
基于密度的轮廓控制参数识别方法研究
2021-11-23 08:39秦幸幸
工业工程 2021年5期
张 阳,秦幸幸
(天津商业大学 1.管理学院;2.管理创新与评价研究中心,天津 300134)
在统计过程控制中,产品或过程的质量特性可以通过某种函数关系来描述,这种函数关系被称为轮廓(profile)[1]。轮廓控制(profile monitoring)即基于统计过程控制理论对质量特性表现为轮廓的产品或过程质量进行监控,通常包括两个阶段。第1阶段基于历史轮廓数据分析来判断过程的稳定状况,并识别受控轮廓集和确定轮廓控制的参数,可称为轮廓控制参数识别阶段;第2阶段则基于所确定的控制参数,建立控制图,实施过程监控,称为轮廓控制监控阶段。轮廓控制参数识别的关键在于受控轮廓集的识别,它是确定轮廓控制参数的基础。因此,本文将研究重点聚焦于受控轮廓集的识别。传统的轮廓控制参数识别方法大多假设轮廓内测量数据之间相互独立[2-3]。然而,在实际情况中,因连续测量时间短、数据量大等原因,会使轮廓内测量点间存在相关关系。此外,实际生产加工过程中存在的系统性误差,也会导致轮廓内测量数据存在相关性[4-7]。因此,忽略轮廓内部相关性的轮廓控制方法已不再适用。
线性混合模型通常用来对内部存在相关性的轮廓进行建模[8-9],并在此基础上构建轮廓控制参数识别方法[10-13]。该类方法首先采用线性混合模型进行轮廓建模,并估计样本轮廓参数。然后,基于轮廓参数建立T2控制图,用于识别受控轮廓集,进而确定轮廓控制参数。构建T2控制图时,可采用连续差分估计量(SDE)[8]、最佳线性无偏估计量(eblups)[10]和基于最小体积椭球(MVE)的估计[11-12]等方法估计T2统计量的方差−协方差矩阵。然而,基于上述方法的T2控制方法是基于全部样本轮廓数据来估计方差−协方差矩阵,进而确定控制限。这将会使得T2控制图的识别性能因异常轮廓的存在而降低,尤其是基于最佳线性无偏估计量的方法受到的影响极大。
为降低因样本轮廓中存在异常轮廓所带来的影响,Chen等[13]提出基于层次聚类(cluster based,CB)算法的受控轮廓识别方法,并在此基础上建立T2控制图,一定程度上降低异常轮廓的影响,且与其他方法相比基于层次聚类的T2控制图的性能更好。然而,此方法需要首先选定一半以上的样本轮廓作为初始受控轮廓,但其中往往会存在较多异常轮廓。由于聚类结果依赖于距离度量的选取,异常轮廓的存在,尤其是较少离群值的存在,会影响最终聚类结果,进而影响最终确定的受控轮廓集。这会使得基于层次聚类算法的T2控制图识别性能会降低。综上所述,降低离群值和异常轮廓对轮廓控制参数识别阶段的影响,是构建稳健轮廓控制参数识别方法的重点和难点。
为了更准确地从样本轮廓数据中识别出受控轮廓集,本文提出基于密度(density based,DB)的轮廓控制参数识别方法。基于密度的算法能够有效地克服层次聚类算法的缺陷,为构建稳健的T2控制图提供保证。所提方法使用样本轮廓参数向量计算样本轮廓的密度;再基于样本轮廓的密度确定一部分初始受控轮廓,排除异常轮廓,尤其是离群值的干扰;随后经过多次迭代获得最终受控轮廓集;在此基础上采用参数均值方法确定轮廓控制参数。基于密度的轮廓控制参数识别方法得到的轮廓控制参数,可用于构建轮廓控制图。
1 模型假设
在生产加工过程中,假定已获取m条样本轮廓数据,且第i条样本轮廓的观测数据为(xit,yit) ,i=1,2, ···,m;t=1, 2, ···,n。本文假设在不同轮廓中测量点位置固定,即当t不变时,xit=xt。基于Jensen等[8]所使用的线性混合模型,建立轮廓模型为

其中,Yi=(yi1,yi2, ···,yin)T为 轮廓测量值;Xi是n×o阶向量,表示与固定效应相关的回归变量,o为回归变量数目; β为o×1阶向量,表示轮廓固定效应参数,且在不同的轮廓中 β不 变;Zi为n×s阶矩阵;bi为s×1阶向量,表示轮廓随机效应参数,且bi服从均值为0、协方差矩阵为G的多元正态分布 (MN),记为bi~ MN(0,G),G为s×s阶 矩阵; εi为随机误差,且εi~MN(0,Ri),Ri为n×n阶矩阵[14]。
Ruppert等[15]给出模型(1)的矩阵表达式为


在实际情况中,V在一般情况下是未知的,常用最大似然估计或最小二乘法来得到B和R[15],从而得出V。在3.1节仿真设置中,假设V已知。
基于式(3)和(4)可估计轮廓参数向量为

其中,bˆi为 矩阵bˆ中的第i行元素所组成的向量。
2 基于密度的参数识别方法
2.1 密度概念
本文将数据向量密度定义为以空间内某个数据向量为中心的最小半径的倒数,且此最小半径需包含周围P个数据向量[16]。其中,P表示密度参数,可根据具体情况来确定。不难看出,根据密度大小可以确定该数据向量是离群点的可能性。如果某个数据向量的密度越小,其离周围P个数据向量的最大距离就越大,则该数据向量为离群点的可能性就越大。具体来讲,假设空间内有一组数据向量集Uω={γ1, γ2, ···, γω}, 其中,γl=(γ1l, γ2l, ···, γφl),l=1,2, ···, ω , 为 φ维向量。对于任意数据向量,分别计算γl与其最近的P个数据向量的距离Dp,l={d1,l,d2,l, ···,dp,l}。 则数据向量γl的 密度ρl=1/Dmax,l,其中,Dmax,l=max{d1,l,d2,l, ···,dp,l}。数据向量密度的矩阵式算法如下。

2.2 基于密度的轮廓控制参数识别方法
基于密度的轮廓控制参数识别方法包括建立轮廓模型、确定初始受控轮廓集、识别受控轮廓集和确定轮廓控制参数等4个阶段。其中,初始受控轮廓确定阶段是整个轮廓控制参数识别方法的重点,是根据轮廓模型参数向量的密度来选定初始受控轮廓。与基于层次聚类的方法相比,基于密度的方法在确定初始受控轮廓时可以事先排除离群轮廓。因此,基于密度的方法可以有效降低离群轮廓对控制参数识别的影响。基于密度的轮廓控制参数识别流程如图1所示,具体步骤如下。
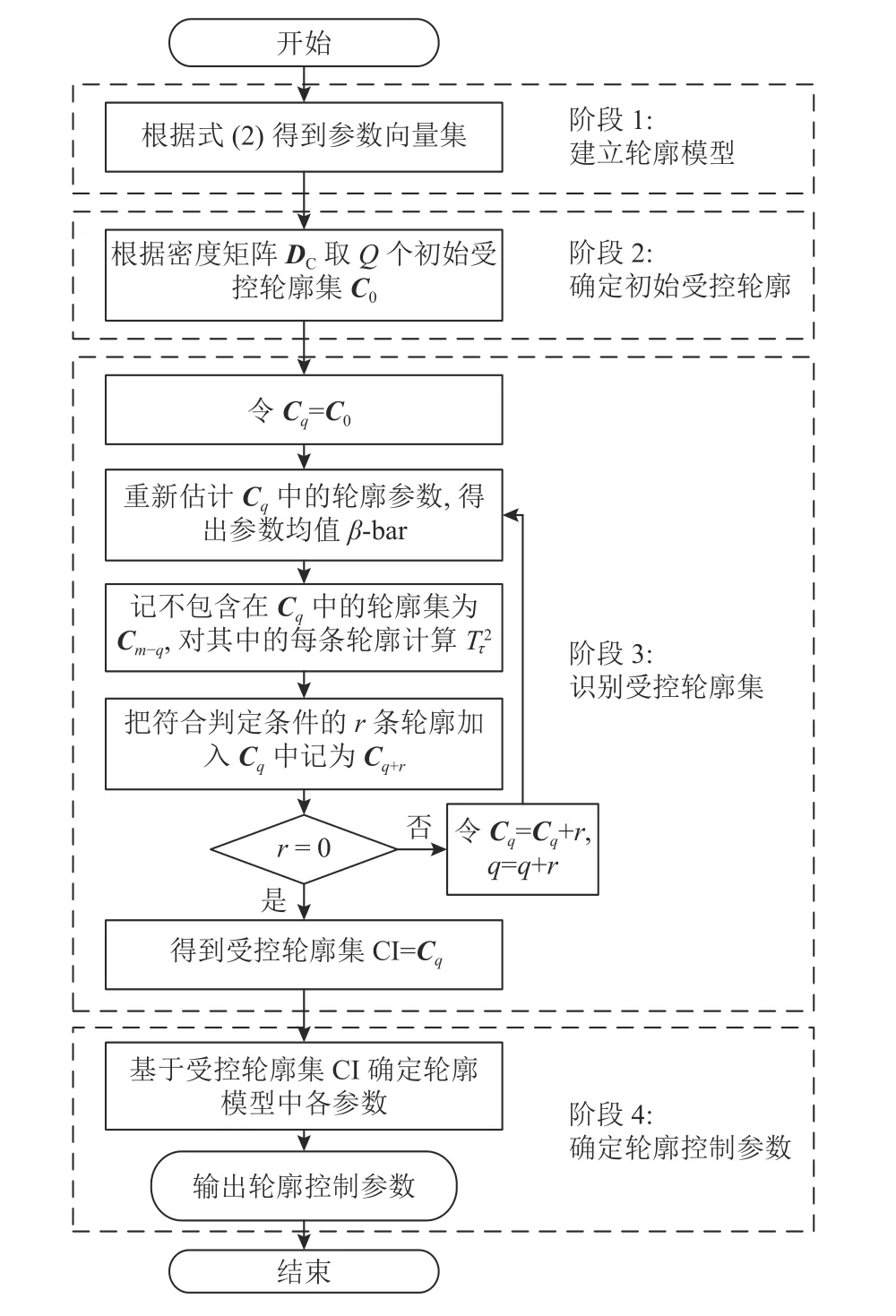
图1 基于密度的轮廓参数识别流程图Figure 1 The flow chart of profile parameters identification method based on data-density
阶段1 建立轮廓模型。
基于式(2)对m条样本轮廓建模,然后可得到轮廓参数向量的估计 βˆi。记C={βˆ1, βˆ2, ···, βˆm},表示所有样本轮廓集合。
阶段2 确定初始受控轮廓集。
本阶段将采用轮廓密度来选定初始受控轮廓。首先,基于2.1节中密度的矩阵式算法,计算并获得参数向量集C的密度矩阵DC。 之后,选取DC中第P列的m个元素,并将其按照从大到小的顺序排列。最后,选取元素排列中前Q个元素所对应的轮廓作为初始受控轮廓集C0。此处,参数Q和P的取值影响所提基于密度的轮廓控制参数识别的性能。参数Q和P设置对所提方法的影响将在仿真分析部分讨论。
阶段3 受控轮廓集识别。
1) 设定受控轮廓集为Cq,并先设定其初始值为初始受控轮廓集,即Cq=C0。
2) 基于Cq中Q条轮廓数据,利用式(3) ~ (5)更新Cq中每个轮廓的参数,并计算均值 β¯。 记Cm−q=C−Cq为不包含在Cq中 的轮廓集,并计算其中第 τ个轮廓的T2统计量为

4)如果r= 0,那么Cq则为基于密度方法得到的最终受控轮廓集 CI, 且 CI=Cq。此时可以终止程序。如果r≠ 0,则令q=q+r,Cq=Cq+r,并返至2),继续受控轮廓集的识别。
阶段4 确定轮廓控制参数。
利用所确定的受控轮廓集 CI,根据线性混合模型使用极大似然估计或最小二乘法,重新估计每条轮廓的参数,并求轮廓参数的均值,即可得轮廓控制参数。
3 仿真分析
轮廓控制参数识别方法的关键是正确地识别出受控轮廓集。仿真分析主要通过蒙特卡洛模拟来分析正确识别受控轮廓集的能力,并与已有方法进行比较分析。
3.1 仿真设置

3.2 识别性能指标确定
轮廓控制参数识别方法正确识别受控轮廓集的能力,可以通过分类精度、敏感性和特异性等性能指标来分析。基于表1的混淆矩阵可根据表2的公式来计算分类精度、敏感性和特异性等性能指标[18]。其中,a为表示正确识别异常轮廓的数目;e为把异常轮廓识别为受控轮廓的数目;f为把受控轮廓识别为异常轮廓的数目;h为正确识别受控轮廓的数目。容易得知,分类精度、敏感性和特异性的取值范围均为 [ 0, 1]。而且,当这些指标的值越大时,则表明所提方法正确识别受控轮廓集的能力越好。

表1 混淆矩阵Table 1 Confusion matrix
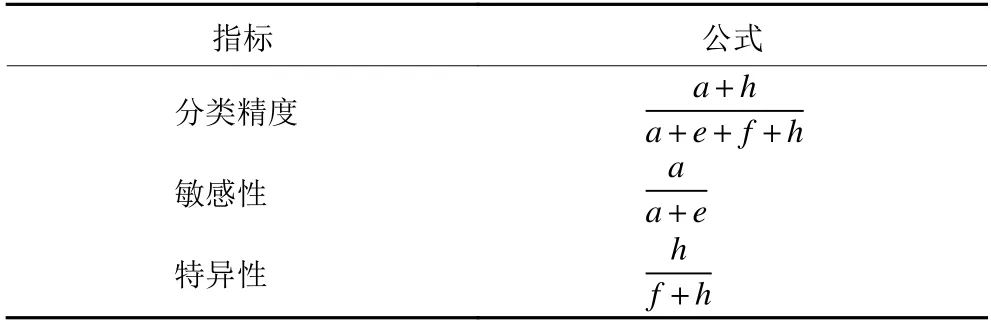
表2 性能指标公式Table 2 Performance index formula
然而,特异性和敏感性呈现的负相关关系,即敏感性取值变大(小)时特异性取值则变小(大),会为同时采用敏感性和特异性比较不同方法性能时带来一定困难。因此,为方便比较,可综合考虑敏感性和特异性指标,采用约登指数(Youden index)[19-22]来分析受控轮廓集正确识别的能力,其定义为

同样,约登指数取值范围也为 [ 0, 1],且取值越大时识别性能越好。本文将基于分类精度和约登指数2个指标来分析参数取值和置信水平的影响。
3.3 参数P和Q的影响分析
在分析参数P和Q对识别性能的影响时,基于3.1节中轮廓模型,首先通过多次蒙特卡洛模拟仿真初步分析参数P和Q的取值及其对应性能指标取值。根据初步分析结果得知,当P和Q的值介于区间[[m/3]+1, [m/2]+1]中时,性能指标相对较好。因此,为进一步分析所提方法的识别性能,将针对不同偏移量进行以下4种组合试验,即
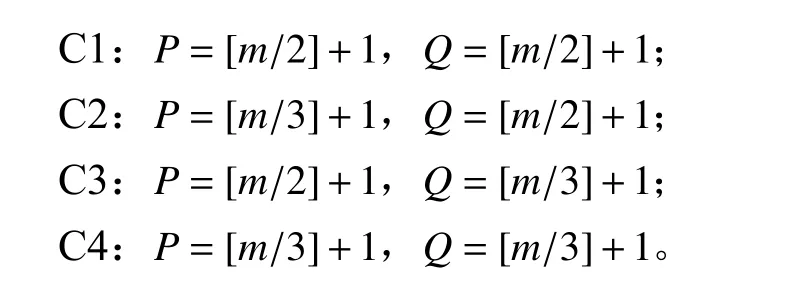
在蒙特卡洛仿真分析中,不同偏移量下各组合模拟仿真次数均为5 000次,其中,α设定为0.025。最终仿真结果如表3所示,其中加粗结果为特定偏移量下不同参数组合中分类精度和约登指数的最优结果。
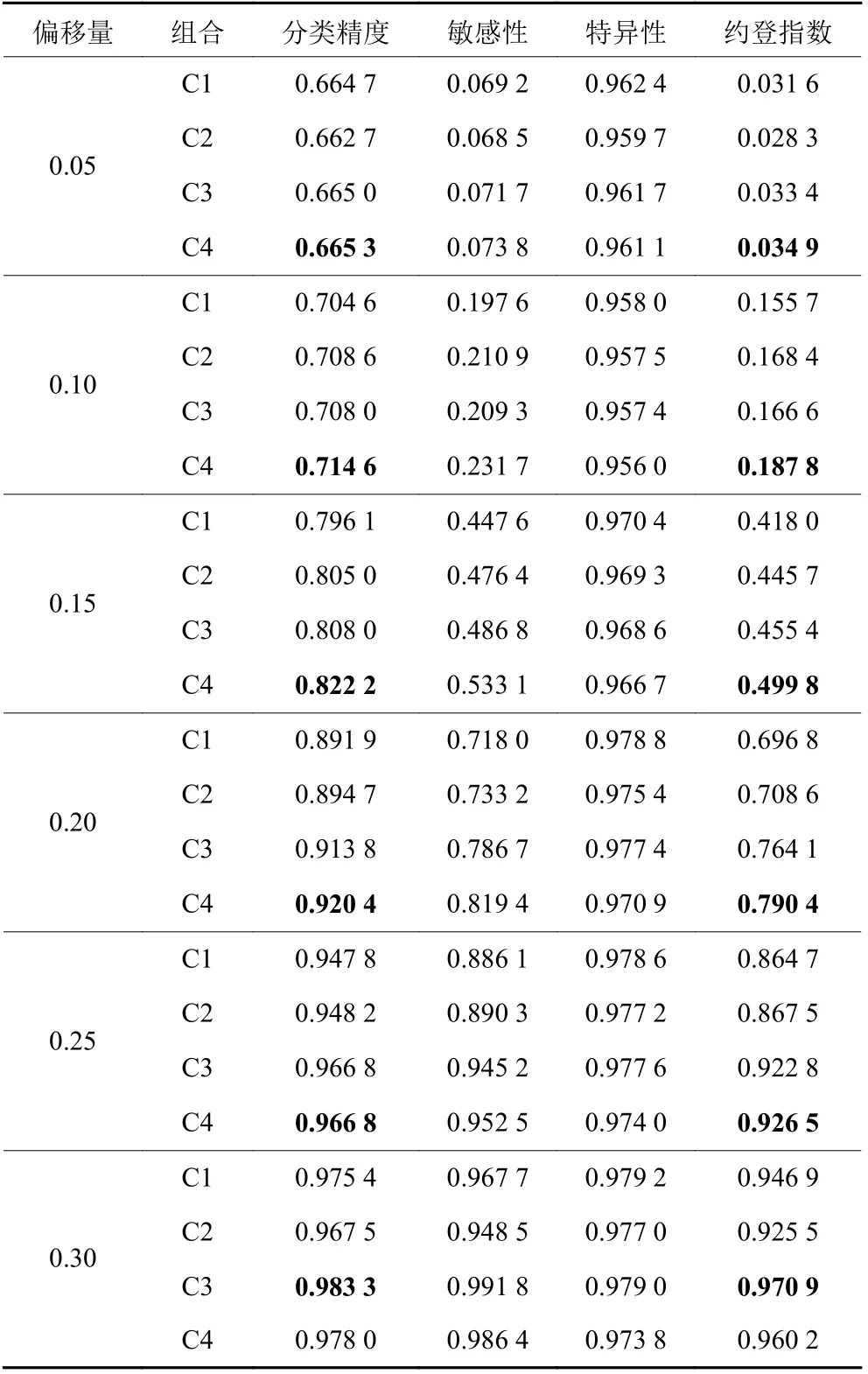
表3 不同参数组合下识别性能比较Table 3 Performance comparisons on different combinations of parameters P and Q
由表3可知,当P一定时,对于任意偏移量,采用较小的Q值可获得分类精度和约登指数的较优结果。另外,当Q一定时,对于小于等于0.25的偏移量,P较小时分类精度和约登指数结果较优;而对于偏移量大于0.25的情况,P较大时可获得较好的性能。此外,对于特定参数组合,随着偏移量的不断增加,分类精度和约登指数也在逐步变大;而且当偏移量大于等于0.25时,分类精度和约登指数的取值大都超过0.95,并接近于1。
通过比较参数P和Q的不同组合下分类精度和约登指数的值,可以发现,无论P取何值,当Q=[m/3]+1时总能获得最优识别性能。因此,在实际应用中,可以设定参数Q为 [m/3]+1,然后再根据偏移量大小设定参数P的取值。具体而言,当偏移量为中小偏移时,设定P=[m/3]+1且Q=[m/3]+1;当偏移量为大偏移时,设定P=[m/3]+1且Q=[m/3]+1。
然而,上述参数P和Q的设定需要假设偏移量根据以往经验预先已知。当偏移量未知时,建议选取参数组合C4,即设定参数P和Q分别为 [m/3]+1和[m/3]+1。因为,虽然对于大偏移的情况,组合C4下分类精度和约登指数的取值比组合C3下较低,但是也超过0.95,并逐渐接近于1。
3.4 置信水平α的影响分析
基于前述分析结果,本节将在参数P和Q分别取[m/3]+1和 [m/3]+1的情况下研究置信水平α对所提方法性能的影响。在不同α取值下,分类精度和约登指数随偏移变化情况如图2(a)和(b)所示。
由图2可知,对于偏移量为中小偏移的情况,α= 0.05时,分类精度和约登指数均能最优,除了分类精度在偏移量为0.05时取值最小之外。而当偏移量较大时,α= 0.01时性能较优。因此,若偏移量已知时,可以为中小偏移给定相对较大的α值,此时识别准确性不高,较大的α值能够有效控制第2类错误的发生;而对于较大偏移,可以设定相对较小的α值,来降低识别准确性很高时容易发生的第1类错误概率。
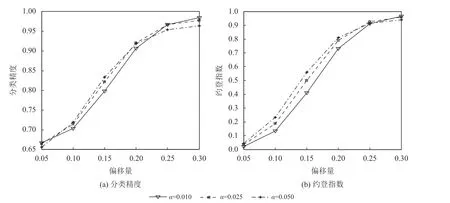
图2 偏移量对分类精度和约登指数的影Figure 2 The effect of offset on classification accuracy and Yoden index
然而,当实际应用中偏移量未知时,建议α设定为0.05。尽管较大的α值会削弱偏移量较大时所提方法的识别性能,但是偏移量较大时分类精度和约登指数都非常接近于1,也能得到良好的分类效果。
3.5 性能比较研究
本节将比较分析所提基于密度的分析方法(DB)与已有方法的识别性能。此处选取P=[m/3]+1,Q=[m/3]+1, α=0.05。已有方法将选取基于层次聚类的分析方法(CB)[13]、基于最小体积椭球的分析方法(MVE)[11-12]和基于连续差分的分析方法(SDE)[8]。性能比较分析采用用蒙特卡洛模拟仿真,各种方法的性能指标结果均基于5 000次重复计算,并列于表4中,其中加粗结果为特定偏移量下不同方法中各性能指标中的最优结果。
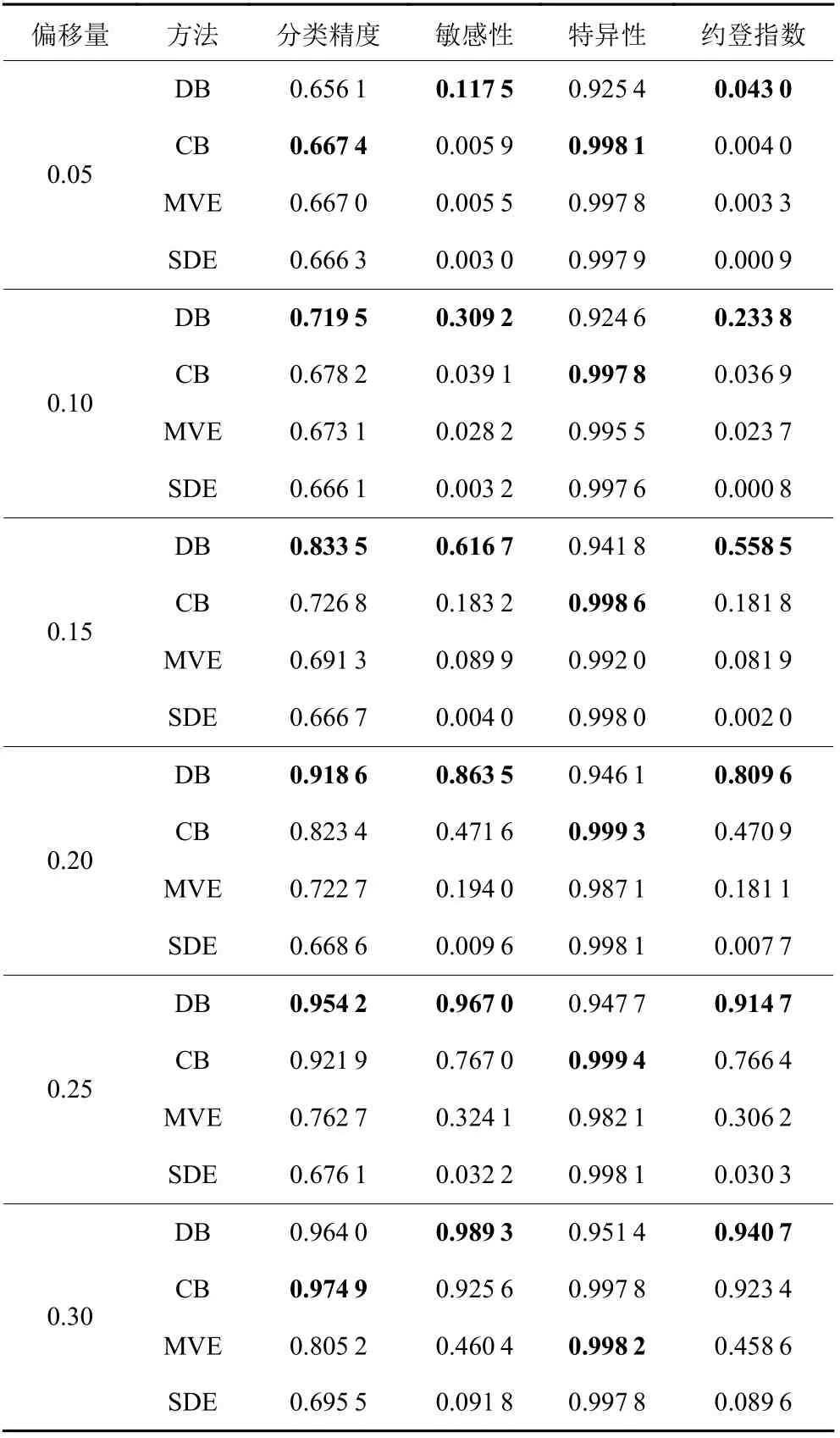
表4 不同分析方法的性能比较Table 4 Performance of different methods
由表4易知,根据约登指数可以得出所提基于密度的方法要优于所有已有方法,而且根据分类精度也可以看出所提方法在大多数情况下也表现出最优的识别效果。当偏移量为0.05或0.3时,根据分类精度的结果,虽然基于密度的方法表现较弱,但是,与最优方法相比,在分类精度的结果上相差不大。综合在分类精度与约登指数上的整体表现,所提基于密度的分析方法的综合性能最好,表现出较优的识别性能。
4 结论
目前已有的轮廓控制参数识别方法受异常轮廓的干扰较大。本文所提出的基于密度的受控轮廓识别方法,改进了已有方法在初始受控轮廓确定时因异常轮廓存在造成敏感性降低的不足之处,进而提高了估计轮廓参数 β¯的准确性,获得更为稳健的T2统计量,从而可以提高识别性能。另外,本文建议使用约登指数作为性能指标,可以综合分析识别性能,从而在比较各种方法的性能时更加方便。此外,基于蒙特卡洛模拟,分析所提方法中初始受控轮廓数目Q、密度参数P和置信水平α对识别性能的影响,并给出当偏移量未知时Q、P和α的设定建议。最后,比较分析所提方法与已有方法的识别性能。结果显示,综合分类精度和约登指数的结果,所提基于密度的轮廓参数控制方法的性能要优于其他方法。因此,基于密度的轮廓控制参数识别方法在很大程度上削弱了异常轮廓对T2控制图的干扰,对于识别产品或过程中的受控轮廓集非常有效。
由于所提基于密度的方法依赖于初始受控轮廓数目Q和密度参数P,从而影响初始受控轮廓集的确定。因此,未来研究中,可以综合运用其他方法,如K均值聚类等,与所提方法来改进初始受控轮廓集的确定。如首先基于不同方法各自确定初始受控轮廓,然后通过比较分析,取不同方法中都包含的初始受控轮廓作为初始受控轮廓集,可以进一步降低异常轮廓的干扰,从而提升参数估计精度,进而提高识别性能和轮廓控制参数的合理性。
猜你喜欢
地理空间信息(2022年3期)2022-04-01
飞控与探测(2022年6期)2022-03-20
装备制造技术(2020年1期)2020-12-25
力学学报(2020年4期)2020-08-11
制造技术与机床(2019年11期)2019-12-04
制造技术与机床(2017年7期)2018-01-19
测绘工程(2017年3期)2017-12-22
中国交通信息化(2017年4期)2017-06-06
黑龙江电力(2017年1期)2017-05-17
城市道桥与防洪(2013年8期)2013-03-11
