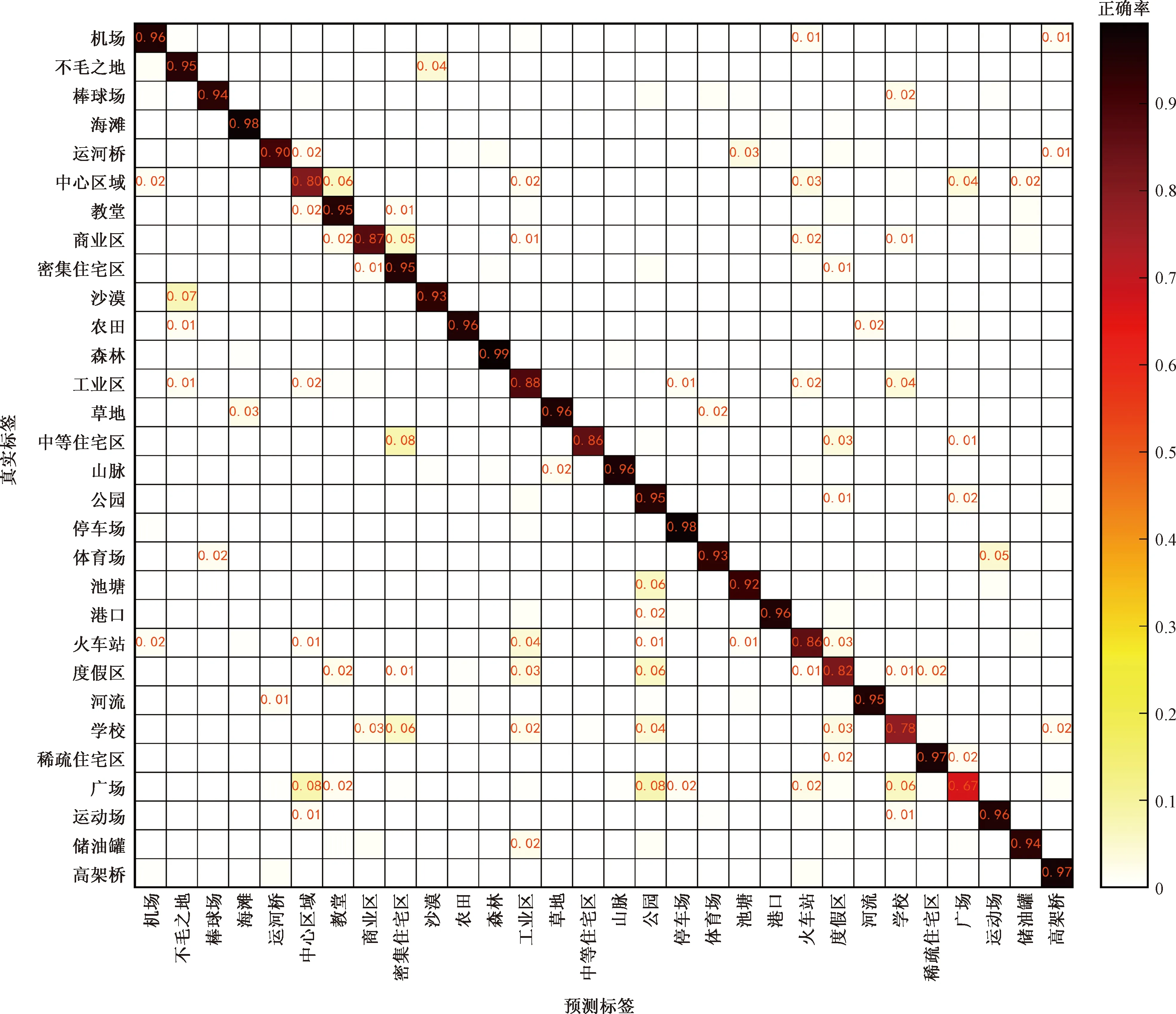
图12 AID场景分类混淆矩阵
为了验证本文方法的优势,将本文方法在AID数据集上的分类精度与近几年具有代表性的几种方法进行对比,各方法的分类精度如表3所示。由表3可以看出,文提出方法的分类精度相比于中层特征提取方法BoVW(SIFT)提升了23.55%,相对于以深度卷积神经网络为特征提取框架的VGG-VD-16和GoogLeNet,分类精度分别提升了2.28%和5.53%。同时与未做任何改进的ResNet50相比提升了3.38%,证明本文所提出的模型在遥感图像场景分类中有一定优越性。
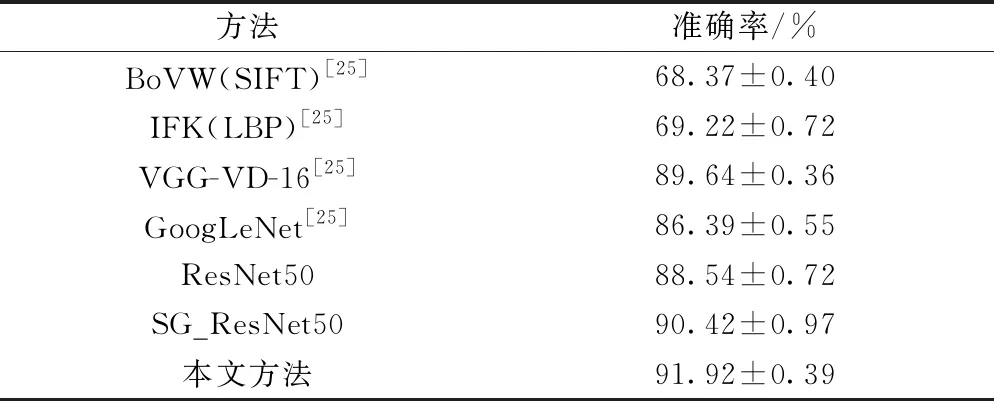
表3 AID数据集上不同方法的平均分类准确率
3.4.3 UCM数据集结果分析
为了进一步验证本文提出模型的有效性,在UCMLU数据集上进行了实验,21类场景图像分类结果如图13所示,总体平均分类精度达到了93.52%。由图13可以看图,大部分场景图像类别分类准确率在90%以上,其中农业、棒球场、海滩等九类场景图像的分类准确率达到了100%,可见该方法对纹理差异较小的场景类别分类准确率较高。
为了更加直观地分析每一类场景图像的分类效果,图14给出了每一类场景分类准确率柱状图。从图14中可以看出仍有部分类别场景图像分类准确率较低,如高速公路和立交桥,其分类准确率分别只有78%和84%。结合图13的混淆矩阵分析可知,高速公路分类准确率较低是因为其和十字路口以及立交桥的场景十分相似,易造成误分。此外,中等密度住宅区与密集住宅区地物信息高度相似,造成部分中等密集住宅区被错分为密集住宅区。
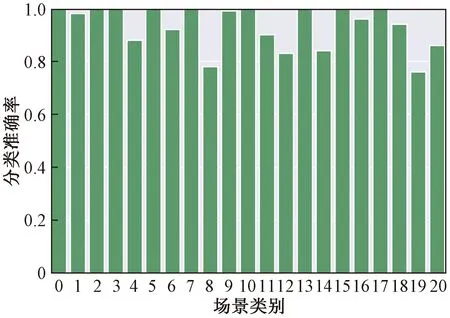
图14 UCMLU每类场景图像准确率柱状图
UCMLU数据集上不同模型的性能对比如表4所示,可以看出本文提出的模型相比于未做任何改进的残差网络大大降低了网络的计算量,同时拥有更高的分类准确率,体现了其强大的特征提取能力。

表4 UCMLU数据集上不同模型性能对比
表5列出了本文提出方法在UCMLU数据集上的分类精度与一些现有方法的对比结果,由表5可以看出,传统的低中层特征提取方法如视觉词袋(bag of visual word,BOVW)的分类精度最低,而卷积神经网络由于其强大的特征提取和学习能力,使用其进行场景图像分类相比于传统方法有进一步提升。而本文提出的改进残差网络模型与以下几种较为流行的方法相比得到了最高分类精度(93.52%),相对于直接使用ResNet50进行分类训练,本文方法的分类精度提升了10.24%。
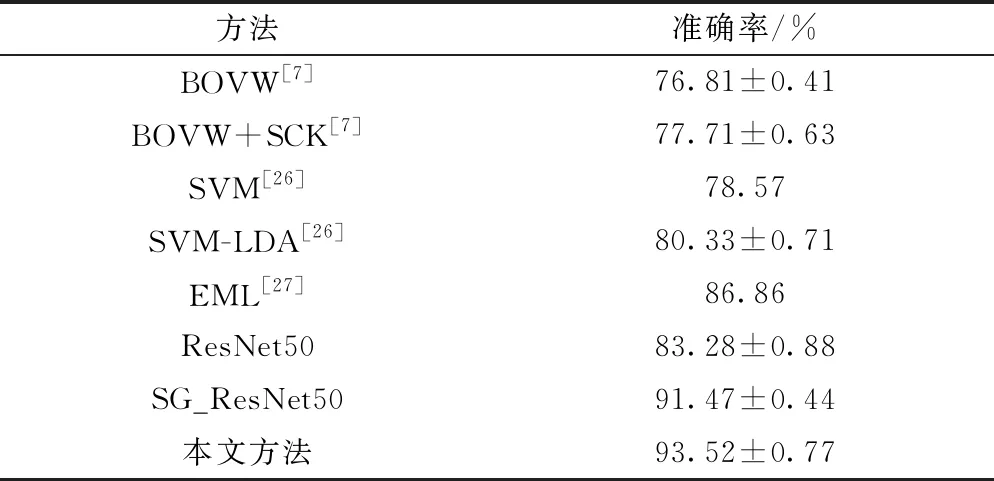
表5 UCMLU数据集上不同方法的平均分类准确率
4 结论
针对遥感场景图像空间信息复杂、图像中关键物体小并且尺度变化大等问题,提出一种改进残差网络的场景图像分类方法。该方法以残差神经网络ResNet50为基础框架,在残差单元中引入分组卷积和可分离卷积,有效减少了网络的参数量和计算量。同时引入多尺度SE block模块,通过对多尺度特征的校准提升了有效特征的权重,进一步提升了模型的性能。在AID和UCMerced_Land Use两个数据集上的分类精度分别达到了91.92%和93.52%,相比于常规的残差网络ResNet50分别提升了3.38%和10.24%,证明本文方法在遥感场景图像分类上的可行性和有效性。但本文方法对地物信息及其相似的场景类别分类效果一般,如何对模型进行改进以适应场景信息更丰富、规模更大的数据集是下一步研究方向。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
